一种阵列众核处理器的多级指令缓存结构*
2018-05-08陈逸飞李宏亮高红光
陈逸飞,李宏亮,刘 骁,高红光
(江南计算技术研究所,江苏 无锡 214083)
1 引言
处理器是高性能计算机的核心器件,其主要参数指标对整个系统的结构和能力起着决定性作用。近年来,众核处理器在学术界和工业界都得到了广泛关注和蓬勃发展,当前主要的众核处理器和众核结构包括NVIDIA公司的GPU架构[1]、Intel公司的MIC和SCC架构[2]、AMD公司的GPU/APU系列[3]以及申威26010架构、MIT的RAW[4]、Stanford的ELM[5]、Tilera公司的TILE[6]、中国科学院计算技术研究所的Godson-T[7]、Adapteva公司的Epiphany[8]、Kalray公司的MPPA[9]、PEZY-SC处理器[10]等。其中申威26010架构、TILE、Godson-T、Epiphany、MPPA、PEZY-SC等均属于阵列众核处理器,其特点是以阵列方式(Mesh)组织众多计算核心,具有可扩展性优秀、实现代价小、功耗低、可提供多层次并行性的优势,是众核处理器发展的重要方向。
阵列众核处理器的不断发展,依然面临着严峻的挑战,一是“访存墙”问题。众核处理器的“计算/访存比”高,部分访存受限的课题呈现计算资源闲置问题,随着大数据时代的到来,访存密集的课题呈现增长趋势,导致这一问题更加显著。二是核心协同问题。阵列众核处理器中“运算核心——应用进程”存在映射关系,用户需要考虑应用进程的分布、同步协作以及局部存储如何高效利用的问题,对编程要求较高;同时,“运算核心——运算核心”之间的连接关系,进程之间的数据交换需要通过片上网络进行,片上网络通信频繁,通信模式也日趋复杂,对片上网络的设计和使用都提出了很高的要求。
在阵列众核处理器中,引入同时多线程技术SMT(Simultaneous Multithreading)[11],是解决上述问题的可能途径,通过多线程技术能够提高片上资源利用率,较强的多线程核心局部存储资源和大量在共享存储中进行的数据交换能够进一步提升运算性能;同时,多线程技术能够让操作系统代替用户进行线程调度,用户得以更高视角进行编程。
阵列众核处理器资源紧张、结构复杂,单个核心可用的计算和存储资源都非常有限,和传统的多线程结构不同,面向阵列众核处理器的多线程结构,需要高度关注开销与性能的平衡,需要对存储结构进行进一步的优化,提高SMT处理器的整体性能,以缓解上述“访存墙”以及核心协同两个问题。
本文首先建立了符合阵列众核处理器特点的实验平台,以SPEC2006为目标应用,基于资源约束条件,对单核单线程以及单核多线程进行了全面对比,分析阵列众核结构可能存在的多线程瓶颈。实验结果表明,随着线程数的增加,由于资源限制,一级指令Cache的命中率明显降低,导致IPC(Instruction Per Cycles)低于单线程。对此,本文提出面向众核处理器的一种冗余指令Cache的结构,并研究了相关的替换策略,分别为FIFO(First Input First Output)替换策略以及类LRU(Least Recently Used)替换策略。其中,FIFO替换策略实现Cache行按照先入先出的顺序被替换出Cache;类LRU替换策略对LRU替换策略进行了改进,标记最近被重用的Cache行具有更高的优先级,使其被保留在Cache中不被替换。实验分析表明,使用类LRU替换策略的冗余指令缓存效果更优,该结构能够减少25.2%的整体指令Cache结构失效率,同时带来30.2%的CPI性能提升。
本文第2节介绍相关工作;第3节对阵列众核结构多线程模型进行分析;第4节提出针对多线程模型进行的优化存储结构;第5节为实验方法与结果;第6节总结全文,并对未来工作进行展望。
2 相关工作
2.1 阵列众核处理器的分类
根据计算核心的结构复杂度和组织方式,可以将众核处理器分为基于通用处理核心和基于计算簇的众核处理器两大类。
