一种优势关系粗糙集近似集动态更新算法
2018-04-18洪智勇李少勇
洪智勇 李少勇
(五邑大学计算机学院 广东 江门 529020)
0 引 言
粗糙集理论是波兰科学家Pawlak在1982年提出的一种有效处理不确定性问题的数学工具,能够智能化处理不精确、不一致和不完备的数据[1]。由于不要求具备先验知识且运算过程简单,因而粗糙集理论成为一种日益重要的智能信息处理工具,广泛地运用在机器学习、知识发现、数据挖掘和决策分析等研究领域[2]。然而Pawlak粗糙集不能处理具有偏好序属性域的信息[3],为此,Greco等[4]提出了优势关系粗糙集模型。优势关系粗糙集模型是Pawlak粗糙集的一个扩展模型,主要创新是用一个优势关系替代Pawlak粗糙集中的等价关系;在论域上构造两种信息粒(优势集和劣势集);把决策类向上和向下联合作为被近似的概念求其近似集。这些创新使粗糙集理论具有了处理偏好信息的能力[5],因此它被广泛地运用在与多指标决策辅助和多指标排序相关的研究领域[6]。
在优势粗糙集方法中,近似集是在优势原则具有协调性的基础上定义的。它要求评价对象的所有指标值都不差于一个参考对象时,评价对象才能归到不差于参考对象所在的类中。然而,少量指标的不协调会减少下近似集中的对象数量,在一定程度上损失了从较大数据集中发现有用模式的机会。Greco等在减少优势原则约束基础上,提出了一种变量协调的优势关系粗糙集方法,允许一些不协调的对象包含到下近似集[7-9]。由于协调性测度能够用于控制上近似集和下近似集的大小,Baszczyński等[10]基于讨论对象集、属性集和优势关系单调性的结果提出了一种具有单调变量协调的优势关系粗糙集方法。随后,他们针对变量协调优势关系粗糙集方法设计了一种连续覆盖规则归纳算法(VC-DomLEM)用于生成最小决策规则集,能够适用于有序和非有序数据[10]。Szeląg等[11]基于变量协调优势关系粗糙集方法构造了一个适用于多指标排序的偏好学习模型。
由于传统的优势关系粗糙集方法并不能直接处理动态变化的数据,本文借鉴已有的利用优势关系粗糙集方法处理动态数据的研究成果,给出一种基于有序等价类进行信息粒合并的快速优势关系粗糙集近似集动态更新方法。当动态偏好序信息系统的对象集发生变化时,该方法能有效地提高优势关系粗糙集近似集更新速度。
1 预备知识
定义1[1]S=(U,A,V,f)表示一个决策信息系统,式中:
(1)U表示论域,即一个非空有限对象集;
(2)A表示一个非空有限属性集,A可以拆分成C∪{d},C表示非空有限条件属性集,d是决策属性;

(4)f:U×A→V是信息函数,它为每个对象的任一属性都赋予一个信息值,即∀x∈U和∀a∈A,∃f(x,a)∈Va。
∀a∈C,由于a具有一个偏好序值域,因此在论域上有一个对应的偏好关系a,即∀x,y∈U,如果f(x,a)≥f(y,a)则x关于属性a偏好y,表示为xay。如果P⊆C,对∀a∈P都有f(x,a)≥f(y,a),称x在P上优于y,记为xDPy,DP表示基于条件属性集P的优势关系和分别表示x的P优势集和P劣势集。优势关系粗糙集方法把论域中的P优势集和P劣势集称为基本知识粒度。

