独立泊松序列与指数序列的变点检测方法比较
2018-10-30韩冰凌孙佳楠
韩冰凌,孙佳楠
(北京林业大学 理学院,北京 100083)
0 引言
变点检测涉及的基础学科涵盖了数理统计、应用数学、计算机科学等,并在金融学、经济学、气象学、环境学等多个学科中广泛应用。例如,在金融学研究中,宿成建和陈洁[1]应用变点模型研究了沪深股股市波动性突变行为,并分析了1992—2002年上证和深证综合指数的方差变点,对这些变点的经济意义进行了解释。在自然环境研究中,涂新军和陈晓宏[2]基于变点原理,运用似然比方法研究了存在变点的河川径流量序列,并给出了一系列的结论。
注意到对泊松分布序列和指数分布序列的变点检测研究不多见,但其具有较强的实际应用价值。一些稀有事件如地震、煤矿灾难等的发生近似服从泊松分布,总结这些稀有事件的发生规律及发展过程中的规律突变,对于防范自然灾害等有重大意义,如对矿难发生次数的变点分析[3]、稀有事件变点问题的分析[4]等。一方面,产品的寿命以及随机服务系统的服务时长等往往服从指数分布,检测这些指数序列的变点,可以为提高生产质量和改进服务质量提供科学依据,如黄志坚和张志华[5]研究了可靠性数据在变点前后服从不同参数的指数分布产品的寿命分布,建立了产品故障分布的模型。
基于上述两种分布的独立序列数据,有必要通过模拟实验就不同变点检测方法的检测效果进行比较研究,并给出能够指导实际应用的有价值的参考建议。R软件中的Changepoint程序包[6]是近年开发的简单实用的变点检测程序包,其中包含了经典的仅一个变点(Atmost One Changepoint;AMOC)检测法[6]和Binary Segmentation(BS)方法[7],也包含了最近提出的Pruned Exact Linear Time(PELT)方法[8]。本文针对泊松和指数分布序列,使用该程序包下的上述三种变点检测方法,分别对不同情境下的独立泊松序列和指数序列进行均值方差变点的检测和比较。
1 三种均值方差变点检测方法
1.1 变点问题的提法
变点一般是指观察序列中统计性质发生变化的点的位置,统计学变点检测问题是对该位置的估计问题。设一个按时间顺序排列的观察值序列记为 y1:n=(y1,...,yn),若存在一个时间点τ∈{1,...,n-1},使得这个时间点之前的序列{y1,...,yτ}和这个时间点之后的序列{yτ+1,...,yn}具有某方面不同的统计性质,那么该时间点τ称为一个变点。当这两个子序列的均值参数变化,τ称为均值变点;当这两个子序列的均值和方差参数都变化,τ称为均值方差变点。如果序列只存在一个变点,称为单变点;如果变点数量为m,即存在不只一个变点,称 τ1:m=(τ1,...,τm)为多变点[9]。
1.2 单变点问题
