中文嵌套命名实体识别语料库的构建
2018-09-18李雁群何云琪钱龙华周国栋
李雁群,何云琪,钱龙华,周国栋
(1. 苏州大学 自然语言处理实验室,江苏 苏州 215006; 2. 苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
信息抽取的目的是从无结构文本中抽取出实体及其相互关系并转化为结构化表达形式,从而为知识库的构造提供数据基础[1-5]。嵌套命名实体中含有丰富的实体信息以及实体之间的相互关系,其结构相对而言也较为简单,因而嵌套命名实体的识别成为信息抽取中值得研究的话题之一。
目前的嵌套命名实体识别都采用有监督的机器学习方法,因而需要一定规模的语料库。GENIAV3.02[6]是生物医学领域内的命名实体语料库,其中包含了嵌套实体,被广泛应用于生物医学领域的命名实体识别研究。该语料库包含2 000条MEDLLINE摘要,94 014个实体引用,其中约有17%的实体嵌套在其他实体中。EPPI[7]是生物医学领域内另一个标注了蛋白质及其相互作用关系的语料库,它包含217个从PubMed和PubMedCentral选出来的摘要和全文文献,总共有134 059个实体引用。RCAHMS[8]是一个标注实体及其语义关系的历史档案语料库,包含1 546个文本,28 272个实体引用,其中18.7%的实体嵌套在其他实体中。
中文方面没有被广泛认可的嵌套命名实体语料库,中文命名实体语料有来源广泛的MSRA语料、新闻领域的1998年1月的 《人民日报》语料和多领域的ACE2005中文语料,因为《人民日报》语料和ACE2005中文语料包含嵌套命名实体的标注信息,所以中文嵌套实体识别研究大都基于《人民日报》语料[9-11]和ACE2005中文语料[12],但是这些标注信息并不完整,存在漏标问题,如“[中共中央/nt 台湾/ns 工作/vn 办公室/n]nt”转换为嵌套结构为“[[中共中央]nt [台湾]ns 工作办公室]nt”[注]嵌套实体的类型标注采用《人民日报》语料的格式,即nr表示人名,ns表示地名,nt表示组织名。,漏标了“[中共]nt”这个实体。本文提出用半自动的方法构建完善的中文嵌套命名实体识别语料库,该方法首先自动抽取嵌套命名实体,然后人工调整自动标注的嵌套命名实体。
1 相关工作
目前的中文嵌套命名实体识别的研究少有考虑嵌套命名实体语料库的构建,主要侧重于方法的研究。嵌套实体识别方法主要分为基于规则的方法和基于机器学习的方法。最初的方法是在识别最外层实体的基础上采用基于规则的后处理方法识别嵌套实体[13-14]。基于机器学习的方法大都采用层次模型,即将嵌套实体的识别转换成多个层次的序列标注问题[7-8,11]。与序列化标注方法不同,Finkel和Manning[15]采用判别式成分句法分析器来训练嵌套命名实体识别模型。该方法把每个句子转换成一棵句法分析树,其中每一个词均作为该树的叶子节点,而每个实体作为该树的子树。其优点是树的表示方法可以清晰地表示任意层数的嵌套实体。
中文嵌套命名实体识别的研究都是在《人民日报》语料和ACE2005中文语料上进行的,前者大都采用层次化模型,后者采用层次标号的方法在分词的基础上进行多层嵌套实体提及的识别[12]。然而在这些语料上进行嵌套命名实体识别时,语料都是自动生成的,并没有人工校验的过程,语料的质量得不到保证,而且这些语料的领域较单一。因此本文提出构建一个完善的嵌套命名实体识别语料库,并将其发布出去。
2 嵌套命名实体识别语料库构建.
