如何运用ATLAS.ti分析定性数据和发掘研究主题
2018-01-17吴世友
吴世友
定性研究方法是中国社会工作研究的主要方法之一。据统计,2006至2008年内《社会工作》期刊(下半月)发表的所有学术论文中,超过七成的实证研究采用的是定性研究方法(沈黎、蔡维维,2009)。2015年内,《社会学研究》期刊发表的44篇实证研究论文中,超过一半(55%)属于定性研究;同年《社会》期刊上发表的43篇实证研究论文中,接近一半(47%)属于定性研究。①资料来源参考:http://www.cenet.org.cn/index.php?siteid=1&a=show&catid=108&id=68934然而,这些定性研究主要依靠研究者逐字逐句编码找主题,比较少借助于定性数据统计软件来开展研究。
一般来讲,开展定性研究是一项非常费时费力的工作,尤其是当研究的样本比较多,访谈资料转录成文字非常长的情况下,或是收集的定性资料包括多种类型文件如图片、音频、或视频资料的话,那么完全依靠原始的人工分析用就难以满足这些对大量、多样的定性数据分析的要求了。因此,如果能借助分析软件的帮助,就可能会起到事半功倍的效果。
本文将介绍一款被广泛使用的定性资料分析软件:ATLAS.ti.这是一款适用于多种形式数据的分析软件,可以同时分析和处理多个文本文档(如word或PDF文件)、图片、音频、视频以及基于google地球的地理方位数据等。这还是一款简单易学,界面友好直观的软件。通常操作ATLAS.ti不需要使用者有很多前设的相关软件知识技能,大部分人根据教程自学就能学会该软件的基本操作技能。此外,ATLAS.ti有很强的数据分析能力和漂亮的结果呈现功能,对提高定性研究的科学性和规范性有很大的帮助。
目前该软件已经发展到ATLAS.ti 8。对中文用户来讲,ATLAS.ti 8版的一个最大的变化就是首次可以直接导入并识别中文文档,并且兼容使用中文进行编码等操作。以往的ATLAS.ti版本都不能识别中文文档(只兼容英语、西班牙语和德语),故中文用户想要使用ATLAS.ti来分析数据的话,只能先把中文文件翻译成以上三种语言,再进行编码分析。因此ATLAS.ti 8版的问世,极大方便了中文用户的使用。
一、ATLAS.ti主要模块
从软件使用界面上讲,ATLAS.ti 8版较以往的版本有了很大的变化,但是基本的工作思路和使用模块跟以往版本大致相似。主要是按照以下图1中几大类来组织项目文档和资料分析的,其中各个模块的关系是层级包含的:“(1)项目(project)”可包含多种“(2)文件(Documents)”,每个文件可包含多个“(3)选取资料(Quotations)”,每个选取资料可包含多个“(4)编码群(Code groups)”;每个编码群可包含多个“(5)编码(codes)”。最后,ATLAS.ti允许对文件,选取内容和编码添加(6)备忘录(Memo)。

(1)项目。首先,在开始之前,可以先把自己的任务归类,有助于对源自同一个项目的多个文件、多种类型数据进行交叉和关联分析。在ATLAS.ti 8版本之前对一个任务归类叫做“阐释单元(Hermeneutic Unit)”,ATLAS.ti 8版有一个更为直观、贴切、易懂的名字:“项目(project)”。在“项目”下面,包含了所有与之相关的数据(即各种文件),以及数据编码,备注,和使用者所建立的数据和编码之间的各种关系。如下图2所示,启动ATLAS.ti后,系统会让你建立一个新的项目,然后会弹出一个窗口给该工作项目命名。当然,ATLAS.ti也允许导入其他已有的项目。
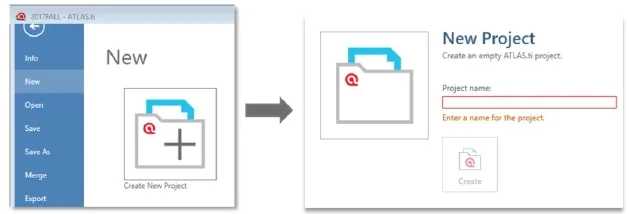
图2 :建立工作“项目”文件夹
(2)文件。接下来,建立好项目后,开始进入ATLAS.ti 8操作界面(见图3)。跟Microsoft Word类似,最上面是一系列[1]主菜单及主工具栏选项:主页(Home)搜索项目(Search project)分析(Analyze)导入/导出(Import/export)工具与支持(Tool&support)。在“主页”选项下面出现的子选项的最左边有个“[2]添加文件(Add Documents)”,点击此可以添加需要分析的数据文件。所有添加的文件会被显示在左下[3]快捷视窗的“项目”下面的“文件”下(点击“文件”左边的空心三角符号,就会下来出来所有已添加的文档名字)。同时,所有导入的“文件”会按照顺序排列(D1:D2:D3…)并显示在右下方的[4]工作界面的上方。当操作界面打开导入的“文件”后,最上面的“项目名称(如:2017FALL-ATLAS.ti)”的右边会多出来一个选项“[5]文件(Document)”,同时“文件”选项下面出现各种可对各种数据文件进行编辑的选项。这时上面的菜单行在“文件”下面会增加三个选项:文件(Document)视窗(view)A-Doc。这八个主菜单的每个选项下面又包含很多相关的子菜单操作按钮。由于ATLAS.ti官网上公布了免费的、详细的ATLAS.ti 8操作手册(请登陆http://atlasti.com/product/v8-windows/点击页面最下面的文档“ATLAS.ti 8 Quick Tour”下载阅读),这里不再重复描述具体各个选项的功能,读者可自己点击了解各个按键功能。对于中文用户,可下载ATLAS.ti 6中文速成教程(http://atlasti.com/wp-content/uploads/2014/07/Quick_Tour_a6_zh_01.pdf?q=/downloads/QuickTour_zh.pdf)。虽然中文用户手册的版本是6.0,但是主要功能介绍是相通的,同样具有参考价值。之前的版本称“文件”为“原始文档”(Primary Documents,or P-Docs)。
