Spark并行计算框架的内存优化*
2018-05-08廖旺坚黄永峰包从开
廖旺坚,黄永峰,包从开
(1.清华大学电子工程系,北京 100084;2.清华大学信息科学与技术国家实验室(筹),北京 100084)
1 引言
集群并行计算是指在大量性能较低、可靠性较差的通用计算机上并行完成巨大的计算任务,是大数据时代满足低成本/高计算能力需求的最佳选择。Hadoop是一个开源的集群并行计算框架,包含MapReduce计算模型和Hadoop分布式文件系统HDFS(Hadoop Distributed File System)存储模型,具有硬件要求低、吞吐量大、容错性好的特点,满足了大数据计算的需要,成为当前工业界最流行的计算框架,也是学术界研究热点。但是,随着数据量迅猛增长,计算复杂度不断增加,计算实时性越来越高,Hadoop计算速度较慢的弱点逐渐显现。于是,Zaharia等[1 - 3]基于Hadoop,在前人不断改进的基础上重新实现其调度模型,形成了Spark计算框架。
Spark是一个快速、通用的大规模数据处理引擎[4],具有快速、易用、通用、兼容性好的特点。它使用有向无环图DAG(Directed Acyclic Graph)进行作业调度,根据依赖关系将不同作业分解成大量子任务组成的DAG,减少了不同作业之间的数据传递过程,并且将前后作业间的中间数据使用内存缓存传递,使用线程池运行计算任务,使得计算速度相比传统的Hadoop MapReduce有100倍量级的提升[3]。
目前对Spark性能的研究主要有三类:第一类是在Spark模型层面对作业调度、底层资源管理等方面做改进和优化;第二类是在提交Spark作业时改变不同的参数,找到最优值;第三类是在应用层面,编程时使用不同的实现方法,提高作业运行性能。Ousterhout等[5]对Spark性能做了详尽测试和分析,认为CPU可以优化的地方较少,而网络使用远未达到饱和状态,其优化对性能的影响很小,但该文献关于内存对性能的影响很少提及。陈侨安等[6]对大量旧任务提交参数和性能进行分析,对比任务相似度,预测出新任务最适合的参数,属于第二类的方法。杨志伟等[7]改变任务调度策略,优先将任务分发给资源空余度高的结点,提高集群整体运行性能,属于第一类的方法。Gog等[8]采用内存分区管理的思路,给应用中处于生命周期的数据对象划定内存区块,运行时不对此区块进行GC(Garbage Collector)操作,但这样需要给每个对象指定明确的生命周期,使得编程更为复杂。Gidra等[9]针对分布式系统的GC进行改造,使各结点GC进程互相发布消息,避免无效的GC操作,提高运行效率,但增加了结点间通信消耗。
Spark的特点是大量使用内存提高计算速度,因此内存资源是Spark最基本的瓶颈,通过内存优化,可以提升Spark的性能。本文针对第二类和第三类方法存在的不足,围绕内存在Spark作业中的分配方法和作用原理,提出不同的内存优化策略,并设计了相应的实验进行论证。
2 Spark作业执行框架分析
2.1 作业调度机制分析
