一种基于频度统计的动态二进制翻译优化方法*
2018-05-08庞建民
李 男,庞建民,单 征
(解放军信息工程大学,河南 郑州 450002)
1 引言
以龙芯[1]、申威[2]、飞腾等为代表的国产处理器的问世不仅显示出我国在自主核心芯片研发上的实力,也大大增强了国家的信息安全防护能力;同时,以神威、天河、曙光等为代表的国产超级计算机的计算能力在世界上也处于领先水平,2016年以来,在全球超级计算机500强榜单上,神威·太湖之光与天河二号三次携手夺得前两名。与国产硬件水平不断提升相比,其上支持的软件栈的数量和规模仍有待提高,面向国产平台借助二进制翻译手段进行软件移植的意义重大。
二进制翻译技术[3,4]是作为程序等价变换工具产生并发展起来的,被定义为一种机器上的指令序列到另一种机器上指令序列的等价转换过程。按照翻译方式可以分为三种[5]:解释执行,静态翻译和动态翻译[6]。动态二进制翻译采用了“查找→翻译→执行”的工作模型,如图 1所示,先在翻译缓存T-Cache(Translated Code Cache)中进行查找,如果命中,则进入执行阶段,否则进入翻译阶段。翻译阶段以基本块为单位进行,将翻译后的代码以翻译块TB(Translated Block)为单位存入到T-Cache中,执行阶段以TB为单位进行,一个TB执行完毕后检查是否存在块链,如果存在则继续执行代码,否则转入到查找阶段。T-Cache作为连接查找、翻译和执行三个过程的纽带,是构成动态二进制翻译的重要内容,也是优化工作的一个关注点。

Figure 1 Model of dynamic binary translator图1 动态二进制翻译器的工作模型
2 问题的提出
为了缓存翻译代码并提高其复用性,动态二进制翻译建立了一套T-Cache管理机制,将动态翻译产生的本地码以TB的形式存入缓存区T-Cache中,当程序运行过程中需要重复调用某TB时,翻译平台会在T-Cache中进行查找。T-Cache机制由于需要暂存TB,需要在内存中开辟一段存储空间,理想的状态是T-Cache无限大,能够容纳所有的TB,但是有限的物理资源决定了T-Cache只能是有限空间。为了在有限的T-Cache空间下尽可能地提高翻译效率,必须对T-Cache进行有效的分配和管理。
程序局部性原理表明,程序中20%的指令占用了80%的执行时间,如果能够使执行频度高的代码较长时间驻留在T-Cache中,无疑会提高执行效率。
为实现这个目的,需要解决好两个问题:一是热代码的有效识别问题。本文将待翻译程序中频繁执行的二进制代码片段称为热代码,识别热代码的工作必须在动态二进制翻译中完成,这就需要在翻译器的合适位置进行程序插桩,动态监控基本块的执行情况,另外,还需要确定热代码的起始位置和终止条件。二是保证热代码能够被整体地执行。热代码往往包含多个基本块,而执行阶段T-Cache中的代码以TB为单位执行,这就会造成热代码执行时程序控制流会在执行线索与翻译线索间频繁切换,造成额外的时间开销。
为此,文本提出了“热代码识别→超块缓存STB(Super Translated Block)构造→T-Cache管理策略改进”的解决思路,针对第一个问题,本文提出了一种基于频度统计的热代码识别算法,通过在翻译器的适当位置进行程序插桩,动态更新每个基本块的执行次数——即“热度”,把热度超过预定阈值的基本块及其后续若干基本块认定为热代码。针对第二个问题,本文提出了构造超块缓存的思想,将热代码中的基本块翻译后链接为缓存容量更大的超块提供给T-Cache系统。基于热代码和超块,本文最后提出了改进的T-Cache管理策略。
本文的主要贡献在于:
(1) 提出了一种基于频度统计的热代码识别算法,通过程序插桩和动态监控对每个基本块的执行情况进行profiling统计,在动态翻译过程中实现了有效识别执行频度高的代码片段。
(2) 提出了构建超块缓存的思想,将热代码中包含的基本块翻译后链接成缓存容量更大的超块,能够有效减少上下文切换次数,降低时间开销,也为T-Cache系统提供了新的缓存资源。
(3) 改进了T-Cache系统的查找方法,提出了双层查找策略,针对新引进的超块缓存进行快速查找,针对常规缓存进行慢速查找;同时,改进了T-Cache系统原有的替换策略,对超块缓存和常规缓存使用了不同的内容替换策略,提高了T-Cache的命中率。