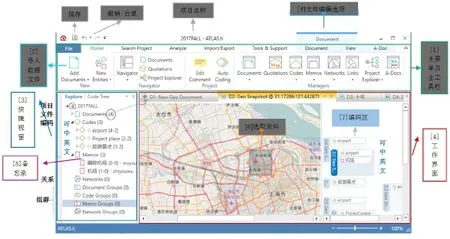
图3 :ATLAS.ti 8版操作界面简介
(3)选取资料。打开文档后,就可以开始进行数据编码了。ATLAS.ti 8允许使用者选取文档文件中的一段文字,图片文件中的某个局部图像(如图3中[4]工作界面左边图片中间部分[6]选取资料),或是音频或视频文件的某节影音资料,以及谷歌地图中的某个地点进行编码。
(4-5)编码及编码群。编码的过程就像是一个“淘宝”的过程。可以在同一个“项目”在不同的“文件”之间进行切换(ctrl+tab)。可以对选取的单个资料,进行重复多个编码,也可以对不同资料赋予相同的编码。所有的编码会显示在[4]工作界面的右边[7]编码区域内。ATLAS.ti 8还允许对同一类别的编码组成编码群(code groups),以往版本称之为编码家族(code family)。例如对以下单个编码:父亲、母亲、女儿、儿子可以组成一个编码群:家庭成员。对中文用户,ATLAS.ti 8允许使用者进行中英文多语种编码,极大方便了中文用户使用该软件。具体编码过程下一节将单独详细介绍。
(6)备忘录。ATLAS.ti 8允许使用至对文件和编码添加备注。在[3]快捷视窗的编码下面,有一个类别是[8]备忘录,使用者可以对各种编码进行备注,或者评论。添加的备忘录名字后面还会显示备注者的用户名,这样如果是多个使用者对同一个“项目”进行编码分析的话,就能清楚知道是哪位使用者添加的备注。这个功能对团队工作会有帮助。当然,使用者也可以把单个备忘录组成备忘录群,跟编码群很类似。
保存和导出文件。如果是第一次在ATLAS.ti编辑文件,需点击“导出(export)”“项目包(project bundle)”,这样就把ATLAS.ti里面建立的编码和原始资料都捆绑在一起了(也应注意将原始文件保存在ATLAS.ti文件所在的同一个文件夹里),否则如果换一台电脑操作,拷贝的ATLAS.ti文件里的编码等将无法与原文件联系在一起。但是在文件包建立以后的操作,就可以直接点击“文件”“另存为”了。
二、ATLAS.ti的编码功能介绍
鉴于ATLAS.ti 8刚问世不久,为了照顾部分ATLAS.ti老版本的使用者,本章将以ATLAS.ti 7的操作界面为例,辅以操作界面的截图,来跟大家分享几个ATLAS.ti常用功能的具体操作步骤。一般而言,如果掌握了7版的操作,8版的操作使用也会很快上手,二者是相通的。
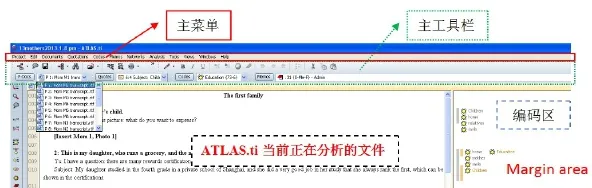
图4 :ATLAS.ti 7主操作界面
ATLAS.ti的编码功能是ATLAS.ti最主要,也是最常用的功能之一。之所以定性研究者们愿意使用ATLAS.ti来对文件进行编码,是因为ATLAS.ti作为一个辅助工具,有很多方面比人工编码更有优势。例如,ATLAS.ti可以帮助使用者通过关键词在全文搜索进行编码,可以减少人工编码会遗漏部分信息的可能性,尤其是当文件数量大,种类多的时候优势明显;ATLAS.ti还可以对编码进行分析,比如汇总编码频次,建立编码之间的关联,并找出编码之间的关系,进而对研究者提炼研究主题很有帮助。ATLAS.ti有很好的结果呈现功能,不仅能呈现编码之间的关系示意图,还可以呈现可视化的编码-文件之间的关系,非常直观,明晰。编码的步骤为:
第一步:导入需要分析的数据文件。ATLAS.ti 7允许导入一个已经存在的项目文件,即某个项目的阐释单元:点击最上方左边的“Project”“Open”“Your atlas file”,这时打开的窗口会显示你电脑指定文件夹里面之前已经存在的“.hpr6”为后缀名的数据文件。如:13mothers.hpr6。点击打开后,所有跟这个项目相关的数据文件会自动加载在ATLAS.ti的主操作界面。在左上方“P-Docs”按钮旁边有个显示框,显示当下工作界面正在使用的文件。如使用者需切换至另一个文件进行编码,可点击显示框右边的“▽”按钮,就会出来一个下拉菜单,上面显示该项目包含的所有的数据文件,点击想要进行编码的文件,ATLAS.ti主操作界面就会加载相应的文件以供使用者进行编码分析(如图5绿色虚线箭头所指的右边部分)。
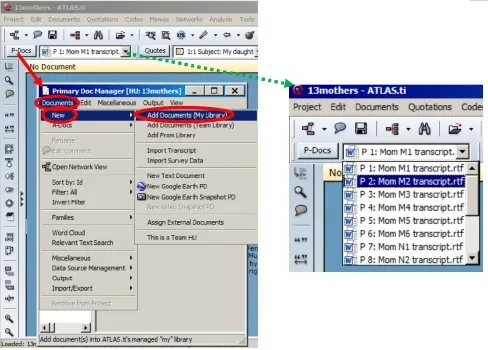
图5 :导入文件示意图
如果需要添加新的文件到当前项目,可以点击左上方“P-Docs”按钮,这时会弹出一个新的对话框“Primary Doc Manager”,点击左上方的“Documents”“New”“Add Documents(My Library)”,然后就可以导入使用者电脑上的文件了。导入的文件类型可兼容文字文档,图像资料,影音文件。此外,还可以导入google地图数据等文件(如图5红色标注部分)。
