基于粗粒度可重构密码阵列的AES算法映射实现
2018-04-18李远铭严迎建
李远铭 严迎建 李 伟
(解放军信息工程大学 河南 郑州 450001)
0 引 言
随着网络空间成为与陆、海、空、天并列的第五空间,其安全问题显得尤为重要和紧迫[1],而密码技术是防护网络安全的基础与核心手段之一。其中分组密码算法AES[2]具有速度快、结构简单、易于标准化等特点,被广泛运用于诸多领域[3]。
文献[4-5]采用了VLIW结构的密码专用指令处理器实现AES算法,虽开发了指令级并行,但仍由指令流驱动,一个时钟周期只可实现一个密码操作,AES算法性能提升有限。文献[6]采用ASIC方式实现AES算法,采用流水和并行思想,对相应结构进行优化,具有较高吞吐率和资源面积效率,但不具灵活性。文献[7]采用了FPGA实现AES算法,利用6个并行AES算法核实现,在Altera公司的Stratix III EP3SL340F151713上的处理速度可以达到5.96 Gbit/s,但未考虑配置开销和功耗开销。而文献[8]在提出的BCORE结构上映射实现了AES算法,利用阵列充足的计算资源对AES算法加速,吞吐率可达2.327 Gbit/s,但其运算单元的粒度为8 bit,对于32 bit处理位宽的AES算法加速有限。
上述AES算法实现方式都存在若干问题。同时随着安全防护力度的不断提升,需要定期更换子密钥,上述文献很少考虑到AES子密钥实时生成问题。因此本文在提出的CGRCA上映射实现了AES子密钥生成算法和AES加密算法。针对不同的应用场景,本文实现了两种AES加密算法映射:面积最小和流水展开。通过分析该阵列具有的特殊单元结构,同一运算单元可以合并实现多个密码操作,减少资源占用。同时考虑了轮运算关键路径的延时差异,选择性插入寄存器,AES加密算法吞吐率得到不同程度的提高,满足了实际应用的需求。
1 AES算法介绍
AES算法是一种迭代型算法,分组长度固定为128 bit,密钥长度可选择为128、196或者256 bit,对应的轮变换次数Nr分别为10、12和14,密钥长度取决于所需的安全等级,其算法流程如图1所示。本文中分组长度和密钥长度都采用128 bit。完整的AES算法由AES加/解密算法和AES子密钥生成算法组成,其中加/解密算法结构类似,只是顺序不一样,本文仅实现加密算法。
