基于点击流的用户矩阵模型相似度个性化推荐
2018-01-18,,
,,
(湖南大学 a.信息科学与工程学院;b.可信系统与网络实验室,长沙410082)
0 概述
为了能够让用户在智慧校园[1]学习平台取得更高的学习效率,智慧校园平台学习资源按照学部、年级和科目分类,便于学生检索,提高学习效率。据统计,平均每天有上十万的用户登录智慧校园学习平台进行学习,每天能够产生上百万条学习资源类别的点击流[2]数据。如何分析用户的海量点击流数据挖掘用户感兴趣的学习资源,对用户进行个性化推荐[3]是一个极具挑战性的工作。
用户对学习资源评价和学习资源搜索记录主观的网络行为,能够反映用户对学习资源的兴趣,所以大部分学习网站分析学习资源评价内容和学习资源搜索记录,挖掘用户的兴趣,从而给用户进行资源推荐[4]。虽然这种基于内容的推荐具有直接而准确的优点,但是推荐之前需要进行大量的内容分析工作,涉及到网页特征的抽取以及所使用的语言的语法、语意、词法的分析等[5]。这种推荐算法不仅工作量巨大,而且当用户访问历史时间较短时,对该用户的访问内容分析也难以得到正确的结果,因此基于内容推荐算法具有一定的局限性。
研究学者发现用户在浏览网页资源过程中所产生的点击流信息可以从侧面反映出用户的兴趣,该研究结果在智慧校园学习资源网站同样适用。用户浏览学习资源会产生资源类别的点击频率、点击路径以及在某一资源类别下的停留时间等点击流数据[6],但是由于视频学习资源的时间长短不一,因此页面停留时间不能有效衡量用户对该类学习资源的兴趣。同时用户在学习的过程中对学习资源的喜好程度也会跟随时间产生变化,所以,引入时间遗忘因子[7]评估用户对学习资源的兴趣程度很有必要。本文针对智慧校园APP学习资源网站特定的网络环境,为用户个性化推荐学习资源做了大量的实验与研究。
1 相关工作
1.1 点击流数据相关研究
近年来国内外学者关于用户网页点击流信息挖掘用户兴趣,求解相似用户,为用户进行个性化资源推荐已经具有了一定的研究成果。用户点击流信息的研究涉及到学习资源网站、电商网站、旅游网站等领域,文献[8]挖掘用户网页点击流记录构建了用户在线购物模型,预测用户网页购买行为;文献[9]研究了大型商务网站用户点击流信息挖掘用户兴趣为用户进行商品个性化推荐,深入分析了用户网页商品类目的点击频率、点击路径和网页页面停留时间3种用户点击流信息构建用户推荐模型,取得了一定的效果,但是这篇文章中求解用户相似度算法时间复杂度太高且推荐效率不是很理想。
1.2 聚类算法分析
用户聚类是用户个性化推荐的第一步,目前相当成熟的用户聚类算法有多种。K-means算法[10]是最常用的聚类算法之一,其算法时间复杂度较低,但是对样本的输入顺序敏感,可能产生局部最优解,而且受孤立点的影响很大。 K-medoids算法[11]是另一种常用的聚类算法,该算法虽然能在一定程度上控制异常数据的影响,但是其时间复杂度较高,在海量用户点击流数据的情况下求解相似用户,效率低下。基于这些问题,研究学者提出了一种领导聚类(Leader Clustering)算法,这种算法不需要预先指定分类对象的簇中心点,而是在簇中随机指定一个对象作为leader,然后计算数据集中所有对象与leader的距离,若距离值小于阈值,则将该对象指派给该leader,否则该对象作为一个新的leader。这样只需要遍历一次数据集就可以对所有对象进行分类,时间复杂度较低。但是对于具有大量对象的数据集,一个对象有可能归于多个类,因此,研究学者又提出了粗糙集理论[12]来解决这个问题。粗糙集理论中每一个簇有一个上近似集和一个下近似集,所以,当某一个对象不确定归属于哪一个簇的时候,可以采用上近似集和下近似集的概念将该对象指派为至少一个确定的簇。