2.1 嵌套命名实体定义
根据命名实体中是否包含其他实体,将命名实体分为简单命名实体和嵌套命名实体。简单命名实体是由一个词或多个词构成的实体,它的内部不包含其他的命名实体。嵌套命名实体是指实体内部嵌套一个或多个简单命名实体的命名实体,该类型的命名实体主要存在于地名和机构名中。嵌套在里面的实体称为内部实体,最外层的实体称为外部实体。如外部实体“[[[中共]nt [北京]ns 市委]nt 宣传部]nt”包含“[中共]nt”、“[北京]ns”和“[中共北京市委]nt”等三个内部实体。
2.2 语料库构建
目前中文命名实体识别中常用的语料有《人民日报》语料[16]、微软语料[17]和ACE2005中文语料[18-19],其中《人民日报》语料和ACE2005中文语料含有嵌套命名实体的标注信息。因此,为了减少标注工作量,我们把《人民日报》语料和ACE2005中文语料作为嵌套命名实体语料。《人民日报》语料规模较大,但是来源单一。该语料属于新闻领域,语料整体比较正规,都是严格的命名实体,人名都是简单命名实体。ACE2005中文语料虽规模较小,但来源多样。
我们定义嵌套实体的出发点是尽可能地挖掘出更多的实体以及实体之间的语义关系,因此比《人民日报》和ACE2005定义了更细粒度和更多层次的嵌套实体结构。《人民日报》定义的嵌套实体都是两层的,即只标注了外部实体中嵌套的最底层内部实体,如嵌套实体“[中共/j 北京/ns 市委/n 宣传部/n]nt”,而我们所定义的嵌套实体要求包含所有嵌套层次的内部实体。ACE2005中文语料中的实体是指一个不能再划分的完整概念,因此理论上说一个实体不能再包含另一个实体,如实体“[西安飞机工业公司]nt”中的“西安”并没有标注,不过ACE通过实体的中心词和外延来指明每个实体的覆盖范围。
2.2.1 《人民日报》语料人工标注
该语料只标注了二层嵌套结构,且都是命名实体。如嵌套实体“[中共/j 北京/ns 市委/n 宣传部/n]nt”不能满足我们对嵌套实体的定义,其正确的标注应该是“[[[中共]nt [北京]ns 市委]nt 宣传部]nt”。
本文采用自动抽取加人工调整的方式来产生中文嵌套实体识别语料,同时为了减少重复标注,我们只对实体而非一个实体的多个引用进行标注,具体过程为:
(1) 自动抽取: 从1998年1月的《人民日报》语料中抽取出复杂命名实体,并去除重复的实体引用,保留其中的命名实体标注。如实体“[中共/j 北京/ns 市委/n 宣传部/n]nt”提取后变成实体“[中共 [北京]ns 市委宣传部]nt”。
