迁移人口规模估计中多维自适应计算模型的应用与构建
——基于甘肃省普查数据的研究
2018-08-29郭志仪刘红亮
郭志仪,刘红亮,2
(1.兰州大学经济学院,兰州730000;2.甘肃省卫生计生统计信息中心,兰州730000)
一、引言与数据来源
宏观地看,人口统计数据具有结构性特点,在较短时期内,这种结构性特点具有较为稳定的特征。在人口统计数据中,人口的稳定性结构特点最为明显的是人口死亡率统计数据。一般情况下,排除大的自然灾害和战争等非个体可控因素后,在一定时期内可以认为人口死亡率具有较为稳定的线性特征。基于这种认识,可以通过1990年、2000年和2010年三次人口普查数据中的1岁组人口和死亡率数据,利用线性回归方法,构造分龄组人口死亡率变动函数①0岁~100岁及以上,每年龄组一个回归函数,每组共有101个回归函数,对1978年到2009年间的推算共需建立四组合计404个回归函数。,通过人口死亡率函数反向推演,可以得到各历史年度的1岁组人口年龄结构数据,对其求和,可以得到该年度各年龄组按照该死亡率计算的应有人口数,再与根据统计公报公布的该年人口统计数据推算的分龄组人口数相比较,其无法用人口死亡来解释的差额部分,可作为该年龄组的迁移流动人口规模的估计值。采用这种办法计算时,假设死亡率具有稳定的特点,因而计算的误差较多地集中在对0岁组人口规模的估计上,若再用历年公布的人口出生率对这一误差做修正,就可较大幅度地减少估计误差,提高总体估计精度。在理想情况下,可以针对某一区域内特定时期的人口变动情况,构建具有区域特点的多维区域人口发展模型,基于这一模型,就可以比较科学地对人口发展过程做出较为客观的评价,为相关人口相关政策的制定和决策提供依据。
本研究使用的基础数据分别来自第四、五和第六次中国人口普查资料中甘肃省人口年龄结构部分和人口死亡部分的1岁组数据,1990年,2000年和2010年甘肃省跨省迁移流动人口数据分别来自《中国1990年人口普查资料》[1]、《中国2000年人口普查资料》[2]、《中国2010年人口普查资料》[3]。
二、计算模型构建
(一)分龄组死亡率变动函数
为了较好地反映死亡率在一定时期内较为稳定的特点,分龄组死亡率函数变动模型假设为线性函数,其函数形式为:
其中Dyi为第y年度i岁组死亡率的估计值,Ayi为线性估计函数的斜率,dyi为y年i岁组死亡率的普查值,Byi为 Y 轴截距。(1)式用来估计 2001~2009年各年龄组死亡率,X轴i参数取序数1,2;(2)式用来估计1991~1999年各年龄组死亡率,X轴i参数取序数1,2;(3)式用来估计1981~1989年各年龄组死亡率,X轴i参数取序数1,2,3;(4)式用来估计1971~1979年各年龄组死亡率,X轴i参数取序数1,2,3,4。当输入参数每年度分龄组死亡率dyi已知时,利用最小二乘法,就可以解得各分龄组估计函数的参数Ayi和Byi:
在实际推算中,利用计算机辅助计算办法,建立最小二乘法函数,输入参数为普查年度某一分龄组的历次普查死亡率,输出参数第一项为Ayi,第二项为Byi,其中Byi为推算年的死亡率初次估计值,为了让死亡率的变动能够符合总人口规模的变动,需要对分龄组死亡率进行多次调整,为了便于区别和说明,将初次计算的分龄组死亡率的估计值叫做分龄组死亡率原始估计值,按照分龄组死亡率原始估计值推算的分龄组人口数叫做初算分龄组人口数。
(二)建立1978~2010年间各年度分龄组死亡率估计值序列
根据(1)~(6)计算结果建立的各分龄组回归函数,利用死亡率计算通式:

分别计算各年度的分龄组死亡率原始估计值。其中1978~1979年间死亡率估计值需要完成1980年分龄组人口及分龄组死亡率计算后才能进行。实际计算时由于1970~1980年,1980~1990年,1990~2000年,2000~2010年Ayi和Byi是分别计算的,需要对y参数做从1到2,步进为0.1的参数变换,其中计算1978年和1979年各分龄组死亡率时,y参数分别为1.8和1.9。经过计算,关键年份1980年计算结果如表1。
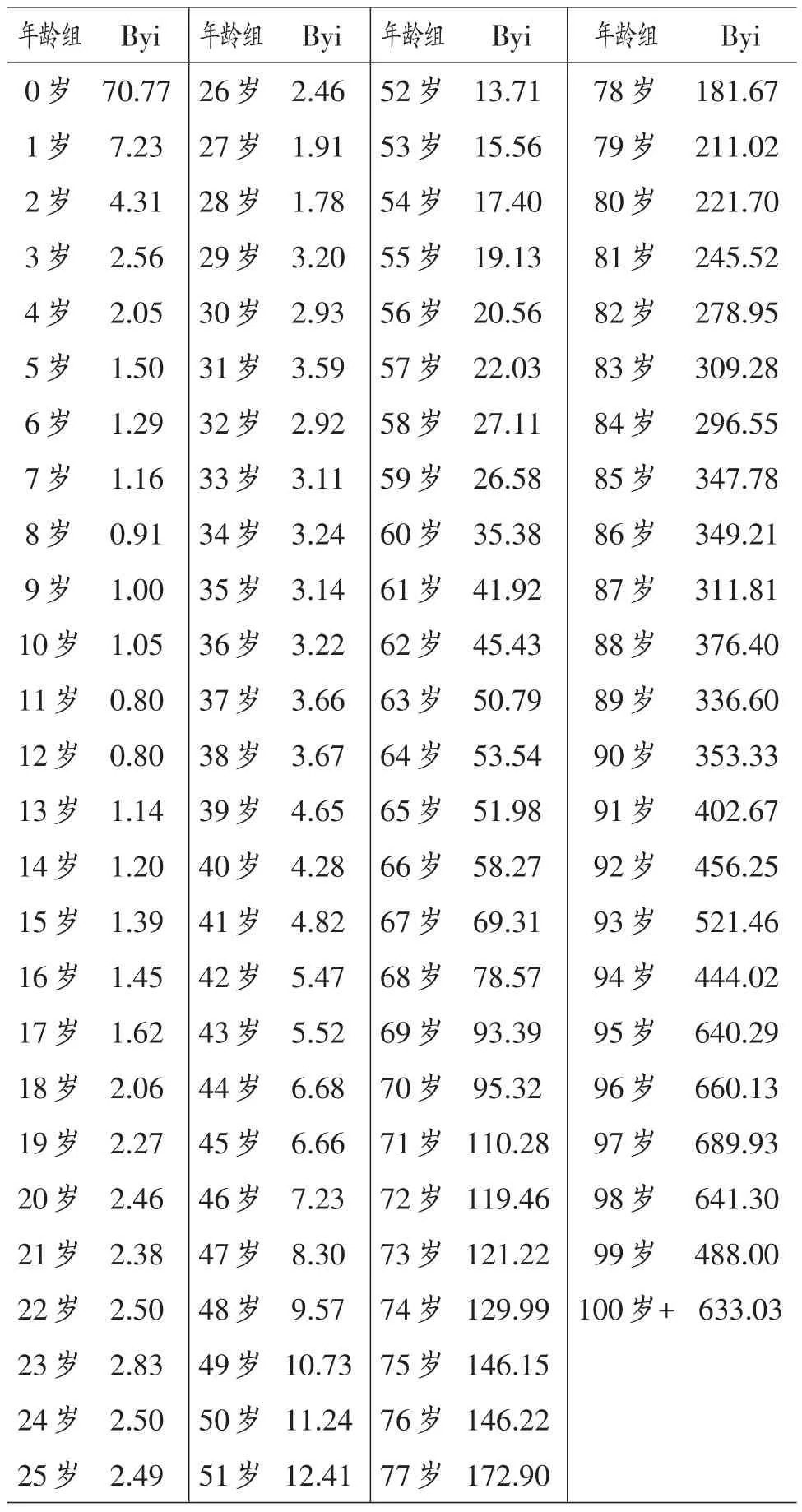
表1 1980年各年龄组人口死亡率原始估计值
(三)建立历年总人口控制变量Py
查询历年统计资料,建立1978~2010年各年度甘肃省总人口的统计公报数,作为总人口输入控制变量(表2)。