基于上述考虑,本文提出了JMATRIX算法,将智慧校园用户历史资源点击流数据,构建用户资源类别点击数据有向图模型,并将资源类别有向图模型转化为矩阵模型存储,然后设计用户相似度求解公式,克服稀疏矩阵冷启动问题[13],求解矩阵模型相似度从而求得用户相似度,最后JMATRIX算法结合Leader Clustering算法及粗糙集理论思想,为用户进行个性化资源推荐。实验结果表明,JMATRIX算法极大的提高了用户的聚类效率和用户相似度准确性,证实了JMATRIX算法相比其他推荐算法在用户个性化学习资源推荐领域具有较高的效率和准确性。
2 基于JMATRIX算法用户相似度求解
JMATRIX算法用户相似度求解思想如下,先根据智慧校园APP学习网站结构创建用户资源点击数据有向图模型,并且引入遗忘因子对用户资源点击数据有向图模型进行遗忘,及时更新有向图模型每一条有向边的权值。根据最终的用户资源点击数据有向图模型构建用户资源点击数据矩阵模型,然后通过JMATRIX算法用户相似度求解公式求得用户资源点击数据矩阵模型的相似度,从而求得用户的各兴趣指标相似度。
2.1 学习资源网站结构
智慧校园APP学习网站具有丰富的学习资源,其树型结构如图1所示。其中第一级父节点为资源类型(如优课),每一个父节点下面又可以分为多个一级子节点(如年级),每一个一级子节点下面分为多个二级子节点(如科目),且一级子节点为二级子节点的父节点,依次类推,每一个二级子节点下面分为多个三级子节点(如教材版本)。

图1 智慧校园APP学习网站结构
2.2 用户兴趣指标
本文引入时间遗忘因子,根据时间赋予资源类别点击频率和资源类别点击路径2个指标不同的权值,计算用户的相似度。常用的用户资源类别点击频率相似度求解算法复杂度较高,通过计算用户每一次会话访问每一个资源类别及资源类别下资源点击数,与本次会话中所有资源点击总数求商,得到每一个资源类别的点击频率。然后取某段时间内资源类别点击频率平均值,构造资源类别的点击频率用户矩阵,通过求解资源类别频率用户矩阵中用户资源类别点击频率向量相似度,求得用户资源类别点击频率相似度。常用的资源类别访问路径的相似度求解,通过求解一段时间内用户之间每一条资源访问路径交集与资源路径的并集求商,得到用户之间每一条资源访问路径的相似度,取平均值来求得用户的资源访问路径的相似度,该求解方式不仅时间复杂度高,而且会丢失精度[14]。为了克服以上问题,本文基于用户历史资源类别点击流信息,构建了用户资源类别点击数据有向图模型,并将资源类别有向图模型转化为矩阵模型存储,设计独特的矩阵模型相似度求解公式求解用户矩阵模型相似度,不仅可以一次求得用户的资源类别点击频率和资源类别点击路径的相似度,极大地简化了用户相似度的求解过程,而且克服了稀疏矩阵的冷启动问题,提高算法的通用性和准确性,取得了非常理想的用户相似度结果。
2.3 用户相似度求解