(2) 人工调整: 人工标注提取出的嵌套实体,通常是添加新的内部实体。如第(1)步中的实体“[中共 [北京]ns 市委宣传部]nt” 经人工调整后为“[[[中共]nt [北京]ns 市委]nt 宣传部]nt”。
2.2.2 ACE2005中文语料人工标注
作为中文信息抽取的基准语料,ACE2005中文语料库被广泛应用于命名实体识别和关系抽取,它定义了七个大类(包括人物、组织、地理政治、处所、设施、车辆和武器)的实体,涉及广播新闻、新闻专线和博客等多个领域,因而可作为潜在的中文嵌套实体语料库。
ACE2005中文语料库并没有直接定义嵌套实体,而是定义了一个实体的中心词(headword)和外延(extension)。所谓实体中心词就是常规意义上的实体指称(mention),而实体外延则是指包含这个实体修饰语的最小名词短语。如短语“[内蒙古]ns [歌舞团]nt”中包含两个实体,而第二个实体的外延则包含了第一个实体,因此可以利用这种特点来生成初始的可选嵌套实体,具体流程如下:
(1) 选出ACE2005中文语料库中指称类型为“NAM”的实体,即命名实体。ACE定义了三种类型的实体指称,即NAM(名称)、NOM(名词)和PRO(代词),命名实体指第一种,因此过滤后两种的类型。
(2) 对于语料文本的每一句中的所有命名实体,如果一个实体的外延包含另一个实体的外延,且第一个实体的中心词紧跟第二个实体的中心词,则第一个实体包含第二个实体。以此类推,第二个实体可以包含第三个实体。
(3) 产生多层嵌套的实体,并把类型为地理政治实体、处所和设施的实体转换为地名类型。如果嵌套实体原来都是地理政治实体,则把它们分成多个独立的不嵌套实体。如“[西藏]ns [达孜县]ns”,尽管ACE定义为嵌套实体,但我们不认为连续的多层地名为嵌套实体。
根据上述处理流程,我们得到了一个初始的嵌套实体列表,但这个列表里面仍然存在漏标问题。如上文提到的实体“[西安飞机工业公司]nt”,ACE2005并没有标出其中的内部实体“[西安]ns”。因此我们进一步人工标注,以得到较高质量的中文嵌套实体语料库。
2.2.3 语料库一致性检验
为了衡量语料库标注的一致性,我们安排了两名志愿者同时进行标注。标注分两个阶段进行,第一个阶段两名志愿者经过初步培训后对语料库进行标注,然后比较他们之间的差异,重新调整标注要求,再进行第二个阶段的标注调整,调整结束后计算最终一致性。在一致性检验时,以一个志愿者的标注为标准集,另一个志愿者的标注为预测集,采用常规的P/R/F1指数来评估嵌套命名实体语料库标注的一致性,其中P为准确率,R为召回率,F1为两者的调和平均值。
