一种基于LDA和TextRank的文本关键短语抽取方案的设计与实现
2018-04-18郎冬冬刘晨晨冯旭鹏刘利军黄青松
郎冬冬 刘晨晨 冯旭鹏 刘利军 黄青松,2*
1(昆明理工大学信息工程与自动化学院 云南 昆明 650500) 2(云南省计算机应用重点实验室 云南 昆明 650500)
0 引 言
关键短语被定义为针对一篇或多篇文档具有总结性的词或短语的集合。自动关键短语抽取[1]是提取给定文档中与主题相关的一组短语,在信息检索、关键词抽取、自动摘要等领域具有重要应用。
关键短语抽取可分为有监督和无监督两种方法,而无监督的方法可分为两种:基于主题聚类和图排序的方法[2]。基于图排序中最常用的是TextRank算法,该算法将文本中的句子、词等作为无向图的节点,把它们之间的关系作为边的权重,再根据排序结果选取出关键词或关键句。顾益军等[3]将TextRank与LDA相结合,使候选词语节点的重要性按文档集主题分布进行了非均匀转移。方康等[4]提出了基于马尔可夫模型加权TextRank的单文档关键词抽取算法,准确率有所提高。Rezaei等[5]针对网页提出了一种融合聚类与TextRank模型相结合的方法,它对所有的名词进行聚类,然后利用TextRank模型抽取关键词,实验效果较好。文献[6]利用深度学习结合词汇聚类的方法进行关键词抽取,对于篇幅较长的文章效果理想,但对于篇幅较短的则无法满足需求。由此可知基于图方法的缺陷是无法抽取出涵盖主题信息的关键短语。第二种基于主题的方法将候选关键词或短语聚类成主题,每个主题由相关的词或短语组成。Shang等[7]融合LDA与TextRank模型,提出了一种专门用于基因信息的摘要系统。TextRank算法除了被用于传统的文本提取之外,还被用于情感摘要的提取[8-9]、网页内容可信度识别[10]、会议文摘等。Blei等[11]在隐含主题挖掘思想的基础上,通过对主题词汇组合成短语,得到了具有表意性的关键短语集合。文献[12,13]从修改短语的搭配方式入手,以主题标签抽取的形式在新闻类语料集上获得了更具解释性的关键短语集合。基于潜在主题方法在关键短语抽取方面取得了较好的效果,但该方法没有综合考虑文档的结构信息,所以在单文本关键短语抽取方面尚存在不足。
针对上述问题,本文综合考虑文档的主题信息和结构信息,根据文档中的词语共现构建出无向加权图。通过词图节点的主题相似度得到边的权值,引入节点主题影响力因素修改随机跳转概率,在加权无向图上运行TextRank算法提取关键词后,再利用bootstraping算法思想迭代生成短语来增强关键词的表意性。最后,将模型用于单文本任务中,实验结果表明该方法可有效提取表意性较强且涵盖文本主要主题信息的关键短语。
1 候选关键词抽取
基于LDA和TextRank的单文本关键短语抽取模型整体框架如图1所示。模型主要分为三部分:
1) 利用主题模型得到目标文本所在语料集的主题分布;
2) 根据目标文本的词语共现关系和词语相似度构建关键词图,在图的基础上利用TextRank算法获取候选关键词排名;
3) 由候选关键词迭代生成关键短语。
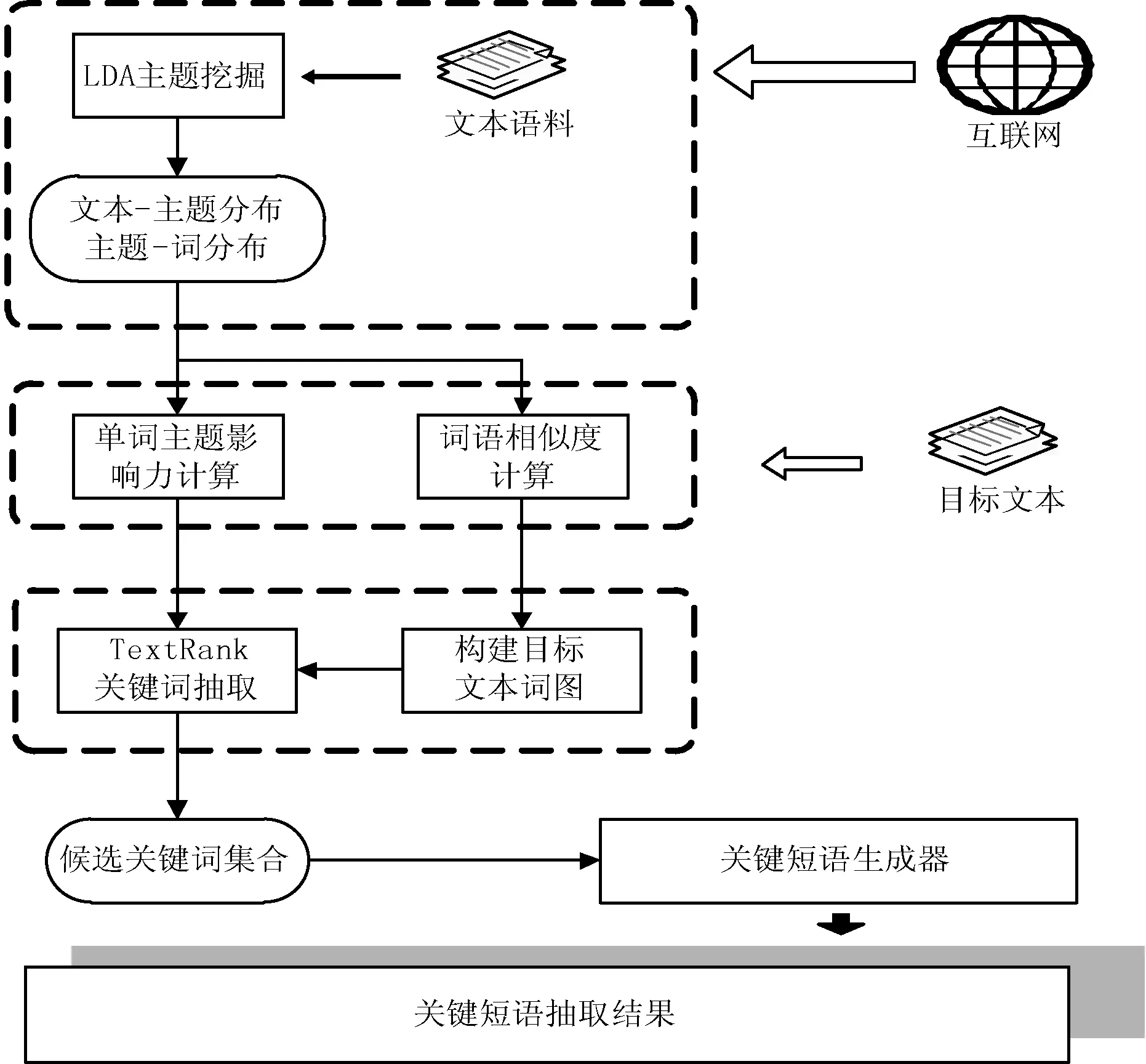
图1 关键短语抽取模型整体结构
1.1 基于LDA模型的文本主题抽取
LDA模型是由Blei等提出的一种对自然语言进行建模的生成模型,适合挖掘大规模文档集中潜藏的主题信息[14]。如图2所示。
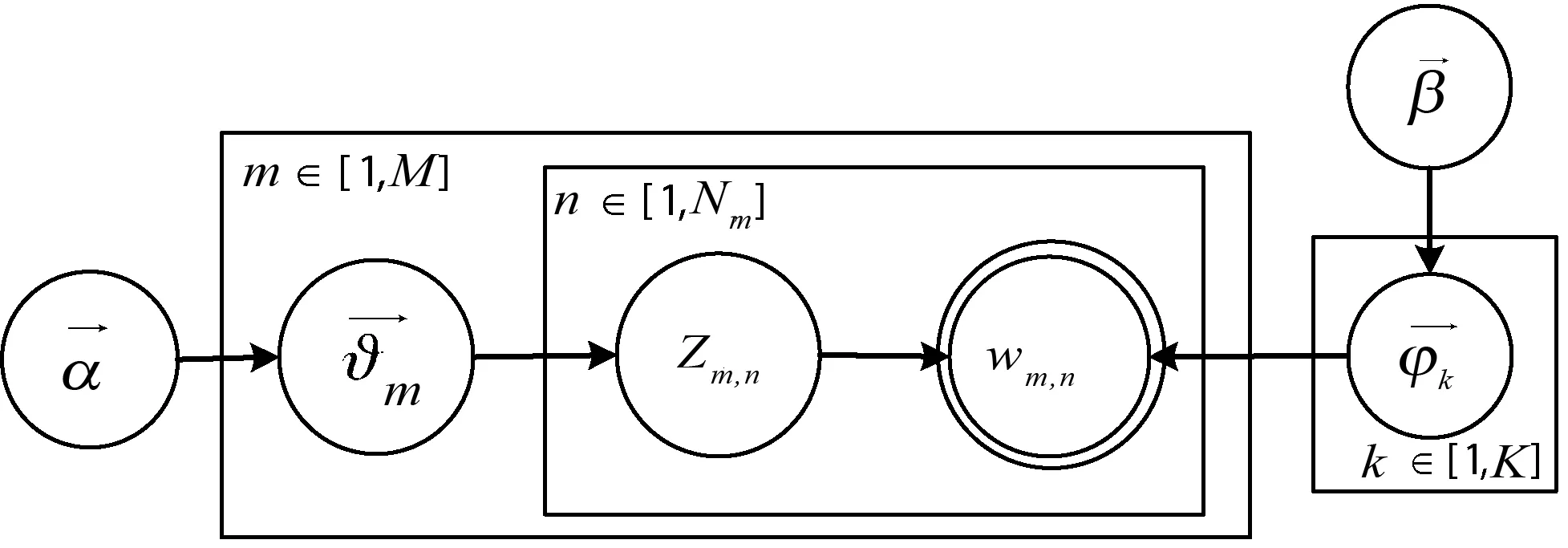
图2 LDA图模型
图中:α和β分别为ϑm和φk的超参数,ϑm为文档-主题概率分布,φk为主题-词汇概率分布,K为主题个数,M为总的文档数目,Nm为第m篇文本中单词总数,Zm,n为词的主体分布,wm,n为词,通过对变量Z进行Gibbs间接估计θ和φ:
(1)
(2)
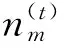
1.2 目标文本单词图构建
为提高关键词抽取效果在TextRank中构建的单词图中,本文选择构建无向加权图[15]。如在长度为k的滑动窗口中,将窗口中第一个词指向剩余的词,节点间边的权重则为词语间的相似度。
对给定文档D以句子为单位进行分割,即D=[S1,S2,…,Sm]。对于每个句子Si∈D进行预处理和词干抽取,为了更好获取到关键短语的表意性,词干抽取时只抽取名词和动词用于单词图构建,即Si=[wi,1,wi,2,…,wi,n],其中wi,j∈Si是候选关键词。构建候选关键词图G=(V,E),V为节点集V=[w1,w2,…,wn],E为节点共现关系生成之间边的集合,k为窗口长度,两点间边(wi,wj)的权重可表示为e(wi,wj)。TextRank是在PageRank算法上演变而来,PageRank的标准公式[16]如式(3)所示。其中s(vi)表示节点的重要程度,它取决于指向该节点的节点分配给该节点的权重比,在PageRank中常取相同的值,In(vi)为指向节点vi的集合,out(vi)为vi指向的其他节点的集合,d为阻尼系数,通常取0.85,(1-d)表示每个节点随机跳转到其他节点的概率。TextRank在PageRank算法的基础上引入边的权值的概念,用于代表语义特征在构建单词图时将词语间的共现关系表示为词语间的语义关系。所以,本文将词语在主题上的相似度作为词语间的语义特征,即单词图中边的权重。具体方法通过余弦相似度取得,计算如式(4),则TextRank的公式如式(5)。
(3)
(4)
(5)
以“电脑维修属于一门技术,可解决硬件和软件等问题。电脑价格是比较昂贵的设备,而日常办公对硬件性能要求较低,用户不会轻易抛弃,所以电脑维修业务有充足的市场空间。”为例构造的滑动窗口长度为3的单词图如图3所示。
