一种基于FPGA的卷积神经网络加速器的设计与实现
2018-06-13来金梅
张 榜,来金梅
(复旦大学 专用集成电路与系统国家重点实验室,上海 201203)
卷积神经网络(Convolutional Neural Network, CNN)是一种受动物视觉皮质(Visual Cortex)结构形式启发,而形成的一种前馈神经网络(Feed-Forward Artificial Neural Network).该种神经网络通常由输入层、卷积层、池化层、全连接层和输出层组成.其中: 输入层即为所要识别的图像信息;卷积层主要由卷积核组成,作用是对输入特征图(Input Feature Map)的信息进行特征提取,并映射到输出特征图(Output Feature Map)中;池化层主要对输出特征图进行下采样,以降低传递特征所需的数据量;全连接层对卷积层最终输出的特征图进行综合处理,完成从特征图对识别标签的映射.输出层将针对每个标签得到的识别结果转化为便于观察形式,比如概率的形式.近年来,卷积神经网络在图像识别领域取得了显著的进展.在ILSVRC(Image-Net Large Scale Visual Recognition Challenge)[1]中,卷积神经网络方案[2-5]相比于传统的图像识别方案显示出了明显的优势,促进了工程领域对卷积神经网络在实际应用场景中实现方案的探索.
然而,常用的网络模型在计算量上均达到了10亿量级,同时参数量上达到了上百兆的量级,因此无论是卷积神经网络的训练还是识别,通常需要高性能的GPU、大容量的存储设备或者大功率的服务器集群为其提供计算和存储的支持.随着智能设备的普及,嵌入式设备对图像快速、准确识别的要求越来越高.对于资源紧张、功耗较为敏感的嵌入式设备来说,庞大的计算量和参数量使得神经网络为卷积神经网络的实现提出了较为严苛的要求.基于现场可编程门阵列(Field Programmable Gate Array, FPGA)以其强大的并行能力、灵活的设计方法和较高的性能功耗比成为了在嵌入式设备中实现对卷积神经网络进行硬件加速的最具吸引力的实现平台之一.本文针对卷积神经网络计算量大、网络参数多的特点,提出了一种基于FPGA的卷积神经网络加速器的设计与实现方法.
目前对FPGA的卷积神经网络的加速方案主要分为两个方面: 一方面是从模型方面对卷积神经网络模型进行压缩,以最大限度降低FPGA计算所需的计算资源和存储空间.目前常用的模型压缩方案主要有模型剪枝(Network Pruning)[6]、矩阵的奇异值分解(Singular Value Decomposition, SVD)[7]和数据量化(Data Quantization)[8,15-16],前两种方法主要应用于传统神经网络的全连接层的压缩,而数据量化方法则适用于卷积神经网络中的所有计算.通常的数据量化通过依次选取不同的量化精度得到不同的量化数据,然后将这些数据依次替换神经网络中的浮点数据重新对测试集进行识别,最后选择量化前后识别率下降最少的精度作为最终选取的量化参数.这种量化方案虽然能得到最优的识别率,但依次尝试所有可能的精度会耗费大量的时间,效率较低.另一方面是从硬件实现的角度提高FPGA对卷积神经网络的计算进行并行加速.在硬件架构上,在目前的“主机+FPGA”架构[8-11]中,往往由处理器控制对片外DRAM数据传输请求的发送.卷积神经网络自身参数量庞大,这些参数往往存储在片外DRAM而非片上的数据缓存中.因此在系统运行过程中需要频繁地发起对片外DRAM的数据传输,进而将片外DRAM中的数据加载到片上缓存中由数据处理单元(Processing Element, PE)进行处理.上述这种架构虽然可以保证数据传输的灵活性,但需要处理器与FPGA之间进行频繁通信,进而引起系统整体性能降低;在电路实现上,文献[8,13-15]采用了高层次综合的方式对已经确定的系统架构进行实现,高层次综合可以提高电路的设计效率,有助于对系统架构的探索,但往往难以保证系统在底层结构,尤其是在计算和缓存这种对性能有直接影响的电路结构上的有效性.