第二步:创建编码。当需要分析的文件加载后,使用者就可以根据研究主题,对文件中的任何部分内容进行编码。所选取的内容(即:Quotation)可以是一段文字,一张图片的部分图像,或者是一段影音文件的某段视频或音频。总之ATLAS.ti给予使用者很大的自由空间来对导入的文件进行编码。一般来讲,创建编码有以下三种方式:
开放编码(Open coding)。顾名思义,开放编码是一个很随性、自由、开放的编码方式,研究者想编哪里编哪里。这也是定性研究者最常用的编码方式之一。这种方法就是研究者一边看(听)文件,一边对感兴趣的地方进行编码。赋予的编码也是根据文件内容而定,可以随时根据需要创建新的编码。开放编码步骤比较简单(见图6):选中想要编码的内容,然后右键点击右键选项“coding”点击“coding”子选项“enter code name(s)”然后在弹出的“Open Coding”对话框里面输入想要编码的内容(如:smile)。假如想对选中的内容赋予多个不同的编码,那么可以在对话框继续输入新的编码内容,按向下“↓”键可以继续添加新编码。
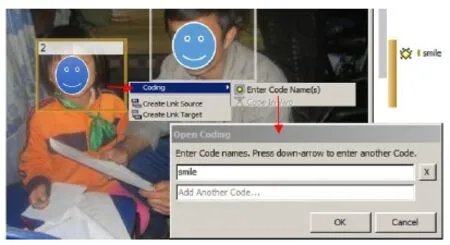
图6 :开放编码示意图
利用编码表进行编码。对于定性研究数据,研究者一般可以根据自己的理解和研究需要,在正式编码前建立一些前设(a-prior)主题编码。举个例子,如果某项对“家庭关系”的研究,会涉及到不同的家庭成员的情况和事件介绍,那么研究者知道需要在之后的编码过程中,对所出现的具体的家庭成员(如:父亲,母亲,女儿,儿子等)进行编码标注,以便将不同的家庭成员的具体情况和事件联系起来。那么,在正式编码前,研究者可以事先建立一个编码表将可能用到的编码先保存在ATLAS.ti系统里,这样在后面的编码过程中就不用重复生成一个编码,直接从预先建立的编码表里面提取即可。
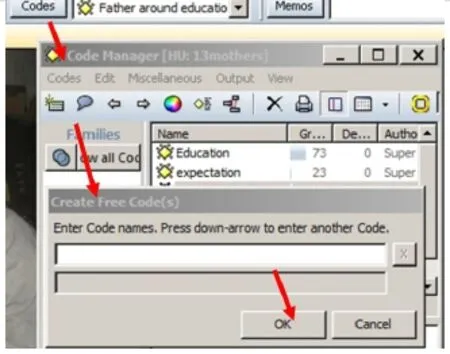
图7 :建立编码表示意图
在前设编码表生成后,使用者可以在浏览文件的过程中,随时提取预设的编码进行编码。这个步骤跟开放编码类似,但比开放编码相对快捷(见图8):选中想要编码的内容,然后右键 点击右键选项“coding”,选择其子选项的“Select Codes(s)from List”然后会弹出一个小的窗口“Select:Codes”,上面列出所有之前已经输入的编码,选中并双击想要赋予选中内容的编码名字,就完成了编码的过程了。
当然,利用编码表进行编码,并不排斥开放编码的使用,很多使用者结合这两种进行编码。如在使用编码表进行编码,遇见新的内容或是有新的研究发现时,此时需要生成一个新的编码,那么就可以用开放编码的方式,添加新的编码,这些后期添加的新编码也会自动合并到编码表里面,方便使用者继续使用。因此,结合二者的长处,既能保证编码的灵活度不受限制,也有利于提高编码的效率。
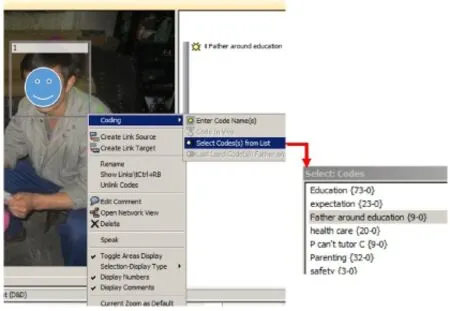
图8 :通过编码表进行编码示意图
自动编码(Autocoding)。这是使用ATLAS.ti编码比人工编码更具优势的功能之一。所谓自动编码,就是可以允许使用者利用关键字检索功能,对文件中涉及的关键字进行统一和自动编码。这些被检索到的相关内容就成为编码所选取的资料(Quotations)。这个功能最适用于直观性的表层的(surface-level),描述性的(descriptive)编码。
自动编码的检索功能比较灵活,跟大部分期刊数据库的检索逻辑类似,使用者可以定义特定的系统表达式。比如用“|”符号表示“或者”,在某单词或字母后面或前面添加“*”符号,表示跟该单词或字母相同的任意后缀或前缀词。例如:想在全文中检索跟“教育(education)”相关的内容进行编码,那么自动检索的表达式可以为:“educat*|school|exam*|class*”.ATLAS.ti会根据这个表达式,逐个搜索相关内容(即包含“educat”的词如education,educator,educating,educate等;或者跟“school”相关的词;或者包含“exam”的词,如examination,exam,examining等;或者包含“class”的词,如classmate,classroom,classes等)。由于对每个单个的检索结果进行编码时需要使用者再次确认,所以使用者可以在确认过程中,对ATLAS.ti自动检索到的相关内容进行甄别,以此减低系统选取的误差。
图9呈现了自动编码的步骤:在最上方主菜单选项点击“Codes”,会出现一个下拉菜单 点击下拉菜单第二个选项“Coding”,会出现一个子选项菜单 点击最后一个选项“Auto Coding”,这时会弹出来一个新窗口“Auto Coding Dialog”这时使用者可以在“Select code”对话窗口里面从编码表里面选取已有的编码,或者点击该对话窗口右边的“New Code”创建一个新的自动编码想要赋予的编码名 然后在下面的“Enter or select Search Expression”对话框内输入相关的检索表达式(如:“educat*|school|exam*|class*”)建议选择“confirm always”选项(那样每次自动编码选取内容的时候会跟使用者逐一确认,否则没选这个选项的话,就会在符合表达式的内容部分,全部自动生成编码了),然后点击“Start”按钮 然后ATLAS.ti会根据检索表达式,帮助使用者逐一确认由ATLAS.ti检索出的内容,并自动赋予给定的编码。如果检索的内容符合自动编码,只需点击“Code it”就完成了编码过程,ATLAS.ti会继续显示下一个检索出的内容。如果ATLAS.ti自动检索出的内容不符合给定的编码内容,那么就点击“Skip it”,这样ATLAS.ti就不会对刚才所检索出的内容赋予预设的编码。