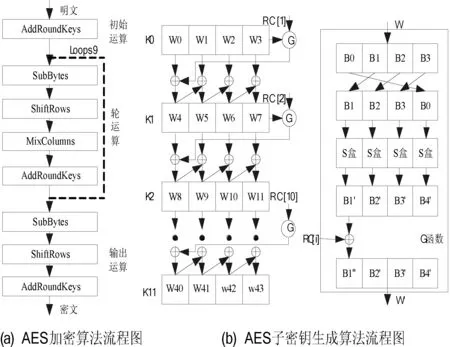
图1 AES算法流程图
图1(a)为AES加密算法流程图,主要基于代替/置换网络结构,完成数据的混乱与扩散。由三部分组成:初始运算、轮运算和输出运算,一般将128 bit明文分组排成4×4的字节矩阵,称为状态state,然后先进行初始运算,之后进行9轮轮运算,最后的输出运算少了列混合这一步。完整的轮运算需要经过字节替换(SubBytes)、行移位(ShiftRows)、列混合(MixColumns)和密钥加(AddRoundKeys)。
图1(b)为AES子密钥生成算法流程图。子密钥生成算法主要由密钥拓展和子密钥选取两个部分组成。其中密钥拓展的核心为G函数,主要由字移位、S盒及与常量的异或操作构成,输入的128 bit主密钥K0,也是第1个子密钥,经过密钥拓展得到44字共11轮的子密钥,供接下来AES加密算法使用。
2 CGRCA平台
2.1 阵列结构
本文依托的阵列平台为CGRCA,面向密码算法高速处理而设计。采用了数据流加配置流驱动方式,通过配置信息的配置,完成多种分组密码算法的实时重构,具有高效率和高并行特点。CGRCA结构图如图2所示。
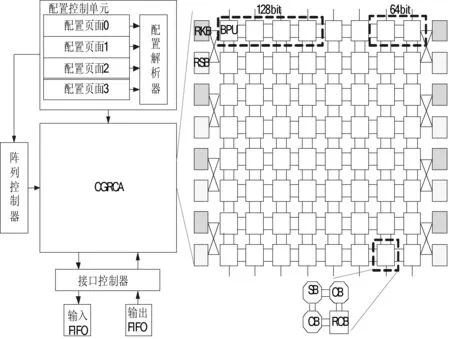
图2 CGRCA结构图
整个平台主要由4部分组成:配置子系统、控制子系统、数据交互子系统和运算子系统。
配置子系统由4个配置页面和配置解析器组成,完成对阵列控制器和运算子系统的重构。为了实现配置信息的快速切换,采用了多配置页面技术,配置切换时间大大缩短。通过配置解析器的解析配置,实现阵列的部分重构和实时重构。
控制子系统即阵列控制器,该阵列的控制器采用可重构设计,通过配置信息的配置,可以灵活产生所需要的控制信号,保证分组密码算法的正确有序执行。
数据交互子系统由接口控制器和输入/出FIFO组成,输入FIFO存储明文数据,输出FIFO存储密文数据,其中接口控制器完成数据的分配、组装等操作。