以《人民日报》为例,第一阶段标注的一致性结果:P为92.50%,R为93.43%,F1为92.96%。两名志愿者的差异主要体现在对地名的嵌套结构理解不一致。第二阶段标注后的一致性结果:P为99.24%,R为99.31%,F1为99.29%。由此可见,经过适当的调整,嵌套实体的标注一致性非常高。
2.3 语料库统计
2.3.1 《人民日报》嵌套实体统计
标注后的《人民日报》中所有实体统计情况如表1所示,实体分为外部实体和内部实体,外部实体还可分为无嵌套和有嵌套两种。从表中可以看出,内部实体约占所有实体的14%。另外:
(1) 无嵌套结构的外部实体中,大部分是地名(~47%)和人名(~43%),再加少量的组织名(~10%),如“[中国]ns”“[邓小平]nr”“[联合国]nt”。
(2) 有嵌套结构的外部实体中,绝大部分是组织名(~90%),再加少量的地名(~10%);如“[[上海市]ns 红十字会]nt”中的“[上海市红十字会]nt”,“[[北京]ns 圆山大酒店]ns”中的“[北京圆山大酒店]ns”。
(3) 内部实体的组成大部分是地名(~75%),小部分是组织名(~24%),还有极少数是人名(~1%),如“[[上海市]ns 红十字会]nt”中的“[上海市]ns”,“[[北京]ns 圆山大酒店]ns”中的“[北京]ns”,“[[[华南]ns 师范大学]nt 函授学院]nt”中的“[华南]ns”和“[华南师范大学]nt”。
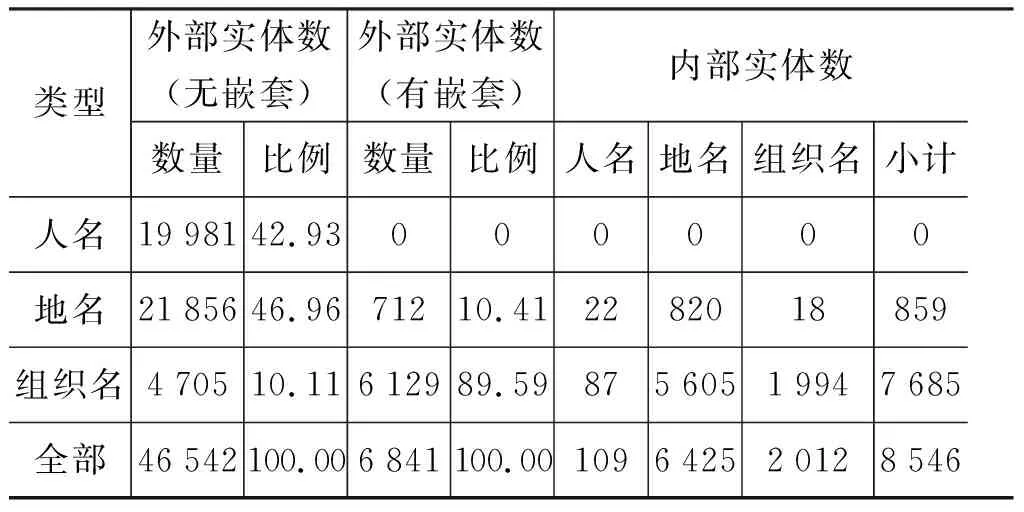
表1 《人民日报》语料嵌套实体统计
2.3.2 ACE2005中文语料嵌套实体统计
标注后的ACE2005中文语料中所有实体统计情况如表2所示。其中,内部实体约占所有实体的11%,略低于《人民日报》中的比例,从表中还可以看出:
(1) 无嵌套结构的外部实体中的组成与《人民日报》差别不大,大部分是地名(~52%)和人名(~30%),再加少量的组织名(~18%)。
(2) 与《人民日报》有所不同,有嵌套结构的外部实体中组织名只占到约76%,低于《人民日报》中的比例(~90%);而内部实体中的绝大部分是地名(~90%),高于《人民日报》中的比例(~75%)。