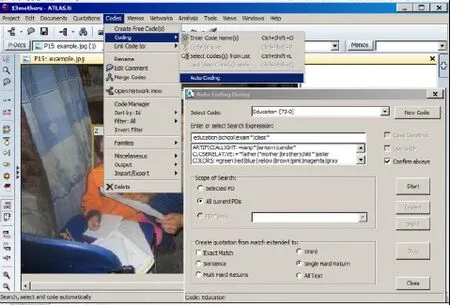
图9 :自动编码示意图
第三步:查看编码及选取内容之间的关系。编码完成后,可以进一步查看编码及选取内容之间的关系。例如,查看某个文件都被赋予了哪些编码,就可以使用“文件及编码网络视图(Network View of Primary Documents and Codes)”这一功能。图10说明了这一功能的步骤:点击主工具栏的“P-Docs”按钮,会弹出一个新的对话框“Primary Doc Manager”再右键点击想要查看的文件名(如P15:N2-8.JPG),选择“Open Network View”然后会弹出一个新的界面,上面显示文件名称(对于图片用户,继续右键点击该文件名,选择“Import Neighbors”选择子选项“Import Codes”)。这样就可以看到所有跟图片文件(N2-8)相关的编码了。此外,对于图片文件,可以进一步点击上方菜单栏中的“Display”的子选项“Full Image for PDs”,即可导入该图片,这样对于显示图片文件和编码的关系更为直观。
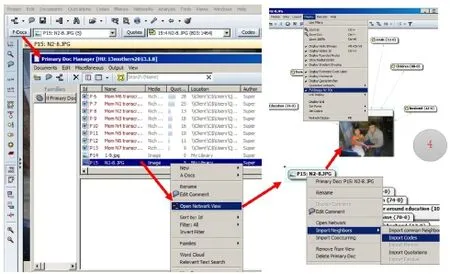
图10 :文件及编码网络视图
ATLAS.ti还支持使用者查看某段选取文件都被赋予了哪些编码,就可以使用“选取内容及编码网络视图(Network View of Quotes and Codes)”这一功能。步骤为:点击主工具栏“Quotes”,会弹出一个新的对话框“Quotation Manager”再右键点击想要查看的选取的内容,选择“Open Network View”然后会弹出一个新的界面,上面显示选取内容跟相应的编码。
当然,使用者还可以查看某个编码都被赋予在那些内容上,那么就可以使用“编码及选取内容网络视图(Network View of Codes and Quotes)”这一功能。步骤见图11:点击主工具栏“Codes”,会弹出一个新的对话框“Codes Manager”再右键点击想要查看的编码名字(如:“P can’t tutor C”),选择“Open Network View”然后会弹出一个新的界面,会显示所选取的编码名字右键点击该编码名,选择“Import Neighbors”选择子选项“Import Quotations”。然后界面就会显示所有跟该编码相关的引用内容。
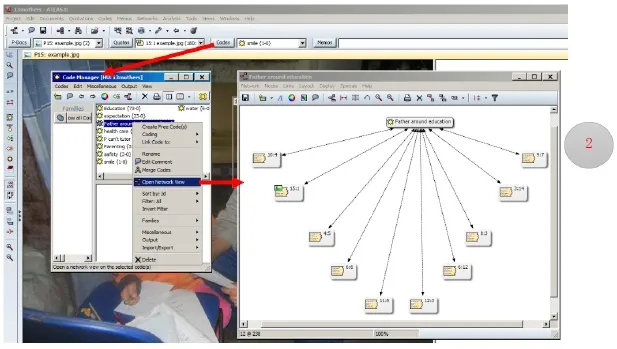
图11 :编码及选取文件网络视图
为了使以上关系视图更为整齐清晰,ATLAS.ti提供一系列调整关系内容分布的小命令。比如当某个编码对应的选取内容很多的时,为了使分布界面更为清晰美观,可以让所有的选取内容标题,均匀分散在某个编码的周围,呈扇形分布。操作步骤为:在关系网络界面最上方的菜单栏,选择“Layout”“Semantic Layout”即可调整各种关系的分布。使用者还可以根据自己的喜好,调整相应的位置与分布。
总之,ATLAS.ti提供多种自由灵活的编码功能,但是每种方法都有其优点和不足。因而,使用者需要根据自己的数据类型,采取灵活多样的编码方法。
三、ATLAS.ti的数据分析功能介绍
ATLAS.ti另一个比人工编码和分析数据的优点在于其强大的数据分析功能。使用者在完成所有数据编码后,ATLAS.ti会将所有的编码进行汇总和分析,从而帮助使用者进一步探讨编码之间的关系。此外,通过对编码的分析,ATLAS.ti还能帮助使用者对定性研究的主题进行提炼,以及方便查询、提取及汇总后期研究报告写作的过程中所需要引用的各个编码和主题等相关的内容等。
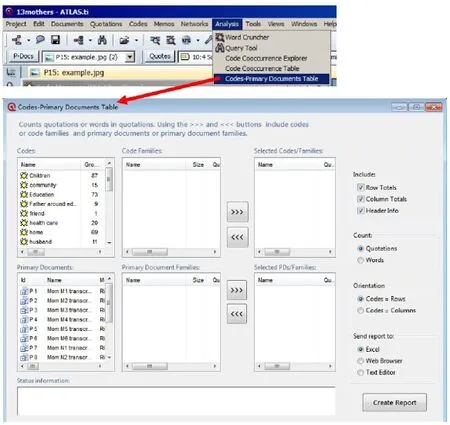
图12 :生成编码-文件表示意图
(一)编码-文件表(Codes-Primary Documents Table)
通过这个表格可以查询每个生成的编码在各个文件中的分布,以及编码的分布频次等。此外,使用者还可以选择查询特定的编码在特定文件中的分布情况。