本文在该领域相关文献的基础上,以交通标志识别(Traffic Sign Recognition, TSR)为应用场景,提出了一种用于识别德国交通标志标准测试集(German Traffic Sign Recognition Benchmark, GTSRB)的卷积神经网络加速器的设计与实现方法.首先,本文采用数据量化的方法降低了网络计算所需的计算和存储资源,在数据量化过程中采用先确定量化精度的可能范围,再从中选取最优量化精度的方法,试图降低数据量化花费的时间成本;其次,提出了一种从FPGA端向片外DRAM发起数据访问的一种系统架构,在该架构中FPGA可以直接对片外DRAM进行访问,不需要处理器进行干预,降低了处理器与FPGA之间频繁交互带来的执行效率下降;最后,针对卷积神经网络的特点,提出了相应的计算和缓存电路的结构,其中卷积器采用了流水线的方式对输入特征图的计算实现了并行处理,并采用屏蔽器实现了数据填充(Padding)和计算的并行操作,提高了卷积器的运算效率,缓存电路则采用一种“双-BRAM”的缓存结构,其中一块BRAM用于数据处理时,另一块用于数据加载,数据加载和数据处理完全并行操作,使FPGA的计算能力得到了最大化利用.
1 卷积神经网络
1.1 网络结构
本次设计所采用的网络结构如图1所示,该网络主要由卷积层和池化层组成,图中:NROW和NCOL分别代表当前层中单个特征图行数和列数;NIN代表输入特征图的个数,其中每层输出特征图的个数即为下一层中输入特征图的个数;K代表卷积窗的规模.前两层卷积均附带规模为2×2的池化操作,因此特征图规模比输入减小一倍.该网络采用1×1的卷积层代替了传统神经网络中的全连接层,降低了网络参数规模,提高了硬件的计算和存储效率.最后,该网络通过平均值池化,即将每个特征图的所有元素求取平均值的方式,将特征图向标记空间映射.通过对该网络在软件平台中进行训练和测试得到其对GTSRB的识别准确率为96.6%.
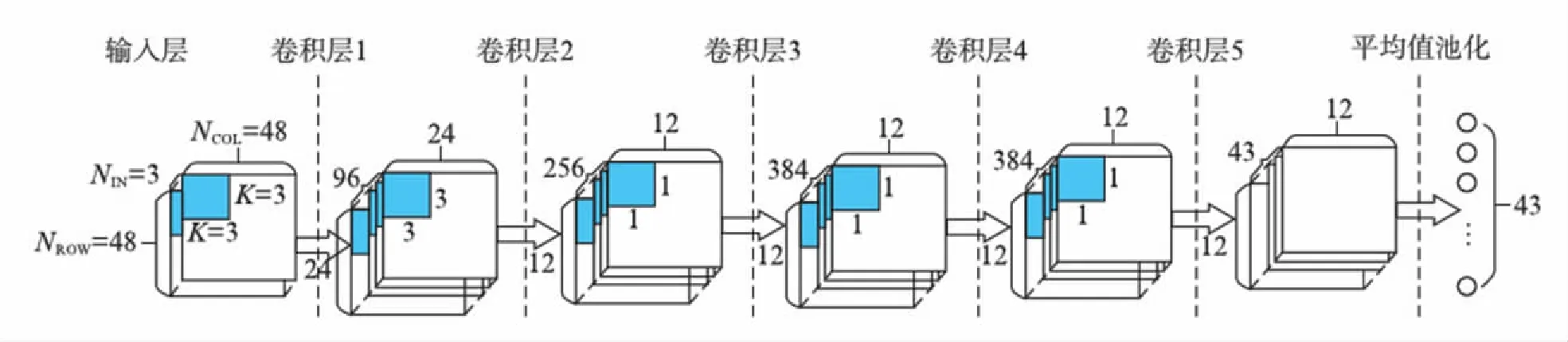
图1 卷积神经网络结构Fig.1 The CNN architecture
1.2 网络压缩
在软件平台上,为了保证计算精度,整个网络参数均采用双精度浮点数表示.本小节针对得到的参数进行数据量化,采用定点数表示这些参数,以保证网络占用的存储空间最小.本文采用的量化实现方案分为如下三个部分: 首先分析网络参数的取值范围,以确定定点数据采用的位宽,确保其不会溢出;其次,计算选择不同精度时得到的量化数据与原来浮点数据相比的误差,选择误差相对较小的精度作为备用精度选项.以上两步中选用的量化位宽和精度应该满足式(1):
2W-P-1>max(|Dmax|×2P,|Dmin|×2P),
(1)
其中:P为量化精度;W为量化位宽;D表示量化前的浮点数据.最后,将上一步筛选得到的量化数据替换原来的浮点数据,在软件平台上测试,选取相比于原来网络精度下降最小的一组数据,作为我们最终硬件实现所采用的定点数据.