运算子系统由8×8个可重构运算块BPU组成,其中每2行左右8个BPU各共享1组RKB和RSB。RKB由寄存器堆搭建,完成子密钥的存取;RSB由RAM块搭建,完成S盒操作;BPU由路由单元CB、SB和密码运算单元RCB组成,完成数据的路由和处理,BPU、RSB和RKB之间的连接采用了专用通道。为了适应相关分组密码算法的大位宽处理需求,可将同一行多个BPU级联完成64 bit、128 bit运算,如图2的虚线所示。并设定第1行和第5行为输入行,由接口控制器负责数据注入和运算启动。
2.2 RCB结构
核心RCB结构如图3(a)所示,由4类互斥的密码模块组成,分别为算法类AL、逻辑类TL、非线性函数类NF和置换类BP。可在配置信息重构下实现多种密码操作,其处理位宽皆为32 bit, REG_IN为明文寄存器,仅第1行RCB具有,而REG为中间态寄存器。此外,因Input/Output Crossbar Network(INET/ONET)的存在,各密码模块可以任意组合连接和任意输出。同时4类密码模块处理后的数据都要经过旁路寄存器Bypass Reg(BR),可选择数据的寄存与否,具有寄存器的动态插入特点。对图3(b)中的任意重构模块来说,根据配置信号Sel的选择不同,模块内部所走路径不同,路径延时也不同,例子中的路径1和2延时分别为0.9 ns和0.55 ns。对于分组密码算法的轮运算来说,通过在合适地方插入寄存器,虽增大了时钟周期数,但也提高了时钟频率,吞吐率反而可以提高。所以需要根据关键路径延时差异,动态插入旁路寄存器,提升分组密码算法的吞吐率。
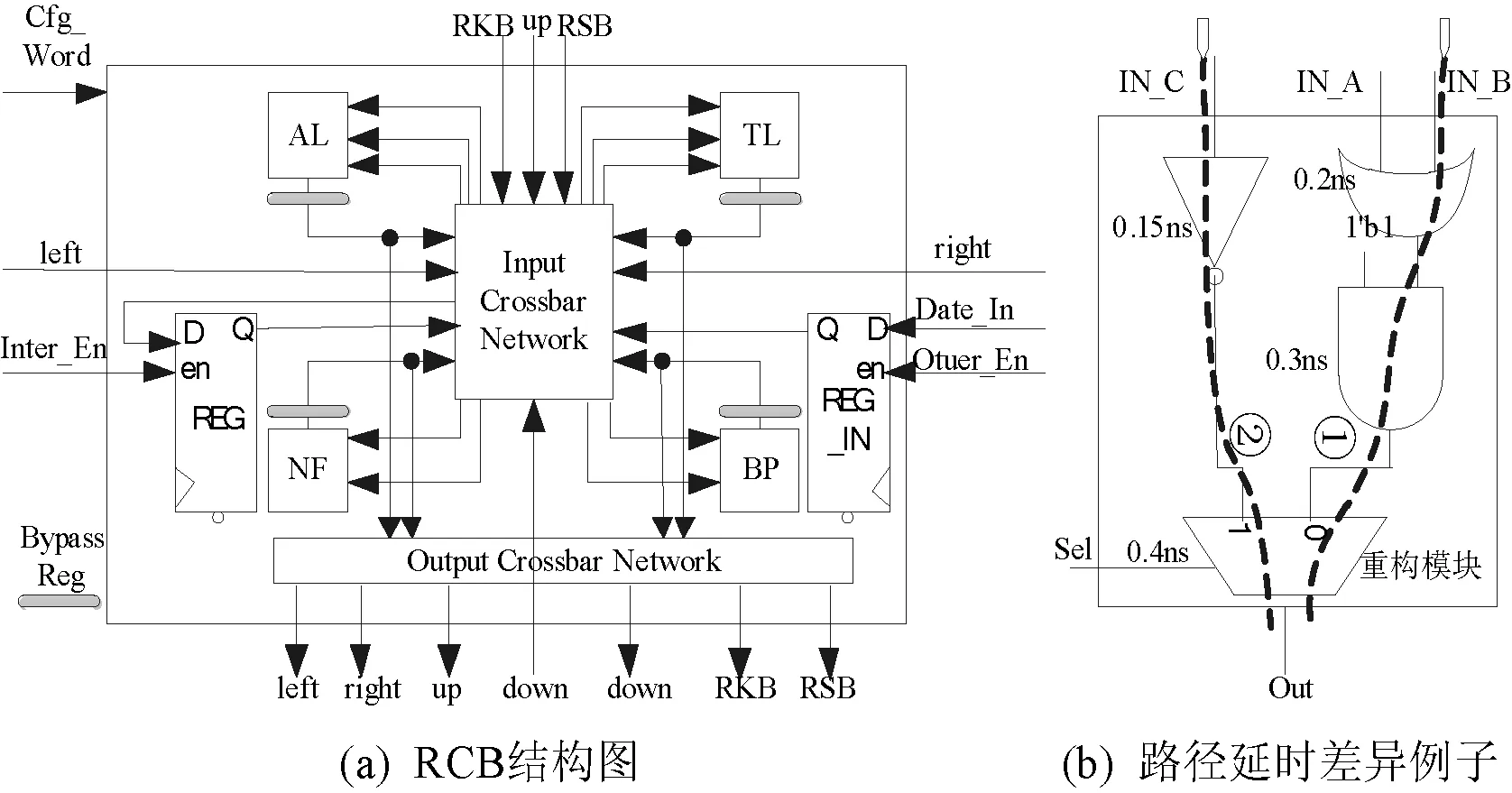
图3 RCB结构及路径延时差异
3 AES算法映射
通过前文对AES子密钥生成算法和加密算法的研究,结合CGRCA结构,本文在该阵列上映射实现了这两种算法。以AES子密钥生成算法为例简述了映射步骤,而AES加密算法采用了两种策略进行实现,分别为:面积最小映射和流水展开映射。同时在分析了轮运算的关键路径延时差异后,充分利用RCB中的旁路寄存器,选择性插入寄存器,最大程度提升AES加密算法实现性能。
3.1 AES子密钥生成算法映射