Spark的作业执行流程如图1所示,用户向Driver结点提交需要运行的作业后,Driver结点创建SparkContext。SparkContext根据程序中的Action操作,将作业划分为连续的Job流,并依次提交到有向无环图调度器DAGScheduler。DAGScheduler对提交的Job进行解析,生成由不同Stage流组成的有向无环图,然后依次将每个Stage提交到线程调度器TaskSchedulerImpl。TashSchedulerImpl为Stage生成线程集TaskSet,并将TaskSet分发到各个工作结点Worker的线程管理器TaskManager。TaskManager根据收到的信息启动Task开始运算,运算结束后得到的数据可能被下一个Stage所使用,称为中间数据,由数据块管理器BlockManager进行管理。BlockManager在内存充足的时候将中间数据存储到内存,以提高访问速度,在内存不够的时候将中间数据存储到本地磁盘、HDFS或丢弃。
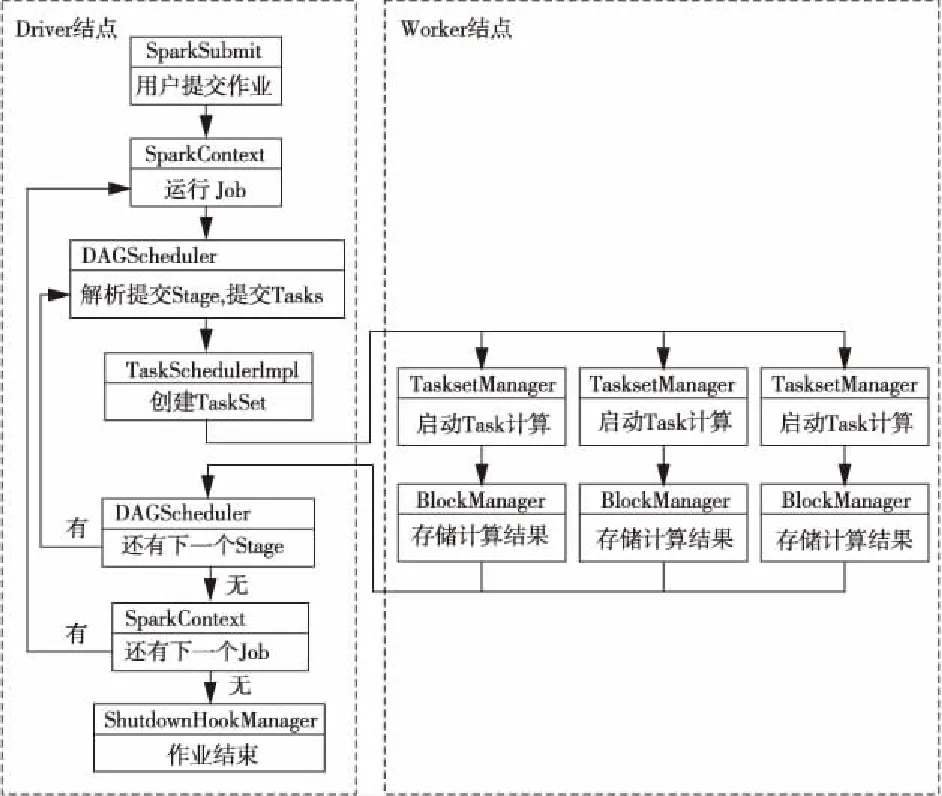
Figure 1 Spark application execution flow图1 Spark作业执行流程
2.2 JVM层内存管理机制分析
Spark作业运行在Java进程中,一个Java进程对应一个JVM。JVM在运行过程中管理的内存空间叫堆空间,用于存储程序中创建的对象,在运行过程中可根据配置动态变化。如图2所示,JVM堆空间分为年轻代(Young Generation)、年老代(Old Generation)和持久代(Permanent Generation),一般年轻代存放短生命周期的对象,年老代存放长生命周期的对象,持久代存放类、方法等元数据,年轻代又可分为Eden、Survivor1(S1)和Survivor2(S2)区间。
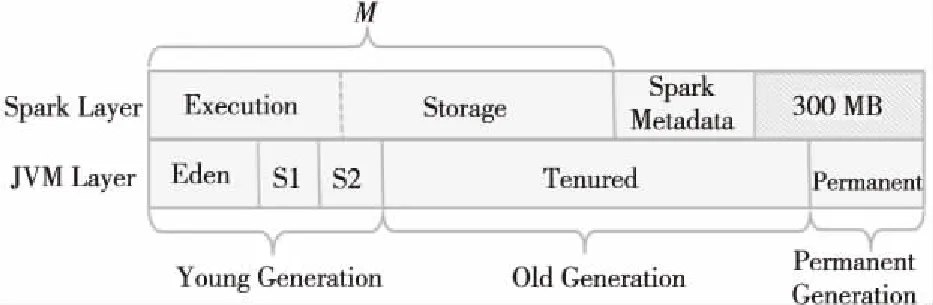
Figure 2 Memory management comparison between Spark and JVM图2 Spark和JVM的内存管理对应关系
JVM运行过程中会使用垃圾收集器GC对内存数据进行清理。新生成的对象存放在Eden区间,Eden区间满了后,会触发Minor GC,将Eden和Survivor1区间仍然存活的对象复制到Survivor2区间。下一次Eden区间再满,再触发Minor GC,将Eden和Survivor2区间仍然存活的对象复制到Survivor1区间,如此不断往复。当对象生命周期足够长或Survivor区间满了后,对象会被转移到年老代区域。当年老代快满的时候,会触发Full GC,清理年老代不需要使用的对象。当持久代有类不需再使用并且需要空间存放别的数据时,会触发Major GC,清理持久代的数据。
当GC被触发时,JVM中所有运行的线程会暂时停止运行,等待GC完成后继续。如果一次作业中GC被触发的次数特别多,就会显著延长作业执行总时间,降低系统性能。其中Full GC需要时间比Minor GC更长,对性能影响更大。Java官方文档[10]显示,在理想情况下,使用30%的时间作为GC消耗,在使用2个CPU内核时,系统吞吐量会下降到80%,而使用32个CPU内核时,系统吞吐量会下降到10%。而Spark作业处理大规模数据,通常都会使用较多的CPU内核,因此GC对性能的影响需要引起重视。