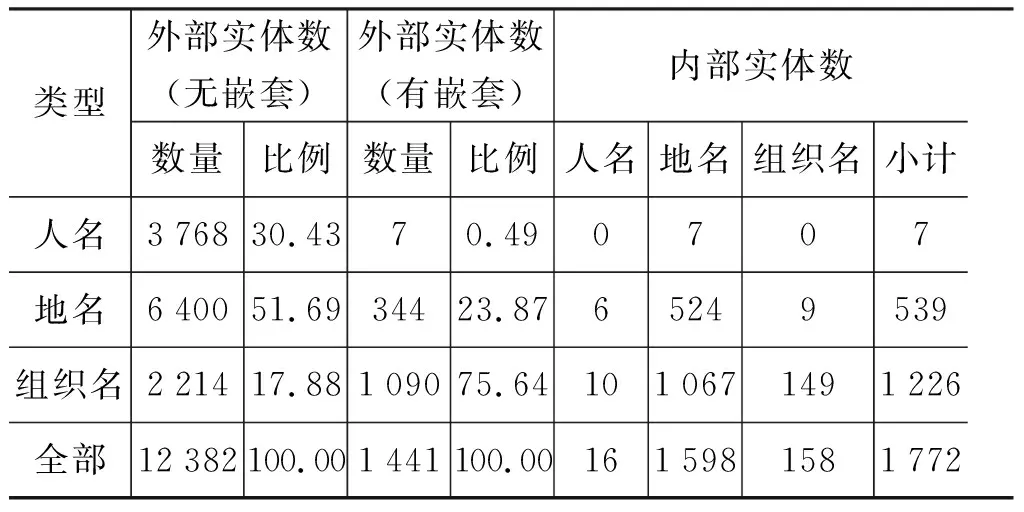
表2 ACE2005中文语料嵌套实体统计
2.3.3 ACE2005中文语料的领域分析
《人民日报》的内容来源于人民日报社,体裁均为新闻,而ACE2005中文语料内容来源于国内外多个媒体机构,体裁有新闻、广播和网络日志等,因此领域更加宽泛。其中各个领域的嵌套命名实体统计情况如表3所示。
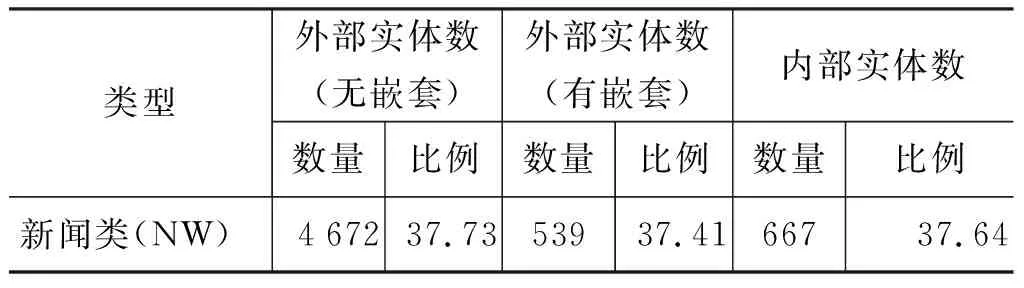
表3 ACE2005中文语料各领域的嵌套实体统计
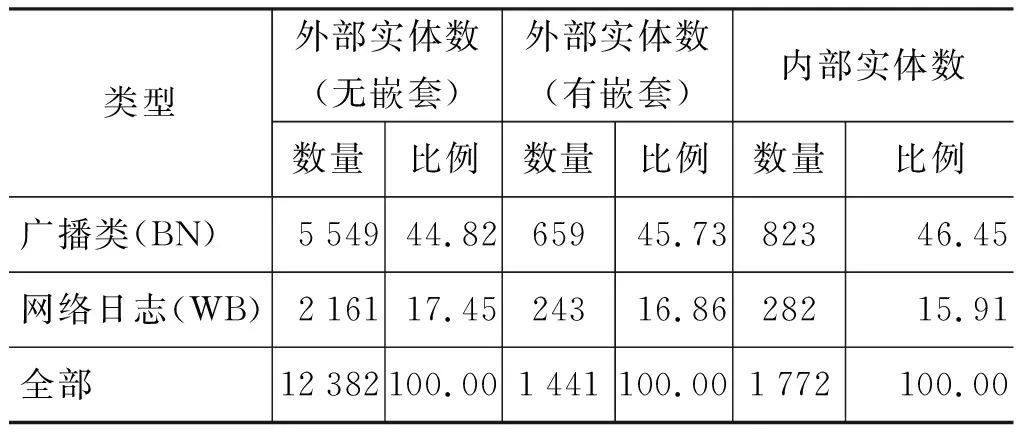
续表
3 实验评估
为了评估所构建的中文嵌套命名实体语料库的特点,首先设计了嵌套命名实体识别的三种方法及所用的模型和特征,然后通过实验比较了三种识别模型的性能,分析了嵌套实体识别的错误类型,并且将构建的新语料与旧语料进行对比分析,最后,在《人民日报》和ACE2005中文语料上进行了跨语料测试分析。
3.1 实验方法
3.1.1 嵌套命名实体识别方法
目前,有关中文嵌套命名实体识别的研究相对较少,本文采用基于机器学习的层次标记和层叠模型等两大类方法来识别嵌套命名实体。
(1) 标签层次化,即扩充一个词的标签,使它反映出该词所参与的所有实体类型,然后用一个序列化标注模型来识别,该方法也可以叫联合标签[7]。
(2) 模型层次化,即采用多个叠加的序列化标注模型,每一层嵌套的实体识别都转化为单独的实体识别问题,识别的顺序可以分为两种: 由内到外和由外到内。由内到外指第一个序列化模型首先识别出基本实体,然后再用第二个模型识别出由第一层实体组成的实体,以此类推。由外到内指第一个序列化模型首先识别出最外层的实体,然后再用第二个模型识别出第一层实体中嵌套的实体,以此类推[7]。
表4 列出了嵌套实体“[[[中共]nt [北京]ns 市委]nt宣传部]nt”在以上模型中的层次标签。
3.1.2 CRF特征
以往的中文命名实体识别研究表明[20],以字为单位的CRF模型在资源最少(即不进行分词)的情况下能取得较好的识别性能,因此本文也采用CRF模型。本文没有增加额外特征,只采用了最基本的上下文特征,具体如下:
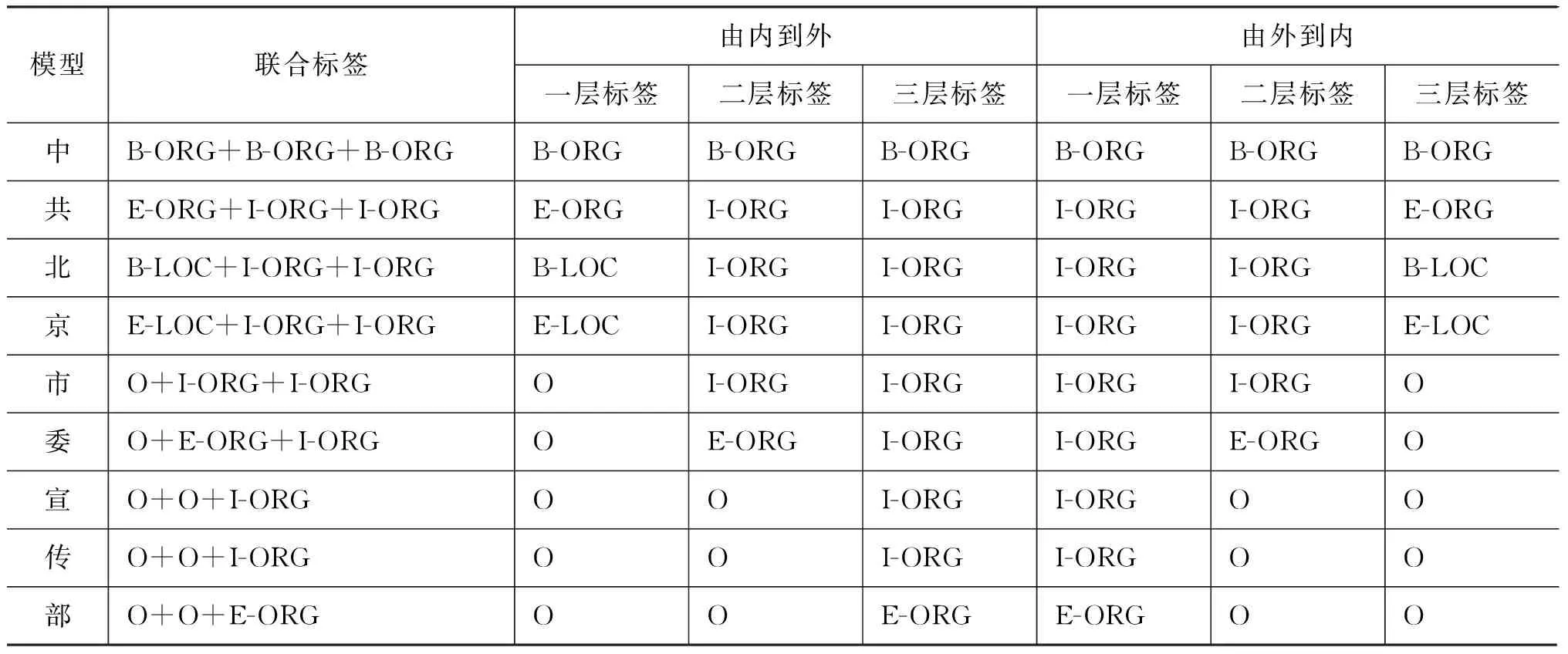
表4 各个模型的层次化标签表示样例
Cn(n= -2, -1, 0, 1, 2)
CnCn+1(n= -1 ,0)