AES子密钥生成算法往往运行一次,只需生成完整的子密钥集,并将其存入RKB即可,子密钥生成时间相对整个数据任务包批处理时间而言,可忽略不计。所以对于AES子密钥生成算法的映射,只需要满足CGRCA相关限制即可,不用考虑性能等要求。
为了完成AES子密钥生成算法需进行以下步骤:
步骤1根据算法描述得到其需要的密码操作种类及其数量。
由第1节中的算法结构可以看出,AES子密钥生成算法将相同的轮运算循环迭代10次后生成10个子密钥,其中第1个子密钥就是外部注入的主密钥,因此只需要考虑轮运算的映射。需要1个移位操作,1个S盒操作,5个异或操作。
步骤2根据密码操作种类确定相应的密码模块种类及数量。
其中移位操作由BP模块实现,S盒操作由RSB模块实现,异或操作由LG或AL模块实现,所以共需1个BP模块,1个S盒模块,5个LG或AL模块。
步骤3完成RCB内部映射,RCB内应尽量合并多个密码操作,从而减少RCB数量。
外部主密钥的注入只能存入第1行,生成的子密钥通过专用通道存入RKB,所以128 bit的主密钥需4个RCB,且4个RCB所包含的密码模块种类及数量满足需求,完成的RCB内密码模块的映射连接如图4所示。其中RCB(1,1),RCB(1,2) 和RCB(1,3)各自只实现异或操作,RCB(1,4)需要实现2个异或操作,1个移位操作和1个S盒操作。接下来以RCB(1,4)说明,主要使用了AL、BP、TL和共享RSB实现其需要的操作,未用到NF模块,RCB内的箭头代表执行顺序,并根据执行顺序对各密码模块连线进行配置。
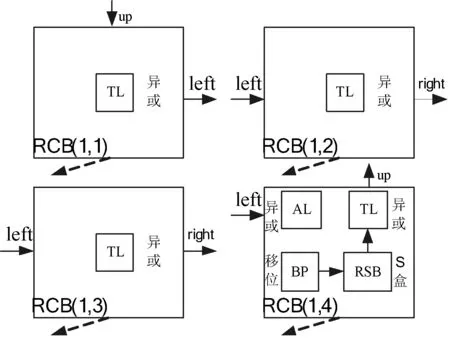
图4 RCB内部映射
步骤4完成RCB间外部映射,根据各RCB需要的输入输出方向,完成外部互连网络的连接。外部映射如图5所示,实箭头走的是CB和SB,而虚箭头走的RKB专用通道。
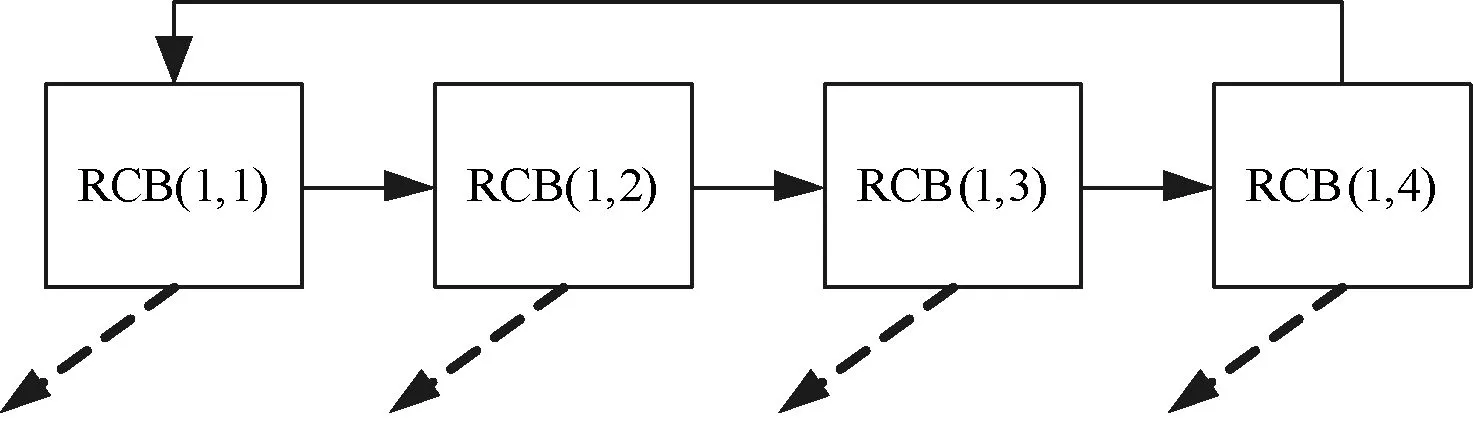
图5 RCB间外部映射
步骤5完成配置信息生成,根据映射完成的数据路径和所需的控制时序,生成相应的配置信息,其中默认RCB中的旁路寄存器为不寄存模式。
3.2 AES加密算法映射
