融入软信息的P2P网络借贷违约预测方法
2018-01-02蒋翠清王睿雅
蒋翠清,王睿雅,丁 勇
(合肥工业大学管理学院,安徽 合肥 230009)
融入软信息的P2P网络借贷违约预测方法
蒋翠清,王睿雅,丁 勇
(合肥工业大学管理学院,安徽 合肥 230009)
在P2P网络借贷中,预测借款的违约概率是用户信用评价的关键,也是借贷平台与投资者关注的重点问题。由于P2P平台所获取的用户财务信息有限,P2P借款信用评价和违约预测面临新的挑战。本文结合P2P平台的信息特点,提出一种融入软信息的网络借款违约预测方法。首先利用主题模型抽取并量化文本软信息中的相关变量,进而分析不同软信息变量对借款违约的影响关系;其次,设计了一种两阶段的变量选择方法对软硬信息进行组合筛选;最后,引入随机森林算法构建融入软信息的违约预测模型,并结合P2P平台的真实数据进行实证分析。结果表明,在P2P借款的违约预测模型中融入有价值的软信息可以提高预测准确率。
P2P借贷;违约预测;软信息;主题模型;变量选择;随机森林
1 引言
P2P(Peer-to-Peer)网络借贷是借贷双方不经过金融中介机构,直接通过网络平台进行借贷的一种互联网金融模式。近年来,这种借贷模式以其门槛低、收益高、方便快捷等特点迅速发展,逐渐成为小额借贷和民间融资的重要渠道。然而,由于受到网络平台虚拟性和征信体系不健全等多种因素的影响,较传统的金融借贷模式而言,P2P模式面临更大的信用问题和借贷违约风险[1]。因此,对P2P借款人的违约进行有效预测是保证P2P借贷平台稳定发展的关键。
针对P2P网络借贷的违约预测问题,学者们沿用了银行信用评价的相关方法,将借款人的收入、资产、负债、借款金额,以及第三方机构提供的个人信用分(如FICO分)等因素作为违约预测的重要依据[2]。这些因素主要来源于借款人的财务信息,也称为硬信息[3]。然而不同于银行等金融机构,P2P平台的业务相对单一,难以获得充足的硬信息来预测违约概率。研究发现,在P2P网络借贷中,依靠硬信息获得较高信用分的借款人也经常出现违约的情况[4]。因而,完全基于硬信息对网络借贷进行违约预测具有一定的局限性,P2P平台需要从更丰富的用户数据中找寻影响借款违约的关键因素。
P2P用户在进行借款申请、还款等行为时,上传或生成了大量非标准、人格化的数据信息,如人口基本信息、借款描述等。这些信息由P2P平台收集,与用户的还款能力和还款意愿密切相关,也被称为软信息。丰富的软信息为违约预测提供了更多价值因素,可以缓解硬信息不足对违约预测造成的影响。现有研究发现,在缺乏硬信息的情况下,软信息对借贷用户行为的影响作用更加明显[5-6]。Dorfleitner等[5]学者针对借款描述软信息,研究了文本长度、拼写错误率、情感词频率三个因素与P2P借款违约行为之间的关系,取得了一定成果。王会娟等[7]也进行了类似研究,但该类研究仅考虑了某一特定软信息对P2P借款违约的影响作用[8],忽略了多种价值信息的交叉和融合效果。由于软信息通常以文本等非标准形式存在,现有研究主要围绕易于量化的可分类软信息进行违约预测[9],或通过人工标注方法提取出人格、情感等信息展开相关研究[5,7],并没有充分挖掘复杂软信息中的内容特征。
同时,网络平台收集的软信息数目繁杂,信息质量层次不齐,若想利用软信息进行P2P借款违约预测,必须采取有效的信息量化和筛选方法,找出违约预测建模的关键变量。以往的违约预测研究常采用Pearson系数、方差分析(ANOVA)、逐步法(Stepwise)等方法进行变量筛选[10]。这些方法以单变量筛选为主,适用于处理线性相关、数值型的硬信息变量。而软信息大多为相关关系复杂的名词型变量,需要进一步考虑各变量间的相互作用,上述方法难以直接用于软信息变量的筛选,也无法将软信息和硬信息变量有效融合。
针对P2P网络借贷平台的数据特点,本文尝试将软信息融入借款违约预测模型,以解决P2P违约预测中面临的硬信息不足问题。为了保证软信息能够得以有效运用,参考了文本分析方法,对多种软信息进行价值提取和量化,并针对软、硬信息的差异性,提出一种两阶段组合的变量选择方法,有效地将两类信息融入违约预测模型。为了验证本文方法的有效性,基于P2P平台的真实数据进行了实验,并取得了较好的应用效果。
本文内容安排如下:第二节介绍了软信息的分类和量化方法;第三节分为两部分,首先阐述本文提出的软硬信息变量筛选方法,其次介绍基于随机森林的违约预测建模方法。基于真实数据集,在第四节展开实证研究,包括实验设计介绍、软信息量化结果、软信息对借款违约的影响分析、以及模型的预测结果,并进一步做了比较分析。最后在第五节进行了研究总结。
