基于主题与语义的对话语料关键词抽取方法
2018-12-13黄青松刘利军李帅彬冯旭鹏
胡 迁 黄青松,2 刘利军* 李帅彬 冯旭鹏
1(昆明理工大学信息工程与自动化学院 云南 昆明 650500)2(昆明理工大学云南省计算机技术应用重点实验室 云南 昆明 650500)3(昆明理工大学教育技术与网络中心 云南 昆明 650500)
0 引 言
关键词有助于提高文本分类、信息检索等自然语言处理任务的性能。近年来,随着即时聊天、网购咨询、自动问答系统等社交网络的迅猛发展,积累了大量的对话特性文档,对话记录隐含了人们聊天的情景和目的,反映了对话者的兴趣。从对话中抽取关键词可以用来总结、组织、检索对话内容,也可被用于用户个人服务、广告推荐等。相较于传统长文本,这类数据具有对话性、短文本、结构松散等特点,导致关键词难以遴选[1]。因此,对话文本的特性给关键词抽取带来了挑战和意义。
1 相关工作
传统关键词抽取主要集中在网页检索、科技文献和文本文档等领域,方法主要分为有监督方法和无监督方法。有监督方法采用人工标注的关键词文档训练分类器得到关键词。Neuyen等[2]针对论文,利用论文的结构信息、词性、词语后缀等特征,提高了关键词分类器性能。Meng等[3]基于神经网络的编码解码预测模型来生成关键词,文中用循环神经网络模型结合注意力和重复机制来训练模型,模型解决以往方法只选择文中出现的词作为关键词和不能捕获文档真正的语义含义的问题。有监督方法缺点:需要标注关键词。无监督方法主要计算词的显著性权值,然后排序推荐。Mihalcea等[4]提出基于图的排序算法TextRank。该方法将文档中词的共现关系构造词汇图,然后计算各个节点的权重得到关键词。Liu等[5]从隐含主题的角度出发,通过在Wikipedia语料上进行主题模型训练,将候选词与文档的主题层相似度作为该词的显著性权值。在此基础上,在偏置PageRank方法中引入隐含主题的权重,提出了Topic PageRank方法,该方法效果优于只利用LDA的方法和基于TF-IDF的方法,这验证了在基于图排序的关键短语抽取算法中引入文档主题的可行性。文献[6-7]计算词语义相似度构建词汇链,然后结合词频或主题信息进行关键词抽取,但方法受到知识库的限制。由于对话文本特点,采用传统的关键词抽取方法是否有效值得怀疑。
对话语料的关键词抽取文献研究较少。刘铭等[8]针对会议记录,提出了两种无监督的关键词抽取算法。在TF-IDF框架下,加入词性过滤、词聚类和句子重要性得分提取关键词。同时研究基于图的迭代方法,分别考虑了词与词、词与句子的图类型得到词的权重,句子与句子、句子与词的图类型得到句子的权重。实验结果表明简单的TFIDF方法优于基于图的方法,而且词性的过滤和句子重要性得分有助于关键词抽取。结果还表明基于共现词聚类的聚类方法对结果没有明显帮助,因为共现的聚类没有拾取词的语义相似性。Song等[9]针对英语和韩语会议记录提出了实时关键词抽取方法,方法主要基于图,考虑历史句子中与当前句子相关性,以及遗忘曲线跟新历史句子生成的图来得到当前句子的关键词。但图边权重利用是否在窗口中共现置为1或0,没有考虑词间的语义关系。Liu等[10]针对会议记录提出一种有监督的关键词抽取方法,其考虑对话数据特点,利用最大熵分类器决定某个一元词是否为关键词,同时考虑了二元词的扩展。缺点是需要标注关键词训练分类器。对话语料中标注好关键词的文档很匮乏。Chen等[11]针对课程讲座语料提出了两步法提取关键词,首先利用PLSA模型计算候选词语的主题一致性和重要性(TCS),方法结合目标文档、按词搜索的文档和维基文档综合计算候选词的TCS。其次,根据词语的TCS排序,前M个作为正样本,其他作为负样本,然后结合词的频率、语义等特征训练SVM分类器。Yeh等[12]利用语义分析分好主题类文档来训练LDA模型,实验表明LDA模型比SVM模型有更高的准确率。训练模型时如何找辨识度高的词是关键。PLas等[13]针对对话研究考虑语义,他们采用两种词典资源:EDR和WordNet来计算词间的语义相似性抽取关键词,并同时对比了两种词典的效果,但方法受词典限制。