面向网络通信的高实时压缩引擎设计*
2018-05-08任秀江周建毅谢向辉
任秀江,王 磊,周建毅,谢向辉
(1.江南计算技术研究所,江苏 无锡 214083;2.数学工程与先进计算国家重点实验室,江苏 无锡 214125)
1 引言
现代高性能计算系统由高性能处理器和高性能互连网络两大主要组件构成。近些年来,随着微电子集成电路工艺的迅猛发展,单硅片上可集成的电路数量越来越多,极大地促进了以GPU(Graphics Processing Unit)、Xeon Phi为代表的新型高性能众核处理器的发展,推动着处理器性能持续按照摩尔定律发展,将单个计算结点的计算能力提高到了前所未有的高度。例如,NVIDIA的最新GPU芯片Tesla K80能够提供2.91 TFLOPS的双精度浮点计算性能[1],Intel最新款的Xeon Phi 7120X的峰值性能也达到了1.238 TFLOPS[2],应用于“神威太湖之光”的国产申威26010众核处理器双精度浮点峰值性能超过3 TFLOPS[3]。而在互连网络方面,受限于Serdes工艺的发展,互连网络的带宽每年以大约26%的速度提高,远低于处理器性能59%的提高速度。有研究预计,到2020年,远程结点的访存延迟将达到惊人的670 000个FLOPS的执行时间,而带宽只能达到0.05 b/FLOPS[4]。互连网络的延迟和带宽已成为制约高性能计算机性能提高的瓶颈之一[5]。
为提高互连网络性能,已经有很多研究人员从不同角度做了大量工作,比如高效的新型网络拓扑结构、均衡的网络负载算法、提高链路传输工艺等方面。本文从减少网络注入数据量的角度出发,对高性能互连网络通信中的数据压缩技术进行研究,基于数据相似性原理,给出了一种高性能的实时压缩网络传输引擎设计,在发送端进行数据压缩、接收端进行数据解压缩,实现了对用户透明的硬件压缩数据通信方式,通过减少网络传输数据量来降低网络负载。
本文剩余部分章节安排如下:第2节给出了相关研究,介绍了无损数据压缩原理和主要算法,总结了实时压缩算法的发展以及实现中存在的问题;第3节介绍了网络通信中的数据传输引擎结构,根据网络包在数据传输引擎中的处理过程,给出了基于数据特征分析的实时数据压缩引擎设计;第4节对所实现的数据压缩引擎进行了模拟实验分析;第5节对全文进行了小结。
2 相关研究
在计算机科学和信息论中,对数据压缩的定义是:按照某种特定的编码机制,用比原始数据少的数据比特(或其他信息单位)表示信息的过程。数据压缩是利用缩减数据量来达到提高数据传输、存储和处理效率的目的。
2.1 无损数据压缩
根据压缩数据复原后与原始数据是否有差别,数据压缩可以分为有损压缩和无损压缩两大类。有损数据压缩是通过牺牲数据中的次要信息来减少数据量,提高压缩比,主要应用于多媒体领域。无损数据压缩则是通过减少冗余数据的方式来缩减数据量,无损压缩后的数据在复原后与原始数据完全一致。在高性能计算领域,不允许数据损失,需使用无损压缩。
按照寻找冗余信息的方式不同,无损压缩算法可以分为基于统计的方法和基于字典的方法两大类。Huffman编码、Arithmetic编码、Shannon-Fano算法等是基于统计无损压缩的典型代表[6],它们需要统计原始数据中各个字符的频率,然后依据统计信息对输入字符进行重新编码,从而达到减少数据量的目的。Lempel-Ziv类算法[7,8]属于基于字典的算法,基本思想是选择输入数据流中已经出现过的字符串作为字典,后续数据流中再有相同的字符串出现,则使用该字典中指向该字符串的指针来代替。基于字典的压缩算法中,字典的选择对压缩效果影响特别大。
在无损数据压缩算法中,无论是基于统计还是基于字典的方法都需要对压缩数据进行字符串分析匹配等预处理操作,这需要大量的逻辑运算操作,对计算能力要求高,一般都采用CPU处理器专门处理,有的甚至采用专门的ASIC芯片或GPU加速器来加速处理[9 - 11]。通常情况下,压缩比越高,压缩算法的处理时间越长。