基于通用处理核心的众核处理器可以看作是多核结构处理器的进一步延伸,通过片上互连网络NoC(Network on Chip)集成众多的通用处理器核心。Intel的Larrabee处理器、MIC架构处理器和SCC架构处理器[2]都属于这一类,其主要特点为:(1)计算核心一般由通用核心简化而来,所有核心功能齐全、计算能力强,但通常没有过于复杂的指令调度、推测执行等结构;(2)计算核心内的运算部件支持SIMD(Single Instruction Multiple Data),通常为位宽很大的SIMD,以提高聚合计算能力;(3)单核心内通常会保留通用处理器中传统的多级Cache存储结构,核心间有的会支持Cache一致性,有的则会采用简化的显式消息替代Cache一致性。
基于计算簇的众核处理器片上集成了大量简单的计算核心,旨在通过简单运算部件的聚合提供超高计算性能。NVIDIA和AMD的GPU系列产品[1,3]都属于这一类众核结构,其主要特点为:(1)计算核心为简单计算部件,多个核心以组或簇的形式进行组织,可通过SIMT方式提供强大的并行计算能力;(2)计算簇内所有计算核心共用指令发射单元,并共享寄存器文件、一级Cache等存储资源,计算簇间则共享二级Cache和主存等;(3)片上通常还集成有大量专用加速处理部件。
2.2 阵列众核处理器结构介绍
阵列众核处理器的特征是多个计算核心以阵列方式(Mesh)组织,可以分为同构阵列众核处理器和异构阵列众核处理器两类。同构阵列众核全部由计算核心阵列构成,异构阵列众核在计算核心阵列外还有额外的管理核心,本文采用异构阵列众核处理结构作为研究基础。
阵列众核处理器整体结构如图1所示,包括管理核心MPE(Management Processing Element)、计算核心阵列CPA(Computing Processor Array)、存控以及系统接口,四个部分通过片上网络NoC互连。其中,管理核心MPE作为通用核心,支持乱序发射、乱序执行和推测执行;计算核心阵列CPA由若干计算核心CPE(Computing Processing Elements)以阵列方式组织构成;CPE是功能简单的运算核心,支持SIMD指令以开发细粒度的并行性,提高峰值性能,用以加速大规模的并行任务。CPE之间的数据交换通过阵列内高速的片上通信进行[12]。
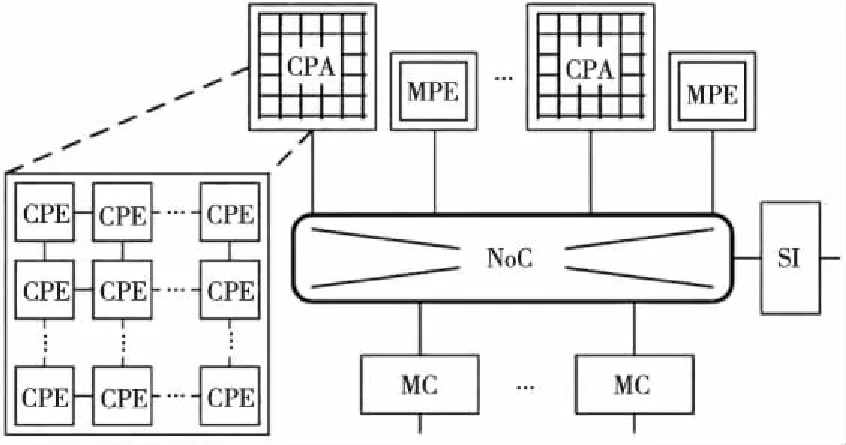
Figure 1 Structure of array-based many-core processor图1 阵列众核结构
2.3 同时多线程技术应用情况介绍
由于通过开发指令级并行来提高执行并行度、进而提高处理器性能受到了诸多因素的限制,学术界和工业界将目光更多地集中在了线程级并行上面,并提出了许多有效的线程级并行解决方案。多线程技术作为线程级并行的主要开发方向之一,能够更精细地共享处理器资源,提高处理器的利用率。
同时,多线程技术允许在一个时钟周期发射多个线程的多条指令执行,减少了由于资源冲突导致处理器无法启动之后周期所造成的“垂直浪费”,以及缺乏足够指令级并行时,处理器无法最大限度地同时启动各种操作所造成的“水平浪费”,提高了处理器发射槽和功能部件的利用率。
在同时多线程处理器的共享Cache资源中,一级Cache是线程访问最频繁的一部分。多线程对于有限的Cache资源的竞争,将导致指令间的相互冲突愈加明显,指令吞吐率性能下降。解决该问题的方法通常有两种,增大Cache的容量或提高Cache的利用率。
SUN的Ultra-SPARC T2处理器具有64个线程,共享一个8体的二级Cache,采用多体交叉Cache技术。该技术将Cache分成多个体,每个体可以被线程独立访问。多体Cache技术需要一个交换网络来将请求从装载存储单元传递到相应的Cache体,体数的增加将使得交换网络的面积增加,同时延长线程Cache体的访问时间。在恰当地调度访存地址流的情况下,多体Cache可以极大地提高Cache的访存带宽[13]。但是,当线程对于Cache体的访问出现冲突时,将极大地影响性能。