Noh[14]根据词语的维基百科语义信息,计算词语与本句和全部句子的语义相似性,抽取与对话语义更相关的词语。文献[15]首先利用LSA获取语义信息,然后对对话文本进行分割,最后得到摘要。李天彩等[16]针对短文本信息流提出新的用户建模方法。首先将用户发表内容合并,然后将内容分割为固定长度的词链,在分割处添加用户名构造上下文关系,最后结合外部数据,使用Skip-gram模型进行训练得到用户的向量表示。将和用户向量最相似的词语作为用户标签。房冠南[1]提出一种针对对话语料的自动标签推荐方法,该方法在TF-IDF基础上,考虑对话者权重(对话者说出的句子数占整个对话包含句子的比重,对话者说出的次数占整个对话包含词数的比重,对话者说出的实词数占整个对话的实词数)、句子重要程度和句子长度等因素,进行关键词抽取,然后通过规则扩展二元关键词,最后在同一尺度下排序得到top-n关键词进行标签推荐。方法实验证明了TFIDF,POS过滤、基于实词的对话者权重、句子重要、句子长度五种因素对关键词抽取有用。同时文中指出所提方法的缺点是抽取关键词仅仅考虑词频、未考虑词的语义关联。
综上所述,本文所提方法聚焦语义和主题信息,结合词语义聚类、词性权重、句子主题相关性等多权重来抽取关键词,简称KSeL方法。最后,TFIDF方法和KSel得到的关键词作为节点,基于语义建立图,通过图迭代得到最终的关键词,简称为GKSeL方法。
2 对话语料的标签生成方法
本文所提方法的流程图如图1所示。首先,对中文语料和对话语料进行预处理、训练得到词向量和主题模型。其次,计算给定文档句子的主题相关度,词与所有句子的相似度,得到词与文档语义相似度权重。然后,用词的词性权重、词的语义相似度、词语义聚类权值结合得到基于语义方法(KSeL)的候选关键词。最后,尝试将KSeL所得关键词与TFIDF关键词利用基于图的方法进行混合筛选(简称GKSel方法),期望结合语义和词频得到关键词。

图1 基于语义与主题的用户标签生成方法
2.1 对话表示
对话语料含有很多语气词和符号,为了提高实验的效率和精度需要做分词和去停用词等预处理工作。为了方便理解,先给出文中所用的定义。
定义1(词的向量表示)W={d1,d2,…,dn},其中n表示词的向量维度,每个词的维度相同,di表示词对应i维上的值。
定义2(会话表示)DL={s1,s2,…,sm},其中m表示对话中句子的个数,不同对话文本含有的句子的个数不一定相同,si表示文中第i个句子。
定义3(主题表示)T={t1,t2,…,tk},其中ti表示组成主题的词,k表示词的个数,ti表示主题第i个词。
定义4(句子表示)S={w1,w2,…,wm},其中m表示句子的个数,不同句子含有词的个数不一定相同,wi表示文中第i个词。
2.2 句子的主题相似性权重
Yunseok Noh[14]阐述含有信息的语句很大程度上与主题相关,反之没有信息的语句包含的词多是无意义或习惯性词语,文献[8,17]都表明重要的句子通常包含关键词,关键词也经常出现在重要句子中。因此考虑句子的主题权重,首先通过训练的主题模型得到给定对话文档的主题T={t1,t2,…,tk},然后,计算文档中每个句子S={w1,w2,…,wm}与主题T的相似度。相似度WeightSi计算如下:
(1)
2.3 词与句子的相似度
如果一个词的语义与对话语句的语义越相似,则该词越能够代表该句子表示的语义信息,文献[14]利用ESA表示词的语义信息,然后基于此计算词的局部权重和全局权重。由此,方法考虑词语与文本中所有句子的相似,得到词的全局相似值作为词的语义权重。词与句子的相似性WeightWi计算如下:
(2)
式中:w1代表候选关键词,w2i代表含有m个词的句子中的第i个词。词与句子相似度高,但句子与对话主题不相关,则词不能很好地代表对话内容。因此,考虑词语与句子相似性的同时需要考虑句子的主题关联性。句子与主题关联性越高,则句子越能够代表主题。最终得到候选关键词的语义相似度值WDscore计算如下:
(3)