2.3 Spark层内存管理机制分析
Spark框架同样对所使用的内存进行管理,其管理的内存主要有两种用途。如图2所示,第一种是用于程序执行,如join、sort、shuffle、aggregation等算子执行时使用的内存;第二种是用于存储,如RDD(Resilient Distributed Datasets)数据缓存和广播变量存储等。用于这两种用途的内存使用一个统一的空间(如图2中的M,其存储空间大小为M),Spark使用一个参数spark.memory.fraction设置M的大小:
spark.memory.fraction=M/(Java堆空间-300 MB)(默认0.6)
在内存M中,一部分用于任务执行(如图2中的Execution,其空间大小为E),一部分用于缓存数据(如图2的Storage,其存储空间大小为R)。Spark使用参数spark.memory.storageFraction设置两者比例:
spark.memory.storageFraction=R/M(默认0.5)
从图2可以看出,Spark管理的内存和JVM管理的堆空间属于同一段物理内存空间,只是在不同层面上进行管理。Spark管理的内存基本等于JVM堆空间的年轻代和年老代的空间,一部分用于执行运算和存储(M),另一部分空间用于Spark的类等元数据的存储。
3 内存优化策略
我们对影响Spark作业执行性能的主要因素进行分类,如图3所示。
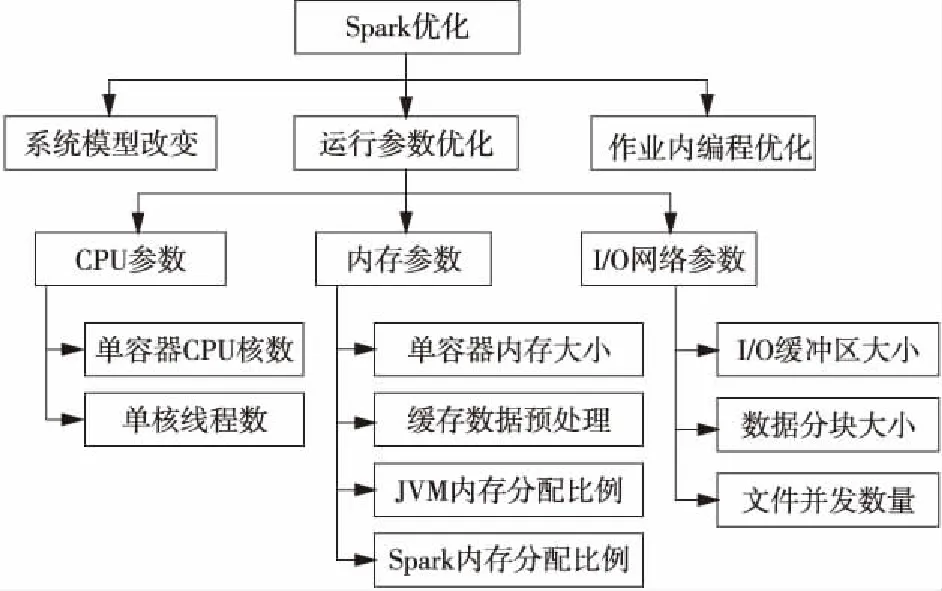
Figure 3 Influencing factors of Spark application performance图3 Spark作业性能影响因素示意图
图3中可以看出,目前对于Spark的优化一般从修改源代码改变系统作业的执行模型,提交作业时调整运行参数和编写作业程序时算法优化等几个方面入手。系统运行参数又可分为CPU参数、内存参数和I/O网络参数等。CPU参数配置包括单执行容器使用的核数、单核的线程数等。网络和I/O的配置包括缓冲区大小、数据分块大小和文件并发数量等。内存的运行参数配置方面,可以通过改变单容器内存大小、对缓存数据进行预处理、改变JVM和Spark管理内存的分配比例等,对作业性能产生影响。
3.1 通过序列化和压缩,减小缓存数据大小,提升系统性能
一般数据从磁盘读取到内存以后,占用空间都会不同程度地增大。这主要是由于Java的对象存储格式所决定的,如每个String对象会占用40 Bytes空间存储文本宏信息,则平均每行40个字符的中文数据集转化成RDD后,占用内存会比原始数据大50%。而对于英文文本来说,内存中存储的UNICODE格式或UTF-16格式的字符,占用内存空间会比磁盘上存储的UTF-8或ASCII码格式大一倍。