表2 甘肃省1978~2010年人口数 单位:万人
(四)2009年开始逐年推算各年龄组人口数和死亡率
根据1978~2009年历年人口规模数和各年份分龄组死亡率原始估计值,从2009年开始逐年推算各年龄组人口数和死亡率。在推算过程中,需要对分龄组死亡率原始估计值进行多次调整,调整办法采取等比调整办法,其约束条件是经过多次调整后,各分龄组人口总数等于推算年人口总数。具体分六个步骤完成,为了便于说明,以下步骤以2009年分龄组人口推算为例:
1.根据2010年分龄组人口数和推算的2009年分龄组死亡率原始估计值计算2009年各年龄组应有人口数。
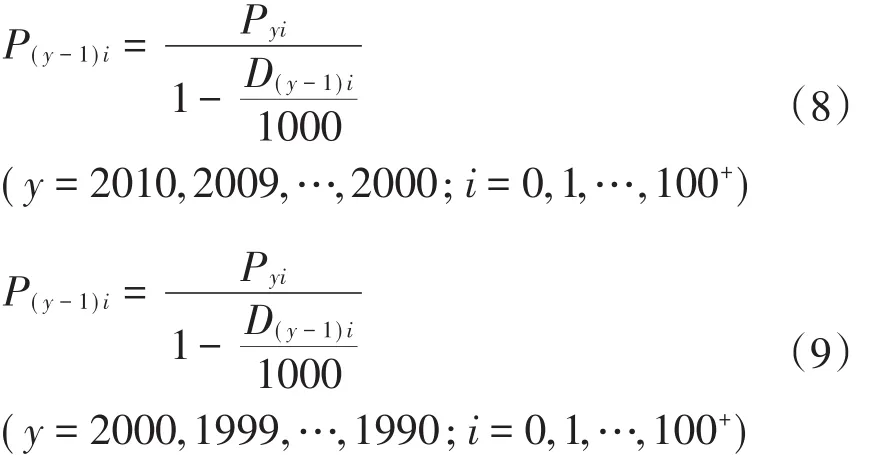

其中P(y-1)i是按照分龄组死亡率原始估计值和调整后死亡率估计值计算的(y-1)年i岁组人口数,意义是(y-1)年i岁组人口数等于y年(i+1)岁组人口数加上y年(i)岁组死亡人口数。其推理依据是,(y-1)年i分龄组人口数减去其死亡人口数应该等于y年(i+1)分龄组人口数。这里假设不能被死亡率解释的人口规模全部为迁移流动人口Lyi,在实际计算中,为了计算方便,假定迁移人口和总人口具有同样的年龄结构特点。式(8)~(11)分别为2000~2009年,1990~1999年,1980~1989年和1978~1979年分龄组人口计算函数。
2.根据2009年各分龄组应有人口数及分龄组死亡率原始估计值计算各年龄组死亡人口数。

3.根据2009年统计公报人口总数减去推算的各年龄组应有人口数的差,除以各年龄组死亡人口总数,得到死亡率初次调整种子调整系数。
4.根据种子调整系数计算调整后各年龄组死亡率。

5.根据2010年各年龄组人口数和调整后各年龄组死亡率再次计算按照调整后分龄组死亡率计算的各分龄组人口数,重复(2)~(5)的计算步骤,直到根据调整后死亡率计算的2009年各分龄组人口数的与统计公报人口数完全相等。在实际计算中,采用种子调整系数累加的办法①由于累加时模型会自动根据各分龄组人口数的正负情况对种子调整系数做加减调整,直到其结果符合精度要求,因而将本计算模型称为自适应计算模型。实际计算时为了避免多次迭代无解模型不能退出的情况,设定最大迭代次数为10,也就是连续迭代10次后,仍不能满足精度要求,则将不能解释的部分归并为迁移流动人口,其最后一次计算结果,作为该年度推算结果。。手工计算时复算次数一般为1~5次。计算机辅助计算时,人口个案精确到±1人。对于以万人表示人口的数据,为了避免四舍五入进位误差,对末尾两位可以采取补0或添加0~49随机数办法解决。

6.将最后一次计算的分龄组死亡率作为2009年各分龄组死亡率的推算值,采取分龄组求和的办法重新计算2009年总人口死亡率。并将2009年各分龄组人口数作为推算2008年各分龄组人口数的基础。
(五)以前一年度分龄组人口数为基础,逐年递减推算2008~2000年,1999~1990年,1989~1980年和1979~1978年各年份分龄组人口数。
(六)根据初次推算的历年人口年龄结构数据减去按照调整后死亡率计算的分龄组人口数的差,作为迁移流动人口数的估计值Lyi。