式中:m表示对话文本含有的句子的个数,WeightWi和WeightSi分别由式(1)-式(2)求得,即WeightSi代表句子i与主题的相似权重,WeightWi候选关键词与句子i的语义相似度。
2.4 词的语义聚类重要度
对话过程中可能会反复提到某个词来强调意图,同时,会话可能用不同的词代表相似的意思,对话所含词语中,如果某几个或多个词语相似,至少说明文本中涉及该类信息。所以本文方法根据词的语义相似度进行聚类,根据得到的类中词语的个数占文本总词数作为该类词的语义聚类权重。本文采用文献[18]中的快速聚类方法,该方法假设聚类中心周围都是密度比其低的点,同时类中这些点距离该聚类中心的距离相比于其他聚类中心最近,对于每个数据点i,需要计算两个量:局部密度ρi和高于i点密度的最小距离δi。
局部密度定义如下:
(4)
当χ<0时;χ(x)=1,否则等于0。这里dc是一个截断距离,这里选择比较鲁棒性,因此算法中dc定义为文中所有点的相互距离由小到大排列占总数2%的位置的词间距离。最小距离定义如下:
(5)
比i点密度高的所有点中,与i点距离最近的点的距离表示为δi,对于最大密度的点其δi为所有点之间距离的最大值。然后给定两δmin和ρmin,同时大于这两个数的点作为聚类中心点。确定聚类中心后,剩下的点的标签按照以下原则分配:当前点的类别标签和高于当前点密度的最近点的标签一致。据此得到候选词w的聚类权重ClusterW如下:
(6)
式中:num1是候选词所属类中词语的数目,num是所有候选词数目,同一聚类中所有词拥有相同的语义聚类重要度。
2.5 词性权重
文献[1,8,10]通过词性过滤只保留动词、名词、形容词作为候选词,其实验表明这种过滤对关键词抽取有帮助,所以,方法考虑词性的权重PosWeight,采用文献[19]中定义的不同词性的权重值,如:动词为0.3,形容词为0.5,副词为0.3,名词为0.8等,其他词性重要度请参考文献。
本文方法考虑词性权重、词语义聚类权重(得分)、词的语义相似度权重(得分),最终得到词权重Wscore计算如下:
Wscore=PosWeight×(ClusterW+WDscore)
(7)
上文公式中词间距distance()和dij采用余弦距离公式,根据文献[20]词语可以由一堆实数的向量形式表示语义信息,本文词向量采用Skip-gram方法得到,如W1{x1,x2,…,xn},W2{x1,x2,…,xn},则词间距离计算公式如下:
(8)
2.6 基于图的筛选
文献[8]的实验结果表明基于TF-IDF方法抽取关键词优于基于图的方法,图中边权重主要考虑TF-IDF。本文主要考虑语义抽取关键词。但是,因为人们对关键词理解有不同的认知,基于语义的关键词概括性可能不如基于频率抽取的关键词,反之依然。所以,考虑将两种方法的抽取的关键词混合,然后基于图的迭代计算词的权重,最后选出TopN个词,期望能综合利用到词的语义和频率信息。
本文中用G=(V,E)代表混合候选词语构成的图,V代表词语节点,E是边的集合,对于每个节点vi,In(vi)代表指向它的节点集合,Out(vi)代表节点vi指向的节点集合。权重Wij代表节点间边的权重。Wij计算如下:
(9)
distance(vi,vj)由式(8)得到,Wij为0表示两词无边链接,节点vi的最终权重计算公式如下所示:
(10)
式中:d取0.85。S(Vi)的初始值定义为:如果该点的词语同时出现在TF-IDF和所提方法中为2,否则为1。权重计算是个迭代过程,直至收敛或达到一定迭代次数停止,最后选取权重最高的N个词。
3 实验结果与分析
3.1 实验数据和预处理
实验使用的数据集来自访谈节目的对话,试验前对语料进行分词、去停用、清洗特殊符号等预处理工作,尽可能地使其包含一个主题。我们招募了8名学生进行人工标注,两人一组标注相同的对话,共标注了1 000个对话,每个人的对话标注的标签不少于5个,标注者可以任意选择他们认为重要的词作为关键词。
访谈对话示例如图2所示。

图2 访谈对话示例
人工标注对话的例子如表1所示。

