基于文本概念化的观点检索方法
2018-05-21刘德元魏晶晶吴运兵廖祥文
刘德元,魏晶晶,吴运兵,廖祥文*
(1.福州大学 数学与计算机科学学院,福建 福州 350116;2.福建省网络计算与智能信息处理重点实验室(福州大学),福建 福州 350116;3.福建江夏学院 电子信息科学学院,福建 福州 350108)
0 引言
随着互联网的迅猛发展,网络中涌现了大量的论坛、博客等社交媒体,吸引大量用户在这些社交媒体上分享他们关于政治、产品、公司、事件的观点。观点检索旨在从社交媒体等文档集中检索出与查询主题相关并且表达用户观点(赞同或反对)的文档,是自然语言处理领域里的一项重要课题[1-2]。
目前,观点检索研究大体上可以分为三类。第一类观点检索方法是两阶段模型,首先利用传统的信息检索模型获得与查询相关的候选相关文档,然后将候选相关文档根据观点得分进行重排序。例如,Zhang等[3]首先利用信息检索模型(BM25)和查询扩展技术找出主题相关的文档,接着用支持向量机(SVMs)分类器对主题相关文档进行观点分类并重排序。Santos等[4]首先利用两种现有方法找出观点语句,接着将查询与观点语句的邻近关系融入DFR(Divergence From Randomness)邻近关系模型中,最终得到文档的观点检索评分。Wang等[5]把重点放在观点分类方面,通过整合推文、Hashtag间的共现关系等特征,采用三种图模型的分类算法进行观点分类。两阶段模型结构简单,容易理解,但是缺乏合理的理论解释。
第二类方式将主题相关度与观点结合起来的统一检索模型。该模型借助当前信息检索和观点挖掘领域的最新模型,直接挖掘描述主题的观点对文档进行排序。Eguchi等[6]提出一种概率生成模型框架下的观点检索模型,通过考虑查询依赖的观点得分将主题相关模型与观点得分联合起来,进而计算文档的排序得分。Zhang等[7]提出一个基于词典的生成模型,通过二次组合(Quadratic Combination)方式将主题相关得分与观点评分结合,但该模型假设观点词是均匀分布的。Huang等[8]通过查询相关与查询无关的混合倾向性扩展将主题检索与倾向性分类的两阶段方法转换成一个统一的观点检索进程。Liao等[9]考虑了观点词针对不同查询所含观点信息的差异性,首先基于异质图计算观点词权重,然后将其融入Zhang等[7]提出的生成模型。论文[10]则利用外源知识和机器学习的方法扩展用户的查询词并融入生成模型。
第三类方式是学习排序模型(Learning to Rank)。Luo等[11]利用文档特征、博主特征和主观性特征,采用RankSVM排序学习模型对推文进行观点检索。Kim等[12]进一步利用了博主特征和标签特征的主观性信息来描述文档的主观倾向。但该模型需要大量的人工标注数据构建训练集,因此这一方法的应用场景相对于前两种方法而言较为有限,并且该模型针对不同的査询,其相关文档数量的差异会对学习的效果评价造成偏置。
上述第二类方式中的模型往往无法根据上下文将词汇进行知识、概念层面的抽象。如例句所示:
例:Ios5updategetsandroidlikenotificationbar!?Applebowedtogoogle!
译:IOS5更新得到类似Android的通知栏!苹果向谷歌低头了!