2.2 高实时性压缩算法
近些年来,一些新型高实时性的压缩算法被提出并应用于片上Cache和访问主存的数据中,用于节省访存带宽和提高访存效率。文献[12]给出了一种基于差值的实时压缩算法BDI(Base-Delta-Immediate),BDI算法的原理是利用数据相似性[13 - 15],计算输入数据相对于基值计算偏移值Delta,只要Delta值的位表示小于原始值位宽,就能达到减少数据量的目的。BDI压缩算法最大的好处是实时性,易于硬件快速实现,具有较小的压缩/解压缩延迟性。文献[16,17]发现频繁从主存中读出或写入的数据值大多数集中在一个范围内;文献[18]利用这个特性给出了FVC(Frequent Value Compression)算法,可以用较少的bit位标识重复的数值。FVC的基本原理与前面所述基于字典的压缩算法类似,只是所用字典容量较小,简化了数据统计的过程,能够达到高实时性、低硬件开销的目标。
文献[19]则发现大多数数据都具有一定的模式规律。例如,32 bit数据中的高16 bit都是0或者都是1,或者4 B中的每个字节都相同。FPC(Frequent Pattern Compression)就是利用这种规律来压缩数据。文献[20]给出了一种叫做C-Pack的FPC压缩算法,能够将多个等长度的数据段压缩为1个数据段,实现多个word字并行压缩。与FVC类似,当出现同一个数据段内的字有的能压缩,有的不能压缩时,解压缩过程串行化。为了优化解压缩延迟,文献[21]中实现了5级流水的解压缩设计,来缓解解压缩的延迟压力;文献[22]则针对数据段中混合的压缩数据和非压缩数据的片上管理给出了一种新型管理架构。
2.3 高速互连网络中的数据压缩问题
通过前面的研究可以知道,高效的数据压缩算法是建立在对数据规律的分析基础上的。高实时性环境中,对数据处理的低延迟需求决定了对数据不能过多迭代分析,在高实时性环境中实现数据压缩要解决好压缩效率和压缩延迟的矛盾关系。
在高性能计算系统中,对高速互连网络的延迟、带宽都有严格的要求,对通信数据进行压缩能够带来减少通信数据量的好处,但是不能以牺牲通信延迟或降低通信带宽为代价。因此,对高速互连网络中的通信数据进行压缩时,所面临的挑战不仅仅是算法的压缩收益,还要解决算法的实时性、硬件可实现性等问题。

Figure 1 Structure of data transmission engine and processing flow of a packet图1 数据传输引擎结构和网络包处理过程
3 网络通信数据压缩
本节根据网络接口中数据传输引擎的结构特征,实现了一种高效流水的硬件数据压缩、解压缩机制,在不需要用户干预、不影响原有通信性能的前提下,实现对通信数据自动压缩/解压缩处理,能够降低网络上数据传输量,相当于提高了网络传输效率。减少网络上的数据传输量,对降低实际应用过程中的网络系统负载也有积极意义。
3.1 网络接口与数据传输引擎
高速互连网络由路由器、网络接口组成。其中,路由器的互连构成网络的拓扑结构;网络接口则是计算结点与网络的中间桥梁,通过配置不同的网络接口,计算结点可以接入不同的互连网络中。
如图1所示,数据传输引擎是网络接口中的主要组成部件,按照数据传输的方向,数据传输引擎分为数据发送和数据接收两个模块。数据发送部件DSU(Data Send Unit)负责从计算结点主存中读取数据,按照传输协议组织成网络包后注入网络。数据接收部件DRU(Data Receive Unit)则是从网络中接收网络包,解析网络包中控制信息,将数据写入结点主存。