表1 对话标注例子
不同的标注者看待问题的角度不同,所以对于词的重要程度的认识也不相同,导致标注的关键词不一致。我们抽样200个对话来计算不同标注者的一致性,人工标注分析采用严格匹配的方式,两个标注者对于同一对话的一致率是32%。
3.2 实验结果分析
为了比较算法的性能,我们使用TFIDF和基于图的TextRank方法作为对比方法。表2中列出了针对同一段对话,四种方法抽取的关键词示例。

表2 不同方法关键词抽取结果
根据抽取关键词结果比较,KSeL阐述的对话主题更完善,TFIDF的阐述缺少主题,表达不够清楚,KSeL和TFIDF同时出现了“钱”和“房子”两个关键词,说明对话很大程度上与房子和钱有关,TFIDF可以理解演员之间买卖房子等,KSeL可以理解为鲁豫王凯俩人讨论毕业和房子的故事,同时牵涉钱的问题,对原话表达更全面清楚。TextRank和KSeL比较抽取结果虽然很多相似,但结合原对话分析,TextRank缺少了“毕业”、“坎儿”、“日子”等描述生活状态的词,多了一些“觉得”、“没有”、“想到”等模糊词语。GKSeL是由TFIDF和KSeL得到,可以看出IFIDF方法中“借钱”、“供”、“月”排到了前面,表达了“房子”,“月供”,“借钱”,“坎儿”的连贯性,与KSeL相比描述的信息更具体深入。
本文采用两种评价方法的性能,第一种采用文献[1]中的自动评价方法,如下所示:
Top-K准确率:k个抽取关键词中至少有一个正确的文档占全部的关键词比例。
精确度:抽取的正确关键词占所有抽取的关键词的比率。
准确率:抽取的正确关键词占人工标注关键词的比例(召回率)。
图3显示了三种方法的Top-K,精确度和准确率。从图3(a)中可以看出,GKSeL在top-1时的准确率达到了48.23%,TextRank和TFIDF准确率分别为39.35%和43.32%,随着标签个数的增加,Top-K准确率的性能有所提高;从图中看出,方法GKSeL对于5个关键词的准确率达到75.12%。图3(b)显示了关键词个数从1增加到5时,精确度随关键词个数变化,GKSeL最高精确度48.56%。显示了召回率的变化情况,随着关键词个数的增加GKSeL的召回率不断增加,最低召回率为21%。从图中得出方法的性能优于TFIDF和TextRank。

(a) Top-K准确率

(b) 精确度-召回率图3 不同方法在对话数据上的性能
第二种方法采用文献[1,8]拒绝率评价,拒绝率代表有多少抽取的关键词是不可以被人接受的。由于人工标注的不一致性,我们需要质疑,Top-K等是否适合用来评价抽取关键词方法的性能。所以本文在少量语料上,采用拒绝率进行人工评测。我们选取100个对话,给2个人提供方法抽取的关键词,并让其标注不能反映对话内容的关键词,然后测量出每个标注者和方法的拒绝率。结果如表3所示。
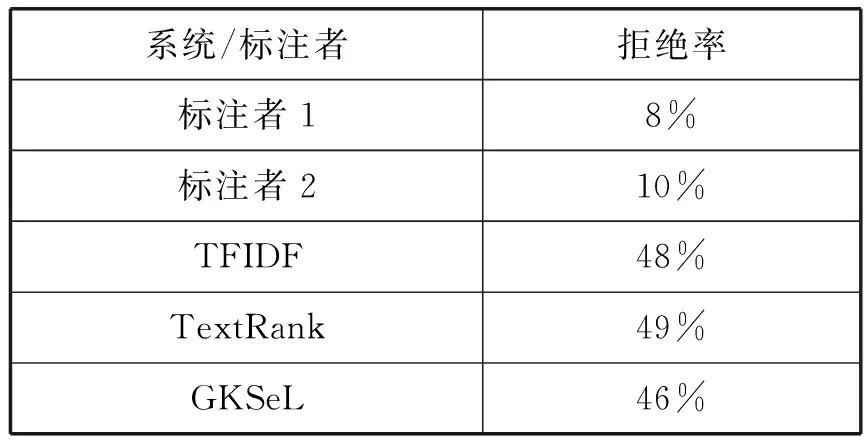
表3 不同方法人工拒绝率
从表3中,可以看出,人工标注的拒绝率最低,因为人能够更清楚地理解对话内容,但不同的人具有不同的出发点,所以拒绝率不同,但符合预期。GKSel的人工拒绝率低于TFIDF和TextRank方法,人工拒绝率的测评结果同样证明了我们所提方法的有效性。
4 结 语
本文提出了一种面向中文对话语料的自动关键词抽取方法。该方法利用语义和主题信息,结合词的语义聚类、词性权重、句子主题相关性等多权重来抽取关键词。最后,结合TFIDF方法得到的关键词建立以词为节点的图,基于图迭代方法得到最终关键词。方法考虑语义基础上兼顾频率,同时利用自动评价和人工评价检验方法的性能。实验结果显示,所提方法优于TFIDF和TextRank方法,证明了本文所提方法的有效性。
本文从实验数据上说明了方法的可行性,但人工标注的不一致性和抽取关键词的准确率有很大关系。另一方面,所抽取的词仍然比较单一,虽然文献[1,10]考虑了二元扩展,但基于模板,比较简单。未来希望可以结合神经网络训练语义的优点来得到文中未出现词且符合人们习惯的词语。因此,未来将考虑未现词和短语方面的研究。