上述文本提到“apple苹果”,现有模型无法识别其是指苹果公司还是苹果水果。因此上述基于词袋的检索模型缺乏对文本词汇在概念层面上的的语义理解。
知识图谱是结构化的语义知识库,其基本组成单位是“实体-关系-实体”三元组,实体间通过关系相互联结,构成网状的知识结构[13]。概念知识图谱是一种单一关系知识图谱,与传统的知识图谱不同,它只包含一种isA关系,例如“Microsoft微软”isA“Company公司”。利用知识图谱,机器不仅能够丰富原始查询信息,同时能够通过分析文本的概念空间以提高对文本词汇的语义理解能力,从而可以计算文本间的语义相似度。例如Dalton等[14]利用实体的相关特征和实体与知识库的连接(包括结构化的属性和文本)来丰富原始查询。Xiong等[15]提出利用freebase获取与查询相关的实体,然后利用非监督或者监督的方法得到最终的扩展词。Wang等[16]在文本分类任务中利用概念图谱推理文本的概念集合以表示文本的主题。Wang等[17]通过分析查询文本的概念空间确定查询中实体的语义,从而制定更加精确的查询关键词。Wang等[18]提出借助知识图谱为文本构建统一的候选词关系图,并使用随机漫步(Random Walk)的方法推导出最优的分词、词性和词的概念,提高实体概念化的准确率。另有学者利用知识图谱提高问答系统的性能[19-20]。
为此,本文提出了基于文本概念化的观点检索方法,首先引入概念知识图谱,通过有效分析查询和文本的概念空间,判断对应多个概念的实体在具体上下文中的正确概念语义,以此来实现概念级别的推理。同时在概念空间计算查询与文本的主题相似度,接着基于词典计算文档的观点得分,最后将相关度得分与文本的观点得分二次组合成相关观点得分,以此提高观点检索的性能。
1 基于文本概念化的观点检索
本文提出了一种基于文本概念化的观点检索方法,首先利用知识图谱分别将用户查询和文本概念化到概念空间上,然后在概念空间计算查询与文本的主题相似度,接着基于词典计算文档的观点得分。最后将相关度得分与文本的观点得分组合成相关观点得分,以此返回文档的排名结果。
1.1 问题描述
为了方便研究,本节将观点检索研究问题形式化描述为:给定一个查询q,观点词典T={ti,i=1,2,…,M},待检索的文档集合D={di,i=1,2,…,N},以及知识图谱G=(V,E)。计算每个待检索文档di与查询q的主题相关度得分Irel(d,q,G)和di的观点得分Iopn(d,q,T),根据检索模型将相关度得分和观点得分组合得到最终的相关观点得分Rank(d)=Score(q,d,T,G)。并根据相关观点评分从高到低排序。
1.2 基于知识图谱的文本概念化
文本概念化的目的是借助概念知识图谱推理出文本中每个实体的概念分布,即将实体按照其上下文语境映射到正确的概念集合上[21](Bags-of-Concepts,BOC)。例如:
例:Ios5updategetsandroidlikenotificationbar!?Applebowedtogoogle!
译:IOS5更新得到类似Android的通知栏!苹果向谷歌低头了!
在上述文本中,通过知识图谱Probase[22],机器可以获悉“apple苹果”这个实体有“Fruit水果”和“Company公司”等概念,“google谷歌”这个实体有“Company公司”等概念。当“apple苹果”与“google谷歌”同时出现在文本中时,通过贝叶斯公式可以分析出该文本中的“apple苹果”有较高的概率属于“Company公司”这一概念。
给定文档集合D={di,i=1,2,…,N},本文利用Probase推理每篇文档的概念集合。文档的相关概念最终表示为一个概念集合di=(〈c1,w1〉,…,〈cj,wj〉,…,〈ck,wk〉),i=1,2,…,N,j=1,2,…,k, 其中wj表示概念cj属于该文档的权重,反映了概念cj对该文档的解释能力。概念化过程分为两部分:实体识别与概念推理。
1.2.1 基于逆向最大匹配的实体识别
为了获得文本的概念集合,首先需要识别文本中的实体,以便通过实体推理概念。对于多词表达的实体,本文仅考虑长度最大的一项,实体之间不相互包含。例如“apple inc苹果公司”可能有两种实体识别结果: “apple苹果”、“inc公司”或者“apple inc苹果公司”,因为三者都在词典中,但本文仅考虑“apple inc苹果公司”这一实体。因此采用基于词典的逆向最大匹配算法来识别文档中的实体。并选用知识图谱Probase中的所有实体(约1200万个实体)作为匹配词典。匹配过程中,采用波特提取器*http:∥tartarus.org/~martin/PorterStemmer/对文档和词典分别做词干提取处理。具体算法描述如下:

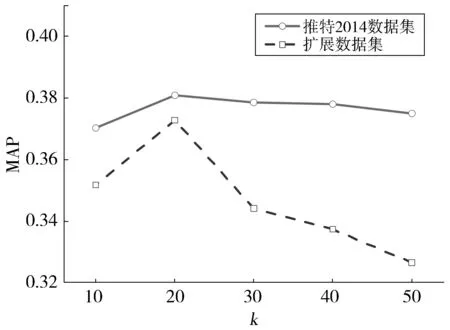
基于逆向最大匹配的实体识别算法输入:文档集合、实体词典输出:每篇文档的实体集合初始化:对实体词典每个词项做词干提取处理。设词典中实体最大长度(包含词汇个数)为maxLen,设输出实体集合entity⁃Set为空。对每篇文档进行如下处理:Step1:对文档词汇做词干提取处理,得到文本s=s1s2…sn。Step2:计算s包含词汇个数,设为n,如果n等于0,转7。如果n 1.2.2 基于朴素贝叶斯模型的概念推理 给定文档的实体集合E={ei,i=1,2,…,M},概念生成的目的是利用Probase中的实体-概念对(Instance-Concept Pairs)推理出最能描述该实体集合的概念集合。为了评估概念对文档的表示能力,采用朴素贝叶斯模型进行评估: (1) 通过贝叶斯公式计算每个概念的后验概率,获得高后验概率值的概念显然就是最能代表给定实体集合的概念。