本文用户相似度求解方式如下,如例用户P一次会话的资源类别访问路径:A-B-D-E-B-D(其中,A、B、C、D、E代表不同的资源类别),那么该条资源类别点击数据在有向图中的存储如图2所示,资源类别之间每一条有向边代表用户点击资源类别的跳转路径,每一条有向边的权值代表用户资源类别之间的跳转次数,可以根据资源类别之间跳转次数与跳转总次数求商,得到资源类别之间的跳转频率。因此资源有向图同时存储了用户资源类别点击频率和资源类别访问路径的点击流信息。

图2 用户P某条资源类别点击数据有向图模型
资源类别点击频率和资源类别访问路径是根据用户资源点击记录,获取资源所属的类别点击信息而得到的,如果学习资源同时属于多个资源类别,那么进行该资源点击信息归属的类别需要做如下处理,例如资源访问路径:resource1(二年级|语文|湘教版)-resource2(二年级|数学|湘教版)-resource3(三年级|英语),则权值二年级-三年级=1/3×1/3=1/9。同理,二年级-数学、二年级-湘教版、语文-二年级、语文-数学、语文-湘教版、湘教版-二年级、湘教版-数学、湘教版-湘教版权值均为1/9。二年级-三年级=1/3×1/2=1/6,同理得到二年级-英语、数学-三年级、数学-英语、湘教版-三年级、湘教版-英语权值均为6/1。
人类的自然遗忘是一个渐进的过程,因此,可以推断用户对某一事物的兴趣也遵循这一规律,即用户的兴趣也随着时间的推移而减弱,而且兴趣遗忘的速度也是按照时间顺序先快后慢。用户最近多次访问的学习资源最能代表用户最近的兴趣,通过引入遗忘因子对用户的兴趣逐渐遗忘,给用户每一条资源类别的访问信息赋予修正权值,得到合理的用户点击记录模型。
遗忘因子K计算公式如下:
(1)
其中,cur表示当前日期,time表示用户浏览资源类别的日期,h表示兴趣遗忘半衰期,即经过h天后用户的兴趣非线性遗忘了一半,它遗忘的速度先快后慢。h的值可以根据实验结果反复调试,也可以依据理论知识人为设定,遗忘速度的快慢由h直接控制。根据艾滨浩斯曲线[15]遗忘规律2 d的时间可以让人类对事物的遗忘达到72%,综合用户对学习资源兴趣的遗忘场景考虑,本文半衰期h定义为2天。
得到时间遗忘因子K值之后,将用户某段时间内对资源类别的每条访问路径均赋予一个遗忘因子K值。如用户P一次会话的资源类别访问路径:A-B-D,将本条路径赋予遗忘因子K值,则可以得到本次资源类别访问路径为K(A-B-D)。若代入相关参数求得K=0.5,则资源类别A跳转至资源类别B,资源类别B跳转资源类别D,由原来的1次变为0.5次,所以,最终本条路径在资源类别点击数据有向图中的有向边权值为0.5。
基于以上原理,将一段时间内用户对学习资源类别点击频率、访问路径的点击流信息转化为有向图模型存储,如图3所示。

图3 用户某段时间资源类别点击数据有向图模型
然后建立学习资源类别矩阵模型,将用户学习资源类别点击流信息存储图转化为学习资源类别矩阵模型存储,如下:
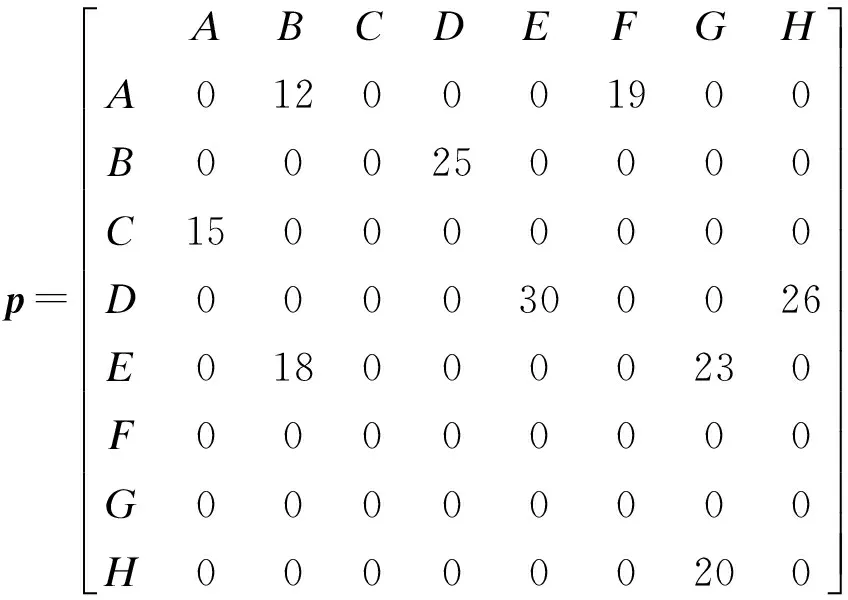
因此,可以求解用户之间学习资源类别矩阵相似度从而求得2个用户之间的相似度,矩阵相似度求解公式如下:
(2)
其中,pi代表p矩阵第i行向量,qi代表q矩阵第i行向量,Spi代表p矩阵第i行点击总数,Sqi代表q矩阵第i行点击总数,Sp代表p矩阵总点击总数,Sq代表q矩阵总点击总数。依次求解2个用户点击流数据矩阵每一行向量用户相似度,选取2个矩阵中所对应的每一行点击数据频率的最小值作为该行的权值,然后与每一行向量用户相似度求积,再将所得行向量的相似度求和,得到2个用户之间的相似度。选取每一行点击数据频率最小值作为该行的权值可以克服稀疏矩阵引起计算误差,当某一行向量全部为0或者2个矩阵对应的2个行向量为零时,零向量将会忽略,所以,该由零向量引起的稀疏矩阵冷启动问题也会得到解决。