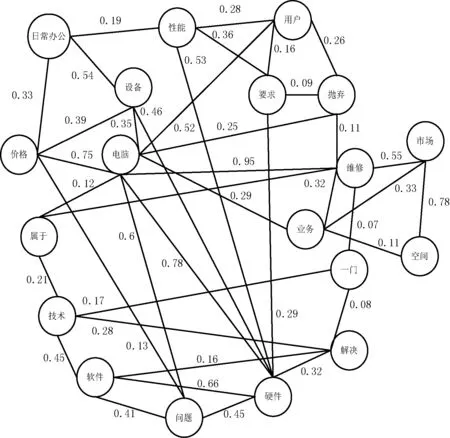
图3 文本单词图构建示例
1.3 引入节点主题影响力的关键词抽取
在TextRank算法中,节点的重要性会随迭代过程不断变化,由式(3)可知,节点间的随机跳转具有相同概率,但如果参考LDA文本生成的思想就容易得出:在某个主题下,作为节点的单词出现的概率越高,则其他节点跳转到该节点的可能性也应该更高。如在一组节点集为“安全,食品,监管,大气,治理,污染”的加权无向图中,给定“环境保护”这一主题后,“污染”这一特征词出现的概率较高,所以在加权无向图上利用TextRank算法时,其他节点应具有更高概率随机跳转到节点“污染”。因为“食品”和“环境保护”这一主题的相关性相较于“污染”要小得多,所以针对“环境污染”这一主题在加权无向图上使用TextRank算法时,其他节点随机跳转到节点“食品”的概率应该降低。基于这种假设,将节点的主题影响力融入到TextRank的迭代中。文献[17]对LDA训练出来的结果按照权重特征对主题特征词进行重排序的做法,主要从两方面计算单词的主题影响力:1) 单词在主题下具有较高的权重;2) 单词和表征主题的主题词具有较高的相似性。
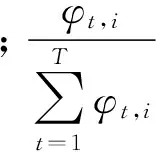
(6)
(7)
综合权重和相似度两方面因素,节点词语wi在主题t中的影响力计算公式如式(8)。一个节点跳转到其他节点的随机跳转概率之和应为1,所以对式(8)做归一化处理,得到式(9),再将该值作为其他节点在主题t下跳转到该节点的随机概率。
WTt,i=KRt,i×AVG_PMIt,i
(8)
(9)
综合以上因素,加权无向图的迭代式(5)变更为式(10)。当迭代次数达到100时或相邻两次迭代节点的重要程度值小于0.000 1时算法终止。
(10)
2 关键短语生成
引入节点主题影响力和迭代算法终止后,得到一篇文档在各个主题下的关键词的重要程度排序,此时再将文档中覆盖度最高的主题代表该文档。随后本文对近期的热点新闻语料按照本文方法进行了关键词抽取,结果如表1所示,表中展示了按重要程度排名前十的关键词。
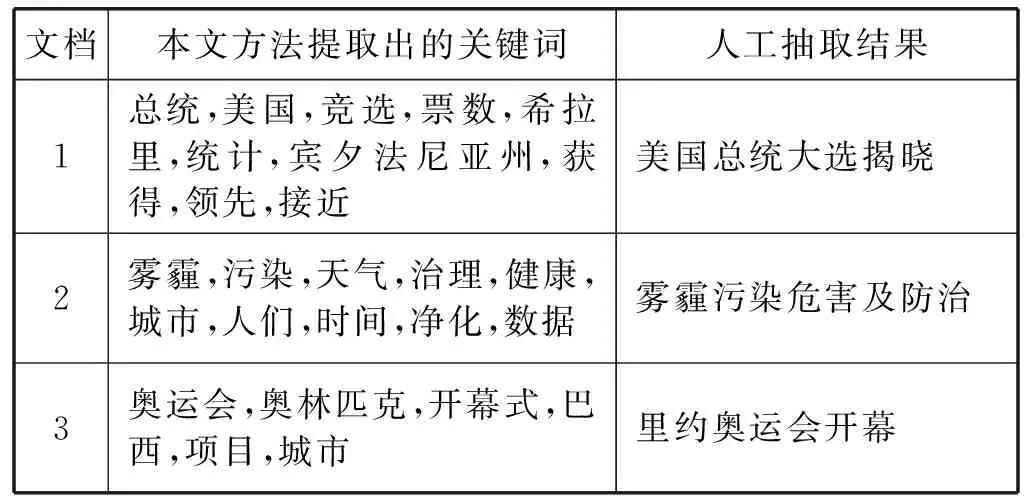
表1 本文方法与人工抽取结果对别示例
由表1可知,基于LDA和TextRank的关键短语抽取方法就可抽取出文档相关性较强、文档主题覆盖度较高的关键词。和人工抽取结果相比,对提取出的关键词集合在可读性上较差。如通过“总统,美国,竞选,票数,希拉里,统计,宾夕法尼亚州”等容易推断出该篇文档讲的是“美国总统竞选”相关的内容。但是由于关键词集合并不带有语义信息,在表意性上远远不如人工提取的标签“美国总统大选揭晓”更能代表该文档。