Spark将作业运行过程中产生的RDD缓存到内存时,RDD中每一行的数据指针等头数据都会缓存下来,而这会占用大量内存空间。序列化可以将RDD转化为字节序列存储,减小缓存数据占用空间,如果序列化后再使用压缩算法对字节序列进行压缩,能更大程度减少空间占用。特别是在内存空间紧张时,减少缓存数据大小,更多内存可以用于代码执行,减少系统的GC触发次数,有效避免或减少对外存的使用,提高运行性能。
3.2 在一定范围内减小运行内存,减少缓存使用,提升性能
使用硬件资源越多,系统性能越好,这是业界普遍的认识。数据在内存中缓存是以RDD分块的方式存在的,分块的大小默认跟HDFS存储文件的分块大小一致。作业运行过程中,如果空闲内存不够存下整个分块,系统会移除掉部分旧的缓存数据,存放新的数据。如果移除掉旧的部分数据还不够的话,系统会放弃使用内存缓存,改用外部存储缓存或不使用缓存。
对于数据量大而计算代价小的作业而言,使用足够大的内存,可以使得内存在缓存全部数据后还有足够的空间执行代码,作业执行过程不会触发GC,系统性能可以达到最佳。而在可使用的运行内存较小时,系统调度策略会发生改变,减少数据的缓存操作,改由重新计算得到原来缓存的数据。如果减少缓存的数据很大,则腾出来的内存空间更多,反而会降低JVM的GC触发次数,在重新计算消耗小的情况下,会使得整个系统运行过程稳定,性能提高。
3.3 配置合适的Spark和JVM使用内存分区的配比,提升系统性能
文献[10]指出,JVM的GC算法是基于“Java程序中大部分的对象都是短生命周期”这一假设,即大部分的对象在Minor GC时就会被清理掉,没机会转入到年老代,因此GC过程中Full GC较少,对系统性能影响不大。而Spark中缓存数据在整个作业期间会一直存在,对于JVM来说都是长生命周期对象,并且普遍数据量大,占用大量的JVM堆空间。大数据背景下的计算任务,一个数据块很容易就占满所有的年老代空间,导致传统GC不能起到应有的作用,反而降低系统性能。通过改变JVM中年轻代和年老代的比例,改变Spark中执行内存和存储内存的比例,可以调节JVM的GC消耗,减少不利影响,提高系统性能。
下一节我们运行大量Spark作业,使用上述不同策略优化,验证不同优化策略下参数配置对系统性能的影响。
4 实验与分析
为验证和分析优化策略的效果,搭建了Spark运行平台。Spark计算层设置4个结点,其中1个主结点,3个工作结点,每个工作结点32 GB内存,8个CPU内核。HDFS存储层设置6个结点,其中1个主结点,5个数据结点,HDFS文件块大小设置为128 MB。
为验证优化策略,设计了两类计算任务:
任务A对不同大小的中文微博数据集(1 GB~100 GB)进行词频统计。任务要求将数据集读出后使用不同的方式缓存,然后做词频统计工作。
任务B对2 227万条60维的向量数据聚类计算,数据以文本的格式存储在HDFS上,共9.82 GB,79个分块。任务要求将数据读入后,转化为Vector向量,然后再以不同方式缓存,最后进行迭代次数不大于8次的KMeans聚类操作。
实验过程中,采用不同的参数配置运行A类任务和B类任务,观察任务运行时间、GC详情、线程执行时间、数据块存取、资源占用情况等指标,并作记录和分析。
4.1 序列化和压缩数据