对于(n×m)的资源类别点击数据矩阵模型用户p,q相似度求解具体的计算公式如下:
(3)
3 实验分析与验结果
3.1 基于JMATRIX算法个性化推荐流程
JMATRIX算法结合Leader Clustering算法和粗糙集理论进行用户个性化推荐,不仅能够对大量的用户进行快速有效聚类,还能够针对一个用户同时属于多个分类的问题,引用粗糙集理论进行有效聚类处理。JMATRIX算法在簇中随机指定一个对象作为leader,然后根据JMATRIX算法用户相似度计算方法,计算数据集中所有对象与领导集中leader的用户相似度,若用户相似度小于所设定的用户相似度与阈值α,该对象作为一个新的领导返回到领导集中,否则判断用户相似度与该用户和领导集中所有leader的最大用户相似度之商,是否大于或等于粗糙集阈值β,如果满足条件那么将该对象指派给这个leader。因此,引用粗糙集理论可以有效解决一个对象满足条件有可能归于多个聚类的问题。JMATRIX算法流程如图4所示。

图4 JMATRIX算法流程
3.2 实验数据集
通过智慧校园用户学习资源点击记录的日志数据,提取日志数据进行预处理,对用户访问极少的学习资源类别和访问数据极少的用户进行过滤处理,提高数据集质量。用户智慧校园学习资源类别点击流数据集如表1所示。

表1 实验数据集
3.3 JMATRIX算法参数优化
JMATRIX算法具有用户相似度阈值和粗糙集阈值2个阈值,2个阈值的大小会影响到聚类结果。用户与leader之间的相似度超过了用户相似度阈值,则说明该用户可能归属于该leader,而粗糙集阈值则决定了某一个用户是否能够同时归属于多个leader。如果用户相似度阈值设置过低,那么无关的用户会指派给leader产生误差,用户相似度阈值设置过高,那么用户会因为过高的用户相似度阈值而难以归属于某一个聚类,从而形成较多的聚类。如果粗糙集阈值设置过低,将会产生不合理的聚类重叠,如果粗糙集阈值设置过高,将会难以使得相似度高的用户归为一个聚类,从而形成过多的冗余聚类。因此,需要根据实验结果调整参数进行反复实验。
去掉粗糙集阈值的限制条件,根据用户相似度阈值参数调整进行反复实验,实验结果如图5所示,用户相似度阈值从0.1增至0.2,用户聚类数没有太大的变化,因为用户相似度阈值过低,会使得一个用户聚类包含众多与聚类领导相差甚远的对象。用户相似度阈值从0.2增至0.35,用户聚类数会随着用户相似度阈值的增大而增加,当用户相似度阈值达到0.4之后,用户聚类数随着用户相似阈值的增加而急速增加,且形成了过多的不具有代表性的用户聚类。综合考虑8 040个用户和45个资源分类,用户相似度阈值取0.3,将用户分为24个聚类。本领域其他研究成果显示,用户相似度阈值设置在0.2~0.3较为合适。
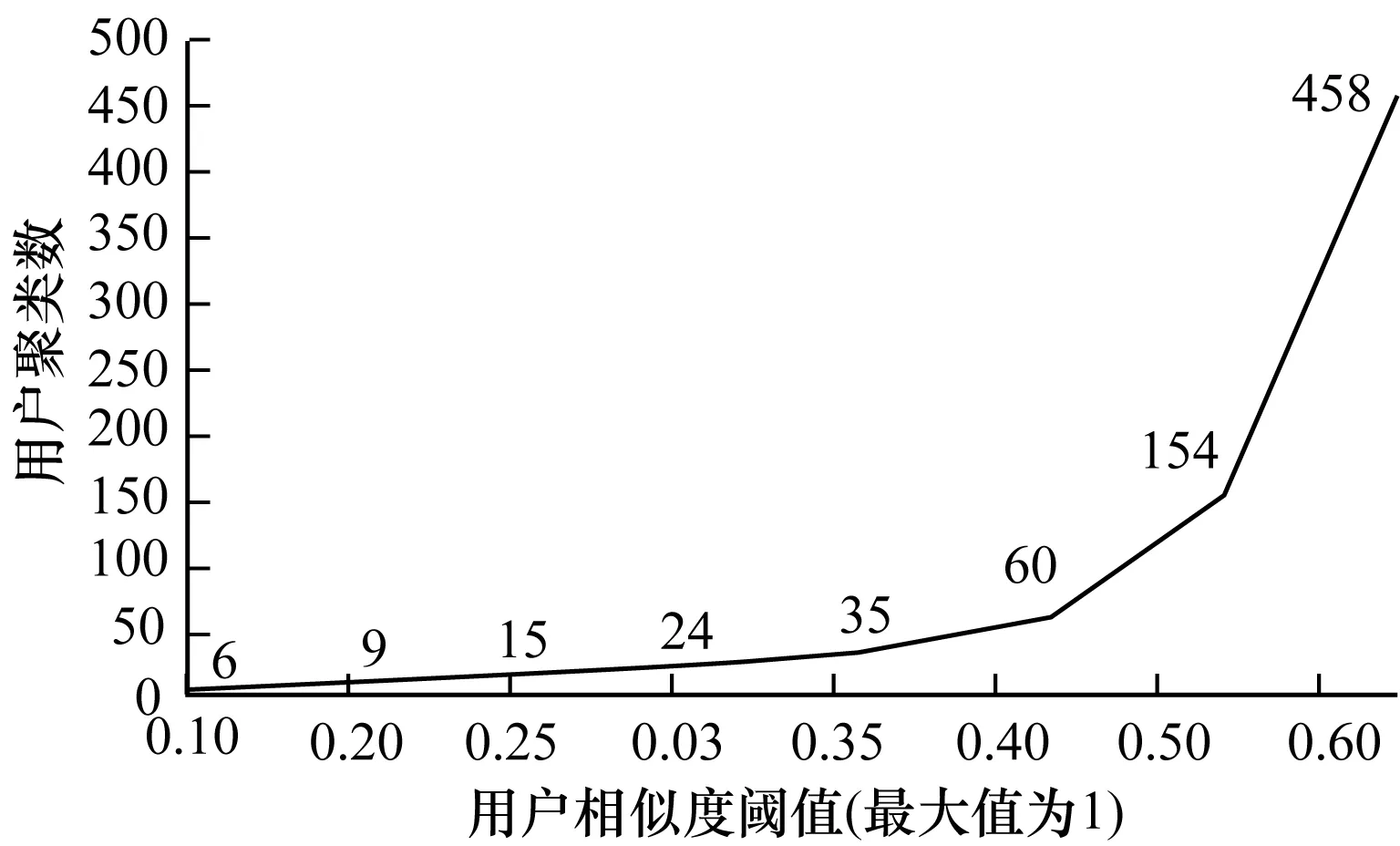
图5 用户聚类数随用户相似度阈值变化曲线