同时把后验概率值作为这个概念表达该文档的解释能力,即为该概念的权重。 在式(1)中,给定概念,得到实体的概率的公式为: (2) 其中n(ei,ck)表示ei和ck的共现次数,n(ck)表示ck出现的次数,这两个值都可以从Probase中直接或经计算得到。两个文本例子和它们经概念化后的概念集合如表1展示。 表1 文本概念化样例Table 1 Samples of text conceptualization. 观点检索的目标是检索出与查询相关且包含作者观点的文档。在以往的研究工作中,有以下统一检索模型: (3) (4) 其中σ(x)=1/(1+exp(-x))是sigmoid函数。 最后,将Irel(d,q)和观点得分Iopn(d,q,T)二次组合可得本文最终的观点检索评分公式为: (5) 本文在实验部分使用了两个数据集。首先,根据2014年文献[9]的推特观点数据集进行实验,这一数据集共含49个查询和3 308篇文档(在下文简称为推特2014数据集)。由于这一数据集的数据量较少,本文利用推特提供的搜索结果及爬虫技术扩展数据集,共爬取10个查询的英文推特29 634篇。标注前采用缓冲池(pooling)技术:针对每个查询,将本文检索模型和基准检索模型的各自检索结果中前500篇文档加入缓冲池,最后得到的缓冲池含7 172文档。5名标注人员对缓冲池的文档进行二值标注,将与对应查询相关并且包含观点信息的文档标为1,否则为0。根据少数服从多数的原则对每篇文档进行判断,对缓冲池外的文档均标注为0。下文将这一数据集记作扩展数据集。两个数据集的基本信息如表2所示。观点词典来自SentiWordNet[23],本文选用评分大于0.6的正面或负面观点词,共3 908个。 表2 数据集基本信息Table 2 Basic statistics of datasets. 评价指标采用文本观点检索领域常用的Mean Average Precision(MAP),NDCG@10,R-precision(R-prec)和binary Preference(bPref),具体计算公式如下: (6) (7) (8) (9) 公式(6)中,Nq指查询的数量,N指总的文档数量,若第i个文档为带观点的主题相关文档,则ri=1,否则ri=0。公式(7)中Zn为标准化因子,用理想返回列表的NDCG@n作为因子进行归一化。r(j)指返回文档的评分,若相关设为2,否则设为1。公式(8)中R指与查询相关并带有对查询观点的文档数量,Rj指检索结果中第j个文档的评分,若是正确结果集中的文档,则取1,否则取0。公式(9)中,R指与查询相关的文档个数,r指具体的某一个相关文档,|nrankedhigherthanr|指排名比r靠前的非相关文档的数量。 Fig.1 MAP with different number of concepts图1 不同概念数量对MAP的影响 为了验证本文方法的有效性,将本文方法与以下模型对比: (1)BM25+Lexicon[9]:使用传统信息检索方法BM25和基于词典的观点得分模型分别计算查询与文档的相关度和文档的观点得分。 (2)BM25-KG+Lexicon[10]:在文献[9]的基础上使用知识图谱freebase的文本描述信息为用户查询进行查询扩展。 (3)BOC+Lexicon:本文方法,基于概念模型计算查询与文档的相关度并结合基于词典的观点得分方法。 实验1不同概念数量对MAP的影响 本文方法在概念化过程中涉及一个参数:每个实体推理出的概念词数量k。实验1研究不同参数k下的MAP值。本文设置概念词数量k的范围10~50,步长为10。 观察图1可以发现,在推特2014数据集中,MAP随概念词数量k的变化趋势比较不明显,折线比较平缓,而且当k为20的时候,MAP获得最优值。在扩展数据集中,当概念词数量k小于20,MAP呈上升趋势且在k为20达到最高值,当k大于20的时候,MAP开始明显下降。值得注意的是,在两个数据集上,观点检索的性能均在k为20的时候达到了最高,说明对于每个实体来说,包含20个概念词是较为合理的。这种合理性并没有随着数据集的扩大而改变,这也说明了k取20是一个较为合理的参数设置。因此,本文在后续实验中,两个数据集上的概念词数量k均设置为20。 实验2方法有效性分析 为了验证本文方法的有效性,对比本文方法和基准方法在两个数据集上的实验结果。结果在表3和表4显示。 表4 本文方法与基准方法在扩展数据集上的实验结果对比Table 4 Comparison of our approache and benchmark approaches on extended dataset 从实验结果可以看出: (1)在推特2014数据集中(表3),BM25-KG+Lexicon四个指标均优于BM25+Lexicon,而BOC+Lexicon(本文方法)除了R-Prec指标与BM25+Lexicon,其余三个指标均优于BM25+Lexicon。在扩展数据集中(表4),BM25-KG+Lexicon在MAP指标上与BOC+Lexicon基本持平,但其余三个指标都优于BOC+Lexicon。而BOC+Lexicon(本文方法)除了NDCG@10指标外,其余三个指标都比BM25+Lexicon好。说明引入知识图谱,可以提高模型的对查询和文本词汇的语义分析能力,进而提高原有观点检索的性能。 (2)在推特2014数据集中(表3),对比本文方法BOC+Lexicon与BM25-KG+Lexicon,BOC+Lexicon优于BM25-KG+Lexicon,虽然在R-Prec,NDCG@10,bPref指标上基本持平,但MAP指标提升了4.2%。在扩展数据集中(表4),BOC+Lexicon除了在NDCG@10指标上低于BM25-KG+Lexicon,在MAP,R-Prec,bPref三个指标分别提升了12.6%,6.1%,16.6%。