Tullsen等人[14]对多线程处理器结构的仿真结果表明,在同时多线程处理器中,多个线程对资源(如Cache、转换检测缓冲TLB(Translation Lookaside Buffer)以及分支目标缓冲BTB(Branch Target Buffer)等)的共享会影响性能。如果单线程的指令Cache失效率为1,那么8个同时多线程的指令Cache失效率将达到14,Tullsen等人提出一种让每个线程都使用私有指令Cache的方法,以减少指令间的相互冲突和干扰。但是此方法在资源极度受限、一级指令Cache通常只有4~8 KB的阵列众核处理器中,不易实现,为每个线程分配单独的指令Cache将大大增加硬件开销。
类似于上述方法,文献[15]提出一种多模块多体的Cache结构设计方案,在独立的总线之间采用多个模块,同一总线内部采用多个体。具体来说就是将一级数据Cache分成n个模块,保持它们之间能够并行访问;同时,在每个模块的内部,又包含着n个体,一次只能对其中的一个进行访问。每个线程的数据只能存储于一个唯一的Cache体中,实际上这种方法是对Cache做了显式的划分。但是,这种显式的固定划分必定会带来一个问题,当某一线程产生大量的访存请求时,划分给它的Cache资源并不一定能够满足其需求,从而影响整体性能。此结构并不能根据线程的访存特性来动态地划分Cache资源,对于性能的提升具有局限性。
3 阵列众核处理器多线程模型分析
针对阵列众核处理器的结构和多线程模型的需求,本文搭建了面向阵列众核处理器结构的实验平台和相关环境,总体结构如图2所示。
本文选取SPEC2006作为测试基准,使用Simpoint工具[16]生成测试各程序的基本块向量(Basic Block Vector)文件,分析基本块向量文件中各测试程序的模拟点,结合权重文件,得到各程序核心段。在此基础上,对GEM5模拟器[17]进行二次开发改造,在系统调用模拟SE(System-call Emulation)模式下使用Out of Order乱序CPU模型,对发射宽度、存储带宽、组相联数、Cache配置等进行修改调试,以符合阵列众核结构特定背景。最后通过对各测试程序进行实验,由输出的数据文件分析CPU性能,将输出的CPU行为文件进行分段,编写xml模板文件输入集成功率面积和时序的多核模拟工具MCPAT(MultiCore Power, Area and Timing)生成相应的功耗及面积文件。
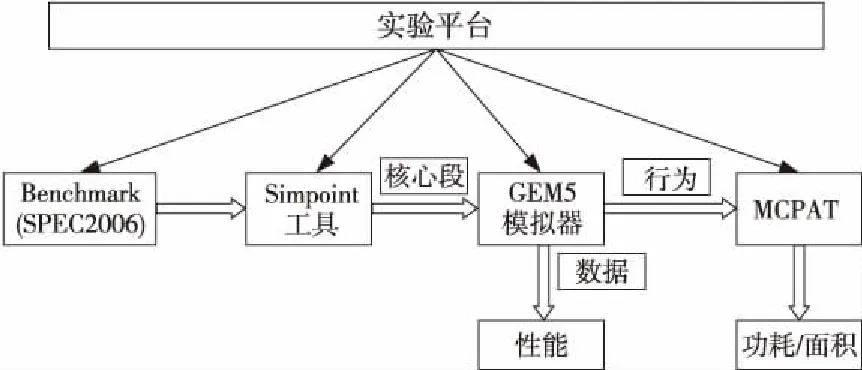
Figure 2 Experimental platform for array-based many-core processor图2 阵列众核处理器结构多线程实验环境
实验针对阵列众核处理器的单个核心结构进行,其单个核心的特点表现在:(1)存储空间通常较小,如PEZY-SC单个核心的存储空间为8 KB,申威众核单个核心的局部存储空间为24 KB;(2)逻辑资源相对紧张,难以支持太多线程;(3)众核核心数量众多,单个核心分配到的访存带宽相对较少等。
为研究阵列众核处理器的多线程瓶颈,针对阵列众核结构特点,对单核单线程、单核双线程、单核四线程分别进行发射带宽、组相连路数、一级Cache参数配置修改、保持配置大小随着线程数成倍增长等进行实验,对比分析单核心下多线程瓶颈。主要实验参数如表1所示。
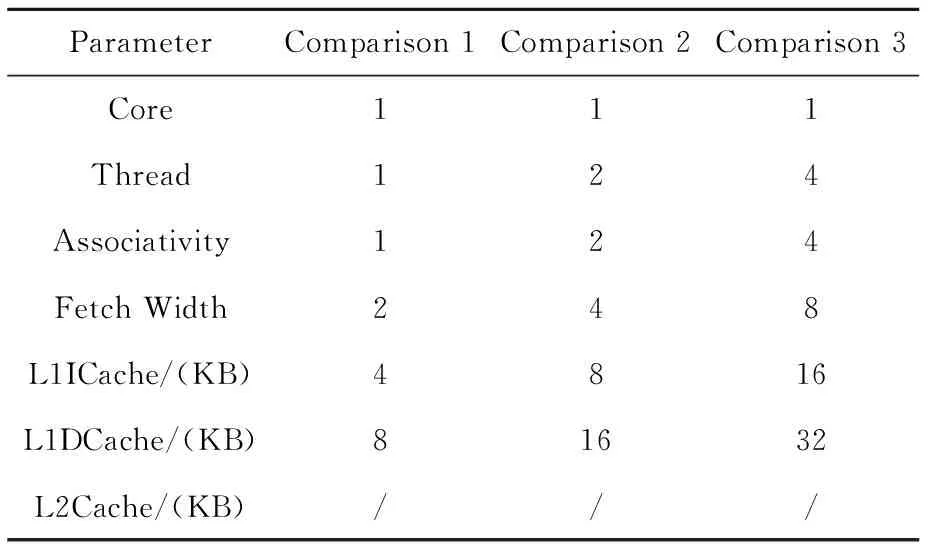
Table 1 Main parameter configuration of contrast experiments表1 对比实验主要参数配置表 B
对比各程序CPI、一级指令Cache、数据Cache失效率,如图3和图4所示。