所以针对此问题本文参照文献[13]的方法,利用bootstraping算法根据抽取出的关键词集合迭代生成关键短语,对词语在目标文本句中的共现关系计算关键短语的权重,然后再对关键短语的权重排序,最后选取前N个短语作为最终的关键短语。为避免统计词语共现时单篇文档提供信息量不足的问题,预先进行文本相似度计算,选取和目标文档主题相似度最高的若干篇文本进行词语的共现统计。
由于词语生成短语是一个迭代过程,在迭代过程中,首先将筛选出的关键词语两两组合成短语,在TextRank迭代终止后得到的短语权重及关键词语在文本句中的共现计算短语权重,再将权重大于阈值的短语加入关键短语集合,为提升关键短语排名,削弱更新关键短语词的权重,再进行下一步迭代,直到找不出符合条件的短语。在统计词语共现关系之前,预先对文本进行主题相似度计算,获取与目标文本最相关的若干篇文档,目的是避免单篇文本提供的信息不足,同时也不会大幅度削弱短语的权重。文本主题相似度由式(11)通过余弦相似度计算得出,其中θdi,t为文档di中主题t的概率,由式(2)计算取得。完整的关键短语生成如算法1所示。
(11)
算法1关键短语生成
输入:候选关键词集合C
输出:关键短语集合K
//候选关键词集合C为TextRank迭代计算得到的权重
//最高的前N个词
(1) 设置标志位Set flag = true
(2) set K=C
//初始关键短语集合等于候选关键词集合
(4)设定阈值 Set λ
(5) 计算集合C中关键词语的权值W(Ci)
//W(Ci)为TextRank在加权无向图上迭代得到的节点
//重要程度值
(6) while flag:
(7) for Ki in K:
(8)for Cj in C:
(9)生成短语P(Ki, Cj);
(10)统计P(Ki, Cj)在目标文本及相似文本句中的共现次数n(Ki, Cj);
(11)计算短语权重
//μ为权重系数
(12)end for
(13) end for
(14) for all P(Ki, Cj):
(15)if W(Ki,Cj) ≥ λ && P(Ki, Cj) K:
(16)将短语P(Ki, Cj) 添加到集合K;
(17)削弱更新Ki和Cj的权重:
(18)end if
(19) end for
(20) if 集合K未更新:
(21)set flag=false;
(22) end if
(23) end while
3 实 验
3.1 实验数据与预处理
实验从互联网采集的两类语料进行关键短语抽取:近期热点新闻事件语料和论文摘要语料,分别记作NEWS和ABSTRACTS。其中,NEWS包含“里约奥运会”、“神舟十一号飞船发射”、“美国总统选举”、“环境污染”、“应届毕业生就业”等五个热点事件语料各200篇,共1 000篇,人工标注的关键词数为8 033个;ABSTRACTS包含“计算机”、“社会学”、“建工”、“农学”、“军事”等五个领域的论文摘要各200篇,共1 000篇,并将文章作者拟定的关键字作为人工标注的关键词,共3 986个。