单变点检测可以转化为假设检验问题,原假设是观察值序列无变点,备择假设为存在一个变点。该检验问题可通过似然比检验实现,具体参见正态分布下均值单变点的检测研究[10]和正态方差单变点的检测研究[11]。
1.3 多变点问题
对于多变点问题,常将变点检测问题转换为目标函数的优化问题其中,C为损失函数,可以采用负对数似然函数。βf(m)为惩罚函数,可以采用 AIC[12]、BIC[13]的惩罚形式。
具体地,使用BS方法[7]优化上述目标函数的思想:第一步,在观察值序列中只检测一个变点的位置,如果序列中存在一个τ满足 C(y1:τ)+C(y(τ+1):n)+β<C(y1:n),则认为发现了一个变点;第二步,针对yτ分得的两个子序列,分别进行单变点检测……直到每个子序列中不再检测出变点。若第一步找不到单变点,则认为此序列没有变点。BS方法是将单变点检测的思路应用于多变点检测问题,方法中常取 f(m)=m。BS方法具有运算效率高的优点,但不能保证检测出的变点是目标函数优化的全局最优解。
若使用PELT方法[8]优化上述目标函数,则需以Optimal Partitioning(OP)算法为基础。OP算法的思想是采用递归的方式优化目标函数。记F(s)=min{F(t)+C(y(t+1):n) +β} ,其中,F(t)表示数据 y1:t中函数最小值。OP算法没有BS方法的求解效率高,于是PELT方法在OP算法的基础上增加了一个剪枝[8]过程,通过剪枝操作来提高运算效率,剪枝的本质是去掉每次迭代过程中不能起到减小F(t)作用的τ。
2 模拟研究
针对独立泊松分布和指数分布序列中的变点检测问题,分别应用AMOC、PELT、BS方法进行模拟实验并比较其效果,从而给出观察值序列服从两种不同分布下的方法选择建议。
2.1 研究设计
模拟数据分别来自独立泊松分布和独立指数分布。每种分布下分别设计观察值序列的样本量为1000、1500;当变点个数设计一个变点时,分布参数的变化范围为由3变为1,或由2变为0.5;当变点个数为两个时,分布参数的变化范围为由3变为1再变为3,或由2变为0.5再变为2;故共8种情境。每种模拟情境生成5组数据来进行重复实验。目标函数中分别采用AIC、BIC两种信息准则作惩罚项。研究中使用R Changepoint程序包的不同变点检测方法来检测泊松和指数分布中的变点。泊松分布与指数分布有一个共同的特点:均值参数和方差参数同时变化。因此使用均值方差变点命令cpt.meanvar进行检测。该程序包可以选择检测变点的惩罚项类型如AIC、BIC。
2.2 研究结果
模拟结果从以下角度分析:检测的变点数、变点位置、输出的负对数似然值的情况。影响结果的变量为观察值序列的样本量、变点个数、分布的参数、变点检测方法的选取、惩罚函数类型。用N表示样本个数,n表示变点个数,λ表示泊松或指数分布的参数。
2.2.1 泊松分布序列的变点检测结果