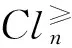



2 基于有序等价类计算基本知识粒的方法
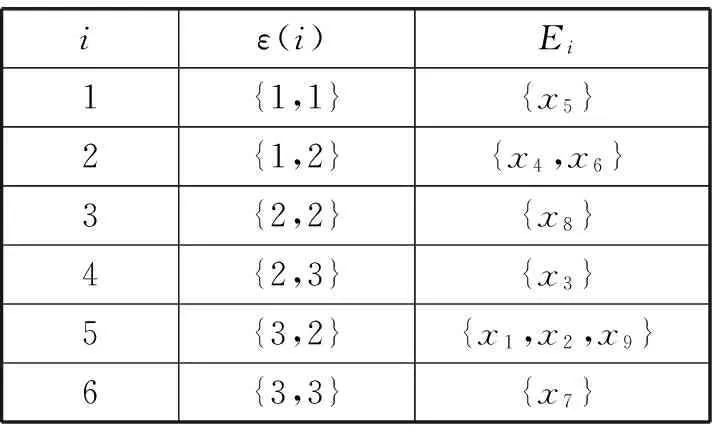
本文用ε(x)={f(x,a1),f(x,a2),…,f(x,ak)}表示对象x的可利用的k个属性的值序列。如果对象x绝对优于对象y,则可利用的k个属性中至少存在一个属性a满足f(y,a) 定义2T={ϑ,E}是一个有序等价类表,其中,E={E1,E2,…,En}是一组有序等价类,ϑ={ε(1),ε(2),…,ε(n)}是有序条件属性值序列集。∀i∈{1,2,…,n},ε(i)={f(y,a1),f(y,a2),…,f(y,ak)}是等价类Ei中任意对象y的k个条件属性值。如果∀r,s∈{1,2,…,n}且等价类Es优于等价类Er,则ε(r)<ε(s)。如果r 例1表1是一个决策信息系统,P={q1,q2}是条件属性集,d是决策属性。 表1 决策信息系统 根据定义2,表2是基于表1的一个有序等价类表。 表2 有序等价类表 从定义2可知,如果ε(r)<ε(s)那么等价类Es优于等价类Er,也就是说,等价类Es中任意对象的优势集包含等价类Er中所有对象。因此,等价类Es中任意对象优势集和劣势集的定义可以改写如下: 例2(继续例1)计算论域U中每个对象的P优势集和P劣势集。 输入:新添加的对象集合X+及已有有序等价类表记为T。 输出:更新后的有序等价类表记为T′。 (2) 比较E和E+中每个元素的ε; (5) 得到更新后的有序等价类表T′。 算法1中第1步是计算有序等价类的增量,其复杂度为O(|X+|2|P|)。第2~4步是更新原有等价类,其复杂度为O(|E+||E|)。由于O(|X+|2|P|+|E+||E|)=O(|X+|2|P|),因此更新算法复杂度远小于从又开始计算有序等价类表的复杂度O(|U+X+|2|P|)。 五是轮养。该鱼养殖具有广泛的适应性,不论是单一养殖或者多品种立体混养,都可以采用轮捕轮放,分批上市,捕大留小,提高养殖效益。 基本知识粒的动态更新目的是为了更新近似集。本文的实验设计思想是把动态更新知识粒的方法嵌入到原始的优势关系粗糙集方法近似集计算过程中,验证该方法能否有效改善优势关系粗糙集近似集计算效率。 为了保证实验的有效性,本文实验数据集采用UCI中四个不同数据集car、glass、iris和wine。这4个数据集的基本信息见表3。 表3 实验数据集基本信息 实验平台为一台个人计算机(PC),其配置为Inter(R)P6100 2.0 GHz,RAM2.0 GB和Windows 7。 分别把表3中4个数据集分成相等的两个部分:测试数据集和备份数据集。首先计算出测试数据集的近似集,然后从每个备份数据集中随机抽选出30、40、50、60和70个对象添加到测试数据集中,分别用动态和静态算法计算基于它们的优势关系粗糙集近似集。基于静态算法和动态算法的耗时,计算动态算法相对于静态算法的加速比,结果见表4。 表4 插入多个对象时近似集更新加速比表 从表4中数据可看出,在四个不同的数据集上插入多个对象时,动态算法相对于静态算法的加速比都超过了20,最高达94.068 7。同时,随着插入对象数量的增加,加速比也随之增大。表4中的加速比指标反映出动态方法具有明显的性能优势,随着插入对象数量的增加,优势越明显。 与添加对象实验不同,直接把表3中4个数据集作为测试数据集计算近似集。然后从测试数据集中随机删除10、20、30、40和50个对象,分别用动态和静态算法计算基于它们的优势关系粗糙集近似集。基于静态算法和动态算法的耗时,计算动态算法相对于静态算法的加速比,结果见表5。 表5 删除多个对象时近似集更新加速比表 从表5中数据可看出,在四个不同的数据集上删除多个对象时,动态算法相对于静态算法的加速比都超过了8,最高达60.095 5。随着删除对象数量的增加,加速比也随之减小。表5中的加速比指标反映出动态方法具有明显的性能优势,随着删除对象数量的增加,优势下降。 总之,从实验结果来看,不论是添加对象还是删除对象,动态算法计算性能总是优于静态算法。 动态数据环境下的知识更新是大数据时代的知识发现研究的热点问题之一,对合理、高效地利用数据进行辅助决策有重要意义。本文以优势关系粗糙集方法为研究对象,首次提出了一些能用于多对象添加或删 除时优势关系粗糙集近似集更新的动态策略及其相应的算法。实验验证了动态方法是一种高效的优势关系粗糙集近似集更新方法,能够用于少量对象频繁更新的动态信息系统中。在以后的研究中,我们将进一步讨论对象集、属性集和属性值同时变化的情况下优势关系粗糙集近似集的更新。 [1] Pawlak Z.Rough sets[J].International Journal of Computer & Information Sciences,1982,11(5):341-356. [2] 于洪,王国胤,姚一豫.决策粗糙集理论研究现状与展望[J].计算机学报,2015(8):1628-1639. [3] Slowinski R.Rough Set Learning of Preferential Attitude in Multi-Criteria Decision Making[C]//International Symposium on Methodologies for Intelligent Systems.Springer-Verlag,1993:642-651. [4] Greco S,Matarazzo B,Slowinski R.Rough sets theory for multicriteria decision analysis[J].European Journal of Operational Research,2001,129(1):1-47. [5] Chakhar S,Ishizaka A,Labib A,et