众所周知,处理器为了优化访存性能通常会设置片上缓存Cache,为了提高主存访问效率内存控制器中也会设置各种缓冲,为了保持数据在主存和片上缓存、以及片上缓存间的一致性,对主存的访问粒度通常设置为Cache行大小,Cache行的大小一般为32字节或64字节。
处理器之间的通信则需要通过互连网络以消息传输的方式进行。消息通信与处理器核心访存相比,通信距离远延迟大,网络包中不仅包含有效数据,还包含一些必要的通信控制信息(如路由信息等),这些有效负荷之外的内容也会占用网络传输带宽。为提高一次网络通信的有效带宽,增加网络包中有效负荷是常用的办法,一个网络包中的最大数据量通常为几百字节到几千字节[23],一般都比处理器中Cache行的容量大。
如图2所示,网络包与主存访问粒度之间的差异,通常由网络接口中的数据传输引擎来处理。一个网络包的产生、传输和接收过程中,需要在数据传输引擎中进行两次存储转发。我们在网络传输引擎中加入压缩、解压缩部件,利用存储转发的过程优化压缩算法实现,完成网络包的压缩和解压缩过程,减少网络包的实际传输长度。
(1)网络包生成阶段:在数据发送模块中,缓存主存数据,完成压缩后转发到高速互连网上;
(2)网络包接收阶段:在数据接收模块中,缓存网络包,完成解压缩后转发写入主存。

Figure 2 Processes of sending and receiving a packet图2 网络包发送和接收过程
3.2 基于数据特征预分析的实时压缩引擎
在DSU中实现了实时数据压缩引擎RTCE(Real-Time Compress Engine),RTCE由数据特征分析模块DFU(Data Feature-analysis Unit)和压缩网络包生成模块PCU(Packet Compression Uint)两部分组成。数据特征分析模块对离散返回的访存数据进行特征过滤,并保存分析结果;网络包的所有数据都返回后,PCU模块根据数据特征分析结果,对数据进行压缩,然后将压缩数据和压缩说明信息(Compress Direction)一并生成网络包,发送到互连网络中。
3.2.1 压缩网络包格式
实时压缩算法的主要原理是利用数据的空间局部相似性特征。网络通信中,网络包数据量较大,若以网络包为单位进行压缩,不仅并行压缩器的开销大,还可能存在数据相似性较差导致压缩收益低的问题;若以访存粒度为单位进行压缩,压缩单位数量增加,附加的压缩说明信息比例增大,也会影响压缩效果。
为解决这个问题,在网络包粒度和访存粒度之间寻找一个折衷的数据量单位实现数据压缩,称为压缩数据块CDB(Compress Data Block)。如图2a所示为网络包悬挂缓冲条目、压缩数据块CDB、访存响应之间的粒度大小关系。数据压缩后的数据块需要携带数据块压缩说明DCI(Data Compress Information),到达目标结点后,数据传输引擎可以根据DCI对CDB进行解压缩。如图3a和图3b所示,分别为不带压缩数据网络包和带压缩数据网络包PCD(Packet with Compress Data-block)的格式。PCD的有效负荷中携带了DCI,DCI信息在网络传输中属于数据压缩的开销。如果数据块不能压缩或者压缩后网络包负荷大于压缩前,DCI的存在会增加网络传输量,可以在网络包传输信息中采用标记位来区分压缩网络包和非压缩网络包。
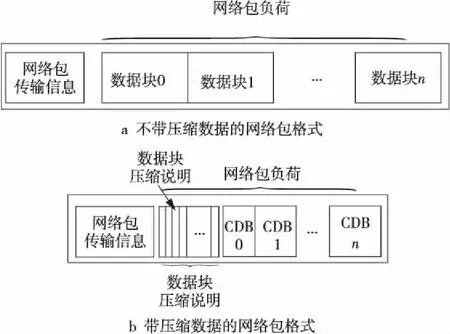
Figure 3 Structure of a network packet图3 网络包结构
3.2.2 数据特征分析
从前面第2节的介绍中可以知道,BDI算法和FVC算法易于硬件实现,是常用的实时压缩算法。图4为两种算法的压缩原理示意图,可以看到两种压缩算法的压缩效率与Base基值粒度和数值选择都有很大关系。

Figure 4 Principle of real time compression algorithm图4 实时压缩算法原理示意