为了满足AES加密算法不同应用场景的需求,分别在CGRCA上实现了面积最小和流水展开映射。该算法流程原本由三部分组成:初始运算、轮运算和输出运算,如图1(a)所示。其中初始运算仅由异或操作组成,为了减少映射资源的占用,对算法流程进行了调整,如图6所示,仅由轮运算和输出运算组成。
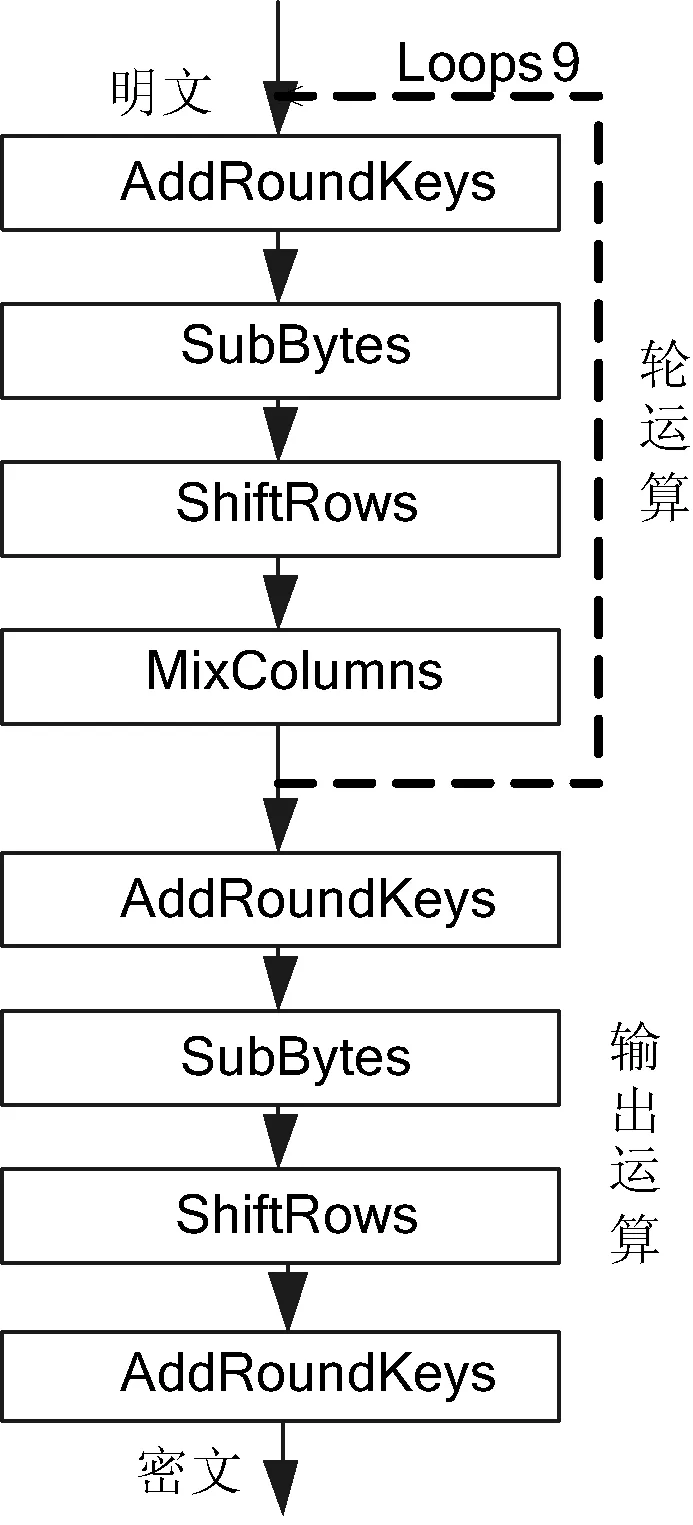
图6 修改后的AES加密算法流程图
首先按照3.1节提出的映射步骤完成了AES加密算法的面积最小映射,如图7(a)所示。该方法充分利用了阵列的并行性,采用 4路并行方式实现算法映射,只需横排4个RCB。通过操作合并,每个RCB都可完整实现轮运算和输出运算中的密码操作,其中轮运算中单个RCB采用如图7(a)的RCB配置1,输出运算中单个RCB采用如图7(a)的RCB配置2。因此实现完整的AES加密算法需要4个RCB,其中4横排的RCB首先在RCB配置1下完成前9轮的轮运算,最后在阵列控制器控制下切换到配置2,完成最后的输出运算。
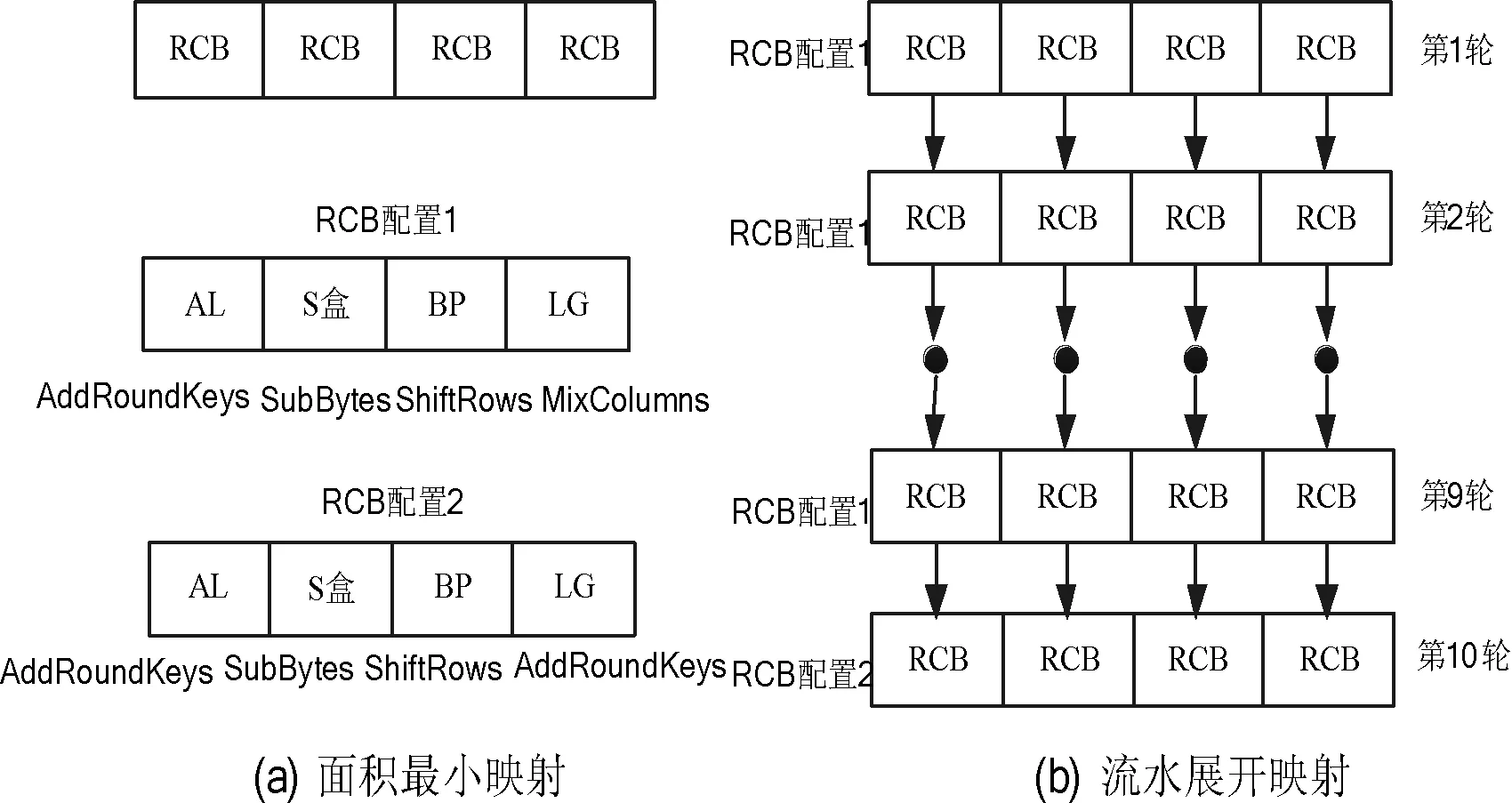
图7 AES加密算法映射实现
在Synopsys公司的Design Compiler软件综合下得到整个阵列延时信息,同时在Verdi仿真软件下得到了算法轮运算实际经过横排4个RCB中各模块的路径延时信息,其中统计的延时信息如表1所示。
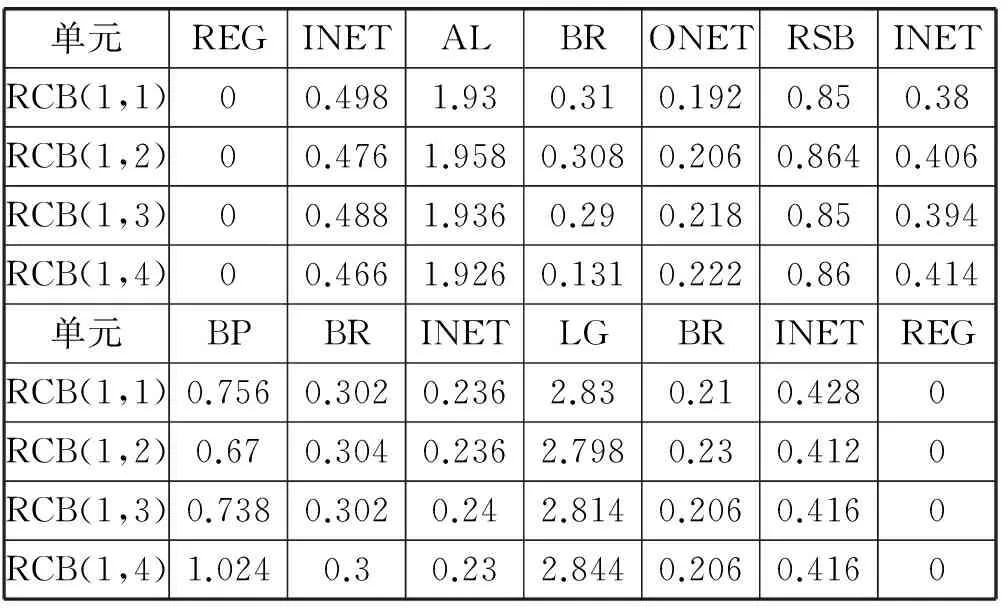
表1 RCB中轮运算延时信息
轮运算每次从REG开始,其中S盒的实现采用RAM块实现,进入RAM块的数据必须寄存,故完成一轮轮运算最少需要2个时钟周期。最大时钟频率由RCB内部两个寄存器间关键路径决定,此时为RCB(1,4)中RSB到REG路径,对应延时为6.294 ns,换算后的时钟频率为158.8 MHz。如果在BP模块后配置BR为寄存模式,对应关键路径为3.996 ns,换算为时钟频率为250.3 MHz,一轮轮运算增加为3个时钟周期。对输出运算而言,整个RCB配置除LG的功能不一样,其余都一样,但LG实现列混合操作远大于异或,故最大频率由轮运算决定,吞吐率计算公式如下:
(1)