先确定量化精度范围再替换参数重新测试的方案,在保证量化精度的前提下,降低了对测试集进行重新测试的次数,减少了确定量化参数所需的时间.数据量化使软件平台中网络参数从64位浮点数转化为16位定点数,使存储网络所需的存储空间下降为原来的1/4,而且从浮点运算转换为定点运算降低了硬件实现所需的计算资源和功耗开销.
2 硬件加速
2.1 系统框架
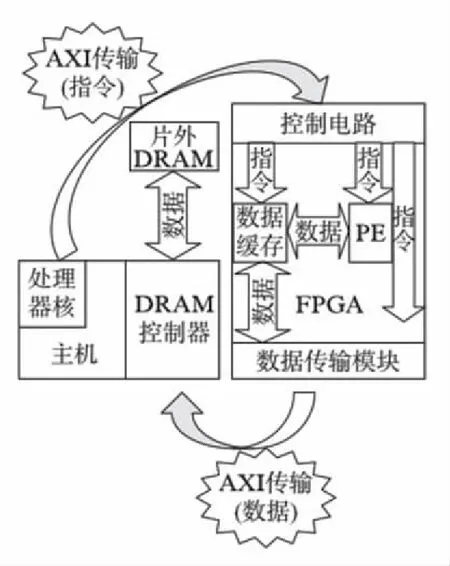
图2 系统架构Fig.2 The system architecture
卷积神经网络加速系统通常采用“主机+FPGA”架构,其中: 主机包括处理器核、DRAM控制器,主要负责计算和数据传输的控制;FPGA端则用于实现数据缓存、数据处理单元(PE)、控制电路等,主要负责对数据的缓存和处理.卷积神经网络操作的数据相对比较规整,对数据传输的灵活性要求较低,因此采用FPGA实现数据传输的控制代价较低,且能避免处理器与FPGA之间大量的通信操作.本文提出了一种从FPGA端发起数据传输的系统架构,如图2所示,在识别开始时,由处理器对FPGA电路进行初始配置,FPGA收到开始信号后,片上缓存和PE分别在控制电路的支配下开始进行数据缓存和处理.在识别过程中控制电路可以根据当前系统的状态直接向数据传输模块发送指令,进而发起对片外DRAM的数据传输,数据请求成功后直接通过数据传输模块加载到数据缓存中,整个传输过程不需要处理器参与.在识别结束后,处理器读取FPGA中产生的识别结果,并由处理器决定开始下次识别或者终止系统.在整个识别过程中处理器仅仅在识别开始和识别结束时与FPGA发生通信,显著降低识别过程中处理器与FPGA通信所需的时间,因此在计算能力受限的嵌入式平台中该架构能提供更高的执行效率.