3.2 实验结果与分析
实验的评价标准分两个阶段评测:第一阶段利用准确率(precision)、召回率(recall)和F-measure来评测关键词的抽取效果,计算公式如式(12)-式(14)所示,其中nlabeled为关键词数,ncorrect为抽取出关键词中的关键词数,nall为抽取出的关键词总数;第二阶段评测生成的关键短语在文章话题覆盖度上的效果。将抽取出的短语和人工抽取的短语进行比较,话题相关记1分,部分相关记0.5分,不相关则记0分。如人工抽取结果为“美国总统大选”,模型方法抽取结果为“美国总统竞选”则记1分;人工抽取结果为“神州十一号飞船对接成功”,模型方法抽取结果为“神舟飞船”则记0.5分;人工抽取结果为“里约奥运会开幕式”,模型方法抽取结果为“巴西举行”则记0分。最后将总得分除以文本数作为关键短语抽取的精度。
(12)
(13)
(14)
由于以下参数会对本文方法的关键短语抽取效果造成影响:文本语料集主题数、构建单词图时滑动窗口的长度和单篇文本抽取的关键词个数,所以本文设计实验1和实验2来获得最优的参数值。


图4 不同主题数下的困惑度
从图4可知,在NEWS语料集和ABSTRACTS语料集中,随主题数的不断增加,困惑度均呈下降趋势。在NEWS语料集中,当主题数达到35时,困惑度趋于稳定;在ABSTRACTS语料集中,当主题数达到45时,困惑度趋于稳定。由此得出此时模型性能最佳,因此分别取主题数目为TNEWS=35,TABSTRACTS=45。
实验2:由于不同长度滑动窗口和单篇文本抽取的词数会对关键词抽取效果产生影响,且在文档结构的表征效果上也有着重要作用。取滑动窗口长度为4~24(间隔为4),分别在NEWS和ABSTRACTS上进行实验,为保证实验的合理性,阻尼系数取,实验结果如图5-图7所示。由图5可以看出,在NEWS语料集上,滑动窗口长度在4~20时,F1值变化不大,当滑动窗口长度大于20后有所下降,当滑动窗口长度取12左右时达到最优,在此状态下能最好地利用文档结构信息。单篇文档抽取关键词数量在6~13时效果较好。在ABSTRACTS上如图6看出,单篇文档抽取关键词数量在6~9式效果较好。相较于在NEWS语料集上的结果,F1测度值受窗口长度影响较小,当窗口长度K=24时仍能取得较好的效果,这与摘要文本包含主题较少有关。而当K>28时,F1值开始下降,这是因为相较于新闻文本,摘要文本篇幅较短,滑动窗口过大则加权无向图变为了全联通图。同时,由图7容易看出,抽取前5个词为关键词的准确率较高,表明该方法能够有效提高关键词的权重,并能够抽取出更接近人工标注的关键词。