为了确定合适的粗糙集阈值,根据所取的用户相似度阈值0.3,不断调整用户粗糙集阈值的大小,得到聚类平均用户数结果如图6所示。去掉粗糙集限制条件,用户相似度阈值取0.3,则聚类平均用户数为335个。由实验结果图可以看出,粗糙集阈值由0.7下降到0.4时,聚类中会产生过多的重复用户,且粗糙集阈值越小,重复用户数越多,当粗糙集阈值由0.85增至0.9时,平均用户数缓慢下降,且当粗糙集阈值达到0.9时,平均用户数接近335个,聚类中几乎不会产生重复用户。所以,综合分析得到粗糙集阈值取0.7~0.85较为合适。而且当用户相似度阈值取0.3,调整粗糙集阈值的大小,得到JMATRIX算法的准确率与召回率,实验结果如图7所示。粗糙集阈值从0.4增至0.6,准确率有小幅的提升,当粗糙集阈值从0.6增至0.8,准确率有大幅度提升且在粗糙集阈值为0.8时准确率达到最大值,当粗糙集阈值大于0.8,准确率会随之降低。召回率在粗糙集阈值处于0.4至0.9之间小幅波动,并无太大变化。综合分析得到,用户相似度阈值取0.3,粗糙集阈值取值0.8最优。

图6 聚类平均用户数随粗糙集阈值变化曲线
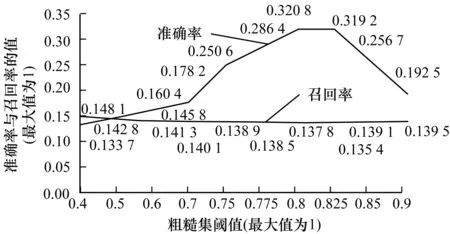
图7 准确率、召回率随粗糙集阈值变化曲线
3.4 结果分析
根据上面的结果分析,将用户相似度阈值取值0.3,粗糙集阈值取值0.8,基于相同的实验数据集,针对JMATRIX算法、Rough Leader Clustering算法和K-medoids算法3种推荐算法进行实验,所得算法用户聚类数、运行时间结果如图8所示,所得算法准确率、召回率如图9所示,实验结果显示,JMATRIX算法在运行效率上相比Rough Leader Clustering算法和K-medoids算法分别提高了15%和29.17%,JMATRIX算法在推荐的准确率上相比Rough Leader Clustering算法和K-medoids算法分别提高了15.35%和24.2%,JMATRIX算法在推荐召回率上相比Rough Leader Clustering算法和K-medoids算法分别提高了16.48%和26.89%。由此可以得到,本文提出的JMATRIX算法在运行时间、准确率和召回率等指标上相比Rough Leader Clustering算法和K-medoids算法更优,因此验证了JMATRIX算法基于用户点击流数据在用户个性化推荐上具有更高的效率和更精确的推荐效果。

图8 3种算法运行时间、用户聚类数结果

图9 4种算法准确率、召回率结果
4 结束语
本文基于智慧校园APP用户不同类别的学习资源点击流数据,提出JMATRIX算法。引入时间遗忘因子,根据时间赋予资源类别点击频率和资源类别点击路径2个指标不同的权值,构建用户学习资源类别点击流数据有向图模型,并将学习资源类有向图模型转化为矩阵模型存储,设计矩阵相似度求解公式,克服稀疏矩阵零向量引起的冷启动问题,求解用户相似度。JMATRIX算法极大地简化用户相似度求解过程,降低了算法的时间复杂度,提高了用户相似度求解效率和用户相似度准确性。实验结果证明,JMATRIX算法相比其他推荐算法具有更高的效率和准确性。下一步工作将研究JMATRIX算法的邓恩指数等其他推荐算法指标的优劣,以及研究JMATRIX算法在电商网站等领域的推荐效果。
[1] 胡钦太,郑 凯,林南晖.教育信息化的发展转型:从“数字校园”到“智慧校园”[J].中国电化教育,2014(1):35-39.
[2] 刘 嘉,祁 奇,陈振宇.ESSK:一种计算点击流相似度的新方法[J].计算机科学,2012,39(6):147-150.