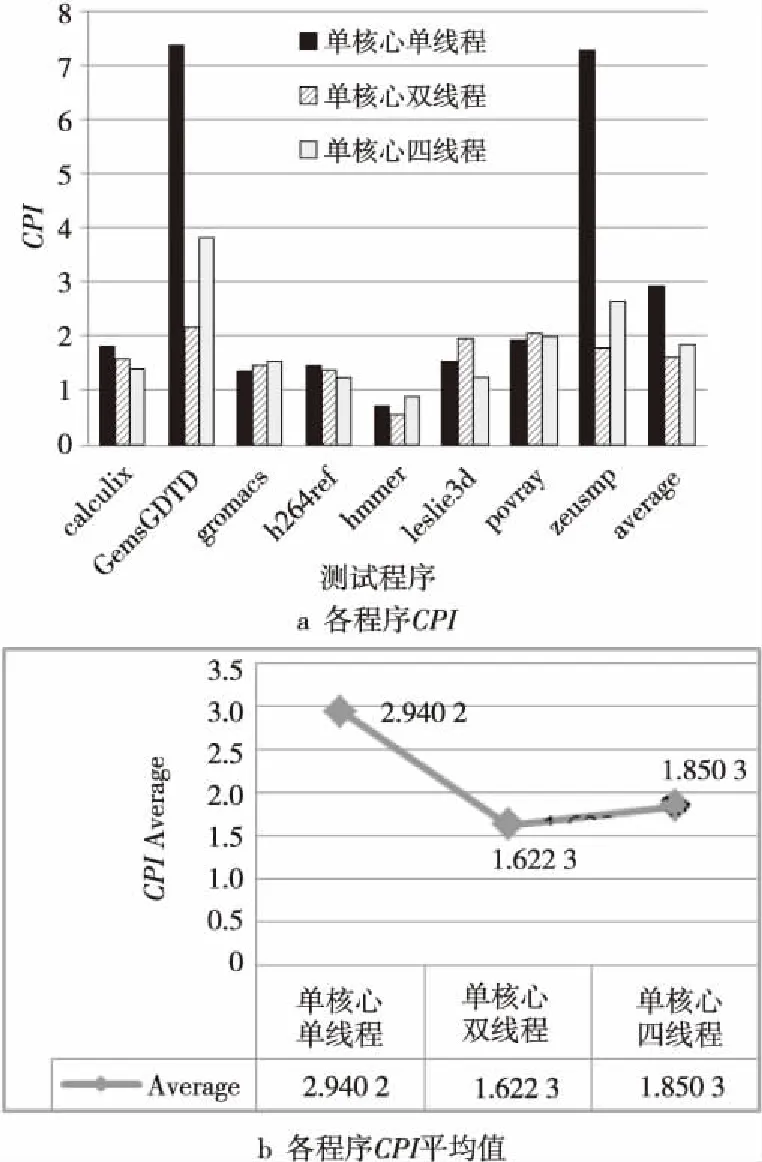
Figure 3 Comparison of each program’s CPI and its average in the configuration of single-core single-thread,single-core dual-thread and single-core quadruple-thread图3 单核心单线程/双线程/四线程情况下 各程序CPI及平均值对比
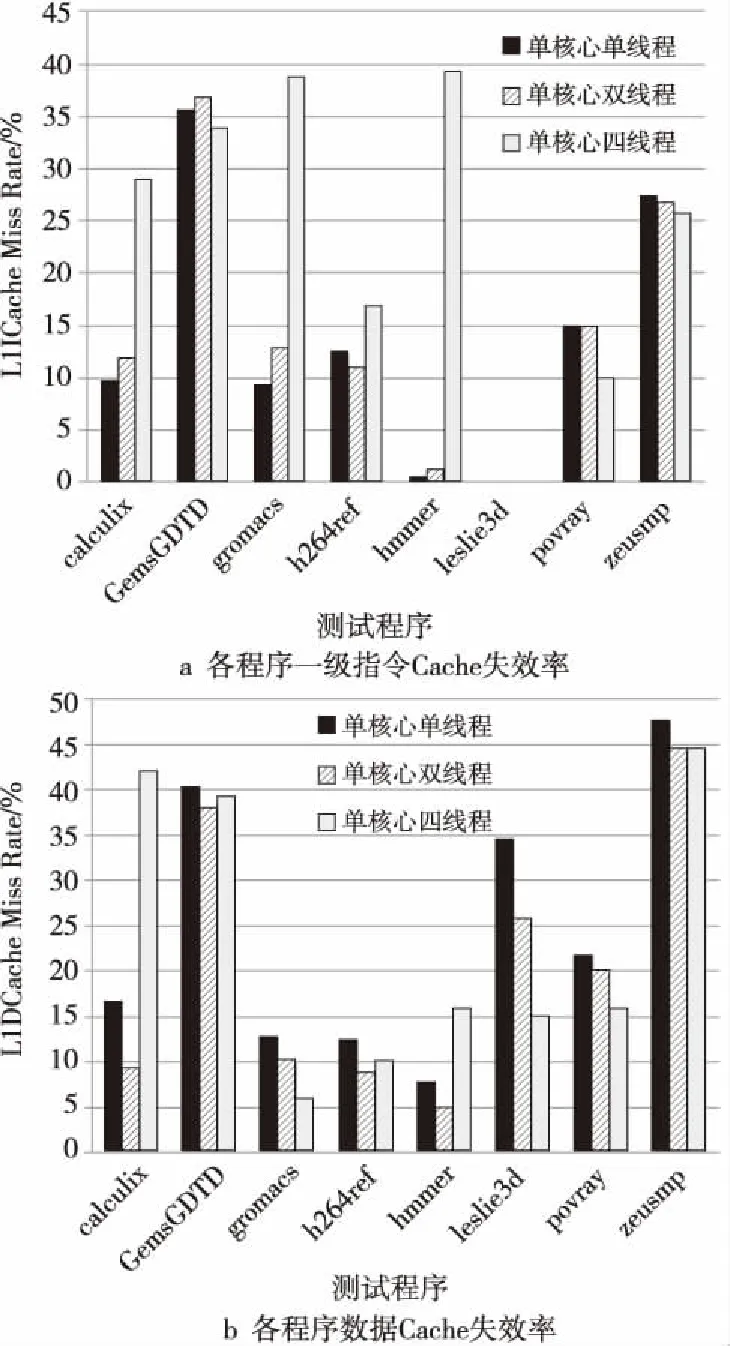
Figure 4 L1ICache and L1DCache miss rates of each program in the configuration of single-core single-thread,single-core dual-thread and single-core quadruple-thread图4 单核心单线程/双线程/四线程情况下 各程序一级指令、数据Cache失效率
从图3可以分析得到,在双线程配置下,各程序CPI平均值最为优异,而随着线程数增长到4时,CPI平均值反而有所上升。结合图4,指令Cache以及数据Cache失效率情况,当线程数增加到4时,虽然数据Cache失效率变化不明显,个别程序中甚至有所降低,但是指令Cache失效率有着明显的增长,较单线程结构上升了76.1%,较双线程结构上升了67.7%。
SMT的优势是提高了指令吞吐率,增加了资源利用率,但由于共享流水线资源导致某些资源被过度利用,如指令队列、Cache、TLB和执行单元等。在单核心单线程配置下,保持组相连数、线程数等参数不变,配置指令Cache放大一倍时的实验数据可得,指令Cache失效率较原有情况下降30.1%,说明指令Cache容量的增大有效地降低了失效率。
但是在上述实验中,尽管随着线程数的增长,指令Cache也相应增加,但由于指令Cache空间太小,指令间的相互冲突和干扰导致指令Cache失效率上升,多个线程在一个共享的指令Cache结构中相互颠簸。由图5可以看出,在其他配置均相同的情况下,两线程核心指令Cache中Cache行的替换次数大幅增加,在阵列众核结构下,指令Cache的失效率情况成为多线程阵列处理器的主要瓶颈。
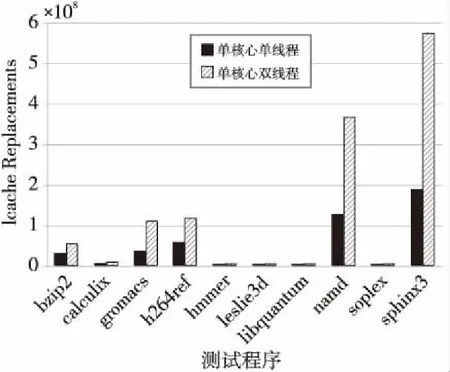
Figure 5 L1ICache replacements of each program in the configuration of single-core single-thread and single-core dual-thread图5 单核心单线程/双线程情况下 各程序一级指令Cache行替换数
4 冗余指令缓存结构设计方案
在多核处理器中已经有多种方法降低指令Cache失效率,如在指令Cache上对多个线程进行分区隔离,包括静态分区等。但是,在资源紧张的阵列众核处理器中,这些方法都不再适用,主要原因是阵列众核核心的一级指令Cache容量较小,静态分区将导致各线程能够有效使用的Cache容量降低,而动态分区将引入较复杂的控制逻辑,增加硬件实现开销。
观察到双线程核心指令Cache中Cache行替换次数的大幅增加,本文提出在一级指令Cache之下加入冗余指令Cache(Redundancy ICache)结构,缓存结构如图6所示。
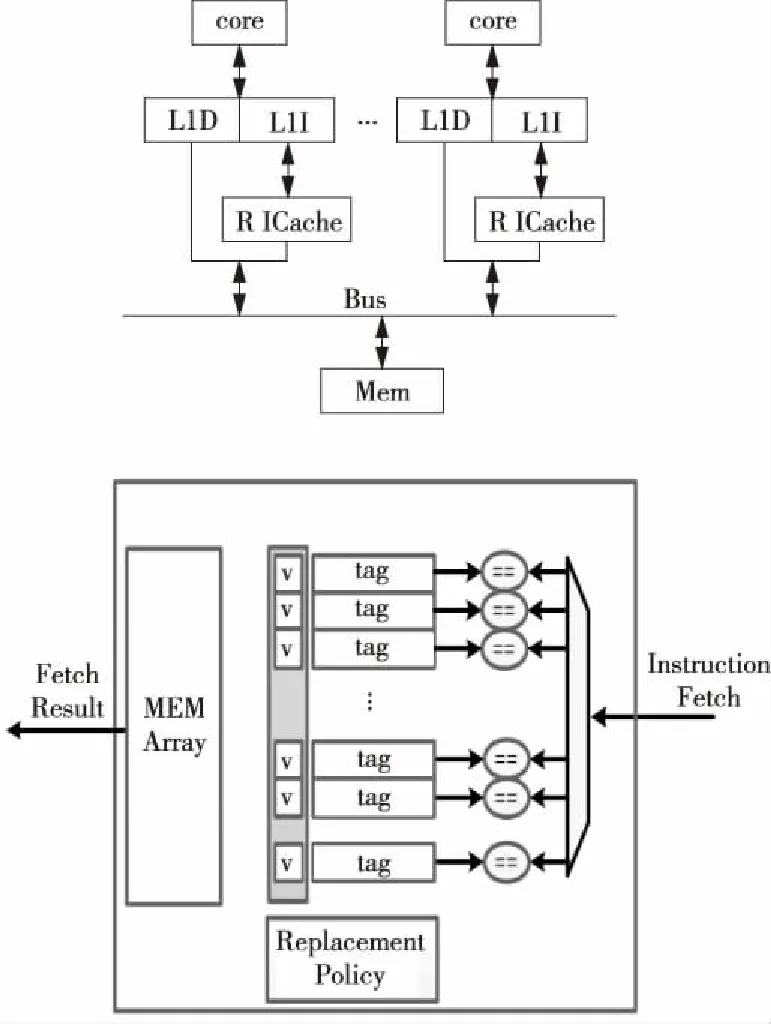
Figure 6 Structure of redundancy ICache图6 冗余指令缓存结构图