表1显示了任务A的数据经过不同方式处理后,缓存占用的空间大小和作业运行时间。任务中数据集为1 096 MB的中文微博文本数据,共8 546万行。可以看出,Spark将数据导入后,占用空间比在磁盘占用空间增加17%,而序列化以后,空间减少14%,如果序列化后再进行压缩,则占用空间比不处理减少42%。在运行时间上,压缩比不压缩平均降低运行时间2 s,同时GC时间减少80%,说明缓存空间的减少能够有效降低GC消耗。但是,最终不处理情况下运行时间是最小的,因为序列化和压缩,包括读取缓存后的反序列化和解压缩过程本身需要占用资源。序列化后再压缩相比序列化后不压缩,虽然压缩过程需要时间,但压缩后占用空间更少,GC消耗大大降低,降低的GC消耗时间远超过压缩过程增加的时间,总作业运行时间反而比序列化后不压缩降低18%。
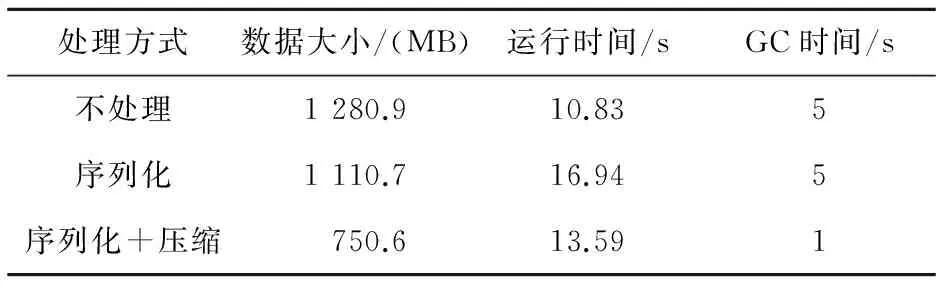
Table 1 Effects of different processingmethods on data size and performance表1 不同处理方式对数据大小和运行性能的影响
图4显示了对任务B用不同缓存方式处理后的性能。任务中数据直接缓存占用空间约10.7 GB,序列化后占用空间约10.3 GB。如果使用压缩后再缓存的方式,占用空间约7.8 GB,减少24%,与文本数据的空间占用规律基本一致。可以看出,在直接使用系统内存和HDFS缓存中间数据的情况下,随着提交内存的增加,系统运行性能提高,这是因为随着内存的增加减少了对HDFS的使用,所以运行速度增加。如果将外部存储方式由HDFS改为DISK,我们可以看到,在内存较少的情况下,系统运行时间比HDFS方式降低很多,因为去除了网络消耗和多备份消耗后,本地硬盘的读写比HDFS读写消耗的时间要短。
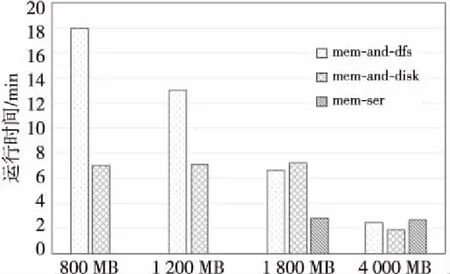
Figure 4 Performance comparison of different caching modes图4 不同缓存方式性能对比
从以上两例中可以看出,减小缓存占用的空间可以减少读写时间,降低GC消耗,提高系统性能。但序列化和压缩两种减少空间的过程本身需要时间,在“一次缓存,多次使用”和内存严重受限的情况下,适用于这种方式提高系统性能。而在内存不够时,用本地磁盘代替HDFS存储中间数据,能够降低读写时间消耗,在通常的情况下都能比较适用。
4.2 改变运行内存大小
图5显示了任务B在提交作业时使用不同内存大小,对任务运行的总时间和GC占用的时间的影响。可以看出,GC时间和运行总时间有明显的正相关性,GC耗时长则运行总时间长。在内存小的时候,GC用时明显较大,在内存大的时候,GC时间则非常之少。当内存从1 500 MB到4 000 MB时,GC时间逐步下降,任务运行时间也随内存增多而下降。内存大于6 000 MB以后,GC用时基本可以忽略不计,而运行总时间趋于稳定。在内存小于1 600 MB时,提交内存越大反而运行时间越长,这符合策略3分析的结果。不过直接计算速度比不上内存缓存,所以相比最佳性能还是差一些。当内存在1 500 MB左右时,GC用时和任务运行总时间达到最高,GC用时占到了总用时的30%。