3 基于频度统计的热代码识别算法
动态二进制翻译主要有三种热代码识别方法[7]:一是基于块的识别。该策略记录每个基本块的使用次数,一旦达到热度即认定为热块,并开始建立热路径。这种方法造成的系统开销较大,预测精度不高。二是基于跳转边的识别。该策略通过统计基本块之间的跳转次数取代收集基本块的使用信息完成热路径识别,文献[8]对该策略进行了详细阐述。该策略实现简单,准确性较高。但是,由于跳转边仅仅反映局部跳转关系,无法应对基本块重叠的情况。三是基于路径的识别。该策略不需要像前两种方法那样,在每次基本块发生跳转时都进行计数统计,仅需要对整条路径进行计数即可,可以有效减少统计开销。文献[9]表明,有效利用该方法的前提是找到一种适合当前动态翻译平台的高效算法。该策略需要有效解决预测路径中包含的基本块的表示问题,文献[10]中提出了一种使用二进制编码序列来标识路径中包含基本块的方法,该方法使用0、1编码来分别标识条件跳转发生后的不同目标基本块,这样,每一条路径对应一个二进制编码序列,所有路径可以构成一个哈夫曼树的结构。
但是,文献[10]在表示路径构成时仅对条件跳转后的基本块进行了编码标识,没有对直接跳转后的基本块进行编码,即忽略了直接跳转的情况。虽然这样可以有效压缩路径长度、节省查找开销,但同时也可能导致路径表示不完整,影响热路径判定的命中率。
综合考虑多种因素,本文提出了一种基于频度统计的热代码识别算法,该算法结合了块识别和路径识别两种策略的特点,借助程序插桩和profiling技术[11]实现了在动态执行过程中对基本块的频度统计。算法在循环终止条件中增加了对于回路的判断,这对于识别程序中最容易成为热代码的循环结构特别有效。
虽然算法会造成部分统计开销,但本文更多的是考虑热路径的有效识别问题,后续内容提到的构造超块缓存方法和T-Cache管理策略的改进才是本文带来效率提升的关键。
3.1 HCFS算法原理
基于频度统计的热代码识别HCFS(Hot Code Based on Frequency Statistic)算法将“一个执行频度高的基本块与其后若干连续执行的基本块组成的路径”作为热代码预测条件,遵循“先热先选择”的设计原则,从频度值高的基本块开始,把其后连续执行的若干基本块也纳入热代码范围。理论上热代码路径越长意味着基本块的复用率越高,更多的基本块能够被连续执行,有利于缩减基本块的翻译次数,降低翻译开销。但是,由于受到缓存区大小的物理限制,热代码不能过长,因此确定热代码识别的终止条件是一个关键问题。本文对热代码的终止条件做出了限制:对于非循环结构,算法规定当热代码长度达到预定上限时,终止热代码识别;对于循环结构,由于其成为热代码的概率高,算法将形成回路作为算法终止的另一个条件,即当基本块跳转到热代码的头部形成回路时,算法终止。
3.2 HCFS算法实现
HCFS算法是基于频度统计实现的,频度统计代码插桩在基本块开始执行前,在获取当前基本块的PC(地址)后,开始对profiling进行递增处理,更新基本块的使用次数,完成基本块执行频度统计。频度统计函数tb_update_profiling( )的实现如下所示:
//功能:基本块热度统计
static inline TranslationBlock *tb_update_profiling(void){
TranslationBlock *tb;
int flags;
cpu_get_tb_cpu_state(env,&pc,&cs_base,&flags);/*获取当前执行到的PC*/
if(tb→pc)
{
++tb→profiling;//更新profiling
}
returntb;
}
其中,tb为指向当前基本块的指针;pc代表基本块的本地地址,负责对基本块进行唯一标识;profiling代表基本块的频度,负责统计基本块的执行次数。
基于频度统计,HCFS算法的伪代码如算法 1所示,算法的工作过程如下所示:
步骤1依次读取可执行文件中的每个基本块信息。
步骤2获取当前基本块的地址pc。
步骤3检查是否为最后一个基本块,如果是,跳转到步骤7;否则,跳转到步骤4。