冗余指令Cache与一级指令Cache全相连,通过总线与主存连接。冗余指令Cache记录从一级指令Cache脱靶(Miss)和替换(Victim)的指令。图7为冗余指令缓存的工作流程图。该结构的提出使得在访问主存前,先检查其中是否存在其所需要的Cache块,若存在,则直接取,就不必再去访问主存,从而降低了整体访问延时。此结构能够有效减少访存时间,降低失效率,从而降低功耗。
冗余指令Cache设计为一个容量小、访问速度快、全相连结构的指令Cache。其中Tag阵列和Memory阵列均采用标准的全相连Cache设计。由于容量小,且希望尽可能装载有最具重用可能的Cache行,本文研究在全相连的冗余指令Cache中的替换策略,分别研究了两种替换策略:
(1)FIFO策略:所有Cache行按先入先出的顺序被替换出Cache。
(2)类LRU策略:本文提出一种类LRU替换策略(Analogous Least Recently Used),标记最近被重用的Cache行具有更大的优先级,保证其在这段时间内不被替换,被替换块将从优先级低的Cache块中选取。此替换策略基于重用次数,为每个Cache块附加一个重用计数器,并在全局设置一个指针,当Cache行发生替换时,从指针位置开始搜索数据阵列,直到找到重用计数器指数最低的项将其作为替换项替换出冗余指令缓存。重用计数器的初始状态为零,每次对Cache行命中后,计数器加1。
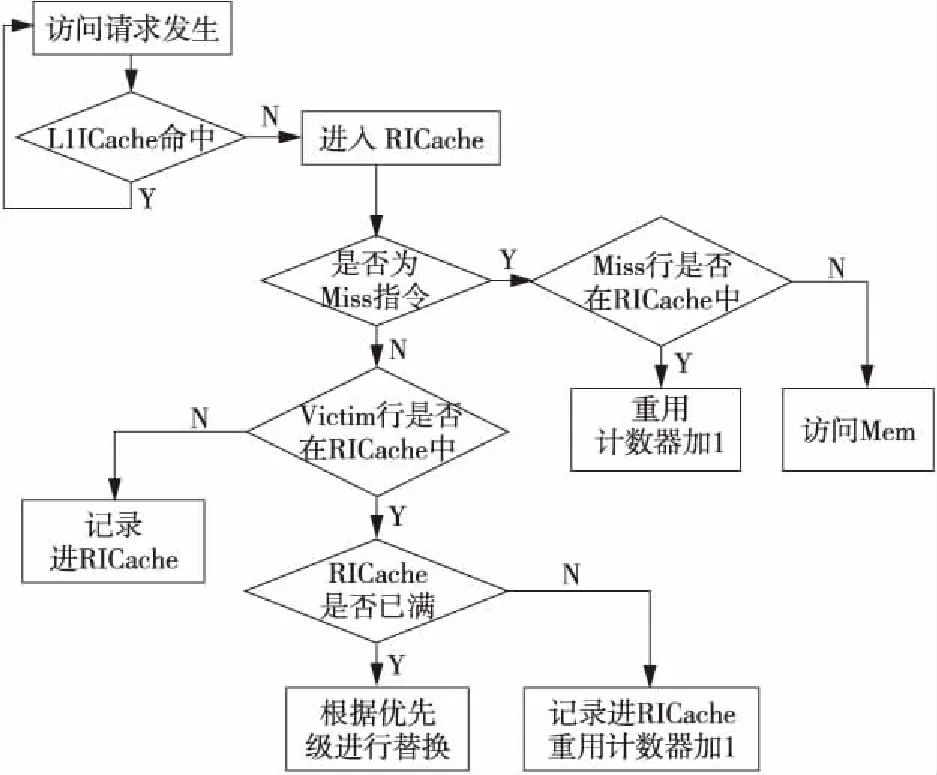
Figure 7 Flow diagram of redundancy ICache图7 冗余指令缓存流程图
5 实验方法与结果
5.1 实验方法
本文通过第3节所述实验平台,进行冗余指令缓存性能的对比实验测试。实验中GEM5模拟器主要配置如表2所示。
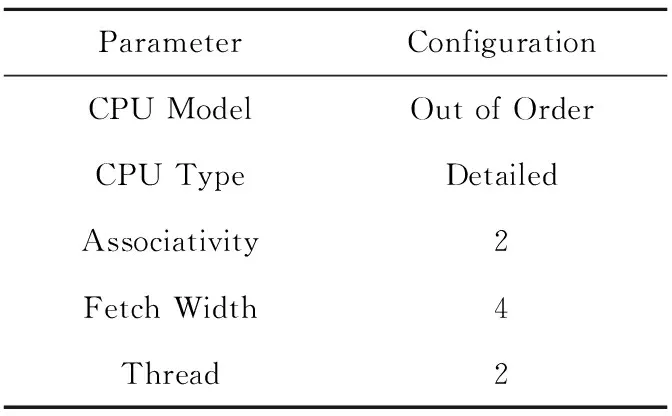
Table 2 Parameter configuration of GEM5 simulator表2 模拟器参数配置表
本文选用了SPEC2006中的12道程序进行测试,具体程序如表3所示。
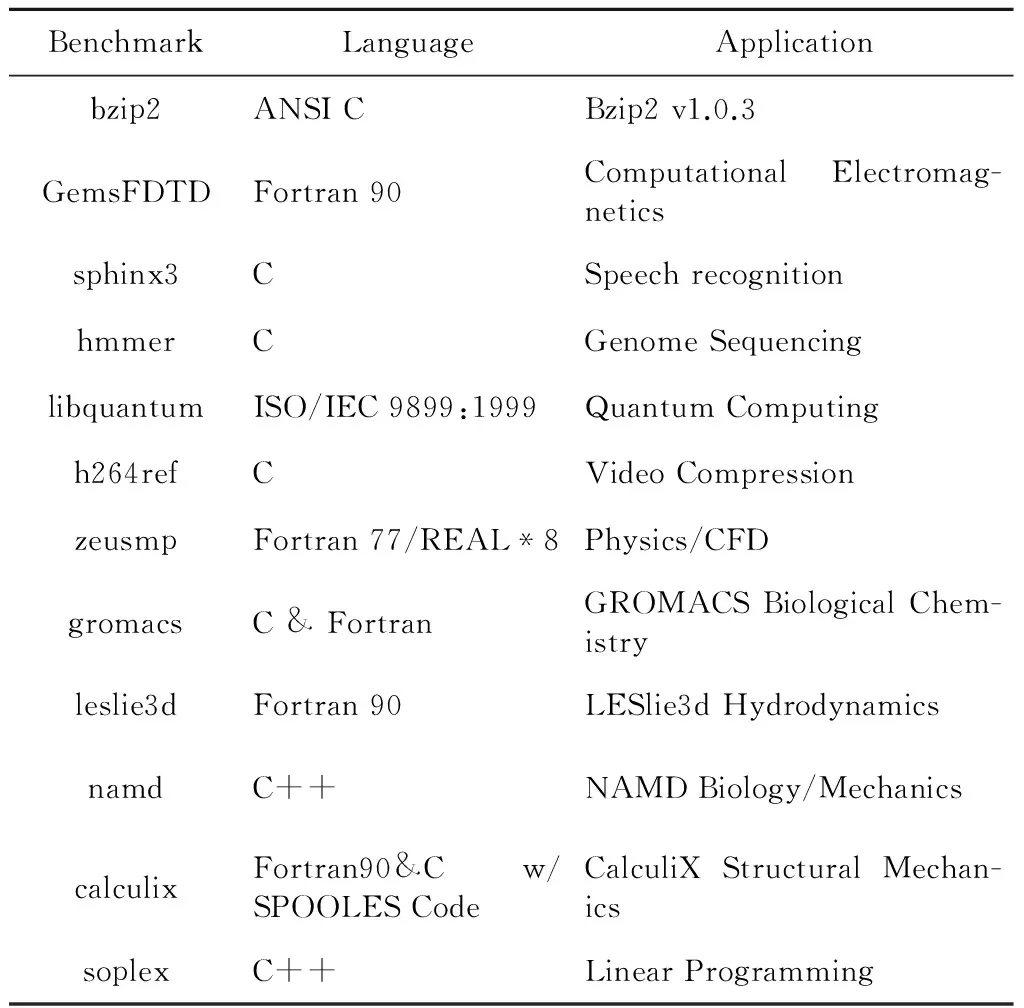
Table 3 Table of benchmarks表3 测试程序表
单核双线程情况下,各组对比实验配置如表4所示。
5.2 实验结果
实验配置为单核双线程配置,组相联数为2,取指宽度为4,一级指令Cache为8 KB,一级数据Cache为16 KB,实现两种替换策略:(1)类LRU策略;(2)FIFO策略。为对比得出冗余指令Cache带来的性能提升,分别采取:(1)将一级Cache放大一倍;(2)增加大小为64 KB的二级Cache;(3)增加大小为256 KB的二级Cache三种结构进行对比。
图8为实验中6个不同配置下各程序CPI值及其平均值,横坐标给出了12道测试程序,纵坐标为各程序的CPI值。图9为各配置下CPI的平均值对比。图10展示了6种配置下的一级指令Cache失效率,横坐标给出了12道测试程序,纵坐标为各程序的指令Cache失效率。图11为使用两种替换策略的冗余指令Cache在各道程序中的命中率对比。对比6个CPI平均值可以发现,配置使用类LRU替换策略的冗余指令Cache的表现仅次于配置核心独享256 KB的二级Cache的结构,但优于配置核心独享64 KB的二级Cache的结构。
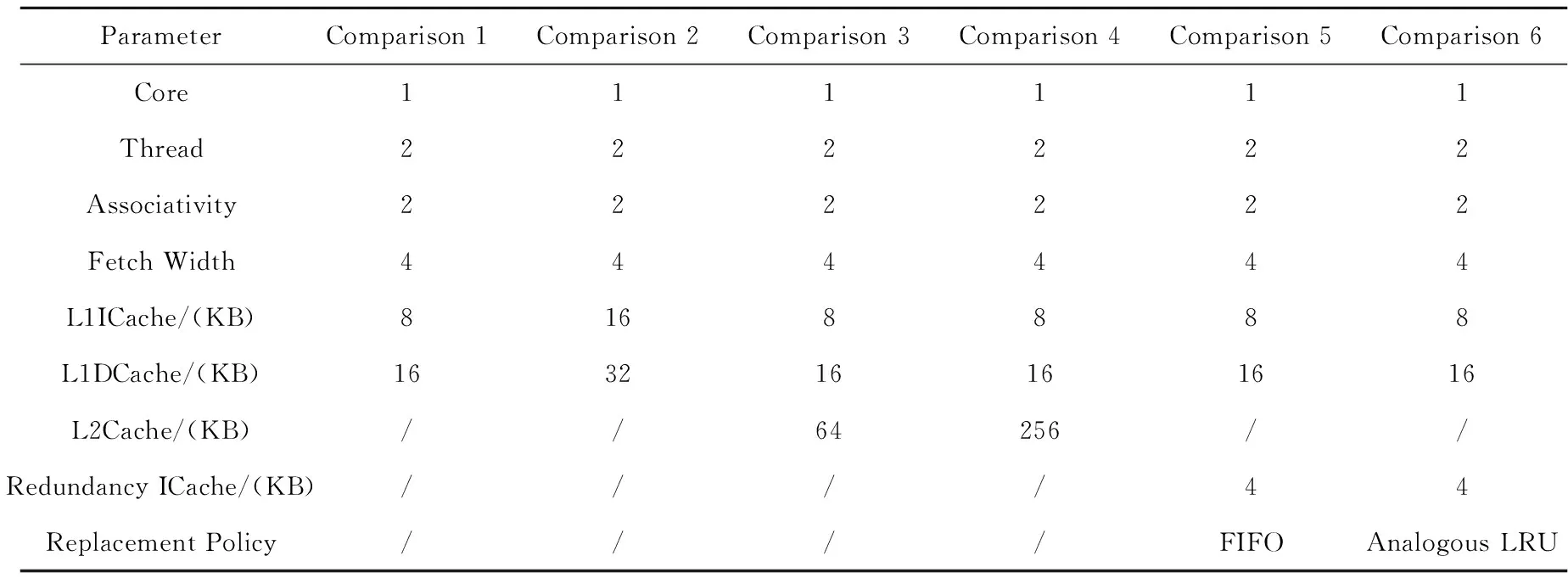
Table 4 Parameter configuration of experiments表4 对比实验参数配置
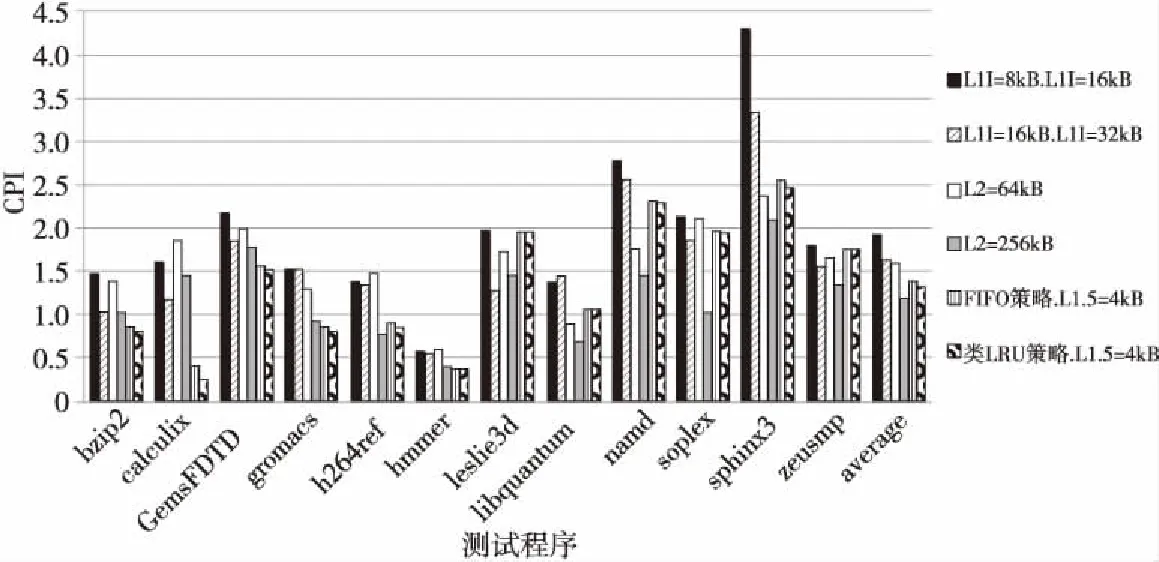
Figure 8 Comparison of CPI in each configuration图8 各配置下各程序CPI对比
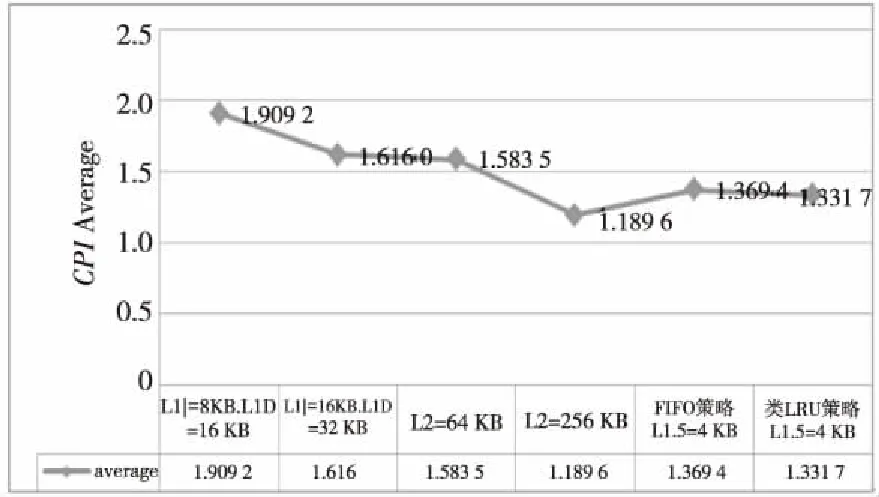