从这里可以看出,在提交Spark作业的时候,在内存足够的情况下,应尽量使用更多的内存,而内存有限的情况下,也并不是内存越少性能就越差,同时也要避免如实验中“1 500 MB”这样的区间。
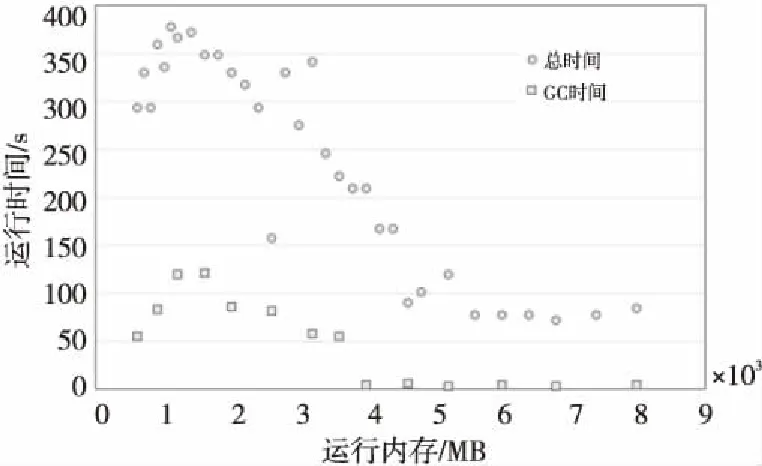
Figure 5 Task running time and GC time scatter distribution图5 任务运行时间与GC时间散点分布
图6展示了任务B运行过程中所有缓存的数据量,包括缓存在内存和磁盘的,以及系统因为内存空间不够,为缓存新数据而从磁盘移除的老数据量。可以看出,在运行内存较小的时候,系统使用内存缓存和磁盘缓存都小,但都随内存增加而增大。而到1 600 MB以后,内存缓存基本保持稳定,磁盘缓存则显著下降。说明内存足够大以后,只用内存就能满足所有缓存要求,所以磁盘使用量下降,同时也越来越不需要移除内存给新的数据腾空间,所以内存缓存移除数据同步下降,最后趋于零。前面内存越小,内存缓存也越小,但磁盘缓存也越小,同图5类似,说明系统根据参数减少了缓存的使用,使用重新计算的方式得到需要的数据,这一部分需要消耗部分时间,但比使用磁盘缓存耗时反而更低。
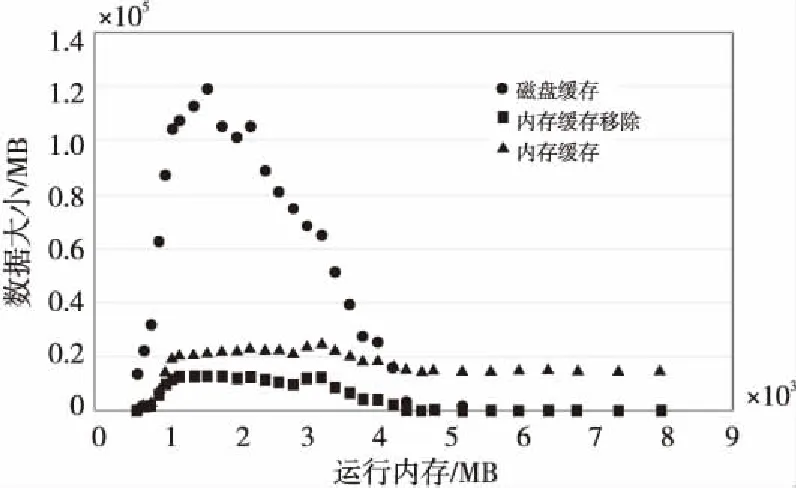
Figure 6 Cache data trends图6 缓存数据变化趋势
综合图5和图6可以看出,Spark作业运行时间与GC时间、存储设备读写时间等都密切相关,由多种因素决定。在数据量太大而内存远远不够的情况下运行任务,酌情减少内存的使用,可能会达到更好的效果。
4.3 JVM堆空间和Spark内存分配
图7展示了使用不同的JVMNewRatio参数运行任务B的结果。NewRatio参数代表JVM中年老代和年轻代大小的比例,我们分别设置为1、2、4、8、15,对比运行效果。从图7中可以看出,当NewRatio参数越来越大,也就是堆空间中年老代占比越来越多的时候,系统的Minor GC时间增加,而Full GC时间减少,任务运行的总时间减少,在参数为8时达到最小值,此时性能比参数为1时提升25%,比默认参数提升10%。
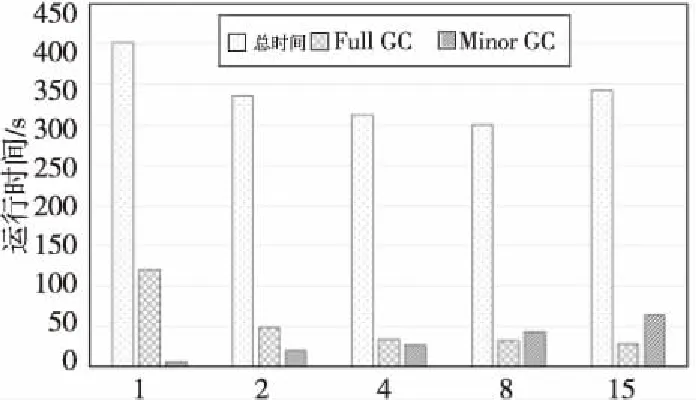
Figure 7 Running time and GC time in different heap space ratio图7 不同堆空间比例时作业运行时间和GC时间
这是因为Spark任务中缓存的数据一般会保持较长时间,并且比较大,在NewRatio较大,即年轻代较小、年老代较大的情况下,会很快占满年轻代的Eden区间,引发Minor GC,所以Minor GC次数比较多,时间比较长,但单次Minor GC的时间会短,因为年轻代空间较小,清理对象较快,如图8所示。而由于年老代空间较大,对象的生命周期容忍度比较大,所以年老代的Full GC次数比较少。从图8中可以看见,单次Full GC时间大约是单次Minor GC时间的10~20倍,因此Full GC的次数更能影响系统的性能。
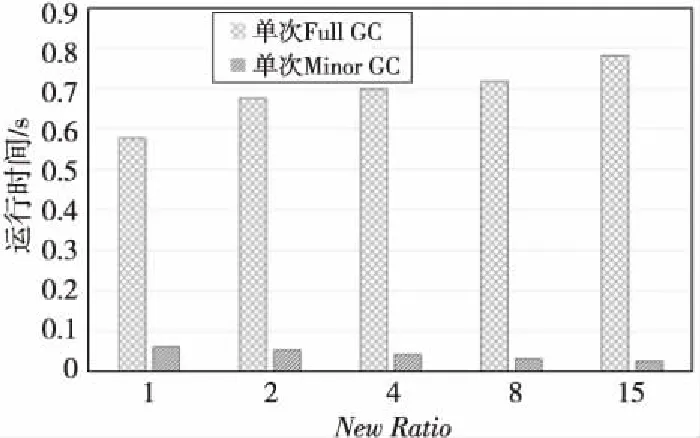