说明本文方法优于基于知识库扩展方法,不仅可以有效分析用户查询的信息需求,同时可以准确理解文本集和查询词汇的语义信息,改善了特征空间的稀疏问题,进而能够提高观点检索的性能。 本文提出了一种基于文本概念化观点检索模型,与已有的研究工作不同,本文充分利用了知识图谱的结构化信息对用户查询和文本集进行语义分析。通过概念知识图谱对文本进行概念层面的抽象,同时在概念空间计算查询与文本的主题相似度,接着基于词典计算文档的观点得分,最后将相关度得分与文本的观点得分二次组合成相关观点得分。实验结果表明,与现有工作对比,本文方法在MAP等指标上有明显的提升。但是,本文模型目前仍是基于词匹配的模型,在概念化过程中产生的依然是稀疏的概念空间,因此,词汇之间的语义相似度计算在匹配失败的前提下可能产生一定错误的概率。因此在未来的工作中,将利用网络表示的方法,通过表示学习利用知识库潜在的结构信息,将文本嵌入低维空间以计算文本相关度。通过这种泛化能力较强的建模方式,希望可以弥补概念化过程中的错误,进一步提高观点检索的性能。 参考文献: [1] Ounis I,Macdonald C,Rijke M D,etal.Overview of the TREC 2006 Blog Track[C]∥Fifteenth Text Retrieval Conference,Trec 2006,Gaithersburg,Maryland,November,2006:86-95. [2] Pang B,Lee L.Opinion Mining and Sentiment Analysis [M].Foundations and Trends in Information Retrieval,2008:1-135. [3] Zhang W,Yu C,Meng W.Opinion Retrieval from Blogs[C]∥Proceedings of the 6th ACM Conference on Information and Knowledge Management.ACM,2007:831-840.DOI:10.1145/1321440.1321555. [4] Santos R L,He B,Macdonald C,etal.Integrating Proximity to Subjective Sentences for Blog Opinion Retrieval[C]∥European Conference on Information Retrieval.Springer,2009:325-336.DOI:10.1007/978-3-642-00958-7-30. [5] Wang X,Wei F,Liu X,etal.Topic Sentiment Analysis in Twitter:a Graph-based Hashtag Sentiment Classification Approach[C]∥Proceedings of the 20th ACM International Conference on Information and Knowledge Management.ACM,2011:1031-1040.DOI:10.1145/2063576.2063726. [6] Eguchi K,Lavrenko V.Sentiment Retrieval Using Generative Models[C]∥Conference on Empirical Methods in Natural Language Processing.2006:345-354.DOI:10.3115/1610075.1610124. [7] Zhang M,Ye X.A Generation Model to Unify Topic Relevance and Lexicon-based Sentiment for Opinion Retrieval[C]∥Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2008:411-418.DOI:10.1145/1390334.1390405. [8] Huang X,Croft W B.A Unified Relevance Model for Opinion Retrieval[C]∥Proceedings of the 18th ACM Conference on Information and Knowledge Management.ACM,2009:947-956.DOI:10.1145/1645953.1646075. [9] Liao X W,Chen H,Wei J J,etal.A Weighted Lexicon-based Generative Model for Opinion Retrieval[C]∥Machine Learning and Cybernetics (ICMLC),2014 International Conference on.IEEE,2014,2:821-826.DOI:10.1109/ICMLC.2014.7009715. [10] 马飞翔,廖祥文,於志勇,等.基于知识图谱的文本观点检索方法[J].