在表1中,数字代表正确识别的变点数,“-”代表变点个数为2时不再使用AMOC方法。作为判定变点检测效果的标准,此处着重考察每种方法得到的变点中,是否包含变点真值,即变点的准确位置。具体地,从检测到的变点中,首先选出距离真实变点最近的位置,再判定其是否距离真实变点在三个时间点以内;若是,则视为检测正确。由表1看出:当变点数为一个时,使用三种方法正确检测的变点数的均值相同,此时这三种方法没有太大差异。当变点数为两个时,PELT方法正确检测的变点数平均而言多于BS方法。比较两种惩罚类型,BIC惩罚下正确检测的变点数平均而言多于AIC惩罚。

表1 不同方法正确检测泊松分布序列变点的个数
由表2看出:从检测到的变点个数看,不管选取的样本量及参数如何变化,当真实情况存在一个变点时,显然AMOC检测的变点总数一定准确,而其他两种方法的变点数在使用AIC类型的惩罚项时均大于一个,使用BIC类型的惩罚项时表现较好。若样本量不同,其他条件相同,使用AIC惩罚项的PELT方法找出的变点数会随着样本量的增大而增大,而其他情况检测出的变点数量与样本量变化无关。当真实情况存在两个变点时,显然AMOC不再适用,使用AIC惩罚项的PELT方法找出的变点数会随着样本量的增大而增大。总体而言,针对惩罚类型选取的不同,BIC惩罚明显优于AIC惩罚下的变点识别效果。

表2 不同方法检测的泊松分布序列的变点总数
再从负对数似然值的大小来看(由于篇幅所限,不展示负对数似然值的表格):若检测变点的方法选取不同(不再考虑AMOC方法),使用AIC惩罚下的PELT方法有时会出现NAN的情况。针对不同的惩罚类型进行比较,BIC惩罚下负对数似然值小于AIC惩罚下的负对数似然值。
2.2.2 指数分布序列的变点检测结果
由表3,当变点数为一个时,使用三种检测方法正确检测变点的平均数相差不大,此时这三种方法没有太大差异。PELT方法相比于另两种方法正确检测的变点数略多。当变点数为两个时,比较BS方法和PELT方法,PELT方法正确检测的变点数的均值与BS方法无明显差异。BIC惩罚下正确检测的变点数平均而言与AIC惩罚相似。
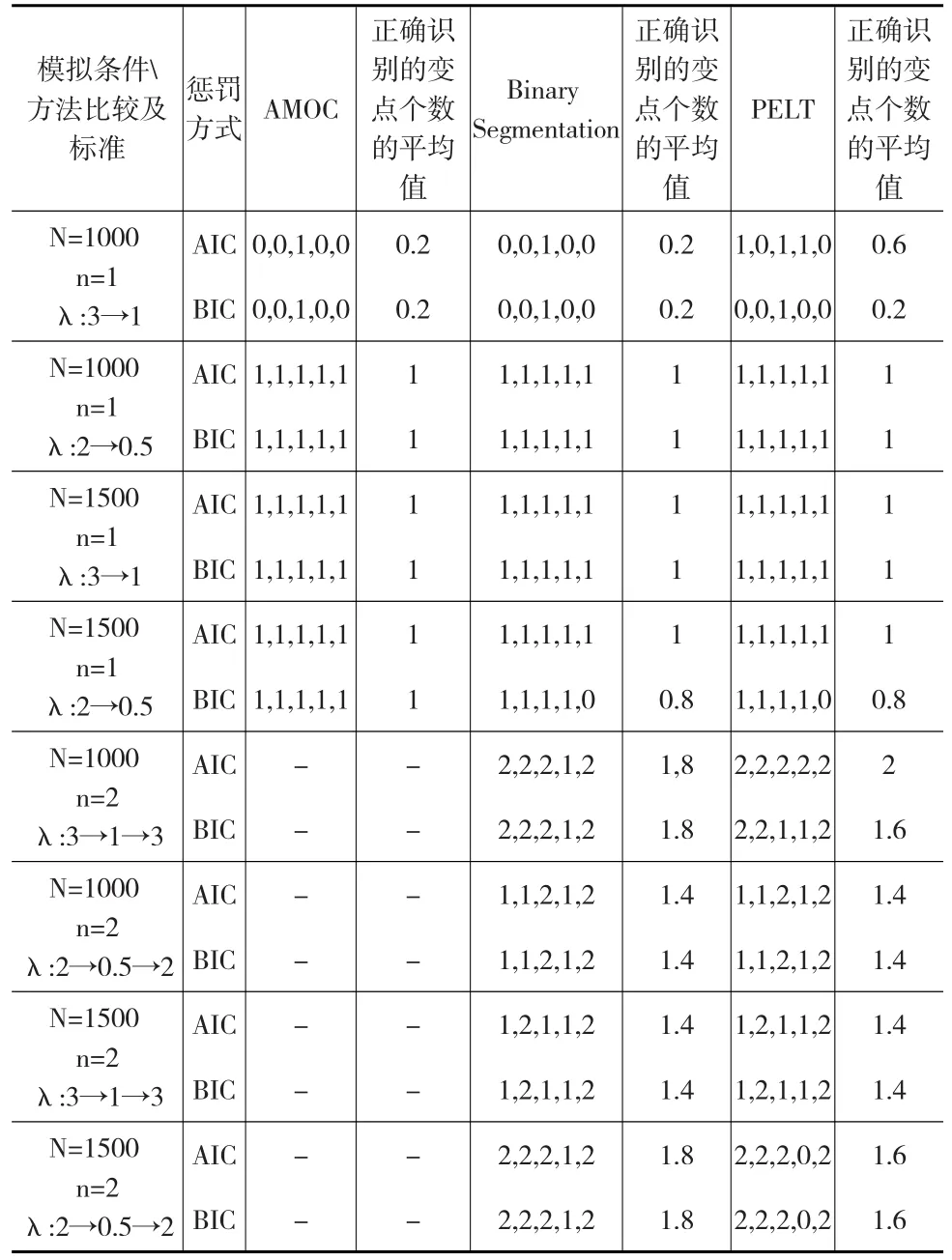
表3 不同方法正确检测指数分布序列变点的个数
由表4看出,类似于泊松序列的研究结果,当真实情况存在一个变点时,显然AMOC检测的变点总数一定准确,而其他两种方法的变点数在使用BIC惩罚项比AIC好。若样本量不同,其他条件相同,使用AIC惩罚项的PELT方法找出的变点数会随着样本量的增大而增大,而其他情况检测出的变点数量与样本量变化无关。当真实情况存在两个变点时,使用AIC惩罚项的PELT方法明显比BS方法差,但适用BIC惩罚时二者表现相似。
从负对数似然值的大小来看(由于篇幅所限,不展示负对数似然值的表格),N=1500时的负对数似然值要大于N=1000时的负对数似然值;若惩罚类型选取不同,其他变量均相同,使用PELT方法时,BIC惩罚下负对数似然值小于AIC惩罚下的负对数似然值;若使用BS方法,两种惩罚方式下负对数似然值相同。