Figure 8 Average time of single GC in different heap space ratio图8 不同堆空间比例时平均单次GC时间对比
Spark有两个参数调节管理内存的分配,spark.memory.fraction表示Spark管理的内存中执行和存储部分占的比例,实验使用任务B在0.9~0.002测试,结果如图9所示。从图9中可以发现,当比例在0.001时运行时间达到最小值,也就是说提交运行内存为2 200 MB时,只使用不到20 MB作为执行代码和存储使用的内存,此时性能比最低水平提升50%,比平均水平提升30%。查找监测数据可以发现,该比例时运行作业,JVM只有Minor GC,同时也几乎没有中间数据存储在内存和硬盘,因为此时Spark使用的内存大小远小于JVM年老代大小,所以根本不会触发Full GC,在内存缓存很小很小的情况下,GC时间最短的性能最高。
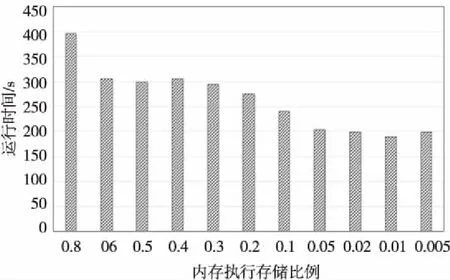
Figure 9 Running time of different Spark memory execution storage ratio图9 不同Spark内存执行存储比例时运行时间
5 结束语
本文分析Spark运行过程中JVM层面和Spark层面对内存的管理机制,从减少数据量、改变提交内存大小、改变JVM堆空间内存分配比例、改变Spark管理内存分配比例几个方面探讨了优化Spark作业运行的方法,并通过实验对方法进行了验证。
通过实验发现,总的来说,使用更大的内存能够提升系统性能。但是,在大数据处理背景下,内存的增长跟不上数据的增长,在有限的内存条件下,适当减少内存使用促使系统用重新计算代替缓存,根据Spark缓存对象和作业性质的特点,优化JVM中堆内存的分配和Spark管理内存的大小,能够有效降低I/O和GC消耗,提高系统性能。
本文的贡献点在于结合Spark对内存的管理和JVM对内存的管理,分析两层之间的内存管理的相互联系,根据数据对象在内存中的存在方式变化,提出优化策略。实验结果说明优化策略能够有效提升系统性能,具有一定的代表性,分析的结论对如何更好地使用和改进Spark也有一定的启发作用。
参考文献:
[1] Zaharia M.An architecture for fast and general data processing on large clusters[M].New York:Association for Computing Machinery and Morgan & Claypool,2013.
[2] Zaharia M,Chowdhury M,Franklin M J,et al.Spark: Cluster computing with working sets[C]∥Proc of the 2nd USENIX Conference on Hot Topics in Cloud Computing,2010:10.