al.Dominance-based rough set approach for group decisions[J].European Journal of Operational Research,2016,251(1):206-224. [6] Rawat S,Patel A,Celestino J,et al.A dominance based rough set classification system for fault diagnosis in electrical smart grid environments[J].Artificial Intelligence Review,2016,46(3):389-411. [7] Greco S,Matarazzo B,Slowinski R,et al.Variable Consistency Model of Dominance-Based Rough Sets Approach[C]//Revised Papers from the Second International Conference on Rough Sets and Current Trends in Computing.Springer-Verlag,2000:170-181. [8] Greco S,Matarazzo B,Slowinski R,et al.An Algorithm for Induction of Decision Rules Consistent with the Dominance Principle[C]//Rough Sets and Current Trends in Computing,Second International Conference,RSCTC 2000 Banff,Canada,October 16-19,2000,Revised Papers.DBLP,2000:304-313. [11] Szeląg M,Greco S,Sowiński R.Variable consistency dominance-based rough set approach to preference learning in multicriteria ranking[J].Information Sciences,2014,277(2):525-552. [14] Jia X,Shang L,Ji Y,et al.An Incremental Updating Algorithm for Core Computing in Dominance-Based Rough Set Model[C]//International Conference on Rough Sets,Fuzzy Sets,Data Mining and Granular Computing.Springer-Verlag,2009:403-410. [15] Xiuyi Jia,Lin Shang,Jiajun Chen,et al.Incremental Versus Non-incremental:Data and Algorithms Based on Ordering Relations[J].International Journal of Computational Intelligence Systems,2011,4(1):112-122. [16] Chen H,Li T,Da R.Maintenance of approximations in incomplete ordered decision systems while attribute values coarsening or refining[J].Knowledge-Based Systems,2012,31(7):140-161. [17] Luo C,Li T,Chen H,et al.Incremental approaches for updating approximations in set-valued ordered information systems[J].Knowledge-Based Systems,2013,50(50):218-233. [18] Luo C,Li T,Chen H,et al.Fast algorithms for computing rough approximations in set-valued decision systems while updating criteria values[J].Information Sciences,2015,299(C):221-242. [19] Luo C,Li T,Chen H.Dynamic maintenance of approximations in set-valued ordered decision systems under the attribute generalization[J].Information Sciences,2014,257(2):210-228. [20] Wang S,Li T,Luo C,et al.Efficient updating rough approximations with multi-dimensional variation of ordered data[J].Information Sciences,2016,372:690-708.
3 基于有序等价类的知识粒动态更新
3.1 有序等价类的动态更新算法
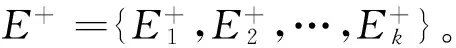
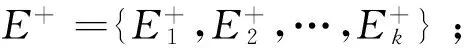


3.2 基本知识粒的动态更新


4 实验评估


4.1 添加对象实验

4.2 删除对象实验

5 结 语