其中C0代表当前的字,Cn代表当前位置之后第n位的字,CnCn+1代表第n位及其下一个字的组合。例如,对于序列“中华人民共和国”来说,当以字为单位时,若C0为“人”,则C1代表“民”,C-1代表“华”,而C0C1代表“人民”。
需要说明的是,训练第一层模型时只有字特征,而训练多层模型时除包含字特征外,还包含所有下层的标签作为特征,而在测试时多层模型选用下层识别的结果作为其特征。
3.1.3 评估方法
我们采用常规的P/R/F1指数来评估实体识别的性能。为了减少评估性能的偏差,我们和其他《人民日报》语料上的研究工作一样[10],采用十折交叉方法,即将所有语料按顺序划分为十份,其中一份作为测试集,另外九份作为训练集,总体性能取十次结果的平均值。
3.2 实验结果
3.2.1 三种嵌套实体识别模型的交叉验证性能
表5列出了在《人民日报》语料上分别用联合标签、由内到外和由外到内三种嵌套实体识别模型来进行嵌套实体识别的交叉验证性能,同时列出了外部实体、内部实体以及全部实体各自识别的性能,表5的结果每一列最高性能需要用粗体表示。外部实体包含上述所说的无嵌套结构和有嵌套结构的外部实体,这就是我们通常所说的不考虑嵌套实体的命名实体(即无嵌套命名实体),内部实体即嵌套在外部实体内的内部实体(即嵌套命名实体)。从表中可以看出:
(1) 外部实体、内部实体、全部实体都是由内到外的模型性能最好,全部实体F1值达到了约90%;
(2) 联合标签的全部实体F1值虽只比由内到外模型低0.24%,但是联合标签模型生成的时间非常长,大概是由内到外模型的40倍以上;
(3) 由外到内模型的性能相对而言较低,比由内到外模型的全部实体F1值低了2.5%,但这个模型的优点是训练内部实体时不需要上下文,因而可以利用外部资源来获得嵌套实体语料。
综上所述,由内到外模型的实体识别F1值最高,且模型训练时间也短,因此接下来的实验都是采用该模型。

表5 《人民日报》语料上各模型的实体识别性能
3.2.2 由内到外模型的各个实体类别性能
表6 列出了嵌套实体识别取得最好性能的由内到外模型在各个实体类别上的性能(表6的结果每一列最高性能需要用粗体表示)。从表中可以看出:
(1) 地名、组织名、人名识别的性能与其实体数目密切相关,数目越多,性能越好。地名数量最多,因此F值最高,人名数量次之,组织名数量最少。
(2) 内部实体识别性能显著低于外部实体识别性能,F值相差约10%,这主要是由于训练实例数量少而引起的。这说明与无嵌套命名实体识别相比,嵌套命名实体的识别仍存在困难。
