极化特征组合在ALOS PALSAR数据地物分类中的应用
2018-08-03贾诗超薛东剑李成绕
贾诗超,薛东剑,2,李成绕
(1. 成都理工大学地球科学学院,四川 成都 610059; 2. 国土资源部地学空间信息技术重点实验室,四川 成都 610059)
ALOS PALSAR是具有极化工作能力的SAR,它用于全天时全天候的陆地观测,通过极化测量获得地物散射回波,继而得到具有目标地物相位、强度信息的散射矩阵。对散射矩阵进行极化分解获得极化特征,应用极化特征可进一步对图像分类[1]。自1970年Huynen提出了目标分解理论[2]后,遥感领域里面涌现了很多基于目标分解的极化SAR图像分类算法。纵观这些分类算法,可以将极化SAR图像的分类主要概括为两步:极化分解和分类方法的选择。极化分解也可以分为两大类:一是基于相干目标分解,主要是针对Sinclair矩阵的分解;二是基于分布式目标(部分相干目标)分解,主要是针对相干矩阵、协方差矩阵和Mueller矩阵的分解。文中的Cloude-Pottier分解和特征参数香农熵、雷达植被指数都是基于相干矩阵的。而分类方法的选择,根据是否存在训练样本和人工干预,可以分为监督分类[3]和非监督分类[4]。监督分类应用最为广泛的是利用统计分布的Bayes分类[5];非监督分类主要分为两类:一是基于聚类分析,二是基于目标电磁散射机制[6]。
本文中使用的SVM分类是一种监督分类方法,基于SVM的极化SAR分类,国外最早开始做了很多研究。在2001年,Fukuda首次将支持向量机应用到极化SAR图像分类中[7],并取得了不错的分类效果,随后基于SVM的极化SAR图像分类不断应用与发展。这些应用主要差别在于极化特征的选择上,如基于Cameron分解[8]、Freeman分解[9]、Yamaguchi分解[10]的极化特征应用;也有将不同的分解特征联合起来进行分类[11-12]。然而这些特征都没有很好地利用目标散射矩阵上的信息,本文采用的方法将Cloude-Pottier分解和香农熵、雷达植被指数、极化总功率组合起来,更好地利用了目标散射信息,各自发挥它们之间的特征优势,如雷达植被指数对植被信息提取具有很好的效果。并且将本文方法与Freeman-Durden-SVM分类方法和Wishart监督分类进行比较,进一步验证了本文方法良好的分类性能。
1 研究区与数据
研究区位于四川省彭州市西北方向的中国石油四川石化有限公司(简称为彭州石化)。彭州石化项目是国家能源发展战略布局的重大项目,经过国家环保部环境影响评价和国家发改委核准,国务院正式批准该项目在彭州建设。彭州石化作为四川省内大型的石化公司,对其周边区域的土地分类研究是必不可少的,也为进一步研究其对周边区域不同地物的环境影响做准备。研究区内主要分布在成都平原,其内有彭州石化的工厂,工厂内分布着很多圆柱形的烟囱,然后是居民地、裸地、水体和耕地。裸地主要分布在河道周边,由于4月正是岷江的枯水期,因此河道水流很小,河道周边的沙地都裸露出来,还有部分是裸露的土地。居民地主要分布在公路两边,耕地在居民地的周边。影像的左上角为山地,紧靠龙门山断裂带,山地植被覆盖较茂密,如图1 所示。在后面的地物分类中所选择的训练样本也是分为这六类地物。
ALOS是日本对地观测卫星,它载有3个传感器:全色遥感立体测绘仪(PRISM),主要用于数字高程测绘;先进可见光与近红外辐射计-2(AVNIR-2),用于精确陆地观测;相控阵型L波段合成孔径雷达(PALSAR),用于全天时全天候陆地观测。文中使用的影像数据是ALOS PALSAR,成像时间是2011年4月7日,数据级别为1.1,入射角为21.5°,极化方式为HH、HV、VH、VV这4种。研究区的图像大小为751×601,影像数据为单视复数数据(SLC)。
2 试验方法与过程
文中地物分类方法的流程分为以下6个步骤:
(1) 对ALOS PALSAR数据进行多视处理,并获取相干矩阵T3和基于Pauli分解下的RGB图像。
(2) 由于地形影响,对数据进行地形校正和地理编码。
(3) 由于SAR影像都会受到相干斑的影响,进行滤波处理。
(4) 提取极化总功率SPAN,再进行Cloude-Pottier极化分解,获取极化特征散射熵、平均散射角和各向异性度,并且获取极化特征香农熵(SE)和雷达植被指数(RVI)。
(5) 将极化总功率、散射熵、平均散射角、各向异性度、香农熵和雷达植被指数组合起来,以此进行SVM分类。
(6) 确定6类分类类别数,选取训练样本,对极化特征组合利用SVM进行极化SAR图像分类,并获取分类后的分类精度。
2.1 数据预处理
由于初始数据是SLC数据,因此在距离向和方位向的采样大小不一致,为了目视解译和训练样本选取方便,进行降斑和数据压缩,对影像进行5∶1的多视处理且在Pauli分解下得到该研究区的假彩色图像,如图1所示。