步骤4判断当前基本块是否处于热代码中,如果是,跳转回步骤2进行下一个基本块判断;否则,进入步骤5,提取新的热代码。
步骤5判断当前基本块的频度值是否超过阈值,如果是,进入步骤6;否则,跳转回步骤2。
步骤6将当前基本块预设为新热代码的头部,启动热代码预测。每次读入一个基本块,判断是否满足两个条件:一是当前基本块是否指向热代码头部,如果是,说明出现回路,跳转到步骤7;二是热代码长度是否达到上限,如果达到,退出本次预测,跳转到步骤2;如果两个条件都不满足,将当前基本块纳入热路径,并继续读入下一个基本块。
步骤7算法结束,输出热代码。
算法1HCFS算法描述
//功能:热路径局部预测
//输入:可执行文件句柄elf-file
//输出:热路径头指针headpc
Foreachtbinelf-file
pc=env→pc;//从全局变量env中获取当前基本块pc
if当前基本块不处于当前热路径中
if基本块profiling大于热度阈值
headpc=pc;//当前基本块为热路径头部
foreachtb→nextinelf-file∥启动热路径预测循环
将基本块纳入热路径序列;
if(基本块pc等于headpc) or (热路径长度大于设定长度上限) 输出当前热路径头指针headpc;//结束热路径识别
break;
Endif
Endfor
else
tb=tb→next;//指向下一个基本块
Endif
else
tb=tb→next;//指向下一个基本块
Endif
iftb→next=NULL
break;//终止动态翻译循环
Endif
Endfor
4 超块缓存构造
识别出热代码后,其包含的基本块被翻译并存储到T-Cache中,但T-Cache以TB为单位的传统执行方式,使得热代码不能被一次性执行完毕,无法充分发挥热代码的功效。为此,本文提出了构造超块缓存的思路,将HCFS算法识别出的热代码中包含的基本块有序地组织起来,翻译后形成缓存容量更大的翻译块—“超块”STB提供给T-Cache使用,不仅使得执行频率较高的代码保存在T-Cache中,也能扩大一次执行的代码量,有效减少线索切换产生的上下文开销。需要说明的是,本文提出的超块概念特指的是在翻译缓存中新开辟的一段特殊区域。
STB的构造过程从热代码的头指针开始,依次判断当前基本块结尾是否为直接跳转,如果是,直接插入后继基本块代码;否则,保留跳转出口信息。图2展示了STB使用前后的对比情况,假设TB1和TB2属于同一个热代码区域,且存在直接跳转关系。图2a展示了未使用STB的情况,TB1执行后和TB2执行前,必须进行相关环境变量的保存工作和恢复工作,环境变量主要包含一些本地寄存器的相关信息;图2b展示了使用STB的情况,将TB1和TB2之间的直接跳转语句删除,合并两个基本块后形成超块STB。

Figure 2 Construction of super translated block图2 STB的构造
作为TB的有益补充,STB丰富了T-Cache的管理范围,但同时也对T-Cache原有的管理方法提出了新的要求。下面从查找方法和清空策略两个方面讨论在增加超块缓存后,对于T-Cache管理的优化。
5 T-Cache系统管理策略的改进
5.1 查找方法的改进
T-Cache系统原有的查找方法只涉及TB,未涉及STB。引进STB后,需要改进原有的T-Cache查找算法,增加对STB的处理。为了不引起混淆,下文将由常规TB构成的翻译缓存区域称为OldCache,由STB构成的翻译缓存区域称为NewCache。
为充分发挥STB的作用,本文提出了分层查找的思想,将查找过程分成两个阶段,先在NewCache中进行快速查找,再在常规OldCache中进行慢速查找,算法描述如算法 2所示。工作流程如下所示:
步骤1从环境变量env中提取当前基本块PC等参数。
步骤2在NewCache中进行快查,取出由PC标识的STB。
步骤3判断STB是否为空,如果是,转入步骤4进行慢查;否则,说明查找命中,转入步骤7。
步骤4在OldCache中进行慢查,取出由PC标识的常规TB。
步骤5判断TB是否为空,如果是,跳转至步骤6,进入翻译过程;否则,说明查找命中,输出TB,算法结束。
步骤6翻译基本块,将翻译后的本地代码存入OldCache中。