RTCE中同时选择BDI算法和FVC算法作为压缩算法。使用DFU模块在访存响应数据返回阶段,对数据特征进行分析。DFU模块中选择了7种压缩算法对数据进行过滤,7种算法如表1所示。访存响应数据返回时,DFU累计每种压缩算法的压缩收益。数据块的访存数据全部返回后,DFU形成对CBD内数据压缩收益评估。在PCU进行数据压缩时,根据DFU模块的评估结果,选择收益最高的压缩算法对数据进行压缩传输。

Table 1 Description of the hybrid compression algorithm表1 混合压缩算法组成说明
3.2.3 压缩网络包生成和解压缩
网络包的所有访存数据返回后,PCU部件开始压缩网络包。按照数据块顺序,从DFU中读取数据块的压缩说明DCI,根据压缩说明中提示的压缩算法,对数据块中的数据进行压缩移位,然后将压缩后的数据块保存到网络包发送缓冲中;等到网络包中所有数据块都完成压缩处理后,再将网络包发送到互连网络中,网络包发送过程中将压缩数据移位拼接成连续数据。
由于压缩后的数据移位逻辑较长,为优化时序将网络包的生成和发送分为上述两阶段进行。如图1中所示,为保证网络包流水传输,PCU中设置多份数据压缩逻辑。接收部件处理压缩网络包的过程正好相反,先将网络包解析为压缩数据块,再由数据块还原为原始数据,最后写入主存中。
4 模拟实验与分析
对实时压缩引擎RTCE进行了RTL编码实现,建立了模拟仿真环境,从数据压缩收益和数据处理效率两个方面对RTCE进行了测试。第3节中分析的不同压缩数据块大小划分,对压缩收益可能会有影响。模拟实验中,配置了64 B、128 B、256 B、512 B四种不同数据块大小的情况,比较不同数据分块大小对数据压缩效率的影响。
为了保证测试数据的真实性,选择从通用测试题和实际应用课题两个方面,抽取数据流轨迹作为RTCE的测试源数据。SPEC2006是业界通用测试集,包含了各个领域的应用测试题,从SPEC2006[24]测试集选择了20道数据密集型测试题,抓取测试题运行过程中的数据流轨迹用作测试数据;Graph500是衡量计算机处理数据密集型应用能力的测试基准,从Graph500中抓取不同运行阶段的通信数据流轨迹用作测试数据;此外,还对并行应用课题化学非平衡流CFD(Computational Fluid Dynamics)算法[25]中的通信数据进行了压缩测试。
4.1 数据压缩性能测试
实验中使用压缩收益来表述压缩结果,即压缩后数据减少量占原数据量的比例进行表述,比例越大表示数据被压缩的幅度越大,压缩效果越好。
压缩收益 = (原始数据量-压缩后数据量)/ 原始数据量

Figure 5 Data compression results of tests图5 测试课题数据压缩结果
图5a所示为SPEC2006测试题中抽取数据的压缩结果,每个测试题按数据块大小分别测试了四组压缩实验。从图5结果可以看到,20道测试题的数据压缩收益均在20%以上,有12道测试题的数据压缩收益达到30%,测试题libquantum的数据压缩收益最高达到47%,平均数据压缩收益为32.8%。
图5b所示为Graph500测试题中抽取数据的压缩结果,横坐标上s16、s18、s20、s22表示测试题的不同运行阶段的通信数据。从图5b中可以看到,Graph500测试题中各阶段数据的压缩收益达到47%以上。在课题运行初期的s16阶段,采用512 B数据块时压缩收益最高达到52.9%,平均数据压缩收益为48.7%。
图5c所示为CFD算法中通信数据的压缩结果,横坐标为不同计算结点发出的通信数据。从图5c中可以看到,数据压缩收益在38%~51%,平均数据压缩收益为46.2%。

