海量网络文本去重系统的设计与实现
2018-12-13汤建明寇小强
汤建明 寇小强
(华北计算机系统工程研究所 北京 100083)
0 引 言
随着互联网的普及,每天有数以亿计的新内容在网络上产生。这些内容或者以新闻报道的形式,或者以公众号和专栏文章的形式呈现在人们眼中。基于如此海量的文本数据,其中有着大量的冗余相似内容。有研究表明,在应用系统所保存的数据中,冗余数据约占60%左右[1]。因此,如何有效地来识别互联网上的重复信息,对学术界和工业界来说都是一个很有意义的课题。
举一个例子:对于基本所有的搜索引擎系统来说,它们底层的爬虫系统会去大量抓取网络上的文本等数据资源,显然,抓取到重复和高度相似的网页和文本进行存储和收录是没有意义的,这样不仅浪费存储资源,也会对后续的计算处理带来不好的影响;同时,展示重复和高度相似的检索结果对于用户来说也是不好的使用体验。对于像传统的新闻门户网站和推荐系统应用来说,保证文章质量是非常重要的。所以,有必要保证对于每天新产生的文本内容进行相似度判断和去重处理。对于相似度过高的文章只保证唯一一份内容入库,这样不仅节约了数据存储的成本,也会提高用户的检索体验。
本文基于simhash算法【2-3】设计和实现一个文本去重系统,采用Ansj开源分词工具对原始文本内容进行分词处理,数据存储采用Rdis+Mysql+Hbase。
1 海量网络文本去重系统设计
1.1 整体架构
图1是本文海量网络文本去重系统的整体功能模块设计图。整个系统可以主要分成三个部分:一是分词模块对原始文本内容进行分词处理;二是判重模块对处理后的文章进行相似度判断;三是入库模块对经过去重的文本数据进行入库处理。
1.2 工作流程
图2是本文海量网络文本去重系统的整体调用处理流程。整个系统会用Maven打成war包,最后部署在Tomcat服务器中。系统以HttpServlet接口的方式提供调用入口。每篇文章有一个唯一标识,记为nid。经过预处理的文本数据以JSON字符串的形式进入系统,主要包含有文章来源url、文章标题title和文章内容content等属性。最后会返回一个唯一标识,以docId来表示,内容相似的文章对应同一个docId值。系统会依次根据文章的url、title和content去Redis中查找是否有相同的缓存值,有则直接返回对应的docId值,没有则会根据文章的url、title和content计算出一个新的docId值,并缓存在Redis中。数据库Mysql中会保存所有nid和docId的对应关系。Hbase中会保存文章的所有内容信息,用docId来唯一标识。
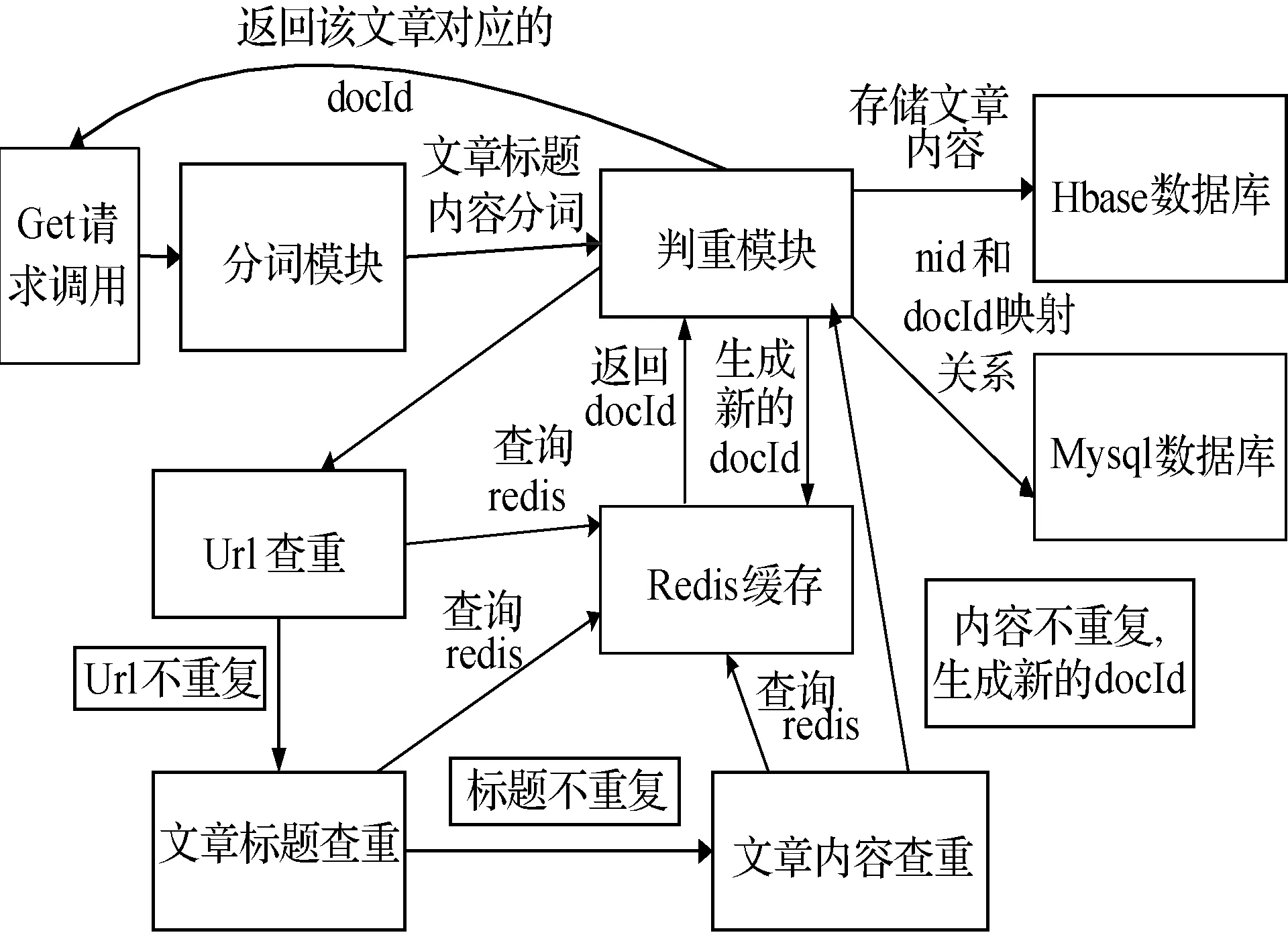
图2 工作流程
2 关键实现技术
2.1 Ansj分词