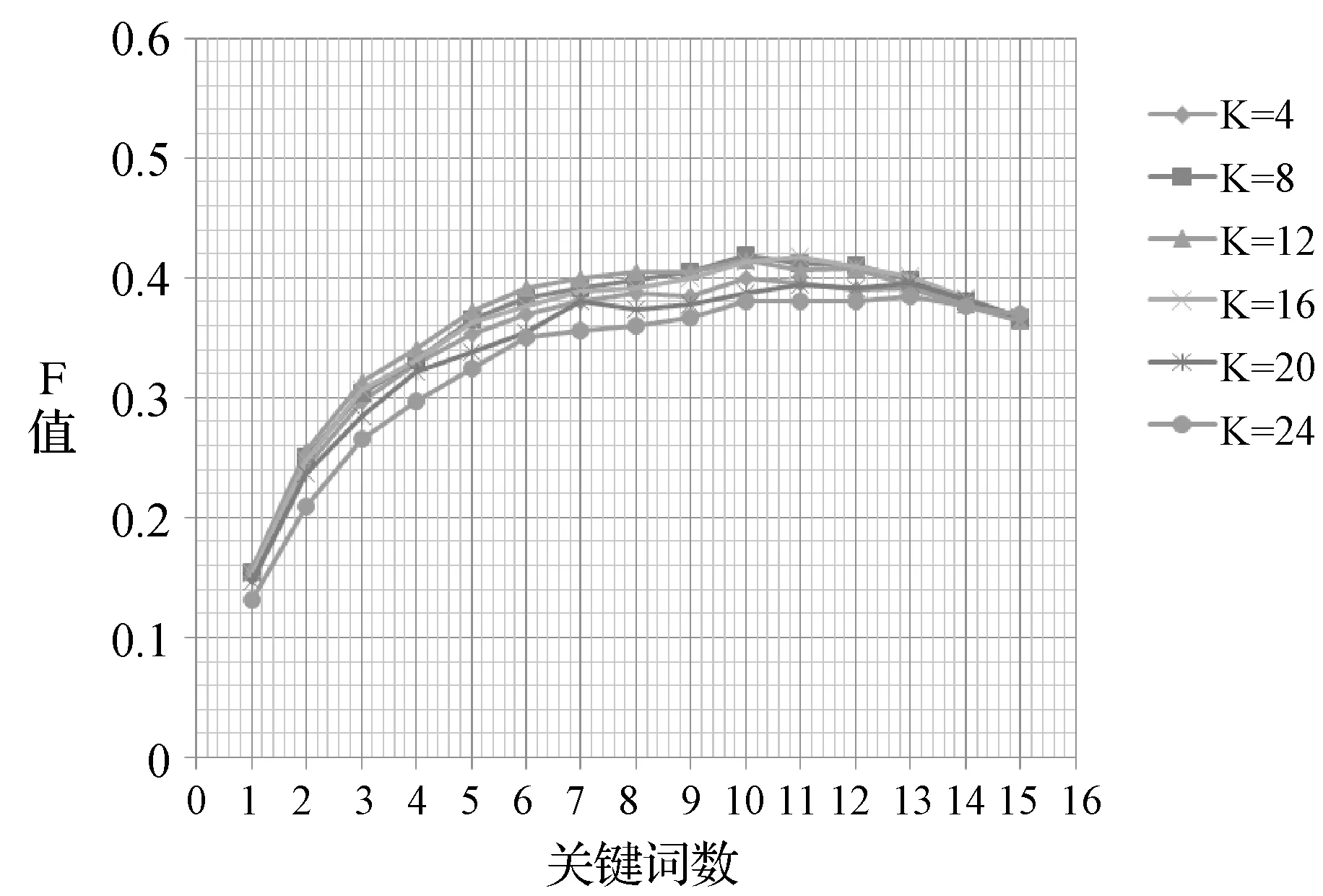
图5 不同滑动窗口长度在NEWS语料上的F1测度
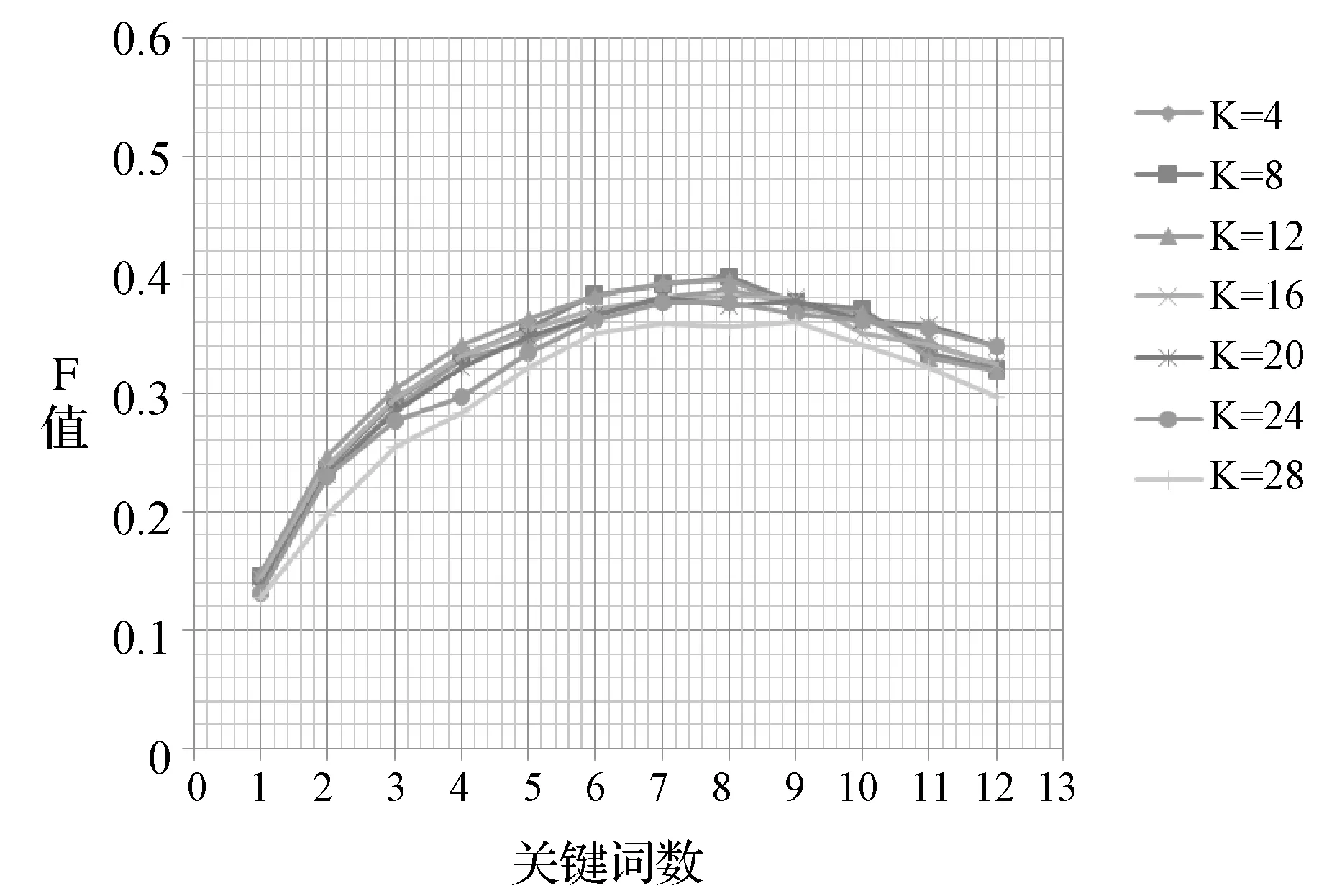
图6 不同滑动窗口长度在ABSTRACTS语料上的F1测度

图7 不同滑动窗口长度在NEWS语料上的准确率
实验3:关键词抽取效果的对比实验。TextRank能够有效利用文档的结构信息,在传统文本关键词抽取上取得较好的效果。基于主题模型的方法能够获得单词和文档的主题分布,通过计算主题相似度亦能有效提取出关键短语;Adrien等[19]提出了一种基于图形的关键短语提取方法,它依赖于文档的主题表示。将本文方法(LAT)与基于LDA的方法、基于TextRank方法和Adrien所提方法的抽取结果进行对比。其中滑动窗口长度取K=12,单篇抽取关键词数为10,阻尼系数取μ=0.85,不同抽取方法的部分抽取结果如表2所示。由表可以看出,在单文本任务上,仅使用基于TextRank或基于LDA的方法性能较低,这是因为文本能够提供的信息量较少,并且容易掺杂干扰性词语;本文LAT方法与Adrien所提方法弥补了其他两种基本方法的缺陷,在召回率和准确率上都有很大提升,对比发现本文LAT方法要高于Adrien等所提方法,在NEWS语料集上的效果尤为明显。
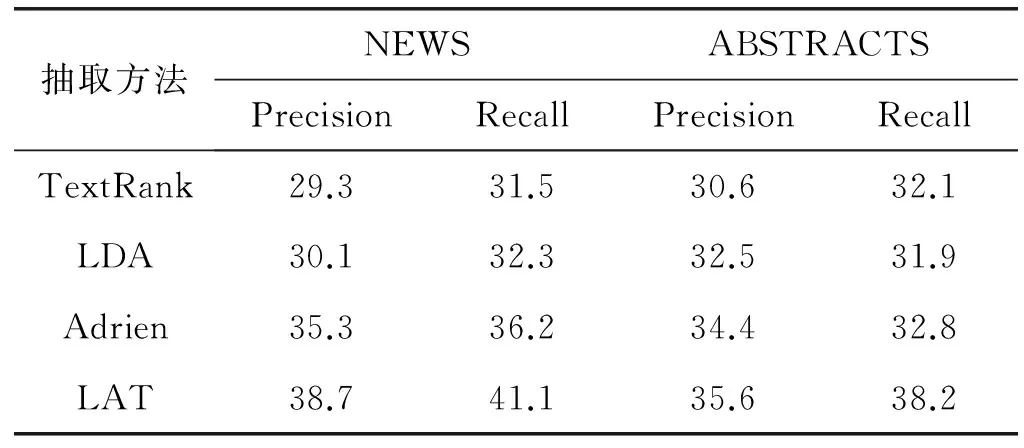
表2 不同抽取方法性能对比 %
实验4:生成的关键短语主题相关性的对比实验。本部分将生成的关键短语与人工抽取结果对比,主要评测由关键词合成的短语能否涵盖文本主要话题,实验结果如表3、表4所示。生成的关键短语能够覆盖文本主要的话题,并能够表示特定的语义信息。此外,该方法在处理事件性语料上有较好效果,能够抽取出包含事件信息或用户意图的短语,而对于摘要类文本则只能提取概念性短语或词语。

表3 关键短语抽取结果 %

表4 部分关键短语抽取结果示例
4 结 语
本文综合考虑了文档的主题信息和结构信息,提出了一种基于LDA和TextRank的单文本关键短语抽取方法。将其运用到关键词抽取中,实验结果表明,该方法能够抽取文本主题覆盖度较高的关键词,由关键词生成的关键短语具有较强的表意性。但该方法仍具有很大的改进空间,如利用文章标题、关键短语语义或将该方法运用到短文本中,进一步提升关键短语抽取的准确率。
[1] Tomokiyo T, Hurst M. A language model approach to keyphrase extraction[C]//ACL 2003 Workshop on Multiword Expressions: Analysis, Acquisition and Treatment. Association for Computational Linguistics, 2003:33-40.