2.2 数据处理单元
数据处理单元主要完成卷积神经网络的计算工作,对加速器的执行效率具有直接影响.本文采用的数据处理单元结构如图3所示,该模块接收多个输入特征图及其对应系数,分别经过多个卷积器完成卷积运算后得到一组卷积结果,将该组卷积结果对应值相加后,经过非线性化(ReLU)和池化后得到一个输入特征图.数据处理单元内部采用多个卷积器,从结构层面实现了对卷积神经网络的并行加速.
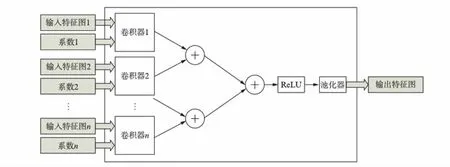
图3 数据处理单元Fig.3 The processing element
为了保证数据处理单元的并行性,对卷积器内部的电路结构采用了“流水线+屏蔽器”的方式对单个的卷积运算实现了并行加速.卷积器的结构如图4所示,整个卷积器由流水寄存器、屏蔽器、乘法器阵列和加法器组成.在计算过程中,输入特征图依次通过长度为NCOL×(K-1)+K(各变量含义与1.1小节中相同)的流水线中,图中虚线方框所示的区域即为当前时刻所需计算的输入特征图窗.对于需要进行填充操作的卷积神经网络而言,输入特征图的边缘位置需要填充0.因此该卷积器添加了屏蔽器,根据当前卷积操作所在的时钟周期,将输出的边缘位置置0.乘法器模块将每个时钟周期的输入特征图窗和对应的卷积系数进行计算,乘法器的个数为K2.因此该卷积器可以做到每个时钟周期输出一个卷积计算结果,同时流水线不会因为数据填充或特征图的切换而中断,从电路层面保证了卷积计算的并行性.
2.3 数据缓存
由于卷积神经网络自身参数量庞大,FPGA器件中的片上存储难以做到对所有参数的存储,加速器需要片上存储器来实现对特征图、系数数据在片上的缓存.为了保证数据处理的稳定性,通常的数据缓存操作包括数据加载和数据处理两部分,对于某个片上存储器来说,只有完成了数据加载后才能对其中的数据进行处理,以避免片外数据传输丢包带来的流水线中断.对于单个片上RAM而言,缓存处于加载状态时,无法为PE提供有效的数据,会导致PE计算效率降低.为了解决这个问题本文提出了如图5所示的“双-BRAM”的数据缓存结构.当数据缓存处于状态1时,BRAM1进行数据加载,BRAM2用于进行数据处理;在状态2时,两块BRAM调换工作状态.可以看到该数据缓存能够保证在整个处理过程中,数据处理单元始终处于工作状态,数据加载和数据处理完全并行操作,使FPGA的计算能力得到了最大化的利用.

图4 卷积器Fig.4 The convolver

图5 数据缓存Fig.5 The data buffer
3 实验结果
我们将本文中所述的加速方法进行了板级实现,本小节主要对得到的实验数据进行分析,以论证本文所采用方法的有效性.本次实验采用了Xilinx提供的ZC702开发板,该开发板包含了容量1GB的片外DRAM,并搭载了XC7Z020 SOC,该芯片同时包含一块ARM处理器和FPGA资源,可以同时完成本文所提出架构的软硬件设计现.本次实验采用的硬件开发环境为Vivado 2014.4,软件开发环境为Xilinx SDK 2014.4,采用的目标测试集与软件平台相同,为GTSRB.
3.1 测试流程
本次测试采用的测试流程如下: (1) 在硬件开发环境中对设计方案进行综合、布局布线、生成位流,给开发板上电并配置位流;(2) 为片外存储器加载数据,包括网络参数和测试用例;(3) 启动SOC中的处理器,开始运行程序,配置FPGA,同时启动计时器,开始计时;(4) 系统开始对测试用例中的图片进行识别;(5) 完成识别后,FPGA输出识别结果,处理器从FPGA端读回测试结果,并通过串口调试接口将其打印到PC软件开发环境的控制台中;(6) 如果测试用例未处理完毕,继续重复操作(4)和(5),如果测试完成,则停止计时器,并将计时器结果读回处理器,打印至软件开发环境中的控制台中.
