局部一致性的信息熵Relief特征加权算法
2018-04-18张敏徐栋
张 敏 徐 栋
1(山东管理学院机电学院 山东 济南 250357) 2(北京理工大学信息与电子学院 北京 100081)
0 引 言
特征选择作为维度削减技术中的热门研究课题,分为过滤法和封装法。封装法依赖分类器的选择,分类效果因分类器选择的不同而产生巨大差异。过滤法因不依赖分类器得到较广泛的关注。Relief算法是一种过滤算法,用于二类数据的特征选择。虽然Relief算法较早提出且得到广泛应用,但该算法依然存在缺陷,如算法的数学定义形式较抽象,性质难以解释,且对噪声和野点鲁棒性较差。ReliefF和Multi-Relief算法[1]作为Relief的推广是处理多类数据的算法,通过将多类问题转化为多个一对多的两类问题。文献[2]提出迭代Relief (I-Relief)算法,I-Relief算法的目标函数的构造是在间隔最大化基础上,并借助类EM的学习策略来更新权重向量的规则,有效弥补了Relief算法对目标函数定义不明确的缺点。
基于上述进展,本文在优化目标函数中引入正则项因子,使分类正确样本周围样本的分类结果保持较高的分类一致性,减小分类错误率。用模糊隶属度构造新的模糊差异度量,并且基于信息熵原理,重新构造了新的间隔最大化目标函数。探讨了具有更好适应性二类数据的鲁棒Relief特征加权算法,并进一步将算法扩展到多类数据的算法。
1 局部一致性的信息熵Relief算法
1.1 Relief和间距最大化
Relief算法的每个特征向量对不同样本有不同的区分能力,其算法是借助这种区分能力来估计特征权值及其重要性。具体算法如下:

(2) 任选样本xn,计算其同类最近邻样本NH(xn)和异类最近邻样本NM(xn)。
(3) 根据式(1)、式(2)更新权值wj:
(1)
(2)

(4) 当t=T时,算法结束,否则返回步骤(2)。
(5) 输出迭代后的权值向量w。
文献[4]初次提出Relief算法和间距最大化的关系,并将其应用于特征选择。文献[2]基于间距最大化对Relief算法进行了具体的数学推理证明,公式如下所示:
s.t.|w|22= 1,w≥0
(3)
式中:ρn(w)表示第n个样本对应的间距大小。
该目标函数存在如下缺陷:1) 特征权值较易集中于某一个值,忽略其他权值,自适应性较差。2) 不能有效地去除冗余特征,对噪声和野点有较差的鲁棒性,分类错误率高。
针对Relief算法以上缺陷,本文引入如下技术:1) 信息熵控制;2) 模糊差异性度量;3) 分类局部一致性。
1.2 信息熵Relief算法
传统的Relief特征加权算法在构造目标函数时特征权值分布不均匀,易集中于某一个特征。实际上目标函数的构造应根据样本的重要性赋予不同的权值。信息熵[3]表明每个消息所提供的平均信息量。熵和样本在属性域上的分布成正比,熵越大,样本分布越均匀。引入信息熵理论公式如下所示:
(4)
目标函数的间距最大化使特征权值容易趋向于某一分量,引入最大信息熵,使各权值的概率分布尽可能均等,改善了Relief算法自适应差的缺陷。
1.3 模糊差异性度量
Relief算法中,差异性度量受噪声和野点的影响较大。本研究采取样本与近邻的p个样本的差异的均值取代。
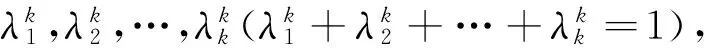
(5)
模糊隶属度公式如下所示:
(6)
新的差异性度量公式如下所示:
(7)
xn到最近异类样本和最近同类样本的第j维特征的模糊差异度量表示公式如下所示:
(8)
式中:NM(xn)代表除xn以外的所有和xn异类的样本集合;NH(xn)代表除xn以外的所有和xn同类的样本集合。
1.4 局部一致性Relief算法
为提高分类准确率,对目标训练数据施加约束条件,即在Relief算法基于分类边界的全局优化框架中引入额外的局部一致正则项,公式如下所示:
(9)
(10)
(11)
Yij=|yi-yj|
(12)