山东大学学报(理学版),2016,51(11):33-40.DOI:10.6040/j.issn.1671-9352.0.2016.250. [11] Luo Z,Osborne M,Wang T.Opinion Retrieval in Twitter[C]∥In Proceedings of AAAI’12.2012:507-510. [12] Kim Y S,Song Y I,Rim H C.Opinion Retrieval Systems using Tweet-external Factors[C]∥COLING,26th International Conference on Computational Linguistics,Proceedings of the Conference System Demonstrations.Osaka,Japan:ACL,2016:126-130. [13] 刘峤,李杨,段宏,等.知识图谱构建技术综述 [J].计算机研究与发展,2016,53(3):582-600.DOI:10.7544/issn1000-1239.2016.20148228. [14] Dalton J,Dietz L,Allan J.Entity Query Feature Expansion using Knowledge Base Links[C]∥Proceedings of the 37th international ACM SIGIR Conference on Research & Development in Information Retrieval.ACM,2014:365-374.DOI:10.1145/2600428.2609628. [15] Xiong C,Callan J.Query Expansion with Freebase[C]∥Proceedings of the 2015 International Conference on The Theory of Information Retrieval.ACM,2015:111-120.DOI:10.1145/2808194.2809446. [16] Wang F,Wang Z,Li Z,etal.Concept-based Short Text Classification and Ranking[C]∥Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management.ACM,2014:1069-1078.DOI:10.1145/2661829.2662067. [17] Wang Y,Li H,Wang H,etal,Toward Topic Search on the Web[R]:Technical Report,Microsoft Research,2010. [18] Wang Z,Zhao K,Wang H,etal.Query Understanding Through Knowledge-based Conceptualization[C]∥International Conference on Artificial Intelligence.2015:3264-3270. [19] Zheng W G,Cheng H,Zou L,etal.Natural Language Question/Answering:Let Users Talk With The Knowledge Graph[C]∥Proceedings of the 2017 ACM on Conference on Information and Knowledge Management,Singapore,2017:217-226. [20] Hao Y C,Zhang Y Z,Liu K,etal.An End-to-End Model for Question Answering Over Knowledge Base with Cross-Attention Combining Global Knowledge[C]∥Meeting of the Association for Computational Linguistics,2017:221-231. [21] 王仲远,程健鹏,王海勋,等.短文本理解研究 [J].计算机研究与发展,2016,53(2):262-269.DOI:10.7544/issn1000-1239.2016.20150742. [22] Wu W,Li H,Wang H,etal.Probase:A Probabilistic Taxonomy for Text Understanding[C]∥Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data.ACM,2012:481-492.DOI:10.1145/2213836.2213891. [23] Esuli A,Sebastlani F.Determining the Semantic Orientation of Terms Through Gloss Classification[C]∥ACM CIKM International Conference on Information and Knowledge Management,Bremen,Germany,October 31-November,2005:617-624.DOI:10.1145/1099554.1099713.
1.3 基于文本概念化的观点检索模型
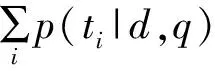
2 实验结果与分析
2.1 数据集及评价指标

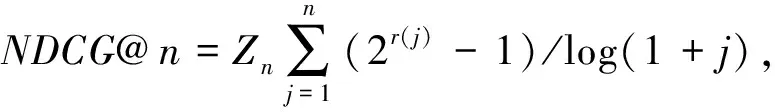
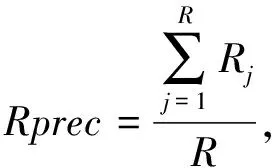
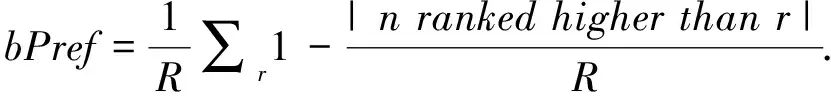
2.2 实验对比

3 结论