[2] Turney P D. Learning Algorithms for Keyphrase Extraction[J]. Information Retrieval Journal, 2000,2(4):303-336.
[3] 顾益军. 融合LDA与TextRank的关键词抽取研究[J]. 现代图书情报技术, 2014, 30(z1):41-47.
[4] 方康, 韩立新. 基于HMM的加权Textrank单文档的关键词抽取算法[J]. 信息技术, 2015(4):114-116.
[5] Rezaei M, Gali N, Fränti P. ClRank: A Method for Keyword Extraction from Web pages using clustering and distribution of nouns[C]//Web Intelligence and Intelligent Agent Technology (WI-IAT), 2015 IEEE/WIC/ACM International Conference on. IEEE, 2015, 1:79-84.
[6] 李跃鹏, 金翠, 及俊川. 基于word2vec的关键词提取算法[J].科研信息化技术与应用, 2015(4):54-59.
[7] Shang Y, Hao H, Wu J, et al. Learning to rank-based gene summary extraction[J].Bmc Bioinformatics,2014,15(suppl 12):618.
[8] Hamid F, Tarau P. Anti-Summaries: Enhancing Graph-Based Techniques for Summary Extraction with Sentiment Polarity[M]//Computational Linguistics and Intelligent Text Processing. Springer International Publishing, 2015.
[9] 林莉媛, 王中卿, 李寿山,等. 基于PageRank的中文多文档文本情感摘要[J].中文信息学报, 2014, 28(2):85-90.
[10] Balcerzak B, Jaworski W, Wierzbicki A. Application of TextRank algorithm for credibility assessment[C]//Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT)-Volume 01. IEEE Computer Society, 2014:451-454.