算法加入正则项因子, 以相邻样本间的相似性为度量,使分类正确样本周围样本的分类结果保持较高的分类一致性,提高了分类准确率。
2 局部一致性的信息熵Relief特征加权算法
2.1 新的优化目标函数
结合信息熵Relief算法、模糊差异性度量、局部一致性Relief,得出新的优化目标函数公式如下所示:
(13)
s.t.|w|22= 1,w≥0
对式(13)做如下说明:目标函数由3项组成。其中第1项对应于间距最大化,第2项对应于特征加权的信息熵,第3项对应于局部分类一致性。参数λ、η是常量,用于平衡各项的贡献。
2.2 理论推导
对于式(13)的优化目标函数,运用拉格朗日定理,可得以下定理。
定理:目标函数J(w)满足式(14)时,取得最大值。
(14)
证明:对式(13)构造拉格朗日函数得:
式中:β>0为拉格朗日因子。
置L(wj,β)对变量wj、β的偏导数为0,可得式(15)-式(17):
(15)
(16)
由式(15)得:
(17)
联合式(16)、式(17)得:
算法1基于二类数据的局部一致性信息熵Relief特征加权算法LIE-Relief-T。
(3) 根据式(14)更新权值wj(t)。
(4) 若t=T或|w(t)-w(t-1)|<θ,算法结束,否则返回(2),且使t=t+1。
(5) 输出更新后的w。
2.3 基于多类数据的局部一致性信息熵Relief特征加权算法
本节将LIE-Relief-T算法扩展到多类版本LIE-Relief-M算法,采用的策略是不论异类样本被划分为多少类,将所有异类样本作为同一类数据处理[5]。则xn对应的样本间距公式如下所示:
(18)
(19)

(20)
根据2.2节的推导方法,可得多类数据输出权值:
3 实现验证
3.1 实验数据
为了验证LIE-Relief-T算法和LIE-Relief-M算法的性能,本实验采取的数据集为UCI基准数据集和基因表达数据集[6],如表1-表2所示。

表1 UCI数据集
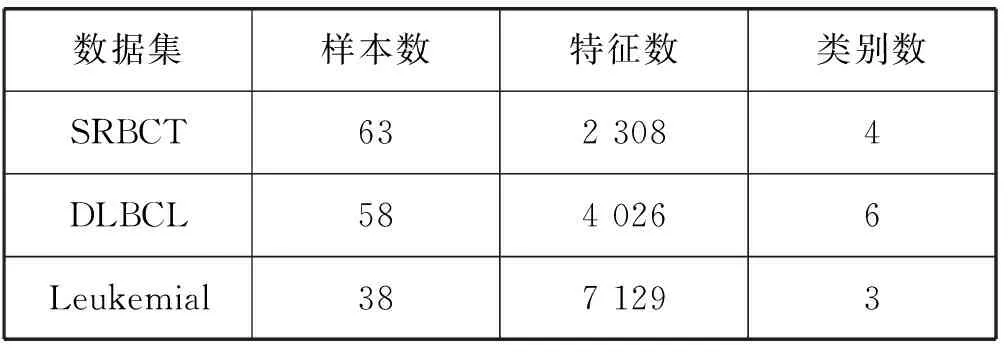
表2 基因表达数据集
为了测试LIE-Relief-T算法和LIE-Relief-M算法确定有效特征的能力,在UCI数据集每个样本中加入干扰特征(二类数据90个,多类数据45个),并将UCI数据集按照5∶1的比例随机分为训练集和测试集,将训练集比例10%的样本错贴类标签作为野点。对基因表达数据集采用leave-one-out策略进行分类测试。
3.2 实验设置
本文提出的LIE-Relief-T二类数据集算法,使之与经典的Relief算法、Simba算法[7]、I-Relief算法[2]、f-MMD算法[8]的性能进行对比;LIE-Relief-M多类数据集算法与ReliefF算法[9]、I-Relief-2算法[10]的性能进行对比。