[3] 印 鉴,王智圣,李 琪.基于大规模隐式反馈的个性化推荐[J].软件学报,2014(9):1953-1966.
[4] 朱 亮,陆静雅,左万利.基于用户搜索行为的Query-doc关联挖掘[J].自动化学报,2014,40(8):1654-1666.
[5] 梁邦勇,李涓子,王克宏.基于语义Web的网页推荐模型[J].清华大学学报(自然科学版),2004,44(9):1272-1276.
[6] 何 跃,马丽霞,腾格尔.基于用户访问兴趣的Web日志挖掘[J].系统工程理论与实践,2012,32(6):1353-1361.
[7] 朱国玮,周 利.基于遗忘函数和领域最近邻的混合推荐研究[J].管理科学学报,2012,15(5):55-64.
[8] MOE W W.An Empirical Two-stage Choice Model with Varying Decision Rules Applied to Internet Clickstream Data[J].Journal of Marketing Research,2006,43(4):680-692.
[9] SU Qiang,CHEN Lu.A Method for Discovering Clusters of E-commerce Interest Patterns Using Click-stream Data[J].Electronic Commerce Research & Applications,2015,14(1):1-13.
[10] HARTIGAN J A,WONG M A.A K-means Clustering Algorithm[J].Applied Statistics,2013,28(1):100-108.
[11] PARK H S,JUN C H.A Simple and Fast Algorithm for K-medoids Clustering[J].Expert Systems with Applications,2009,36(2):3336-3341.
[12] PARMAR D,WU T,BLACKHURST J.MMR:An Algorithm for Clustering Categorical Data Using Rough Set Theory[J].Data & Knowledge Engineering,2007,63(3):879-893.
[13] 廖寿福,林世平,郭 昆.个性化推荐冷启动算法[J].小型微型计算机系统,2015,36(8):1723-1727.
[14] 于 洪,罗 虎.一种Web用户访问路径的可能性模糊聚类算法[J].小型微型计算机系统,2012,33(1):135-139.
[15] ZENG Liren,LI Ling.An Interactive Vocabulary Learning System Based on Word Frequency Lists and Ebbinghaus’Curve of Forgetting[C]//Proceedings of Workshop on Digital Media & Digital Content Management.Washington D.C.,USA:IEEE Press,2011:313-317.