表3 甘肃省1978~1990年间三个主要年份分龄组人口数 单位:‰,万人

式中pyi为分龄组人口初算值,p′yi为根据调整后死亡率计算的分龄组人口数。
三、计算结果
根据上述计算办法,建立计算机速算模型,输入参数为1990年、2000年和2010年各分龄组人口数和分龄组死亡率,1970~2010年各年度总人口规模,精度设置为1/10000000。经过多次试算得到1978~2009年各年度分龄组人口数和分龄组迁移流动人口数(计算结果保存为一个106行236列的数据表格)。为了检验计算的有效性和准确性,对1981年分龄组数据及死亡率数据进行校验,1981年利用年龄结构推算方法计算的总死亡人口为112756人,总人口死亡率为5.81‰,与1982年11月出版的《甘肃省第三次人口普查手工汇总资料汇编》[5]中统计的1981年甘肃省总人口死亡人数110355人相比,相差2401人,占2.18%,总人口死亡率与5.72‰相比,相差0.09个千分点。考虑到计算中累积性误差等因素的影响,可以认为,计算结果较好地反映了当时人口年龄结构状况。推算期间主要年份的分龄组人口数及死亡率数据见表3。
根据2000年和2010年普查资料和推算结果,甘肃省1978~2010年间跨省迁移流动人口规模变动区间在-19.9万人至70.59万人之间波动,主要结果如表4。
对照普查资料,2000年甘肃省跨省迁移流动人口22.79万人,模型估算数据为25.15万人,相差2.36万人,占当年总人口的0.94‰;1990年甘肃省跨省迁移流动人口19.92万人,模型估算数据为19.52万人,相差0.49万人,占当年总人口的0.22‰,考虑的多次迭代产生的累积误差等因素,可以认为模型能够较好地估计人口迁移流动规模。对估算的跨省迁移流动人口规模做单样本T检验,检验均值3.88,t=0,sig=1,数据一致性良好(表5)。
四、基于计算结果的简要分析
(一)1978~2010年间甘肃省跨省迁移流动人口规模呈波动增长态势
从计算结果看,甘肃省跨省迁移流动人口规模从1978年的1.86万人波动增长到2010年的43.28万人,其中有14个年度迁移流动规模为净流入(负值)(图1)。
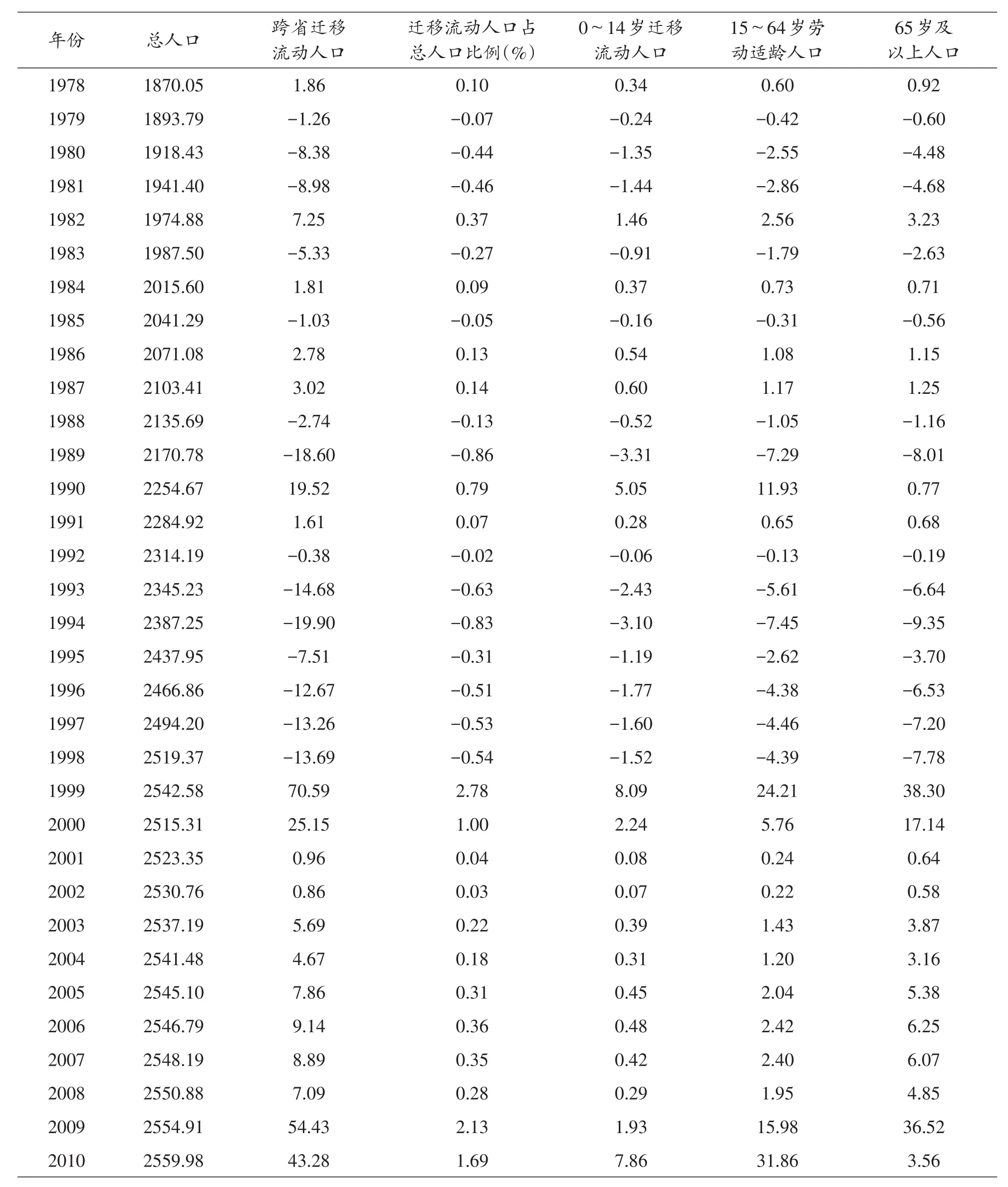
表4 根据年龄结构推算方法估算的1978~2010年甘肃跨省迁移流动人口规模 单位:万人