3.2 识别精度
文献[15-16]中,采用数据量化进行模型压缩,由数据量化引入的识别准确率的下降在0.97%~1.3%范围内.本文中将数据量化后的参数代替原有的参数在软件平台上进行测试后发现,卷积神经网络的识别准确率从96.6%降低到96.0%,即由数据量化引入的准确率下降为0.6%.经过板级实现后,识别准确率依然为96.0%,说明硬件实现并未引入新的识别精度的下降.
3.3 资源占用
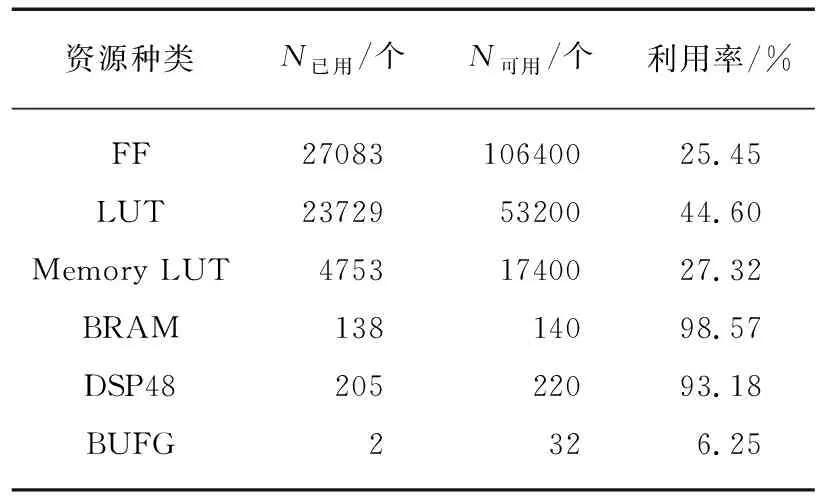
表1 资源消耗
本次设计经过综合、布局布线后,Vivado 2014.4给出的资源占用情况如表1所示,通过对FPGA资源占用情况的分析可以发现,乘法器(DSP48)和BRAM是本次设计中消耗量最大的两类资源.通过3.3小节的分析可知,BRAM对数据的缓存和PE对数据的处理同时进行,对于相同容量的BRAM来说,处理BRAM中的所有数据一般都大于数据传输所需要的时间.因此使用本次设计中采用的缓存结构时,最终限制系统性能的因素不是FPGA中BRAM的存储空间而是乘法器的数目.
3.4 性能
经过板级测试,该系统运行的工作频率为150MHz,识别每张图片时间为49ms.通过对本次设计的板级测试,得到系统的性能和功耗数据与其他文献的对比,如表2所示.由表中列出的其他文献的测试结果可以发现解决方案的吞吐率与采用FPGA器件中乘法器的数目呈正相关趋势.本次实现采用的FPGA器件中包含的乘法器数量较少,因此在吞吐率这个指标上并不占优势;既然解决方案的吞吐率与采用FPGA器件中乘法器的数目呈正相关趋势(且通过3.3小节中对资源占用情况的分析,可以得到本次设计的限制因素就是乘法器的数目),那么对于不同器件之间对同一目标的实现,我们可以用乘法器利用效率,即单位乘法器所贡献的吞吐率,来衡量设计方案的有效性.可以看到,本次设计在该指标上优于此表中的其他实现方案,这意味着在计算资源受限的嵌入式平台中,该方案能提供更高的性能;器件资源的减少带来的好处是运行功耗的降低,通过性能功耗比这个指标可以衡量实现方案对能量的利用效率,可以看到本次设计实现在该指标上的表现也优于此表中列出的其他方案,这意味着对于一些对能耗有严格要求的嵌入式设备中,该方案可以使单位能量贡献更多的计算量.
