新建住宅虚拟重复交易数据的生成方法
2018-03-21金升平
刘 宇,苏 攀,金升平
(武汉理工大学 理学院,武汉 430070)
0 引言
房地产的最大特点就是异质性。科学的房价指数编制模型,必须考察同质房产的价格变化,剥离品质变化对销售成交价格的影响。国外房价指数的编制方法在经历以中位数和简单加权平均为代表的第一代方法、以样本匹配法和拉氏加权为代表的第二代方法之后,建立在现代数理统计分析基础上的第三代房价指数编制方法为同质性房价指数,其主要模型与方法有两个:一个是特征价格法,直接把房子价格和一系列主要品质联系起来。另一个是重复交易法,考察同一栋房子不同时期的成交价格变动[1,2]。
近年来,我国房地产价格明显上涨,相关房价统计数据却与大众普遍的感知存在较大偏离,这暴露出房地产价格指数编制在反映房地产市场价格水平变化程度方面的缺陷。目前我国新建住宅房价格指数大多采用简单的平均法、中位数法或加权平均法,只相当于国外的第一代和第二代方法,无法满足同质可比的要求,在准确性等方面存在明显不足。这就需要结合我国新建商品住宅的特点,运用国外的先进方法进行房价指数的编制方法研究。
房价指数的特征价格法,在理论上和学术界相对占有优势,但在实际应用上有一定的困难,因为较为全面地收集每套住宅的特征数据的准确性难以保证,且代价很大。因此特征价格法不能很好地适用于我国新建住宅的房价指数的编制。长期以来,学术界认为,我国新建商品房只有一次交易,新建住宅的房价指数的编制不能应用重复交易法。但中国房地产有其特点,除少量原有的独立自建房和别墅外,新建住宅都是楼宇结构且一个小区一个楼盘的成片开发。出于楼宇稳定性需要,楼宇除顶层之外其他楼层的户型配比是一样的,各种户型在朝向位置上是一致的,楼上楼下同样位置对应的户型都是相同的[3]。从直观上讲,我国新建商品化住房结构较为单一或者说较“同质”。
国内有少数文献对这一特点进行了研究[3-8],本文将在先倚懿等[5]和Jin W H等[6]提出的基于上下楼集合的虚拟重复交易的基础上,利用上下楼的关系和很多不同上下楼集合对应楼层价格基本相同的现象,研究不同上下楼集合可匹配的方法,以及两种方法产生虚拟交易数据的融合问题。
1 虚拟交易数据产生方法模型
1.1 基于同一上下集合的虚拟数据产生方法
约定同一楼栋、同一单元、同一朝向的所有房屋为一个“上下楼集合”,一个单元一般由两个上下楼集合构成,也有部分单元由三个或更多个上下楼集合构成。在同一年同一个月内同一上下楼集合售出了两层,记为l1,l2( )l1<l2,单价分别为p1,p2,记该月为t。而且从已有销售记录来看,这个朝向的所有楼层的总面积都相等。如果另外一个月此上下楼集合的房产售出了位于第l层,l层与l1和l2满足一定的邻近条件时,可以通过插值的方法计算出在第t月位于第l层房产的虚拟单价。