为了进行错误分析,我们随机抽出内部实体识别错误的100个例子,错误情况如下:
(1) 大部分(80%)内部实体识别错误是由于该实体在语料中出现很少,因而这类实体较难识别出来。例如,“[[柳林]ns 电厂]ns”识别成了“[柳林电厂]ns”,漏掉了“[柳林]ns”这个实体。
(2) 少部分(20%)内部实体由于上下文的误导,导致实体识别错误,例如,“[[河北省]ns [张家口地区]ns ]ns”识别成了“[[河北省]ns [张家口]ns地区]ns”,这是因为语料中“地区”有时和前面的地名构成一个整体,有时又独立。

表6 《人民日报》语料上分类型的实体识别性能
3.2.3 人工语料和自动语料的性能对比
为了说明人工构建的嵌套命名实体语料库的优势,我们把自动抽取后生成的嵌套命名实体语料和人工调整后的语料进行嵌套命名实体识别对比实验。这实际上可以看作是一个语料的两种标注,即自动标注和人工标注。据统计,与人工标注语料相比,自动标注语料的内部实体漏掉了约48%,其中组织名漏掉了90%,人名漏掉了36%,地名漏掉了35%。实验仍采用十折交叉验证,自动标注部分作为训练集,人工标注部分作为测试集。表7列出了《人民日报》语料上各个实体类别上的嵌套实体识别性能。从表中可以看出:
(1) 与表6(人工标注语料)相比,表7的外部实体识别性能F1值略有下降(~2%),而内部实体识别F1值则大幅度下降(~16%)。这主要是因为自动抽取漏掉很多内部实体(~48%),而外部实体并没有减少。
(2) 与表6实验结果相比,在表7的内部实体识别性能F1值中,组织名下降最多(~54%),地名次之(~12%),人名最少(~9%)。这主要是因为《人民日报》标注的内部实体中的组织名大多数由多个词语组成,所以漏掉了大部分的组织名(~90%),而人名和地名漏掉的相对较少(分别为~36%和35%)。

表7 《人民日报》自动抽取语料上的实体识别性能
3.2.4 跨语料测试
为了对比《人民日报》语料和ACE2005中文语料之间的嵌套实体识别性能,我们进行了跨语料测试。因为《人民日报》实体数量是ACE2005中文语料的四倍,为了公平比较两个语料的差异,我们取《人民日报》语料的四分之一。实验包含两个部分,一是交叉验证,即分别在《人民日报》语料和ACE2005中文语料上进行十折交叉验证;二是跨语料测试,即一个语料交叉验证时,划出的九份作为训练集,另一个语料作为测试集。实验结果如表8所示。