表5 1978~2010年甘肃省跨省迁移流动人口规模一致性单样本检验
(二)1978~2010年间跨省迁移人口中各分龄组人口规模变动情况基本保持一致
1978年甘肃省0~14岁跨省迁移人口规模0.34万人,仅占总人口的0.02%,2010年,其规模增长到7.86万人,占总人口的比例提高到0.31%。15~64岁劳动适龄人口规模从1978年的0.6万人,占总人口的0.03%,提高到2010年的31.86万人,占总人口的比例提高到1.24%。1978年甘肃省跨省迁移人口中65岁及以上老龄人口0.92万人,占总人口比例为0.5%,到2010年,65岁及以上老龄人口降低到升高到3.56万人,占总人口比例提高到0.14%(图2)。

图1 1978~2010年间甘肃省跨省迁移流动人口规模变动图

图2 1978~2010年间甘肃省0~14岁跨省迁移人口规模变动图
五、对年龄结构推演方法的讨论
(一)如果利用1990年,2000年和2010年普查数据中迁移人口对甘肃省迁移人口做线性估计,则1978~2010年间,甘肃省跨省迁移流动人口规模一直处在0值以上,对线性估计模型计算的1978~2010年间跨省迁移流动人口与本研究计算结果做配对样本T检验,T=-0.59,sig=0,差异显著,直接用普查数据做线性估计会带来较大误差(表6)。
(二)利用本方法可以较好地对历史人口年龄结构做出相对准确的推算,但其局限性也很明显。一是本方法受历史统计数据质量及准确度的影响较大,特别是普查年。二是对历史年份数据的推算要从1989年开始①只有1990年及以后普查数据中可以得到完整的分龄组人口及死亡率数据。,计算量大,必须借助计算机辅助计算。三是高龄组人口规模受死亡率变动的影响较大,某一高龄组死亡率变动,会影响以后年份的数据计算,因而,对死亡率的变动的估计,超过10年后将带来较大误差。同时,对高龄组死亡率0值要作非0化处理,也就是该年龄最少要有1个人存活,替代办法是降低最高年龄组的数值,比如从100岁及以上,降低为90岁及以上②为了计算结果的稳定和推算的可持续,本研究对异常死亡率中超过1000‰的分龄组死亡率,利用前后年龄组死亡率均值重新赋值,对为负数的死亡率做了0值处理,对处理后仍不能解释的部分归并为迁移人口。。
(三)本方法对分龄组死亡率的估算采取历史数据回归推算办法,并未采取通用区域死亡模式做标准化处理,对数据比较研究带不便,这是需要进一步改善的地方。✿

表6 对普查数据线性估计与本研究推算跨省迁移人口的配对样本T检验