Ansj是一个分词效果非常精准的中文分词器[4],它完全开源,是ICTLAS的Java实现版本,同样是构建了Bigram[5]+HMM的模型来进行分词。虽然它的基本原理和ICTLAS一样,但是Ansj在工程上做了一些优化,比如:用DAT高效实现的检索词典、用邻接表来实现分词DAG、同时支持基于个人需求的自定义分词词典,以及支持消歧义规则的自定义等[8]特点。
2.2 simhash文本去重算法
Simhash是locality sensitive hash(局部敏感哈希)的一种,最早是由Moses Charikar在《similarity estimation techniques from rounding algorithms》一文中提出来的。
该算法的主要思想就是降维,将高维的特征向量经过一系列的处理后映射成低维的特征向量,然后通过比较两个向量的Hamming Distance来判断文本是否高度相似甚至完全重复。其中,Hamming Distance通常又称为汉明距离[7],这是信息论中的一个概念,指的是两个长度相等的字符串之间对应的各个位置上不同的字符的总个数。简单来说就是,将其中一个字符串变为另一个字符串总共需要改变的字符总个数。这样一来,通过对比文档内容的simhash值的汉明距离,就能够得到它们之间的相似度是多少。
2.3 Redis+Mysql+HBase三级存储系统
Redis是一个支持网络的、基于内存存储、数据可持久化的开源Key-Value数据库[9]。和传统的关系型数据库Mysql相比,Redis的查询和存储性能都要高得多。由于Redis可基于内存存储,所以非常适合用作缓存处理,这样可以加快存储和查询速度,也能够减轻数据库的负载压力。
在本文的海量网络文本去重系统中,Redis用来存储文章url、title和content经过处理后的索引,这样,即使是在高并发的网络场景下,每次有新的请求进入系统,也不会存在查询瓶颈。这样的缓存设计也将真正的文章内容存储解耦,使得判重模块只关注于文章内容去重,数据的存储异步地载入库模块进行,可以在很大程度上提高整个系统的处理性能。
在本系统的三级存储系统设计中,Mysql只用来存储每篇文章的唯一标识nid和docId的映射关系,并不真正存储文章的数据内容。互联网上的海量文本数据包含的属性大不相同,Mysql不适合用来存储这种数据,当数据量大到一定级别后,Mysql的性能也会大打折扣。因此,文章的数据最后存储在HBase中。
HBase是一种分布式的存储系统,它构建在HDFS之上、支持面向列的存储[6]。HBase支持数据实时地读写,同时,它对超大规模的数据集的随机访问也支持的非常好。基于HBase的这些特性,非常适合用来存储海量的文本数据,其列存储属性极易扩展,不会因为文章内容各不相同的属性而带来存储困难。
3 海量网络文本去重系统的实现
3.1 分词模块
对于请求的Json数据,其格式大致如下:
json=
{
″url″: ″http://www.help.com″,
″title″: ″测试″,
″content″: ″这是一个测试″,
″category″: ″0″,
″media″: ″sina″,
″imageCount″: ″4″
}
url表示文章的网络地址,title表示文章的标题,content表示文章的内容,category表示文章的属性,media表示文章所属的媒体,imageCount表示文章中的插图数量。在该系统中,我们只关注title和content两个字段的内容分词。
分词模块将title和content的内容切分成一个一个单独的词,采用Ansj提供的ToAnalysis分词实现,对于分词后的单词,保存在Redis缓存中,过期时间设置为7天。
3.2 内容判重模块
该模块是系统的核心模块。主要依据文章的url、title和content三个属性值来进行判重处理。
经过分词处理的文章title和content,会首先经过判重模块提供的签名方法生成一个唯一的64位签名,该方法则基于simhash算法实现。simhash算法主要分为5个步骤来进行:
(1) 分词 该步骤首先调用分词模块提供的方法,将待处理的语句先进行初步的分词,这样就得到了语句有效的特征向量,接着为特征向量来设置权重,这里可以根据需求自定义n个级别的权重。比如将n设为5,则可以用1~5来表示每个向量的权重。在具体实现中,可以根据每个单词在整段文本数据中出现的次数来定义它对应的权重值大小。
(2) 计算hash值 通过hash函数来算出上一步中每个特征向量各自的hash值,hash值可以看成用二进制数0和1所组成的n-bit位签名。比如“去重”的hash值计算出来为110010,“系统”的hash值计算出来为101001。经过这样处理之后,字符串值就变成了一系列的二进制数字组合。
(3) 加权处理 在算出了单词hash值的基础之上,对这些特征向量来进行加权处理,具体实现方式即:W=hash×weight,weight代表该单词在文本中的权重。对上一步算出来的每一个hash值,计算它二进制数字每一位的加权结果。如果该位的值为1,那么就和权值进行正相乘;如果该位的值为0,就和权值进行负相乘。例如:假如上一步“去重”的权值为3,则加权后的值计算为W(去重)=3 3-3-3 3-3;同理,假设“系统”的权值为5,则加权后的值为W(系统)=5-5 5-5-5 5。其余所有特征向量依此类推。
(4) 合并计算 将所有经过加权计算的特征向量的加权结果累加,得到这段文本的总的加权值。例如:拿前面的“去重”和“系统”举例,累加得到“3+5 3-5 -3+5 -3-5 3-5 -3+5”,最后结果为“8 -2 2 -8 -2 2”。