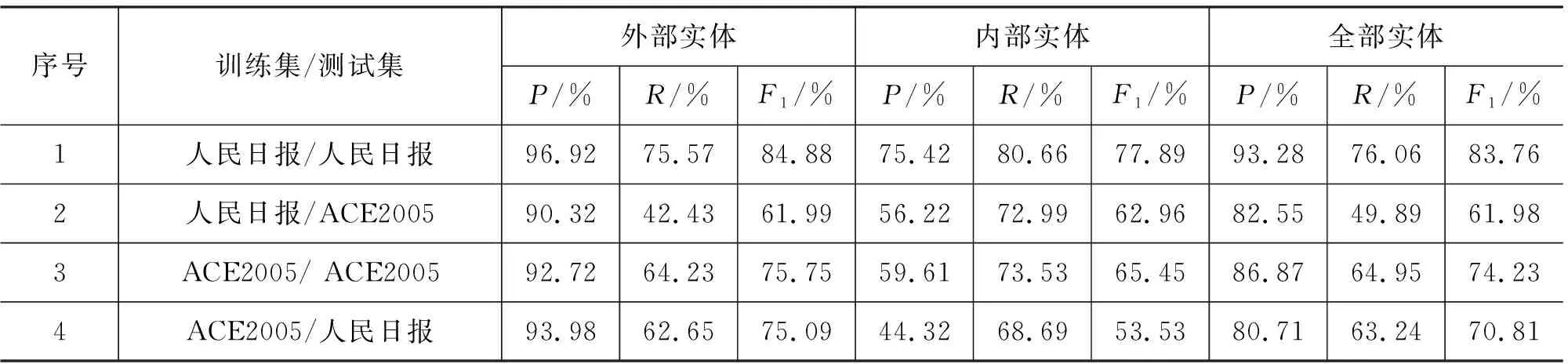
表8 跨语料实体识别性能
从表8可以看出,语料内交叉验证性能总体上明显高于跨语料测试性能,但《人民日报》和ACE2005两个语料的情况不尽相同。
(1) 分析实验1和实验3的差异
尽管语料规模相同,但无论是外部实体还是内部实体,《人民日报》的P/R/F1性能普遍高于ACE2005的性能,原因可能有以下几点:
① 两者领域来源不同,《人民日报》语料来源于单一的新闻领域,而ACE2005中文语料来源于广播、新闻和网络日志等。ACE2005文本的多样性导致性能较低;
② ACE2005中文语料存在约10%缩写型实体,如“中科院/nt”、“二汽/nt”和“亚/ns”等,缩写型实体训练数量较少,导致难于识别,而《人民日报》没有缩写型实体(缩写都是用“j”标注的)。
③ ACE2005中文语料中存在约2%的英文实体,如“VladimirPutin/nr”“Aceh/ns”“BaFin/nt”和“a/nr 小姐”等。
(2) 分析实验2和实验3的差异
实验2的内部实体F1值(62.96%)略高于外部实体性能(61.99%)。这是因为尽管ACE2005中文语料外部实体标注与《人民日报》不一致(参见上面分析),但是内部实体(即嵌套实体)标注基本一致,因而实验2的内部实体性能略低于实验3的内部实体性能(~2%),甚至略高于实验2的外部实体性能。
(3) 分析实验3和实验4的差异
ACE2005跨语料外部实体性能和语料内交叉验证性能相似。当ACE2005中文语料作为训练集时,所产生模型的交叉验证性能并不高,但由于ACE2005中的新闻类语料(~40%)和《人民日报》语料相似,所以该模型在《人民日报》测试集上的性能并没有明显降低。
4 总结
针对中文嵌套命名实体语料库不足的问题,本文通过半自动的标注方法构建了两个中文嵌套命名实体语料库。这两个语料库各有千秋,在《人民日报》语料上构建的语料库虽然领域较为单一,但规模较大,可以用于领域内的中文嵌套实体识别研究;而在ACE2005基础上构建的语料虽规模较小,但领域来源多样,适合于跨领域的中文嵌套实体识别研究。
语料内的交叉验证和跨语料的嵌套命名实体识别实验结果表明,中文嵌套实体识别的性能还偏低,尤其是跨语料识别时。
今后的工作在于: 一方面如何提高中文嵌套实体识别的性能;另一方面如何利用目前的资源(如维基百科等)生成规模更大的中文嵌套语料库,从而提供更宽泛的领域适应性。