Figure 9 Comparison of the average of CPI in each configuration图9 各配置下各程序CPI平均值对比
从图9可以看出,当一级Cache放大一倍时,整体CPI得到优化,但效果不明显。结合图10具体分析,绝大部分程序的指令Cache失效率未得到有效降低,说明简单放大一级Cache容量并不能大幅提升指令Cache的命中率。主要原因是指令Cache空间的使用频率很不平衡,大量未使用的Cache行一直处于空闲状态,Cache行存在着严重的冲突缺失问题,当此问题发生在线程循环处时,将严重影响性能。另一方面,成倍增大一级Cache使得硬件资源的开销成倍增加,不符合阵列众核结构资源受限的背景。
分析两种配置核心独享型的二级Cache的对比实验,由图8及图9可发现,在配置256 KB的二级Cache下,CPI指数得到了显著优化。结合图10进一步分析,除去个别几道指令Cache失效率增长的程序,两种情况下一级指令Cache的失效率普遍降低,但变化不明显。为单核心配置独享的二级Cache后,尽管访问速度得到提高,但是二级Cache会产生核间存储访问需求的不平衡,导致更多的访问失效,从而影响整体资源利用率。同时,原有的一级指令Cache尚未被充分使用,依旧存在着大量的空闲Cache行,指令间的相互冲突也未被有效地消除。二级Cache的加入也使得设计更加复杂,硬件开销增大。
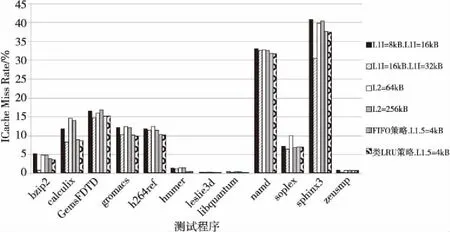
Figure 10 ICache miss rate of each configuration图10 对比实验各配置下指令Cache失效率
使用两种替换策略的冗余指令Cache均能有效优化CPI,CPI指数分别降低28.3%(使用FIFO策略)和30.2%(使用类LRU策略)。仅次于配置256 KB的二级Cache结构,优于配置64 KB的二级Cache结构。图9表明,两种替换策略的整体指令Cache的失效率较之未配置以及配置二级Cache时得到了显著降低,失效率分别下降24.3%(使用FIFO策略)和25.2%(使用类LRU策略)。说明当一级指令Cache中被丢弃或替换的Cache行,在两种替换策略下均被有效地收入冗余指令Cache中。当下一次发生相同地址的Cache行丢弃时,能够直接从冗余Cache中取出相应的Cache行,从而有效提高了整体缓存结构的命中率。单独配置一个大小为4 KB的冗余指令Cache,硬件开销相对较小,且性能优于配置64 KB的二级Cache结构,符合阵列众核处理器资源极度受限的背景。
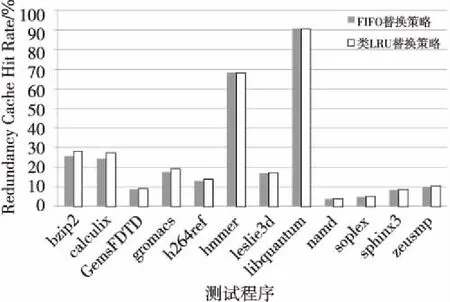
Figure 11 Comparison of redundancy Cache hit rate using FIFO and analogous LRU图11两种替换策略下冗余缓存命中率对比
分别对比两种不同的替换策略,根据图11可得类LRU替换策略表现更优。可以说明,在冗余指令Cache中,类LRU替换策略通过利用栈结构记录最近被重用的Cache行,标记其具有更高的优先级,使其保留在Cache中不被替换,得到了更加优异的表现效果,更符合全相联的冗余指令Cache结构。FIFO策略并未考虑程序的执行特点,可能会增加Cache行换出的次数,从而降低性能,并且增加开销。
6 结束语
阵列众核处理器已经广泛应用于高性能计算领域,为了构建未来高性能计算系统处理器,必须解决严峻的“访存墙”挑战以及核心协同问题。本文研究了阵列众核处理器单核心多线程结构的存储结构优化问题,通过实验得出多线程结构存在着一级指令Cache失效率高,导致整体性能无法得到提高的问题。针对这一问题,本文提出了一种冗余指令Cache的存储结构,在GEM5模拟器上实验评估了这一方案,并对其性能进行了分析,得出了以下结论。