具体步骤见图12:先在主菜单栏中选择“Analysis”点击下拉选项中的“Codes-Primary Documents Table”,这时会弹出一个新的对话框“Codes-Primary Documents Table”在新对话框的左上角的“Codes”小窗口里面显示了所有已经生成的编码(即:当前项目文件的编码表),选中想要查看的编码名字(可全选或选择部分);或是选中中间的“Code Families”中的编码群(如果之前已经生成了编码群的话就可以选,如果没有,则不用选)然后点击“>>>”按钮,将所选的编码纳入将要分析的“Selected Codes/Families”小窗中以备稍后的分析;如需撤销所选编码,只需选择所选编码,再按“<<<”按钮即可 继续在“Codes-Primary Documents Table”对话框的左下方选想要查询的文件名字(可全选或选择部分)或是选中中间的“Primary Document Families”中的文件群(如果之前已经生成了文件群的话就可以选,如果没有,则不用选)然后点击“>>>”按钮,将所选的文件纳入将要分析的“Selected PDs/Families”小窗中以备稍后的分析;如需撤销所选文件,只需选择所选文件,再按“<<<”按钮即可“Codes-Primary Documents Table”对话框最右边的选项,使用者可以根据自己的喜好,或者自己的研究需要酌情调整,但是一般情况下按照默认设置即可最后点击“Create Report”就完成了生成编码-文件表的步骤了。
pH值作为衡量果醋饮品的一个重要指标,本文采用PHS-25酸度计对不同时段的柠檬果醋进行测量,并做出比较。由图3可知,柠檬果醋的pH值在酿造不同阶段的样品中并未产生过大的变化,由最初的2.77下降到2.66,而后缓慢下降到2.63。表明其pH值的随储藏时间的推移而增大,酸性增强,表明柠檬果醋的口感逐渐变得醇厚起来。
编码-文件Excel交叉分布表。ATLAS.ti接着会生成一个编码-文件Excel交叉分布表,见图13:第一列为编码群,第二列为各个编码群的子编码,之后各列依次显示所有选取的文件名称。使用者还可以在excel里面,对生成的excel进行进一步编辑,比如用不同的颜色背景区分不同编码族。由于默认的excel编码-文件交叉分布表只显示各个编码在每个文件的分布频次,使用者可以在频次基础上,添加百分比行(图13黄色部分),可以更加直观显示各个编码的分布情况。
根据分布表的极多值或极少值提取潜在的研究主题。图13可以帮助使用者对各个编码在各个文件的单个分布和汇总分布情况有个大概的了解。通常来讲,定性研究者可以根据这个表的分布情况,提取相关的主题。比如频率出现最高的前几个编码,就可能是该项目的关注点,或者是访问对象比较关注的话题或问题。如图13表明:儿童[Children;79%];教育[Education;66%];家[Home;67%]是流动家庭母亲们拍照的主要关注对象、关注点和拍摄地点。同样,频率出现最少的几个编码也可以是研究者的潜在关注点。比如图13表明:流动家庭母亲的拍照内容很少涉及亲戚[Relatives;5%];朋友邻里[Friends&Neighbors;5%];甚至没有涉及任何家里的老人[Elder;0%]。通过这些极少值的编码,可以对了解和理解研究对象的生活日常和家庭互动情况有一个了解,对于一些应当涉及(前设编码)而实际没有涉及的编码(如家中老人),研究者就可以进一步挖掘其中的缘由,因而也可以成为一些有意义的研究主题。当然提炼这些研究主题的基础需要建立在研究者对研究主题,研究背景,研究内容,以及研究对象情况比较熟悉,并能对这些极多值或极少值进行合理解释。
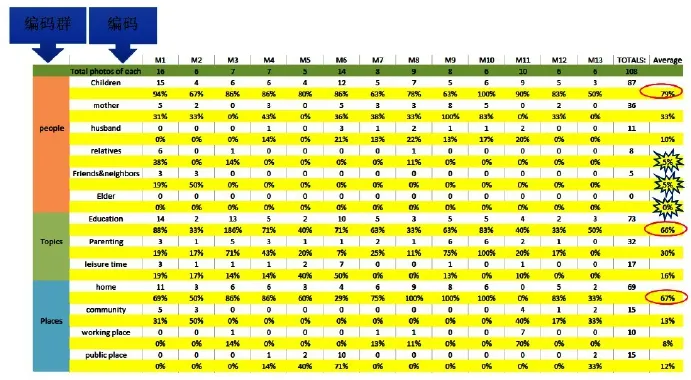
图13 :编码-文件Excel交叉分布表
(二)编码交互出现表(Code Co-occurrence Table)
通过这个表格可以查询各个编码之间的出现的重合率,并以此了解不同编码之间的相关程度。具体步骤见图14:先在主菜单栏中选择“Analysis”点击下来选项中的“Code Co-occurrence Table”,这时会弹出一个新的对话框“Code Co-occurrence Table”在新对话框的左边的“COLUMS”和“ROWS”里面选取全部的编码或部分编码,按”>>”选取或“<<”撤销。选取后的编码会自动导入到右上的显示框中。如果点击表格中的数字,下方的两个小方框里面就会自动显示出相关的选取内容。需要指出的是,研究者只需看对角线的上半部分或下半部分就可以,因为表格内容是按照对角线对称的。
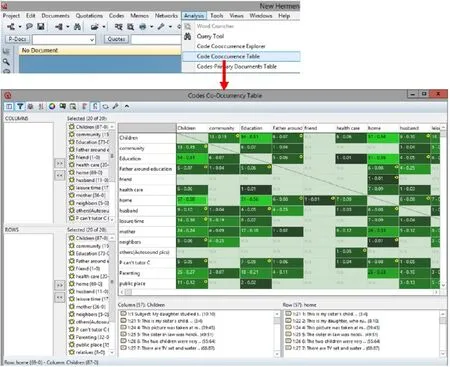
图14 :编码交互出现表示意图
编码重合率(Code Co-occurrence Rate)。数字表格中的数字和比率代表行列编码之间的重合度(见图15)。如果把鼠标放在某个格子上,ATLAS.ti就会显示一个白色的对话框,给出行列编码的各自出现的频次(如smile(52)@Children(87)意味着smile这个编码出现了52次,children出现了87次)。而格子里显示的“50–0.56”,第一个数字“50”表示这两个编码在同一个选取内容同时出现了50次,换句话说,有“smile”的地方就有“children”同时出现了50次;“0.56”表明两个编码的重合率,或重合度,其换算公式是:
AB编码重合率=AB编码重合次数/(A编码次数+B编码次数-AB编码重合次数)
用上面的例子,smile编码和children编码的重合率,ATLAS.ti是这样计算得来的:0.56=50/(52+87-50)。这个重合系数越高,说明两个编码之间的重合度越高。为了方便区分,ATLAS.ti用不同颜色代表不同的重合度,例如绿色越浅,表示的重合系数越高;绿色越深,表示重合系数越低。重合系数小于0.10的格子,ATLAS.ti会在该格子的右上角标注一个黄色的小圆圈,这样方便使用者在重新调整或精简编码交互关系表时,在图14的操作界面,能比较方便快速定位两个重合率低的编码,从而将这些编码在行列编码选取列表里移出。另外,如标有“n/a”字样,则表示行列编码之间无重合。