作为推广,设同一上下楼集合房产在同一年同一个月内售出了k层,记为l1<l2<…<lk,单价分别为p1,p2,…,pk,记该月为t。如果另外一个月上下楼集合房产售出了位于第l层。楼栋为高层或小高层,如总楼(记为ltotal)必须至少为12层。l1≥3,lk<ltotal。当l层与所售出的k层中的两层满足一定的邻近条件时,可用插值的方法计算出在第t月位于第l层房产的虚拟单价。用方法生成的虚拟交易数据称为基于楼层的虚拟交易数据。
1.2 基于上下楼集合的虚拟数据产生方法
1.2.1 规则1基于同一楼栋不同上下楼集合的匹配规则设A和B为同一楼栋的不同上下楼集合,其总高度都为n,房产从第1层到第n层分别为A1,A2,…,An和B1,B2,…,Bn,设楼层集合,在同一年同一个月售出了方位A和B的第lk层,但不同楼层销售的年月可以不同(k=1,2,…,s)。Al1,Al2,…,Als和Bl1,Bl2,…,Bls的销售单价分别为pl1,pl2,…,pls和ql1,
如果满足以下3个条件:
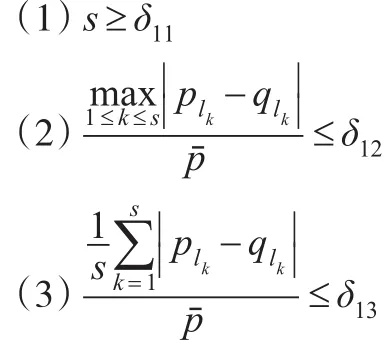
则称两个上下楼集合A和B是匹配的。其中δ11,δ12,δ13的设置视具体情况而定,例如δ11=4,δ12=0.04,δ13=0.02。
如果两个上下楼集合A和B是可匹配的,则上下楼集合A的第i层房产Ai在某年某月的售价为pi,但Bi在该年该月没有销售记录,则Bi在Ai对应的年和对应月的虚拟售价为pi。同理,如果Bi在某年某月的售价为pi,但Ai在这个对应的年和月没有交易,则Ai在这个对应的年月的虚拟售价为pi。
1.2.2 规则2基于同一楼栋不同上下楼集合的匹配规则的改进
规则1中要求检查匹配时,相同楼层都是同年同月销售的。但有时相同楼层是相邻月份销售的,但相隔的时间不长。设A和B为同一楼栋的不同上下楼集合,其总高度都为n,房产从第1层到第n层分别为A1,A2,…,An和B1,B2,…,Bn,设楼层集合,在同一年同一个月或相邻的月售出了上下楼集合A和B的第lk层,但不同楼层销售的年月可以不同如果上下楼集合A和B的第li层为同一年或相邻的月售出的,要求它们销售日期相差的天数小于31天。设Al1,Al2,…,Als和Bl1,Bl2,…,Bls的销售单价分别为pl1,pl2,…,pls和ql1,ql2,…,qls,Alk和Blk销售日期相差的天数记为dk,k=1,…,s,再记
如果满足以下3个条件:

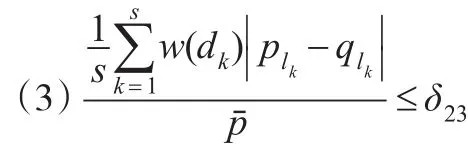
其中w(dk)为房价关于天数的权系数,可取w(d)=1-d/300,(0≤d≤30)。则称两个上下楼集合A和B是匹配的。其中δ21,δ22,δ23的设置视具体情况而定,例如δ21=4,δ22=0.04,δ23=0.02 。
与规则2一样,如果两个上下楼集合A和B是可匹配的,则上下楼集合A的第i层房产Ai在某年某月的售价为pi,但Bi在该年该月没有销售记录,则Bi在Ai对应的年和对应月的虚拟售价为pi。同理,如果Bi在某年某月的售价为pi,但Ai在这个对应的年和月没有交易,则Ai在这个对应的年月的虚拟售价为pi。
1.2.3 规则3基于不同楼栋的两个上下楼集合的匹配规则
设两个上下楼集合位于不同的楼栋,但这两个楼栋属于同一小区的同期楼盘,其总高度(总楼层)相同,也可仿照规则1或规则2,类似给出两个方位是可匹配的定义。但对于相应参数的设置应相对苛刻一些。
1.3 两种虚拟交易数据的融合及虚拟数据的处理
对于高层或小高层,可分别利用基于同一上下楼集合的虚拟交易数据模型(记为模型1)和基于不同上下楼集合的虚拟交易数据模型(记为模型2)生成虚拟交易数据,所以就存在两个虚拟交易数据的融合问题。具体方法如下:可将模型1产生的虚拟数据再基于模型2产生虚拟数据,反过来亦可。如果一套房产存在相同时间产生了多条虚拟交易数据记录,则将这几条记录合并成一条的虚拟交易数据。合并时交易价格可采用简单平均或加权平均,其不同数据类型的权系数进行具体数据测算后确定。
2 虚拟重复交易数据产生方法的对比分析
2.1 虚拟交易数据示例
下面以湖北省襄阳市2012年1月至12月的83个楼盘的房地产的商业银行按揭房贷数据为例,比较本文方法与前期的方法所产生数据质量问题。数据来源于中国人民银行武汉分行,每套房产数据其中包括项目名称、所在小区、楼栋、单元、楼层、房号,房产总价、房产面积、房产购买时间、房产交易单位价格、房产所在区域编号等信息。数据几乎包括了襄阳市的所有楼盘,并且信息全面,能够反映出襄阳市的房价指数变化情况。
在剔除内容不完整的信息后,获得6354条有效样本。首先根据基于同一上下楼集合的匹配规则产生虚拟数据1,产生虚拟交易数据4475条,与原始数据匹配共得到986条虚拟重复交易的数据。然后根据基于不同上下楼集合的匹配规则生成虚拟数据2,产生虚拟交易数据576条,与原始数据相匹配共得到285条虚拟重复交易的数据。对前两种规则产生的数据进行融合,得到3862条虚拟交易数据,把原始数据与虚拟数据进行匹配找出同一房屋在不同时间虚拟重复售出两次的交易对共有1178条。在考虑基于不同上下楼集合的匹配之后,多产生了384条重复交易数据。产生的数据形式如表1所示,这里只列举小部分楼盘的部分变量的数据。
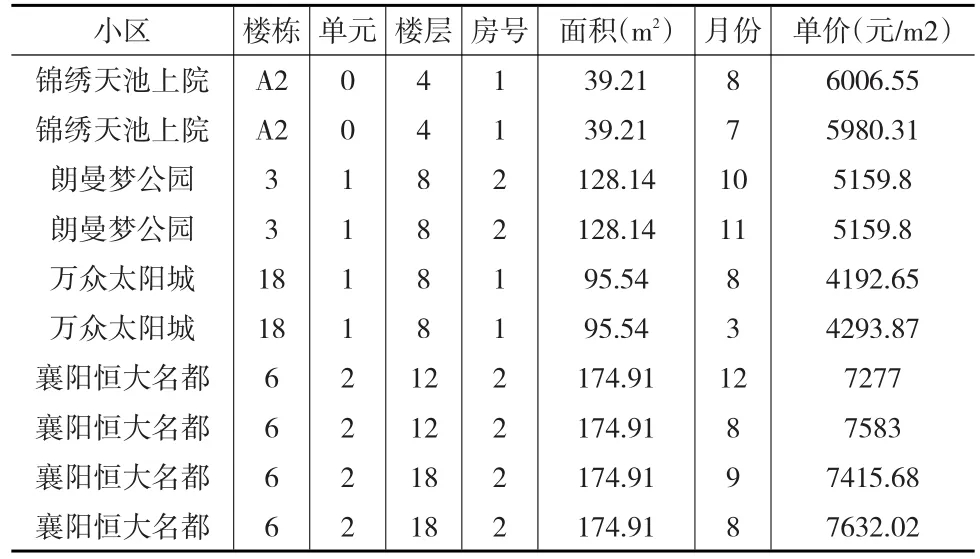
表1 虚拟重复交易数据
2.2 模型选择
重复售出模型[2]的具体形式为:

其中Pi,t是第i套房产在时期t的交易价格。t是第1次交易时期而t'是第2次交易时期,满足t'>t。It是房产在时期t的价格指数,Uitt'是交易误差,满足,这里iid表示独立同分布。式(1)取对数得:

其中pi,t=logPi,t,βt=logIt,uitt'=logUitt'
类似于重复交易模型,Case和Shiller[7]假定式(2)有另外的误差结构:

这里t'>t,Hi,t是一个Guassian随机游走(random walk)过程,所以
Case和Shiller的三阶段广义最小二乘法(3GLS)如下:
(1)对式(2)运用OLS进行拟合。得出的结果为重复交易指数。记一对重复交易的残差为εitt'。
(2)对以下关于α0,α1回归问题运用OLS进行拟合:

其拟合值记为',组成矩阵
对式(2)运用加权最小二乘法进行拟合,其加权矩阵为W-1。可以看到,加权后,对数交易误差为常数,不在存在异方差,因此,对于参数估计量,可以得到最优的估计量。因此本文可以运用加权重复交易法估计房地产价格指数:
Case&Shiller的三阶段广义最小二乘法被称为加权重复交易模型,对重复交易模型误差项的异方差问题进行处理,得到的估计量更优,被广泛应用在住房金融研究中。本文选用Case&Shiller模型对两种方法产生的虚拟重复交易数据进行对比研究。
2.3 结果对比分析
把基于同一上下楼集合的虚拟重复交易数据方法记为方法1,把本文提出的虚拟重复交易数据产生方法记为方法2。运用Case&Shiller模型计算出两种产生虚拟重复交易数据的方法所得到的各月份的房价指数如表2所示。

表2 方法1和方法2所得各个月份的房价指数 (单位:%)
由表2可以看出,两种方法所得的房价指数的变化趋势大致相同,相同月份的房价指数相差不是很大,误差的最大值为0.18。方法2所产生的虚拟重复交易数据与方法1产生的虚拟重复交易数据质量相当,方法2产生的数据样本量较大。两种方法编制的房价指数如图1所示。

图1 房价指数变化图
由图1可知,指数1代表是基于方法1所得的房价指数变化曲线,指数2是基于方法2产生的房价指数变化曲线。总体来看,房价指数在不断增大与我国房价不断上涨的趋势相吻合。两条曲线的波动情况大体一致,但基于后者所得到的房价指数稍高于基于前者所产生的房价指数,波动性更大一点,这比较符合我国房价的变化情况。

图2 Case&Shiller模型计算房价指数的残差图
图2给出Case&Shiller模型计算房价指数的残差图,可以看出除个别异常点之外大部分残差都在[-2,2]之间围绕0上下波动,说明模型的拟合效果较好。可以在某些程度上认为,本文选择的虚拟重复交易模型符合我国新建住宅的市场情况,在一定程度上反映房价指数的变化。
3 结论
在房地产价格指数编制模型的构造过程中,数据的质量和数据的容量是编制房地产价格指数的关键性因素。如何获得足够的数据和可行性高的数据,是编制房价指数时必须解决的重要理论问题。本文分别基于同一上下楼集合和不同上下楼集合的虚拟交易数据产生方法来产生虚拟交易数据,并考虑到对两种数据的融合,增大了样本容量,提高了数据的质量。将虚拟交易数据与原样本进行配对,得到虚拟重复交易数据,满足重复交易法的数据形式,可行性高。通过运用优化的重复交易模型Case&Shiller模型对房价指数的计算以及对残差的分析,可以认为利用虚拟重复交易数据,可以更为科学地编制我国新建住宅房价指数,更为准确地反映我国房价市场的价格变化趋势,本文的方法达到了国际上第3代房价指数方法的标准。
[1]杨楠.房价指数的编制、管理与应用[M].上海:上海财经大学出版社,2010.
[2]Bailey M J,Muth R F,Nourse H O.A Regression Method for Real Estate Price Index Construction[J].Journal of the American Statistical Association,1963,58(304).
[3]许永洪.住房体格指数编制理论与应用研究[M].北京:中国社会科学出版社,2013.
[4]Guo X Y,Zheng S Q,Geltner D,et al.A New Approach for Constructing Home Price Indices:The Pseudo Repeat Sales Model and Its Application in China[J].Journal of Housing Economics,2014,(25).
[5]先倚懿,金升平.混合效应模型在新建住宅房价指数中的应用研究[J].统计与决策,2016,(15).
[6]Jin W H,Jin S P.The Virtual Repeat Sale Model for the House Price Index for New Building in China[J].Applied Mathematics,2014,5(22).
[7]Case K E,Shiller R J.The Efficiency of the Market for Single-Family Homes[J].American Economic Review,1989,79(1).
[8]金升平,曾恂,李琼.中国新建普通商品房价格指数编制方法研究[J].武汉金融,2017,(6).