图1 Pauli分解的RGB图像
SAR图像的成像方式为侧视成像,其特有的成像方式也决定了图像的一些几何特点。在地形起伏的山地,SAR图像会出现透视收缩、叠掩和阴影,这些固有的几何特点对影像的正确分析会产生一定的影响。如本文使用的SAR影像数据在左上角有一部分是山地,原始数据在该部分有明显的几何形变,需要进行地形校正。然后再对影像进行滤波处理,去除相干斑噪声的影响。
本文所采用的滤波方法为Refined Lee滤波,通过试验比较3种不同的滤波窗口,窗口大小分别为3×3、5×5和7×7,对3种窗口都做到最后的图像分类,通过分类精度来选择,发现7×7的滤波窗口分类效果更好,因此本文选择7×7的滤波窗口,如图1所示。但是7×7滤波窗口得到的图像细节损失与其他两种相比更为严重一些,不过所选择的研究区域较大,区内各地物的分布较多,不同地物之间的分界线也很明显,因此细节损失对最后分类结果没有太大的影响。图2、图3分别给出了3×3和5×5的滤波图像。

图2 3×3滤波图像

图3 5×5滤波图像
2.2 极化特征提取
在单站互易媒质的后向散射情况下,Shv=Svh,对极化散射矩阵进行矢量化,在Pauli基下
(1)
由散射矢量定义极化相干矩阵
(2)
式中,上标H表示共轭矩阵;<·>表示集平均。
Cloude-Pottier极化分解是1997年Cloude和Pottier[13]利用相干矩阵T3将相干矩阵分解为不同的特征矢量和对应的特征值,通过该极化分解,可得到3个特征参数
(3)
(4)
(5)
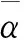
基于特征值的参数香农熵(SE)是由Morio等提出的[14-15],它可以表示为与强度(SEI)和极化(SEP)相关的两分量之和
SE=log(π3e3|T3|)=SEI+SEP
(6)
式中,SEI是与总后向散射功率相关的强度分量;SEP是与极化度相关的极化分量。
雷达植被指数是对极化SAR的各个极化通道的综合表述,它可以描述植被的冠层特征。研究区内有大量的林地,为了获得更好的分类精度,本文加入雷达植被指数。Van Zyl利用随机指向的介质圆柱体模型分析植被区的散射,对于这种模型,第二个和第三个特征值相等[16]。雷达植被指数的定义为
(7)
当RVI= 4/3时,为细圆柱体,单调递减到0时,为粗圆柱体。
通过以上的极化分解和特征参数提取得到了极化总功率、散射熵、平均散射角、各向异性度、香农熵和雷达植被指数,如图4所示。
这些特征所表现的研究区都有各自的不同信息,将它们组合起来,不同信息之间相互补充,可以提高分类的精度。但是特征之间也会有相同信息,过多的特征组合会造成信息冗余,对分类精度并没有提高,反而分类精度会有所降低[17]。
2.3 基于 SVM的图像分类
SVM是一种线性和非线性数据分类的方法,它以训练误差作为优化问题的约束条件,以置信范围最小化作为优化目标来构造,将数据映射到高维空间中,然后寻找最优分类超平面[18]。
设训练数据为{(x1,y1),(x2,y2),…,(xn,yn)},xi∈Rn,yi是分类结果标签,yi∈{+1,-1},i=1,2,…,n。求得的分类超平面为
wT+b=0
(8)

图4 极化特征
支持向量机是为了使离超平面比较近的点能有更大的间隔,即最优分类超平面,也就是等价于求二次规划问题为
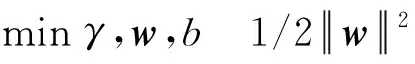
(9)
当数据集线性不可分,可以利用核函数将数据集映射到高维空间中,进而在新的空间中线性可分,求得最优分类超平面。本文选择径向基函数作为核函数,惩罚系数为4096,γ值为1.0。选取极化总功率、散射熵、平均散射角、各向异性度、香农熵和雷达植被指数作为SVM的分类特征。然后在Pauli分解的RGB图像上选取训练样本,各个训练样本的大小分别为:工厂烟囱2348个像素、林地3240个像素、居民地2911个像素、裸地2317个像素、水体1646个像素和耕地2511个像素。选择的训练样本如图5所示。