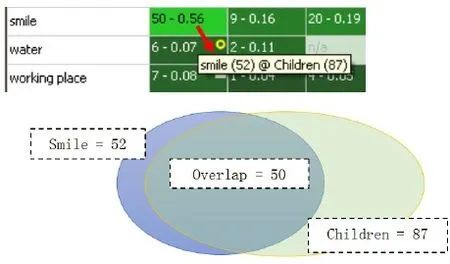
图15 :编码重合率示意图
建议一开始生成这个表的时候,可以全选所有的编码,然后将显示灰色的以及“n/a”的行列编码从已选的编码表里面去掉(选中编码后按“<<”按钮),再将相关系数较小的(如重合率小于0.20)编码也去除。这样精简编码交互出现表,只留下重合率高的编码。当然,假如研究者在基于以往经验或研究积累基础之上,得出某两种编码之间有很强的重合度假设,但是编码交互出现表显示二者的重合率极低,这种情况下,也可以保留弱重合率的编码,最后在汇报结果的时候,找出解释这个反常情况的原因。
总而言之,这些数字和表格,都是为了帮助研究者更好的呈现研究主题,解释或阐述某个现象。并没有绝对的标准区分和限定,研究者需要根据对所研究的主题有一定的了解和积累,在此基础之上才能更好的利用ATLAS.ti这一工具来服务自己的研究工作。所以我们常说,做定性研究表面看上去很容易,其实要真正做好一个定性研究,并非易事,对研究者的能力和阅历要求很高。同样,运用ATLAS.ti也并非简单的只是跟电脑软件操作,而是在操作过程中,研究者需要不断地运用自己所积累的知识和经验,对研究过程、研究发现、以及研究方法随时进行调整。
四、ATLAS.ti的结果呈现功能介绍
前面提到,使用ATLAS.ti的最终目的就是帮助研究者更好的找出,以及呈现研究结果。本章将结合笔者参与的一项针对上海市浦东新区T村的流动家庭“母亲形象”的影像发声(Photovoice)项目为例(项目介绍参见:朱眉华,吴世友&Mimi Chapman,2012;2013;Chapman,Zhu&Wu,2013),来跟大家分享一些使用ATLAS.ti来帮助研究者找出研究主题,以及如何运用ATLAS.ti强大的图表功能来更好地呈现研究发现。
(一)利用编码-文件Excel交叉分布表来提炼研究主题
找出出现频率最多的编码提炼主题。通过编码-文件Excel交叉分布表上呈现的频率分布(参见图14),可以发现,以下三个编码:儿童(children;79%);教育(education;66%);家(home;67%)出现的频次最高,而且这三点也完全符合这些流动家庭母亲们日常生活的主要特点:即她们每天的关注的主要对象是自己孩子,在孩子身上,她们的主要关注点是孩子的教育,以及她们日常生活的主要活动区域是自己的家里。针对此,我们根据这些母亲们的访谈资料和对照片的介绍,提炼出以下几个研究主题:“子女教育:期望与担忧”和“生活空间:被城市遗忘的角落”(朱眉华,吴世友&Mimi Chapman,2013);以及“望子成龙”和“一切为了孩子”(Chapman,Zhu&Wu,2013)等主题。
(二)利用编码交互出现表的重合率来呈现编码之间的关系并提炼主题
通过重合率较高的编码来提炼主题。按照之前的的建议,可以删掉重合率较低的编码,保留重合率较高的编码(如图16)。根据这个表格,可以更加简要清晰地查看项目文件中,重合率较高的编码有哪些,为什么这些编码会有重合,而非与其他编码有高重合率?这些高重合率意味着什么?研究者带着这些问题,就可以进一步深入挖掘更多的定性资料,来辅助和理解编码之间的关系。挖掘出有趣/意义的编码关系,也可以成为潜在的研究发现。
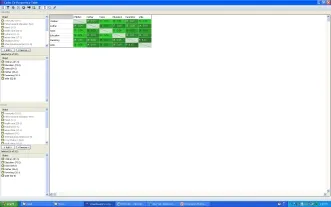
图16 :精简版编码交互出现表
利用编码关系图来呈现编码之间的关系。ATLAS.ti另一个很好用的功能就是可以用直观的视图来呈现编码之间的关系,以及编码跟文件,选取内容之间的关系等。这里介绍用ATLAS.ti来呈现编码之间的关系图。这个图可以表达某个编码群跟附属编码之间的关系,也可以表达不同编码群所附属的编码之间的关系。此外使用者还可以手动修改ATLAS.ti默认的效果图,如不同的颜色和线条的粗细虚实来表示不同编码之间的重合率等等(如图17)。
通过图17关系图,我们可以清楚的看到,“home”和“education”,“home”和“children”,以及“children”和“education”之间重合度很高,说明这些妈妈拍的日常生活照片里面,很多跟她们孩子的教育活动相关,并且,大部分时间是在家里拍的。
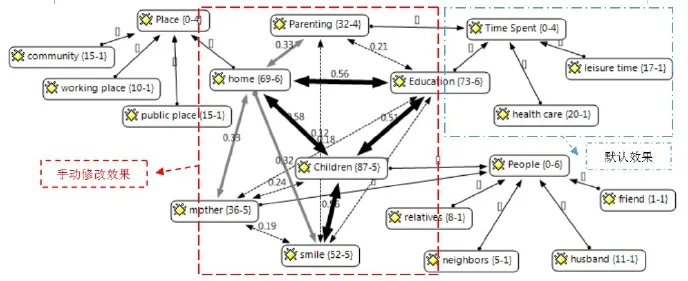
图17 :编码关系图(引用自:Chapman,Wu,&Zhu;2016)
创建编码关系图的步骤如下:点击主工具栏的“Codes”,弹出“Code Manager”窗口选择(点击+ctrl点击可连续选择多个编码)想要查看关系的编码,然后右键点击“Open Network View”。这时弹出的新窗口会显示所选的编码(但彼此之间无线条连接)点击某个编码(出现蓝色方框,左上角有一个红点),再点击工具栏上的“创建关系”按钮,这时鼠标指向的地方会从红色点那连接一条线点击所要建立关系的另外一个编码,这时会接着出现一个下拉菜单,提供一些编码关系的选项(例如“==:相关关系”,“[]:从属关系”,“=>:因果关系”,“<>:矛盾关系”等;如图18),研究者可以根据二者的实际关系,点击相应的选项然后两个编码之间就会有一条线条,上面会写上相应关系的标签。如需取消创建的关系,只需点击想要取消关系线条,然后点击“创建关系”按钮右边的“消除关系”按钮即可。