步骤7输出STB,算法结束。
在上述步骤中,步骤2中的快查针对NewCache,步骤4中的慢查针对OldCache。快查和慢查都使用了Hash查找方法,将PC作为键值。查找过程的顺序是先进行快查再进行慢查,如果慢查也未命中,则进行翻译工作。
算法2改进的T-Cache查找算法
//功能:查找T-Cache
//输入:环境变量env
//输出:翻译缓存tb
cpu_get_tb_cpu_state(env,&pc,&cs_base,&flags);//获取env中的相关成员值
tb=env→th_jmp_NewCache[tb_jump_NewCache_hash_func(pc)];/*在NewCache中进行查找*/
if(!tb)//如果没有找到所需超块
{
{tb=env→tb_jmp_OldCache[tb_jmp_OldCache_hash_func(pc)];/*进入OldCache中查找*/
if(!tb)
{
tb=tb_gen_code(env,pc,cs_base,flags,0);/*进入翻译模块*/
env→tb_jmp_OldCache[tb_jmp_OldCache_hash_func(pc)]=tb;/*将tb写入OldCache中*/
}
}
输出tb;
改进的T-Cache查找算法,加入了针对STB的处理,一旦命中,立即执行热代码对应的翻译缓存,并且一次执行的代码量大,使得程序经常执行的代码部分可以驻留在T-Cache中,能够有效延长执行线索在T-Cache的驻留时间,提升了系统效率。
5.2 替换策略的改进
T-Cache的替换策略在T-Cache管理优化中发挥着重要作用,由于STB的引入,需要改进原有的替换策略。
T-Cache已有的替换策略包括:全清空策略(Full Cache Flush)采用的方法是一旦T-Cache空间不足,则清空全部T-Cache内容。该算法实现简单,但性能不高,未考虑基本块的热度;最近最少使用策略(Least-Recently-Used)考虑了热度的影响因素,一旦T-Cache空间不足,淘汰最近使用最少的基本块,但该策略由于替入块与替出块的大小不同,容易形成存储空间的碎片;先进先出策略(First-In-First-Out)采用队列作为数据结构,一旦T-Cache空间不足,淘汰排在队头的基本块。该策略可以有效减少空间碎片,但未考虑热度影响。分时清空策略(Preemptive Flush)根据程序的运行情况,在特定时域内采用全清空处理。该策略被Dynamo[12]平台采用,可以有效降低热块的损失。
由于新构建的NewCache丰富了T-Cache系统的翻译缓存类型,结合工程实际,本文针对不同缓存类型采用不同的替换策略。针对OldCache,仍然使用简单的全清空策略;针对NewCache,为了提高管理效率,采用先入先出的替换策略,将超块按照先后顺序从地址低位向高位依次存放,当NewCache满时,将先进入的超级块淘汰。该策略实现简单,和全清空策略相比,可以较好地提升查找效率,延长STB的存活时间。
6 实验
6.1 实验环境
本文将提出的优化方法在开源二进制翻译器QEMU1.7.2[13]中进行了实现。使用了如表 1所示的实验环境,源平台采用的是X86-64架构处理器;本地平台采用的是国产SW410处理器。测试用例选取了SPEC 2006(Standard Performance Evaluation Corporation)测试集,它是由标准性能评估公司组织建立的一套用于计算机系统评估的业界标准测试集。

Table 1 Test environment表1 实验环境
6.2 热代码识别测试
使用SPEC 2006中的部分用例对HCFS算法的识别效果进行了测试,因为此项测试只涉及热代码的识别,不涉及超块的构造及T-Cache管理策略的改进,为此,测试时注释掉了T-Cache优化部分的代码,图3和表2分别展示了热代码识别情况和对应的频度统计造成的开销情况。