Figure 6 Comparison of compression gains for different data block sizes图6 不同数据块大小的压缩收益比较
图6中对不同数据块大小下的压缩收益进行了比较。SPEC2006中的测试题结果显示,不同数据块大小对大多数课题的压缩收益没有太大影响,差异最大的是omnetpp测试题,压缩收益差异范围小于5%;从Graph500中数据测试结果来看,数据块越大压缩效果越好,但差异范围也在5%以内;CFD算法的数据结果中,数据块越大数据压缩收益越大,但差异程度较小,在6%以内。综上可以知道,RTCE采用不同数据块划分下的数据压缩收益变化不大,差异小于6%。
最后,在CDB数据块为64 B的情况下,对RTCE中采用的混合压缩算法与各个单一压缩算法进行测试比较。从图7的对比结果可以看到,与单一压缩算法相比,采用混合算法的压缩收益提高明显。有些测试数据采用单一压缩算法甚至出现了数据量增加的情况,这是因为不同的测试课题数据具有不同的特征,采用单一算法虽然能够简化硬件设计复杂度,但也同时降低了压缩结构的适用范围。
4.2 RTCE引擎实现开销评估
RTCE引擎增加的数据压缩逻辑和解压缩逻辑,通过增加数据缓冲将数据的移位拼接分为数据块间和数据块内两步进行,通过增加有限的启动延迟,保证了压缩/解压缩过程的处理流水。在NC-Verilog模拟环境观测增加的启动延迟小于20个时钟节拍。在28 nm工艺下,采用标准单元库对RTCE的RTL代码进行了逻辑综合和后端物理设计,时序分析结果显示RTCE能够运行在1 GHz以上;布局布线后,RTCE的面积开销为2 744 132.493 1 μm2,其中压缩/解压缩组合逻辑开销占比7.8%,面积开销占比16.4%,面积开销增加主要是由于压缩/解压缩逻辑中增加了大量SRAM构成的存储器所致。

Figure 7 Comparison of compression gains for different compression algorithms图7 不同算法压缩收益比较
5 结束语
本文对实时数据压缩进行了研究,面向网络通信给出了一种实时压缩网络传输引擎RTCE设计,实现了对用户透明的硬件压缩数据通信方式;使用SPEC2006、Graph500等测试题中数据流轨迹对RTCE进行了压缩测试实验,实验结果表明经过RTCE后数据量平均减少35.4%;在应用课题CFD算法的数据测试中,压缩后数据量平均减少46.2%。NC-Verilog模拟结果显示,RTCE的数据处理过程流水,传输带宽不变,启动延迟增加20个时钟节拍,压缩/解压缩逻辑面积开销仅增加16.4%。综上所述,RTCE实现了通信数据的硬件压缩,能够在不降低数据传输引擎性能的前提下,减少网络注入数据量,对通信带宽日益宝贵的高性能互连网络有一定的现实意义。
最后,感谢为本文工作提供测试数据帮助的张昆博士、林恒博士、刘鑫博士。
参考文献:
[1] http://images.nvidia.com/content/tesla/pdf/nvidia-tesla-k80-overview.
[2] https://www.intel.com/content/www/us/en/high-performance-computing/high-performance-xeon-phi-coprocessor-brief.html.
[3] https://www.top500.org/system/178764.
[4] Graham S,Snir M,Patterson C.Getting up to speed:The future of supercomputing [J].National Academies Press Washington Dc,2004,149(1):147-153.