如需更改默认关系图的视觉效果:选中想要调整的编码之间的关系线,右键选择“Change Relation”,自动弹出关系选择菜单点击最后一个选项“Open Relation Editor”,就会弹出一个“Code-Code-Relations Editor”窗口,使用者可以根据自己的喜好和研究需要对关系进行修改(如在“Line Style”的选项调整线条的粗细、虚实、颜色等;见图19)。
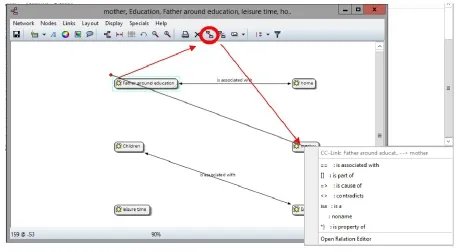
图18 :创建编码关系示意图
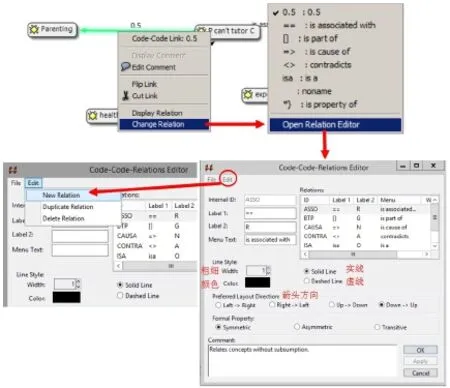
图19 :调整编码关系设置示意图
如果想创建一个新的关系,则可以点击“Code-Code-Relations Editor”窗口左上方的“Edit”点“New Relation”,然后按照要求填写相应的内容即可。例如:要新创建一个编码之间重合度大于0.5的强关系:“Internal ID”填写“STRONG”,“Lable 1”填写”++”,“Label 2”填写“ST”,“Menu Text”填写“>0.5”“Line Style”选项的“Width”选择“5”,Color选取红色 点击“OK”就可以完成。然后再去添加编码关系的时候,关系选项菜单就会多出来一项刚刚创建的强重合关系可供选择(见图20的右边图示)。同样的方式,使用者还可以创建相应的其他数值(如0.4;0.3;<0.2等)的编码关系。使用者基本上可以建立任意想要对应的编码之间的关系(如图17所示)。这个功能用在做研究汇报的PPT示意图,非常实用,也能很清晰明确地表达各种编码之间的关系,从视觉上来看,比用表格、数值的呈现方式更具优势。
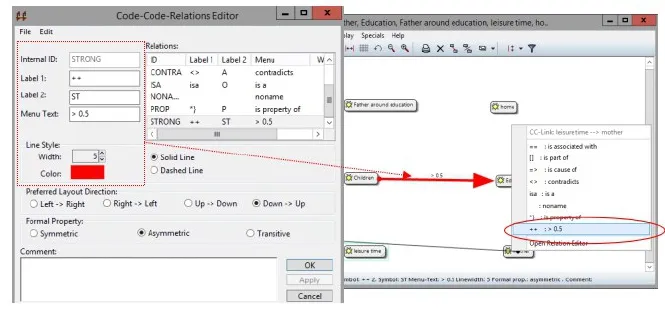
图20 :创建新的编码关系示意图
(三)找出不合乎常理/不寻常的事件或编码关系提炼主题
对这一个提炼主题的方法,需要研究者对研究问题和研究对象的背景知识,以及相关理论常识有一定的了解。因为只有知道了哪些是合乎常理的、哪些是理论上应该有的,才能发现具体的研究过程中,出现的不合乎常理的事件和节点。这就要求研究者,不仅要关注出现频率高的编码,还要对出现频率低的编码具有一定的敏感度。例如,我们发现有几个频率出现最少的几个编码有点不寻常。因为在创建前设编码表的时候,我们认为一般的传统中国家庭,大部分应该是有老人跟子女一起生活的,于是我们创建了“老人”这个编码,然而,在编码过程中,我们发现,没有一个流动家庭母亲拍照的内容涉及到家里的老人(Elder;0%),这是一个很不寻常的现象。但是,基于流动家庭这一特殊特征,我们似乎又能理解为什么会有这样的现象发生。于是在后期的访谈于讨论会上,我们再次跟这些母亲提出这点发现,进一步了解她们自己对这一发现的理解和看法。针对这一发现,我们提出了一个研究主题“家有一老,如有一宝”(Chapman,Zhu&Wu,2013:254)。
此外,我们发现,她们的丈夫也只有10%的照片涉及到。针对这一个发现,我们进一步了了解了这个比例背后的故事,他们的家庭情况等。并以此提出了另一个主题“男儿有志在四方”(Chapman,Zhu&Wu,2013:255)。
(四)对特殊事情和有重大影响的事件进行编码
通过特殊事件提炼主题。在编码过程中,有些研究对象发生的单个特殊或关键性事件(例如:家庭成员去世、患重大疾病、或升迁等),对研究对象个人及家庭产生重大影响,需要进行编码,备注。这些事件可能发生的频率不高,但是可能成为用于理解研究对象人生轨迹,或者目前的生活方式和行为等状况的因素。这些事件,可以用于帮助研究者提炼一些研究主题。例如,在上海的影像发声项目分享过程中,我们发现“健康问题”是这些流动家庭的另外一个重要关注点,于是提出“看病难,看病贵”这个主题(Chapman,Zhu&Wu,2013:253)。
五、对定性资料的引用
通常在写定性研究报告/论文的时候,需要直接引用一些原文资料,那么用ATLAS.ti分析定性数据的另一个好处这时就凸显出来了。因为在对庞杂的定性资料数据分析完以后,研究者可以很方便的调出所有的每个编码所指的原文资料,可以是文字原文,也可以是影像资料等等。还可以搜索出不同的编码关系之间(如A和B重合;是A非B等关系)的原文引用,研究者不需要倒回去原文里面一个个找出来,而ATLAS.ti可以直接帮研究者导出来所有的资料,大大节约了研究者的时间。