图3中,定义热代码识别率HCR(Hot Code Ratio)来描述识别效果,HCR=Nhotcode/Nallcode×100%。公式中,Nhotcode代表用例的热代码包含的基本块数量;Nallcode代表用例的基本块的总数;HCR代表热代码中的基本块占用例基本块总数的比率,HCR数值越大,说明用例的热代码识别效果越好。从测试结果可以看出,用例h264ref和sjeng的识别效果较好,识别率分别达到29.73%和23.45%,gobmk和libquantum的识别效果较差,识别率只有0.14%和0.98%。
表2展示了每个用例的profiling开销情况,第二列Time1表示未进行频度统计时的用例执行时间;第三列Time2表示进行频度统计时的用例执行时间;第四列表示频度统计造成的开销情况,Profiling开销比=(Time2-Time1)/Time1×100%。

Table 2 Cost of profiling for hot code表2 热代码profiling开销
测试数据说明,识别热代码时造成的profiling开销与热代码的识别情况直接相关,识别效果越好的用例,profiling时间开销越大,反之,开销越小。例如,用例sjeng和h264ref的开销分别达到5.02%和5.86%,而用例gobmk的开销只有0.14%。另外,测试结果也说明在未使用T-Cache优化方法前,热代码识别只能带来负收益。

Figure 3 Performance test of HCFS algorithm图3 HCFS算法性能测试
6.3 T-Cache管理的改进测试
为测试改进的T-Cache查找算法和替换策略效果,实验记录了对OldCache和NewCache使用分层查找方法并配合使用改进的替换策略时的运行时间,此项测试包含了全部优化代码。表3和图4以不同形式展现了使用改进的T-Cache管理策略时的优化效果。表3以表格的形式展现了测试用例使用优化方法前后的时间以及优化加速情况,Tori表示优化前的运行时间,Topt表示优化后的运行时间,定义加速比Ratio=1-Topt/Tori×100%描述加速效果,Ratio值越小,表明优化效果越好。图4以柱状图的形式展现了各个用例的加速情况。
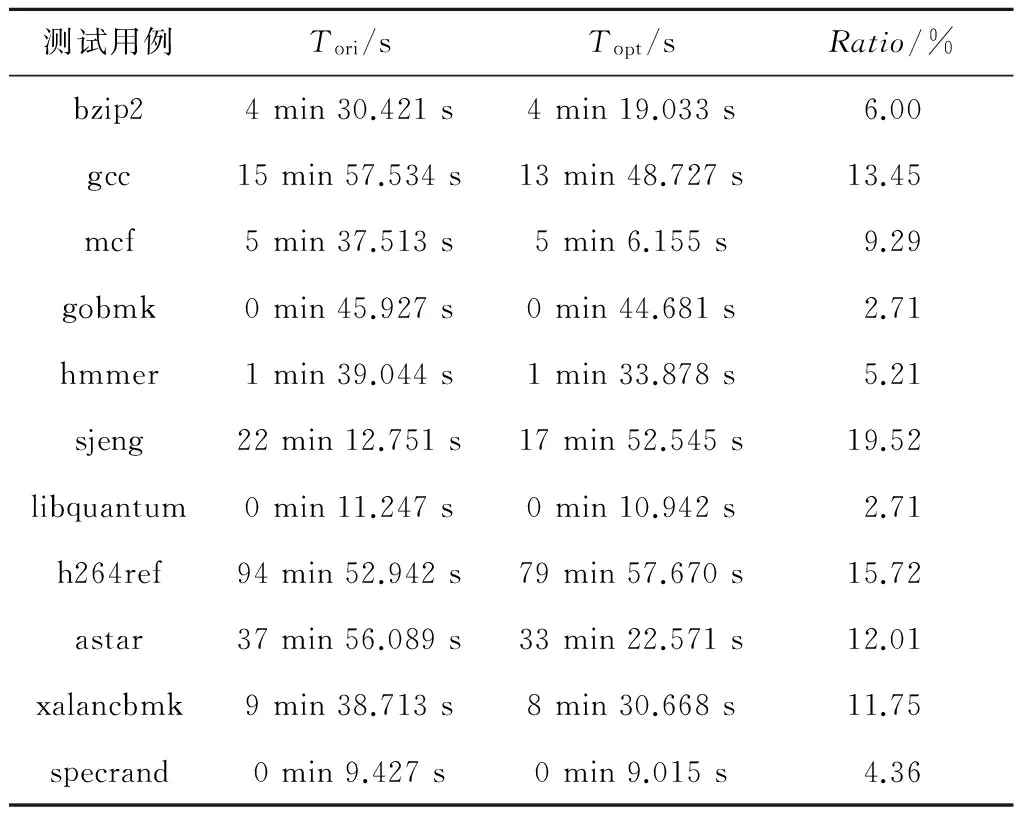
Table 3 Test of optimization method of T-Cache表3 T-Cache优化方法测试

Figure 4 Test of optimization method of T-Cache图4 T-Cache优化方法测试
显然,使用改进方法后,翻译系统的执行效率得到了明显提升,测试用例sjeng和h264ref的加速效果最明显,分别达到了19.52%和15.73%。所有用例的平均加速比达到9.34%。
7 结束语
本文以“热代码识别→超块缓存构造→T-Cache管理策略改进”为优化线索,提出了一个提升动态二进制翻译效率的方法。通过热代码的识别和超块的构造,为改进T-Cache的原有管理策略打下了基础。引入了热代码的概念,通过在动态翻译过程中对基本块的执行情况进行即时监控和统计,实现了对执行频度高的热代码的识别。为了使热代码能够常驻翻译缓存,通过构造“超块”的方法,将热代码中的基本块重新链接,形成了容量更大的翻译缓存。引进超块后,通过引入双层查找策略,以及采用新的替换策略,提高了超块的使用率,同时也增加了T-Cache的命中率。该优化方法的正确性和带来的收益在国产申威处理器平台上进行了实验验证。下一步,需要进一步考虑翻译缓存中OldCache和NewCache的不同占比情况对优化效果的影响。
参考文献:
[1] Cai Song-song,Liu Qi,Wang Jian,et al.Optimization of binary translator based on GODSON CPU[J].Computer Engineering,2009,35(7):280-282.(in Chinese)
[2] SW410[EB/OL].[2014-03-26].http://www.shenweimicro.com/.
[3] Altman E,Kaeli D,Sheffer Y.Welcome to the opportunities of binary translation[J].IEEE Computer,2000,33(3):40-45.