(5) 降维处理 对于以上处理后的n-bit的hash加权值,对每一位,如果该位的值大于0则置为1,否则置为0,从而得到该文本语句的simhash值。同样以上面的例子来看,则降维处理后的值为101001,这就是最后这段文本的simhash签名。
图3体现了计算simhash签名的过程。
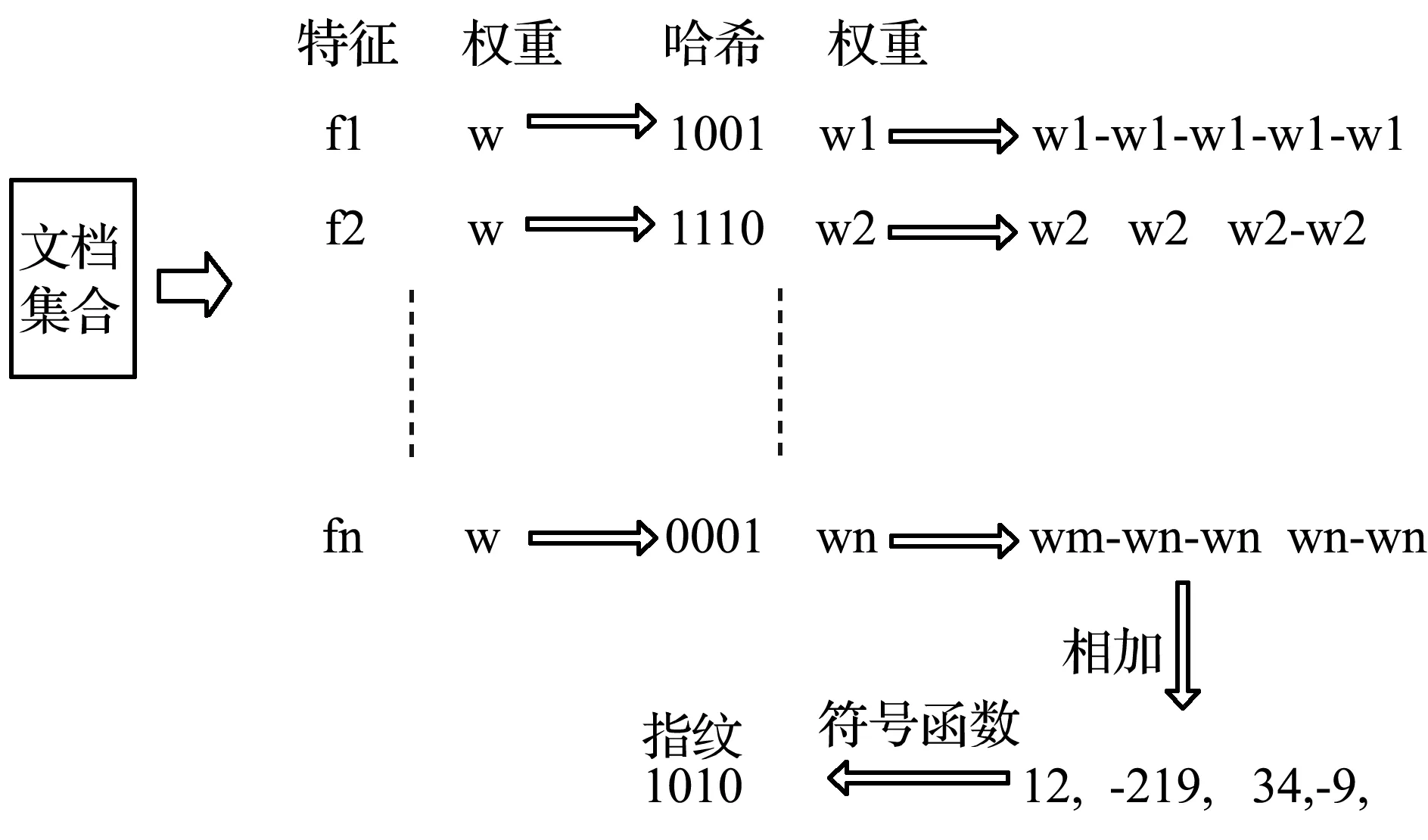
图3 计算simhash签名
在得到每篇文档对应的simhash签名值之后,通过计算两个签名值的汉明距离来判断它们是否相似。判断标准可以根据具体业务场景来定,本系统采用业界工程实践较好的3作为判断标准,即对于64位的simhash值,如果汉明距离相差在3以内的话,就可以认为两篇文档是高度相似的。
以上通过计算simhash值来判断相似的过程是判重模块所提供的一个方法,具体到本系统的业务逻辑处理中,判重流程如下:
(a) 根据url和固定前缀值URL_INDEX形成的字符串去Redis缓存中查找是否有相同的值,如果存在,则直接返回对应的docId值;如果不存在,则进行步骤(b)。
(b) 根据title生成的simhash签名以及固定前缀值TITLE_INDEX形成的字符串去Redis中查找是否有相同的值,如果存在,则直接返回对应的docId值;如果不存在,则进行步骤(c)。
(c) 根据content生成的simhash签名以及固定前缀值CONTENT_INDEX形成的字符串去Redis中查找是否有相同的值,如果存在,则直接返回对应的docId值;如果不存在,则进行步骤(d)。
(d) 经过前面三步流程查找都没找到,说明这一次请求的文章是一篇新的文章,则根据该文章的url、title和content值生成一个唯一的64位docId值,同时对title和content的simhash值建立索引并进行缓存处理,以供下一次新的请求做查询比对处理。
以上即为整个判重模块的设计实现。
3.3 数据入库模块
数据入库模块异步地进行数据的入库存储处理。
对每一次请求,如果进过判重模块处理后为相似的文章,则在Mysql中添加一条记录,保存该文章nid和已经存在的相似文章的docId的映射关系;如果判重处理后为新的文章,则在Mysql中添加一条记录,保存该文章nid和新生成的docId值的映射关系。对每一个docId值,只在HBase中保存一份热度最高的文章内容。
我们在其他的系统中需要检索或者推荐文章时,就不会出现重复相似的文章,因为入库模块最后数据入HBase的过程中保证了一个docId值在HBase中只保存有唯一一篇文章。
3.4 实验结果展示
本系统采用Java开发实现,采用Maven作为项目构建工具,最后部署在Linux服务器上,以war包形式部署在tomcat容器中,提供一个访问接口供外部调用,具体调用形式如下:
127.0.0.1:8080/docId/getDocId?json={ }