实验所用计算机为Intel(R) Core(TM) i5-4210M, 2.60 GHz的CPU,4.0 GB的内存,Win7操作系统,Matlab2009版本。
实验选用K-NN分类器[11],K值由交叉验证策略确定。
3.3 实验结果
以ROC(Receiver operating characteristic)曲线和分类错误率为评价标准评估实验结果。图1-图2为各种算法在UCI数据集上运行10次取平均值后得到的ROC和分类错误率曲线。

图1 不同算法在UCI数据集上的ROC曲线图
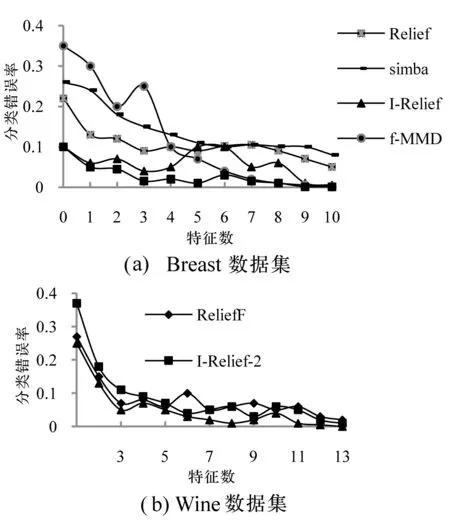
图2 不同算法在Breast/Wine数据集上的分类错误率比较
其中,图1为算法的ROC曲线图,图2分别抽取了UCI数据库的Breast和Wine数据集。从图1、图2能直观得出,本文算法因增加信息熵和局部分类一致参数模型,较传统的算法分类错误率更小,具有更明显的优越性或竞争。
图3中,dw=‖w(t)-w(t-1)‖,LIE-Relief-M算法的误差较小,经过较少的迭代次数收敛性曲线即达到稳定状态。

图3 LIE-Relief-M算法在Wine数据集上的收敛曲线
图4为多类算法在Wine数据集上的特征权值变化曲线。其中前13维特征来自Wine数据集,后45维特征是手动添加的干扰特征,理想情况下后45维特征的权值越小越好。由曲线可得:ReliefF算法的干扰特征权值最大且稳定性最差,LIE-Relief-M算法加入信息熵控制,使算法对例外点和野点的鲁棒性增强,干扰特征权值最小且接近于0,且干扰特征权值变化曲线收敛性较好。同样,在其他UCI数据集上得到了类似的实验结果。