式中:L为分组长度,F为时钟频率,C为时钟周期数。BR旁路模式时,完整AES加密算法用时24时钟周期(多的4周期由2个配置切换周期、启动周期和结束周期),BR寄存模式时,用时34时钟周期,各自吞吐率分别为846.9 Mbit/s和942.3 Mbit/s。结果表明,通过利用路径延时差异,动态插入寄存器,提高了算法吞吐率。因此需要在3.1节基础上增加步骤6。
步骤6计算配置完成后的路径延时信息,并根据实际情况动态插入寄存器,最大程度提升算法性能,并重新生成配置信息。
为充分利用阵列具有的大量计算资源,适应需要较高吞吐率场景的需求,AES加密算法的流水展开映射方式如图7(b)所示。每1轮需要4个RCB,全流水展开需要40个RCB(小于CGRCA的64个RCB),上一行RCB的数据分别对应传输到下一行的RCB中,前9排采用RCB配置1,最后一排采用RCB配置2。每次轮运算完成后不再寄存于当前RCB的REG,而是寄存于下一轮RCB的REG,此时会经过CB模块,导致关键路径延时增加。且整个映射过程不存在配页面的切换开销。轮运算的BR为旁路模式时,最大延时6.64 ns,即时钟频率为150.6 MHz;BR为寄存模式时,最大延时为4.342 ns,即时钟频率为230.3 MHz,理想情况下,数据量无限大,此时吞吐率计算公式如下:
(2)
式中:II为迭代间隔,此时各自吞吐率为9 638.4 Mbit/s和9 826.1 Mbit/s,流水展开方式的吞吐率较面积最小方式吞吐率有很大提高,同样动态插入寄存器后,其吞吐率也有所提高。
4 性能评估
本文所有延时信息基于CMOS 55 nm工艺,阵列综合后的面积约为15.5 mm2,通过第3节的分析可知,给定的映射步骤分别实现了AES加密算法的面积最小和流水展开映射方式。在计算了关键路径延时差异后,通过动态插入寄存器,在原来基础上提升了吞吐率,4种方式的比较如表2所示。
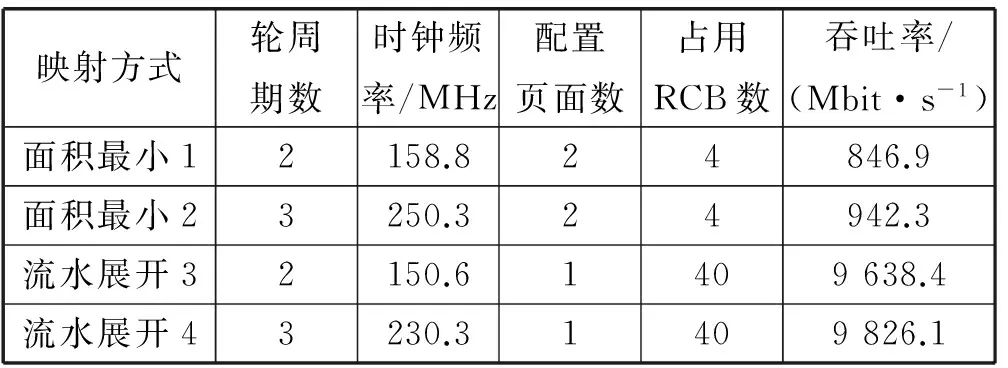
表2 不同方式的综合比较