[11] Blei D M, Lafferty J D. Visualizing Topics with Multi-Word Expressions[J]. eprint arXiv:0907.1013, 2009.
[12] 闫泽华. 基于LDA的新闻线索抽取研究[D]. 上海交通大学, 2012.
[13] 寇宛秋, 李芳. 基于种子词汇的话题标签抽取研究[J]. 中文信息学报, 2013, 27(5):114-121.
[14] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(3):993-1022.
[15] Mihalcea R, Tarau P. TextRank: Bringing Order into Texts[C]//Proceedings of EMNLP, 2004,85:404-411.
[16] Page L. The PageRank citation ranking: Bringing order to the web[J]. Stanford Digital Libraries Working Paper, 1998,9(1):1-14.
[17] Lau J H, Newman D, Karimi S, et al. Best topic word selection for topic labelling[C]//COLING 2010, International Conference on Computational Linguistics, Posters Volume, 23-27 August 2010, Beijing, China,2010:605-613.
[18] Song Y, Pan S, Liu S, et al. Topic and keyword re-ranking for LDA-based topic modeling[C]//ACM Conference on Information and Knowledge Management, CIKM 2009, Hong Kong, China, November,2009:1757-1760.
[19] Bougouin A, Boudin F, Daille B. TopicRank: Graph-Based Topic Ranking for Keyphrase Extraction[C]//International Joint Conference on Natural Language Processing,2013:543-551.