[3] Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C]∥Proc of the 9th USENIX Conference on Networked Systems Design and Implementation,2012:141-146.
[4] Apache Spark-Lightning-fast cluster computing[EB/OL].[2016-09-14].http://spark.apache.org/.
[5] Ousterhout K,Rasti R,Ratnasamy S,et al.Making sense of performance in data analytics frameworks[C]∥Proc of the 12th USENIX Conference on Networked Systems Design & Implementation,2015:293-307.
[6] Chen Qiao-an,Li Feng,Cao Yue,et al.Parameter optimization for Spark jobs based on runtime data analysis[J].Computer Engineering & Science,2016,38(1):11-19.(in Chinese)
[7] Yang Zhi-wei,Zheng Quan,Wang Song,et al.Adaptive task scheduling strategy for heterogeneous spark cluster [J].Computer Engineering,2016,42(1):31-35.(in Chinese)
[8] Gog I,Giceva J,Schwarzkopf M,et al.Broom: Sweeping out garbage collection from big data systems[C]∥Proc of the 15th Usenix Conference on Hot Topics in Operating Systems,
2015:2.
[9] Gidra L, Thomas G,Sopena J,et al.NumaGiC: A garbage collector for big data on big NUMA machines[J].Acm Sigplan Notices,2015,50(4):661-673.
[10] Java SE 6 HotSpot[tm] Virtual machine garbage collection tuning[EB/OL].[2016-09-16].http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html.
附中文参考文献:
[6] 陈侨安,李峰,曹越,等.基于运行数据分析的Spark任务参数优化[J].计算机工程与科学,2016,38(1):11-19.
[7] 杨志伟,郑烇,王嵩,等.异构Spark集群下自适应任务调度策略[J].计算机工程,2016,42(1):31-35.