由上述4种方式可以看出,面积最小方式占据最少的面积,仅4个RCB,且时钟频率较高,但需要两个配置页面,每轮轮运算存在配置切换开销,对性能有所影响,适合一些吞吐率要求不高场所。而流水展开方式最大程度利用了阵列充足的计算资源,吞吐率大大提高,达到9.8 Gbit/s,但是资源占据较多,也意味着较大的功耗,适合高吞吐率场景使用。此外通过利用轮运算中关键路径的延时差异,动态插入寄存器,面积最小2和流水展开4相比面子最小1和流水展开2各自吞吐率提高了11.3%和1.9%。
为了客观反映本文AES加密算法的实现性能,通过与几种密码处理结构及FPGA实现方式进行性能比较,结果如表3所示。其中文献[9]中采用了流处理架构SRCCPA对分组密码算法进行加速,取得了较好的加速效果。因不同处理结构的使用的工艺不一样,为进行公平比较,本文借鉴了文献[10]的工艺性能公式:Pa=Pb×Lb/La。其中Pa表示工艺换算后性能,Pb表示原工艺性能,Lb表示原工艺特征尺寸,La表示新工艺特征尺寸。
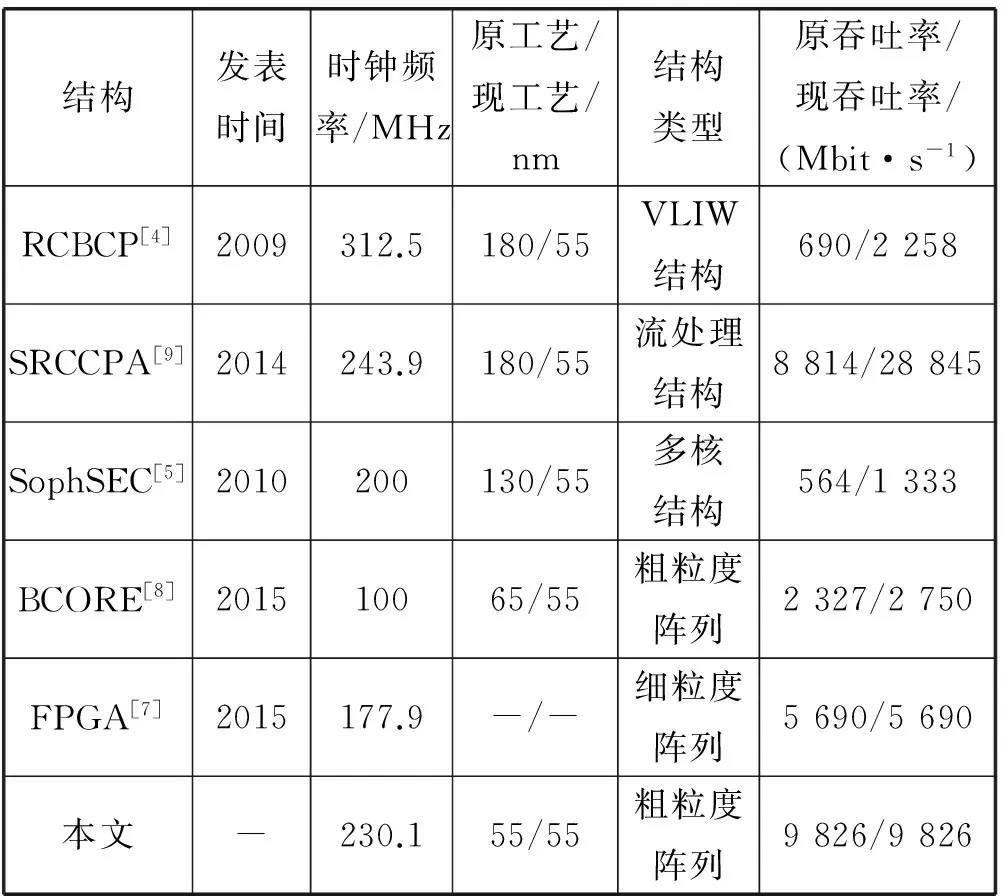
表3 与其他平台性能对比
由表3中的比较结果可以看出,基于CGRCA实现的AES加密算法具有较高的吞吐率,相比文献[5]SophSEC平台有最大7.37倍的性能提高,相比文献[7]的FPGA实现方式有最小1.73倍的性能提高。但是不如文献[9]中SRCCPA结构实现的性能,原因在于文献[9]采用了4倍资源复制的4×1流处理架构对AES算法进行加速,最大资源面积是13 381 704×4=53 526 816 μm2,约为53.5 mm2,此时面积开销是本文阵列的好几倍,通过资源面积增大的代价来换取性能提高。总的来说,本文通过采取流水展开方式实现的AES加密算法性能,可达其他平台的1.73~7.37倍,且具有较大的灵活性,可适应多种场景的算法映射实现。
5 结 语
本文首先分析了映射平台CGRCA具有的结构特点,尤其是RCB的特殊结构:不仅可以实现多个密码操作,而且可以选择性插入寄存器。然后本文映射实
现了AES子密钥生成算法和AES加密算法。针对AES加密算法,考虑应用场景不同分别完成了面积最小和流水展开两种映射方式。同时考虑到轮运算关键路径延时差异,选择性插入寄存器,一定程度上提高了算法实现的吞吐率。特别是流水展开方式最大程度利用阵列资源,相比别的平台,具有很大的吞吐率优势。未来基于该阵列可以映射实现AES算法其余变种及其他种类的密码算法。