表4 不同方法检测的指数分布序列的变点总数
3 实证
Carlin等(1992)[3]针对1851—1962年这 112年间英国每年发生煤矿灾难次数的数据,使用贝叶斯方法进行变点检测并找到一个变点k=41,其对应年份为1891年;每年发生矿难的平均数由1891年之前的3.10下降到1891年之后的0.90。图1为1852—1962年英国煤矿灾难每年的发生次数时序图。
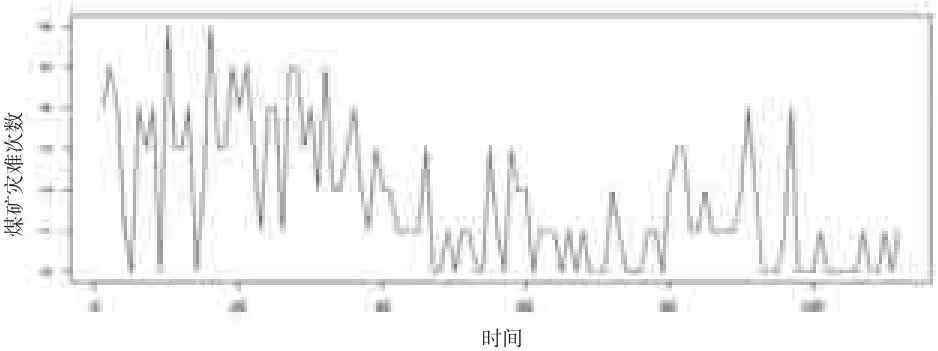
图1 1851—1962年英国每年发生煤矿灾难次数的时序图
根据该数据的产生背景,不妨假设序列中各随机变量相互独立并服从泊松分布。这里分别使用AMOC、BS和PELT方法分析该数据,观察不同检测变点方法及惩罚方式检测变点的效果,并与Carlin等(1992)的研究结果进行比较。由表5看出,AMOC方法可以较准确地检测到变点。PELT方法采用AIC惩罚时过于敏感,检测出的变点数较多;采用BIC惩罚时可以减轻这种情况。BS方法表现较好,适用BIC惩罚时比AIC惩罚表现更好。

表5 三种方法对英国矿难数据的变点检测结果
进一步,如果对BS方法约束检测到的变点个数为一个,BS方法检测到的变点也是准确的,结果见下页表6。

表6 约束BS方法仅检测一个变点的结果
4 结论
本文的研究得到以下结论:首先,对模拟研究,当观测值服从泊松分布且只有一个变点时,AMOC方法一定可以检测到准确的变点数量和位置,并且此时具有较小的负对数似然值,因此相对其他两种方法较优。若使用另外两种方法,最好选择BIC惩罚类型,不论从检测出的变点个数准确度或负对数似然值来看,使用BIC惩罚要优于使用AIC惩罚。相对而言,BS方法要优于PELT方法。当泊松序列中存在两个变点时,比较BS方法与PELT方法,看出两种方法均在BIC惩罚下可以得到较准确的变点数量和较小的负对数似然值。其次,指数分布的结果与泊松分布类似,当变点个数为一个时,使用AMOC方法可以检测到准确的变点位置,并且此时具有较小的负对数似然值,相对其他两种方法较优。当变点数为两个时,使用BS方法与BIC惩罚结合使用、PELT方法与BIC惩罚结合使用得到的结果是类似的。再有,通过对实证研究中的变点检测并与前人研究结果对比,发现AMOC、BS、PELT三种检测方法的检测效果优劣与模拟结果类似。总之,泊松序列或指数序列存在一个变点时,使用均值方差同时变化的AMOC方法相比另外两种方法更优;对存在两个变点的情况,BS或PELT结合BIC惩罚均较好,前者略优于后者。本文的结果对于泊松和指数分布序列如何选择三种方法来检测变点具有较好的指导意义,未来研究还可探索对随机变量序列服从其他分布类型时上述三种方法的变点检测效果的比较。