(1)在使用类LRU替换策略的冗余指令Cache的结构下,整体结构的CPI提高30.2%,优于配置64 KB核心独享的二级Cache结构,并且此结构带来的硬件开销小、功耗低,适用于资源极度受限的阵列众核结构;(2)在上述结构下,通过解决SMT核心运行时易发生Cache行冲突的问题,使得整体Cache结构的失效率较未配置时下降25.2%,这在一定程度上缓解了阵列众核处理器多线程模型下一级指令Cache失效率高的问题。
未来工作可以考虑针对该冗余指令Cache的调度策略进行研究,以进一步提高性能。同时,基于上述优化的片上存储层次结构,在阵列众核背景下,进行核心簇的结构研究工作。
参考文献:
[1] Keckler S W,Dally W J,Khailany B,et al.GPUs and the future of parallel computing[J].IEEE Micro,2011,31(5):7-17.
[2] Saule E,Catalyurek ÜMit V.An early evaluation of the scalability of graph algorithms on the Intel MIC architecture[C]∥Proc of Parallel and Distributed Processing Symposium Workshops & PhD Forum,2012:1629-1639.
[3] Dan B,Sander B.Applying AMD’s Kaveri APU for heterogeneous computing[C]∥Proc of 2014 IEEE Hot Chips 26 Symposium,2014:1-42.
[4] Taylor M B,Kim J,Miller J,et al.The raw microprocessor:A computational fabric for software circuits and general-purpose programs[J].IEEE Micro,2002,22(2):25-35.
[5] Dally W J,Balfour J,Black-Shaffer D,et al.Efficient embedded computing[J].Computer,2010,41(7):27-32.
[6] Wentzlaff D,Griffin P,Hoffmann H,et al.On-chip interconnection architecture of the tile processor[J].IEEE Micro,2007,27(5):15-31.
[7] Fan D,Zhang H,Wang D,et al.Godson-T:An efficient many-core processor exploring thread-level parallelism[J].IEEE Micro,2012,32(2):38-47.
[8] Olofsson A, Nordstrom T,Ul-Abdin Z.Kickstarting high-performance energy-efficient manycore architectures with Epiphany[C]∥Proc of 2014 Asilomar Conference on Signals,Systems and Computers,2014:1719-1726.
[9] Dinechin B D D,Massas P G D,Lager G,et al.A distributed run-time environment for the Kalray MPPA-256 integrated manycore processor[C]∥Proc of International Conference on Computational Science,2013:1654-1663.