其中,127.0.0.1为系统部署的服务器网络地址,8080为访问的端口号,docId为服务名称,getDocId为访问接口,json={}为请求数据,以Json形式传输,具体字段可见3.1中所描述。利用Postman来模拟请求,先自定义一个测试数据如下:
json=
{
″url″:″http://www.simhash.com″,
″title″: ″计算机应用与软件″,
″content″: ″海量网络文本去重系统实验测试,这是一段测试文本的内容。″,
″category″: ″0″,
″media″: ″test1″,
″imageCount″: ″4″
}
系统运行过程如图4所示。
可以看到,如果是一篇新的文章请求系统,则系统内部会经过url、title和content三次查找判重操作,最后会在Redis中缓存新的索引,并返回计算生成的新的docId值。最后结果以Json字符串形式返回,如下所示:
{
″filterReason″: ″docId_filter good news″,
″docId″: ″cdd71f57317390e7-ad7b2a053b6e4176″,
″filterStatus″: ″good″,
″status″: ″success″
}
接下来我们再定义一个和上面相似的文本内容作为请求数据去请求该去重系统,自定义数据如下:
json=
{
″url″: ″http://www.simhash1.com″,
″title″: ″计算机应用和软件2″,
″content″: ″海量网络文本去重系统实验检测,这是一段相似的测试文本的内容。″,
″category″: ″0″,
″media″: ″test2″,
″imageCount″: ″3″
}
可以和上面的请求数据对比,两者高度相似,这次系统运行过程如图5。
从图中红线圈可以看到,系统最后判断content排重成功,也就是成功判定出这篇请求的文章和上一篇文章相似。在查询Redis判重的过程中,由于标题和内容都相似,系统也没有重新计算新的索引去缓存。最后返回的docId值也和上一篇相同,也就是没有重新计算生成新的docId。
4 结 语
海量网络文本去重系统用于对互联网上充斥着的大量重复网页内容和文章进行去重处理。由于采用多模块的解耦设计,可以保证系统在高并发的访问情况下做到快速响应。整个系统采用Maven作为项目构建工具,易于移植和扩展。同时,本系统提供标准的HttpServlet接口,采用Json作为通用的网络数据传输格式,可以很方便地接入到其他需要进行文本去重处理的工程项目中。未来,该系统将添加图片判重处理模块,这样使得系统的适用范围更广,可以识别出相似的图片,这样对包含有插图的文本内容可以进行更为精确地去重判断和处理。在系统的并发处理和存储性能方面也将展开进一步的研究工作,从而提高系统的性能水平。