[4] Gschwind M, Altman E R,Sathaye S,et al.Dynamic and transparent binary translation[J].IEEE Computer,2000,33(3):54-59.
[5] Cifuentes C,Malhotra V.Binary translation:Static,dynamic,retargetable?[C]∥Proc of International Conference on Software Maintenance,1996:340-349.
[6] Li Jian-hui, Ma Xiang-ning,Zhu Chuan-qi.Dynamic binary translation and optimization[J].Journal of Computer Research and Development,2007,44(1):161-168.(in Chinese)
[7] Shi H,Wang Y,Guan H,et al.An intermediate language level optimization framework for dynamic binary translation[J].ACM SIGPLAN Notices,2007,42(5):3-9.
[8] Ball T,Mataga P,Sagiv M.Edge profiling versus path profiling:The showdown[C]∥Proc of the 25th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages,1998:734-148.
[9] Dhodapkar A S,Smith J E.Comparing program phase detection techniques[C]∥Proc of the 36th Annual IEEE/ACM International Symposium on Microarchitecture,2003:217.
[10] Shi Hui-hui,Guan Hai-bing,Liang A-lei.Hot path optimization in software dynamic binary translation[J].Journal of Computer Engineering,2007,33(23):78-80.(in Chinese)
[11] Spink T,Wagstaff H,Franke B,et al.Efficient code generation in a region-based dynamic binary translator[C]∥Proc of the 2014 SIGPLAN/SIGBED Conference on Languages,Compilers and Tools for Embedded Systems,2014:3-12.
[12] Bala V,Duesterwald E,Banerjia S.Dynamo:A transparent dynamic optimization system[J].Proceeding of ACM SIGPLAN Notices,2000,35(5):1-12.
[13] Bellard F.QEMU,a fast and portable dynamic translator [C]∥Proc of the Annual Conference on USENIX Annual Technical Conference,2005:41-46.
附中文参考文献:
[1] 蔡嵩松,刘淇,王剑,等.基于龙芯处理器的二进制翻译器优化[J].计算机工程,2009,35(7):280-282.
[6] 李剑慧,马湘宁,朱传琪.动态二进制翻译与优化技术研究[J].计算机研究与发展,2007,44(1):161-168.
[10] 史辉辉,管海兵,梁阿磊.动态二进制翻译中热路径优化的软件实现[J].计算机工程,2007,33(23):78-80.