[10] Sakamoto R, Nitadori K. Implementation and evaluation of data-compression algorithms for irregular-grid iterative methods on the PEZY-SC processor[C]∥Proc of the Workshop on Irregular Applications:Architectures & Algorithms,2017:58-61.
[11] Tullsen D M, Eggers S J,Levy H M. Simultaneous multithreading:Maximizing on-chip parallelism[C]∥Proc of International Symposium on Computer Architecture,1995:392-403.
[12] Zheng Fang, Zhang Kun, Wu Gui-ming, et al. Architecture techniques of many-core processor for Chinese Journal of Computers, 2014,37(10):2176-2186.(in Chinese)
[13] Shah M,Barren J,Brooks J,et al.UltraSPARC T2:A highly-treaded,power-efficient,SPARC SOC[C]∥Proc of IEEE Asian Solid-State Circuits Conference,2007:22-25.
[14] Tullsen D M,Eggers S J,Emer J S,et al.Exploiting choice:Instruction fetch and issue on an implementable simultaneous multithreading processor[C]∥Proc of the 23nd Annual International Symposium on Computer Architecture,1996:192-202.
[15] Sui Xiu-feng, Wu Jun-min, Chen Guo-liang. Performance evaluation and optimization of Cache architecture for simultaneous multi-threading processor[J]. Journal of Chinese Computer System, 2009,30(1):159-163.(in Chinese)
[16] Nair A A,John L K.Simulation points for SPEC CPU 2006[C]∥Proc of IEEE International Conference on Computer Design,2009:397-403.
[17] Binkert N,Beckmann B,Black G,et al.gem5 simulator:A modular platform for computer-system architecture research[EB/OL].[2016-04-21].http://www.gem5.org.
附中文参考文献:
[12] 郑方,张昆,邬贵明,等.面向高性能计算的众核处理器结构级高能效技术[J].计算机学报,2014,37(10):2176-2186.
[15] 隋秀峰,吴俊敏,陈国良.同时多线程处理器上的 Cache 性能分析与优化[J].小型微型计算机系统,2009,30(1):159-163.