4 总 结
本文提出了一种基于FPGA的卷积神经网络加速器的设计与实现方法.首先,采用了数据量化的方法对卷积神经网络中的数据进行了压缩;其次,提出了一种从FPGA端发起数据传输的系统架构,避免了在大量数据传输过程中处理器的频繁干预所造成的性能下降;最后,给出了用于卷积神经网络加速的高效计算和缓存电路实现.同时从软件模型、系统架构、电路实现三个方面保证了加速器的性能和效率.本次设计进行板级实现后与该领域相关文献的数据对比、分析发现,本次设计无论是在资源效率还是性能功耗比方面都有较大提升,在资源和功耗受限的平台中实现对卷积神经网络的加速具有显著优势.
参考文献:
[1] RUSSAKOVSKY O, DENG J, SU H, et al. ImageNet large scale visual recognition challenge [J]∥InternationalJournalofComputerVision, 2015,115(3): 211-252.
[2] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks [C]∥Advances in Neural Information Processing Systems. Lake Tahoe, NE, USA: NIPS, 2012: 1097-1105.
[3] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. St. Boston, MA, USA: IEEE, 2015: 1-9.
[4] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [J/OL].[2014-09-15]. http:∥arxiv.org/abs/1409.1556v2.
[5] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE, 2016: 770-778.
[6] HAN S, POOL J, TRAN J, et al. Learning both weights and connections for efficient neural network [C]∥Advances in Neural Information Processing Systems. Montreal, Canada: NIPS, 2015: 1135-1143.
[7] GOLUB G H, VAN LOAN C F. Matrix computations (3rd edition) [M]. Baltimore MD, USA: Johns Hopkins University Press, 1996: 374-426.
[8] ZHANG C, LI P, SUN G, et al. Optimizing FPGA-based acelerator dsign for deep convolutional neural networks [C]∥Acm/sigda International Symposium on Field-Programmable Gate Arrays. Monterey, CA, USA: ACM, 2015: 161-170.
[9] HAMMERSTROM D, GAO C, ZHU S, et al. FPGA implementation of very large associative memories [M]∥FPGA implementations of neural networks: Springer, 2006: 167-195.
[10] IDE A, SAITO J. FPGA Implementations of neocognitrons [J].FPGAImplementationsofNeuralNetworks, 2006: 197-224.
[11] PORRMANN M, KALTE H, WITKOWSKI U, et al. A dynamically reconfigurable hardware accelerator for self-organizing feature maps [C]∥Proceedings of the 5th World Multi-Conference on Systemics, Cybernetics and Informatics. Orlando, USA: SCI 2001. 2001, 3.
[12] PEEMEN M, SETIO A A A, MESMAN B, et al. Memory-centric accelerator design for convolutional neural networks [C]∥IEEE, International Conference on Computer Design. Asheville, NC, USA: IEEE, 2013: 13-19.
[13] CHAKRADHAR S, SANKARADAS M, JAKKULA V, et al. A dynamically configurable coprocessor for convolutional neural networks [C]∥International Symposium on Computer Architecture. Saint-Malo, France: IEEE, 2010: 247-257.
[14] GOKHALE V, JIN J, DUNDAR A, et al. A 240 G-ops/s mobile coprocessor for deep neural networks [C]∥Computer Vision and Pattern Recognition Workshops. Columbus, OH, USA: IEEE, 2014: 696-701.
[15] SUDA N, CHANDRA V, DASIKA G, et al. Throughput-optimized openCL-based FPGA accelerator for large-scale convolutional neural networks [C]∥Acm/sigda International Symposium. Monterey, CA, USA: ACM, 2016: 16-25.
[16] QIU J, WANG J, YAO S, et al. Going deeper with embedded FPGA platform for convolutional neural network [C]∥Acm/sigda International Symposium on Field-Programmable Gate Arrays. Monterey, CA, USA: ACM, 2016: 26-35.