[1] 范爱锋,程启月.赛博空间面临的威胁与挑战[J].火力与指挥控制,2013,38(4):1-3.
[2] Fox D.Advanced Encryption Standard (AES)[J].Gateway,1999,23(3):511-576.
[3] 德门.高级加密标准(AES)算法:Rijndael的设计[M].北京:清华大学出版社,2003.
[4] 孟涛,戴紫彬.分组密码处理器的可重构分簇式架构[J].电子与信息学报,2009,31(2):453-456.
[5] Huang W,Han J,Wang S,et al.A low-complexity heterogeneous multi-core platform for security soc[C]//Solid State Circuits Conference.IEEE,2010:1-4.
[6] Kotturi D,Yoo S M,Blizzard J.AES crypto chip utilizing high-speed parallel pipelined architecture[C]//IEEE International Symposium on Circuits and Systems.IEEE,2005:4653-4656.
[7] 李冬冬,杨军.并行AES算法加密解密电路的高效实现[J].微电子学与计算机,2015,32(3):100-103.
[8] 郭岩松,刘雷波.一种面向分组密码的粗粒度可重构阵列及AES算法映射[J].微电子学与计算机,2015(9):1-5.
[9] 陈韬,罗兴国,李校南,等.一种基于流处理框架的可重构分簇式分组密码处理结构模型[J].电子与信息学报,2014,36(12):3027-3034.
[10] Liu B,Baas B M.Parallel AES Encryption Engines for Many-Core Processor Arrays[J].IEEE Transactions on Computers,2013,62(3):536-547.