图5 训练样本
SVM的参数设置完成且选好训练样本后,进行图像分类,分类后得到地物分类结果图和分类精度。
3 结果分析与比较
通过以上的试验过程得到本文研究方法的分类结果图,然后进行Wishart 监督分类和Freeman-Durden-SVM分类。Wishart 监督分类[19]是根据选取的训练样本数据进行Wishart 距离度量来分类。Freeman-Durden分解[20]是一种以物理实际为基础,将三分量散射机制模型用于极化SAR观测技术,它不需要使用任何地面观测数据。3个散射机制分别为体散射、二次散射和表面散射。Freeman-Durden-SVM分类首先进行Freeman-Durden极化分解,提取极化特征,然后在SVM里面进行分类。为了避免由于训练样本的不同影响最后的分类效果,本文的3种方法所选择的训练样本相同。3种方法的分类结果如图6所示。

图6 分类结果
通过分类结果可以明显看出Wishart监督分类效果最差,错分像素很多,各类地物之间界限也不明显,如林地里错分了很多工厂烟囱和耕地。而Freeman-Durden-SVM和本文方法分类效果相对好很多,错分像素也出现很少,边界清晰,但是Freeman-Durden-SVM方法在耕地和居民地的地方明显错分一些裸地。这只是根据分类结果图目视分析得到的结论,表1给出了3种方法精确的分类精度,包括用户精度、总体精度和Kappa系数,它们分别从不同的角度对不同方法的分类效果进行评价,精度值越大,分类效果越好[21]。

表1 图像分类精度 (%)
从表1可以看出本文方法的用户精度、总体精度和Kappa系数都高于其他两种方法,其中工厂烟囱和林地的精度高达99.70%和99.38%。从分类结果图中可以发现工厂烟囱很明显地被提取出来,而且与工厂内的其他建筑之间的分界线也很清晰。极化特征组合中加入的各向异性度和香农熵可以将工厂烟囱的特征提取出来,有利于后面对它进行准确地分类;林地的分类效果也很好,边界清晰且错分像素很少。雷达植被指数可以描述植被的冠层特征,从雷达植被指数图可以观察到,左上角的林地信息被描述得很清楚,再加上平均散射角的信息进行补充,因此林地的精度很高。水体的分类精度相对于本文方法是最低的,这主要是因为影像的成像时间是4月7日,四川省内部分耕地已经灌水,准备水稻的种植,因此耕地被错分为水体。Freeman-Durden-SVM方法分类效果次之,裸地和水体的效果相对较差。由于Freeman-Durden分解为3个散射分量,水体和裸地都可以认为是表面散射,仅依据协方差矩阵分解的表面散射分量,难以很好地区分出同为表面散射的水体和裸地。而本文方法将不同的极化特征组合起来,丰富了表面散射模型,可以较精确地分出水体和裸地。不过Freeman-Durden-SVM方法分类整体效果较好,Kappa系数为91.88%。Wishart监督分类效果相对最差,林地的精度只有56.54%,工厂烟囱也没有很好地提取出来,精度为62.10%,整体的Kappa系数只有69.94%。因为Wishart监督分类是根据训练样本数据进行Wishart 距离度量来分类,训练样本的选择对最后的分类结果也有一些影响,而且根据Wishart 距离度量很难准确区分出研究区的六类地物。总体来说,本文方法将不同极化特征组合起来,信息之间相互补充,分类效果很好,各地物之间界限清晰,总体精度为97.64%,Kappa系数为97.14%。
4 结 论
本文通过Cloude-Pottier极化分解,用散射熵、各向异性度和平均散射角来表征各种散射机制,再加上香农熵和雷达植被指数进行补充,很好地获得了目标地物不同的散射机制。另外加入极化总功率对空间信息描述,组合这些极化特征对ALOS PALSAR全极化数据进行SVM分类,得出以下结论:
(1) 本文方法分类结果效果较好,Kappa系数为97.14%,相对另两种方法的Kappa系数分别提高了5.26%和27.20%。
(2) 耕地和水体的分类精度相对较差,主要是由于成像时间刚好是水稻的种植期,部分耕地已经灌水,造成耕地错分为水体。
(3) 在Cloude-Pottier极化分解基础上加入香农熵可以提高工厂烟囱的分类效果,加入雷达植被指数可以提高林地的分类效果。