具体操作就是生成一个编码搜索报告(Query Report).具体步骤见图21:在上方快捷工具栏选中一个望远镜的小按钮(鼠标放在望远镜图标上,会显示“Retrieve quotations with the query tool”这一行字),(或者在主菜单栏中选择“Analysis”点击下拉选项中的“Query Tool”)就会弹出一个“ATLAS.ti Query Tool”窗口 在左下方“codes”栏目里显示了编码列表,双击想搜索原文引用的编码(例如想看“教育“[education”]”和“父母对辅导孩子学业有困难“[P can't tutor C”]”这两个编码重合部分的引用,则双击这两个编码),这是选中的编码会自动显示在右上“Query”方框里然后在“ATLAS.ti Query Tool”窗口最左边的那一列符号里选择想要的搜索条件,把鼠标放在每个符号上,就会显示该符号代表的命令(如“”表示搜索A“and”B重合部分的引用)然后右下方就会自动加载相应的Id,文件名字等信息 点击右下窗口右上角的一个打印机按钮,在下拉菜单中选择相应的选项,如“Full content”然后会弹出个小的窗口“send output to:”询问想要将所引用内容发送到哪里去选择“editor”,然后点“ok”然后会弹出一个新的对话框,显示搜索报告(Query Report),在这里就可以查询,拷贝复制想要的基于不同编码条件选取的原文资料引用了。
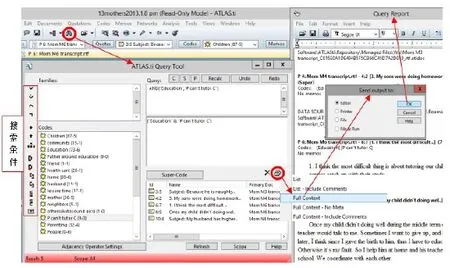
图21 :通过编码搜索报告获取原始资料引用
总之,本文通过分享笔者参与的一项针对上海市浦东新区T村的流动家庭“母亲形象”的影像发声项目,简要介绍了一些使用ATLAS.ti来帮助研究者找出研究主题的方法,一般可以通过以下四个方法找出研究主题:首先找出出现频率最多的编码;其次,找出重合率较高的编码;第三找出出现频率不合乎常理/不寻常的编码或编码关系;最后,找出对研究对象有中大影响的特殊事件或关键问题。
一般来讲,一篇学术文章的篇幅不会太长,所以,如果按照以上四个方法各找出一个研究主题,那么对撰写一篇定性研究的学术论文就够了。但如果要扩展为一个较长的研究报告,那么一般来讲,介绍出现频率最多的前三个(那么就可以有三个主题);不合常理的主题或编码关系(可能可以找到一到两个,也可能没有);重合率最高的三四个编码关系,以及一两个重要事件,应该也就足够了。最后,如果研究者能利用好ATLAS.ti的一些图像绘制功能和基于编码搜索的原始资料引用等功能,不仅能提高结果呈现的质量,还能大大节约研究者的时间和精力,起到事半功倍的作用。
当然,ATLAS.ti很有多其他的功能,需要读者自己进一步去发掘和探索。另外,ATLAS.ti只是一个辅助的研究工具,好的定性研究,需要很多其他的因素,例如良好的研究设计,丰富的研究数据,研究者的研究学识背景和对研究主题的敏感度等等。在具备这些基础之上,利用ATLAS.ti来分析定性研究数据,才有可能进一步提高定性研究的水平。目前我国使用ATLAS.ti开展定性研究的案例还不是很多,希望各位读者学习本章的内容以后,多多尝试使用ATLAS.ti,丰富中文领域ATLAS.ti的使用案例。
[1] 沈黎、蔡维维,2009,《社会工作研究的理念类型分析——基于〈社会工作〉下半月(学术)的文献研究》,《社会工作下半月(理论版)》第2期。
[2] 朱眉华,吴世友&Chapman,M.V.,2013,《流动家庭母亲的心声与社会工作的回应——基于T村母亲形象影像发声项目的分析》.《中国青年政治学院学报》第5期。
[3] ATLAS.ti软件主页:http://www.atlasti.com
[4] Chapman,M.V.,Wu,S.,&Zhu,M.2017,What is a picture worth?A primer for coding and interpreting photographic data.Qualitative Social Work,,16(6),810-824.Online first.https://doi.org/10.1177/1473325016650513
[5] Chapman,M.V.,Zhu,M.,&Wu,S.2013,Mothers in transition:Using images to understand the experience of migrant mothers in Shanghai.Journal of the Society for Social Work and Research,4(3),245-260.
[6] Friese,S.2014,《 ATLAS.ti 6速 成 教 程 》,Retrieved from http://atlasti.com/wp-content/uploads/2014/07/Quick_Tour_a6_zh_01.pdf?q=/downloads/QuickTour_zh.pdf
[7] Friese,S.2014,Qualitative data analysis with ATLAS.ti.Sage.Retrieved from http://zdenek.konopasek.net/archiv/kpa/filez/Atlasti_workshop_manual_english.pdf
[8] Petrova,V.2014,Intro to Atlas.ti:Qualitative Data Analysis Software.Retrieved from http://csscr.washington.edu/papers/14-01.pdf
[9] Smit,B.2002.Atlas.ti for qualitative data analysis.Perspectives in Education,20(3),65-75.