[5] Ang J, Brightwell R, Donofrio D, et al. Exascale computing and the roll of co-design[J].Advance in Parallel Computing,2012,20:43-64.
[6] Hu Yu-chen,Chang Chin-chen.A new lossless compression scheme based on Huffman coding scheme for image compression [J].Signal Processing:Image Communication,2000,16(4):367-372.
[7] Ziv J,Lempel A.A universal algorithm for sequential data compression[J].IEEE Transactions on Information Theory,1977,23(3):337-343.
[8] Shun J,Zhao F.Practical parallel lempel-Ziv factorization[C]∥Proc of Data Compression Conference,2013:123-132.
[9] Ozsoy A,Swany M.CULZSS:LZSS lossless data compression on CUDA[C]∥Proc of IEEE International Conference on CLUSTER Computing,2011:403-411.
[10] Ozsoy A, Swany M,Chauhan A.Pipelined parallel LZSS for streaming data compression on GPGPUs[C]∥IEEE,International Conference on Parallel and Distributed Systems.IEEE Computer Society,2012:37-44.
[11] Erdodi L. File compression with LZO algorithm using NVIDIA CUDA architecture[C]∥Proc of 2012 4th IEEE International Symposium on Logistics and Industrial Informatics(LINDI),2012:251-254.
[12] Pekhimenko G,Seshadri V,Mutlu O,et al.Base-delta-immediate compression:Practical data compression for on-chip caches[C]∥Proc of International Conference on Parallel Architectures and Compilation Techniques,2012:377-388.
[13] Collange S,Defour D,Zhang Y.Dynamic detection of uniform and affine vectors in GPGPU computations[C]∥Proc of International Conference on Parallel Processing,2009:46-55.
[14] Collange S,Kouyoumdjian A.Affine vector cache for memory bandwidth savings:Technical Report ensl-00649200[R].ENS de lyon,University de lyon,2011.
[15] Kim J,Torng C,Srinath S,et al.Microarchitectural mechanisms to exploit value structure in SIMT architectures[C]∥Proc of International Symposium on Computer Architecture,2013:130-141.
[16] Lefurgy C,Bird P,Chen I,et al.Improving code density using compression techniques[C]∥Proc of the 13th IEEE/ACMInternational Symposium on Microarchitecture,1997:194-203.
[17] Orosa L, Azevedo R. Temporal frequent value locality[C]∥Proc of the 27th International Conference on Application-specific Systems,Architectures and Processors(ASAP),2016:147-152.
[18] Lee Y, Krashinsky R, Grover V,et al.Convergence and scalarization for data-parallel architectures[C]∥Proc of IEEE/ACM International Symposium on Code Generation and Optimization,2013:1-11.
[19] Alameldeen A R,Wood D A.Adaptive cache compression for high-performance processors[C]∥Proc of International Symposium on Computer Architecture,2004:212-223.
[20] Chen X,Yang L,Dick R P,et al.C-pack:A high-performance microprocessor cache compression algorithm [J].IEEE Transactions on Very Large Scale Integration Systems,2010,18(8):1196-1208.
[21] Alameldeen A R,Wood D A.Frequent pattern compression:A significance-based compression scheme for L2 caches:Technical Report 1500[R].Madison:University of Wisconsin-Madison Department of Computer Sciences,2004.
[22] Pekhimenko G,Seshadri V,Kim Y,et al.Linearly compressed pages:A low-complexity,low-latency main memory compression framework[C]∥Proc of IEEE/ACM International Symposium on Microarchitecture,2013:172-184.
[24] Standard Performance Evaluation Corporation.SPEC CPU2006 benchmark [EB/OL].[2016-04-21].http://www.spec.org/cpu2006.
[23] InfiniBand Architecture specification[EB/OL].[2000-10-24]. http://www.infinibandta.org.
[25] Wang Z J, Fidkowski K,Abgrall R,et al.High-order CFD methods:Current status and perspective [J].International Journal for Numerical Methods in Fluids,2013,72(8):811-845.