图4 不同算法在Wine数据集上的权值向量对比
基因表达数据集均为高维数据,没有添加干扰因素,采用分类错误率为实验评估标准。如图5所示。
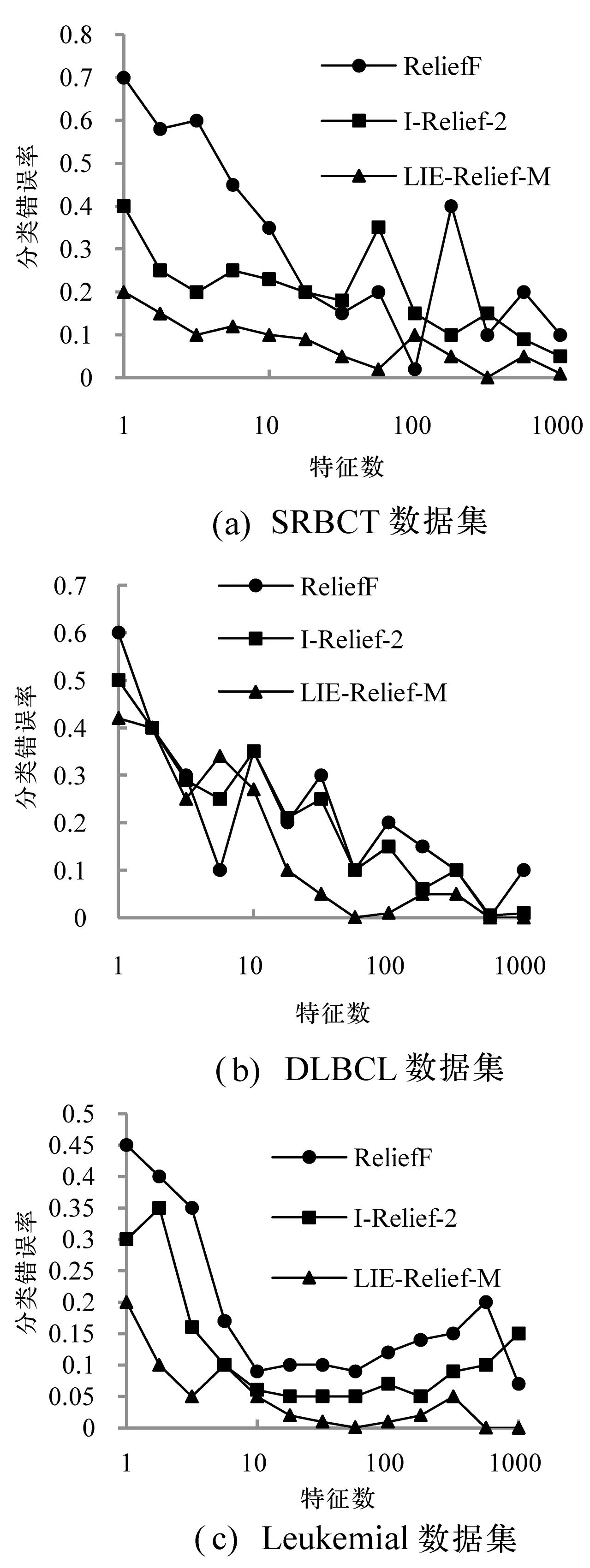
图5 不同算法在基因表达数据集上的分类错误率比较
由图5可得,LIE-Relief-M算法因加入分类局部一致性参数因子,在基因表达数据集上的分类错误率最小,较其他两种算法具有更好的分类性能。
4 结 语
本文在Relief算法的基础上,基于信息熵、模糊差异性度量、分类局部一致性提出LIE-Relief-T二类数据算法,并将其扩展到多类LIE-Relief-M算法。在UCI和基因表达数据集上分别验证了LIE-Relief-T算法和LIE-Relief-M算法。实验结果表明新算法不但分类错误率低,对野点和噪声也具有更好的适应性和鲁棒性。未来的工作中,对算法参数选择的理论依据、开发适合大规模数据集的快速Relief特征加权算法将是研究的方向。
[1] Ye K,Feenstra K A,Heringa J,et al.Muiti-RELIEF:a method to recognize specificity determining residues from multiple sequence alignments using a Machine-Learning approach for feature weighting[J].Bioinformatics,2014,24(1):18-25.
[2] Sun Y.Iterative RELIEF for feature weighting:Algorithms,theories,and applications[J].IEEE Trans on Pattern Analysis and Machone Intelligence,2013,29(6):1035-1051.
[3] Shannon C E.A mathematical theory of communication[J].Bell System Technical Journal,1948,27(3):379-423.
[4] Gilad B R,Navot A,Tishby N.Margin based feature selection-Theory and algorithms[C]//ICML’04 Proceedings of the twenty-first international conference on Machine learning.ACM,2004:43.
[5] 陈俊颖,陆慧娟,严珂,等.Relief和APSO混合降维算法研究[J].中国计量大学学报,2017,28(2):214-218.
[6] Sun S L,Xu Z J,Yang M.Transfer learning with part-based ensembles[J].Lecture Notes in Copmuter Science,2013,7872:271-282.
[7] Sun Y,Wu D.A RELIEF Based Feature Extraction Algorithm[C]//Siam International Conference on Data Mining,SDM 2008,April 24-26,2008,Atlanta,Georgia,Usa.DBLP,2008:188-195.
[8] Selen U,Jaime C.Feature Selection for Transfer Learning[C]//European Conference,ECML PKDD 2011,Greece,2011:430-442.
[9] Robnik M,Kononenko I.Theoretical and empirical analysis of Relief and RRelief[J].Machine Learning,2014,53(102):23-69.
[10] Theodoridis S,Koutroumbas K.Pattern Recognition[M].3rd ed.New York:Academic Press,2013:44-60.
[11] Jing L P,Ng M K,Huang J Z.An Entropy Weighting k-Means Algorithm for Subspace Clustering of High-Dimensional Sparse Data[J].IEEE Transactions on Knowledge & Data Engineering,2007,19(8):1026-1041.