2 软信息的分类与量化
软信息是一类难以量化、检验及传递的非标准信息,常以文本形式存在,其中主观和定性成分较多,具有人格化特征[11-12]。在P2P借贷中,网络平台是借款人信息的收集者,其收集的信息主要包括以下四类:人口基本信息、财务信息、历史信息、借款信息。其中,软信息大多由用户自己向平台提供,涉及借款人的基本信息和借款情况。硬信息则主要来自平台外部或用户在平台上的行为记录,涉及财务信息和历史信息。因此,我们根据P2P平台的信息类型,将软信息划分为两类。
(1)借款人软信息:指借款人的人口基本信息,主要涉及年龄、性别、婚姻状况、教育程度、居住地、职业等,这些信息来源于P2P用户,由网络平台收集并进行分类标记,是最常见的软信息数据。该类信息反映了借款人的人格特征和基本条件,有利于判断借款人的还款能力,以易于分类的文本为主。
(2)借款软信息:指每笔借款的详细情况,主要包括借款类型、借款描述、还款方式等文本类信息。由于不同类型的借款面临的风险程度不同,在违约预测中不仅要考虑用户的信用风险,也要考虑借款自身的风险。对P2P用户而言,每个借款人会针对自己的借款申请做出相应的详细描述,其中涉及借款用途、资产情况、收入能力、社交情况等多种价值信息,间接反映出借款人的借款态度和还款意愿。该类信息通常以文本形式存在,难以直接用于模型建模。
针对难以量化的借款软信息进行重点分析,采用LDA主题模型抽取其中的价值信息,将有效的主题转化为若干个关键词变量并量化赋值。对于具有明显类别区分的文本信息,则直接将其转换为分类变量。
LDA模型是一种非监督的主题模型,其主要思想是将每个文档看作是所有主题的一个混合概率分布,将其中的每个主题看作是单词上的一个概率分布。它由文档集、文档、单词三层组成,模型结构如图1所示。

图1 LDA模型结构图
图1中,参数α反映潜在主题之间的相对强弱,β表示所有潜在主题的概率分布;θ表示目标文本在潜在主题上的概率分布,φ表示主题在单词上的概率分布;T是主题数,z表示该文档分配在每个词项上的潜在主题个数,W 是目标文档的词向量表示,N表示一篇文档中单词的个数,M是文档集中文档的个数。
假设j是一个潜在主题,wi是文档d中的第i个单词,则wi属于主题j的概率为:

(1)
其中,P(wi)表示单词wi在给定文档d中出现的概率,对于任一文档来说是可观测的已知变量;P(wi|zi=j)表示单词wi属于潜在主题j的概率,即φ;P(zi=j)则表示j是文档d的主题概率,即θ;二者分别服从超参数α和β的Dirichlet分布。同理可得出文档d中包含特征词w的概率P(w|d为:
(2)
对θ和φ进行参数估计,建立LDA三层模型。
运用LDA模型对所有文本段落信息进行主题抽取,并构建相应的主题变量;利用模型计算出文本在每个主题上的分布概率,以此度量文本与每个主题的相关程度,并为相应变量赋值。据此生成的主题变量即为相应文本段落信息的量化结果,具体结果见第4节。
3 融入软信息的P2P违约预测模型
借款违约是指借款人在合同规定时间内无法还本付息或履行相关义务,从而使投资者遭受损失。针对借款进行违约预测,主要分为还款能力分析和还款意愿分析。借款人的还款能力可以结合其收入能力、资产/负债情况等硬信息数据,以及借款人软信息进行分析;对于还款意愿,则可以从借款人的历史记录硬信息、借款描述软信息等方面体现。因此,本文在硬信息基础上融入软信息进行建模,丰富P2P借贷违约的预测依据,并设计一种两阶段的变量选择方法对软、硬信息变量进行混合筛选,以保证变量的有效性,提升模型效果。
3.1 软硬信息变量组合选择
量化后的软信息可以与硬信息相结合,直接参与违约预测建模。但是,P2P平台的软信息变量数目繁多且质量参差不齐,其中包含大量与违约情况无关或冗余的变量,这些变量不仅会增加预测模型的训练复杂度,同时还会降低模型精度。软信息变量以名词型变量为主,其与违约变量间大多为非线性关系,因此必须构建一种能够同时处理软信息和硬信息变量的筛选方法,以保证模型的预测效果。
为此,设计了一种先排序再封装的两阶段组合选择方法。首先,将量化后的软信息与硬信息变量混合,利用三种度量标准分别对所有变量进行重要性排序并将排序结果集成;其次,为了保证变量间的组合效用,基于预测模型的精度对混合变量集进行封装筛选,具体步骤如图2所示。
(1)综合排序
信息度量标准是一种无参、非线性的标准,可以很好地量化变量对于类别的不确定性程度,同时处理数值型或名义型变量。以往研究中,卡方检验、Person相关系数等统计值是常用的变量重要性度量标准,用于判定变量间的统计相关性。然而,软信息的数据分布不确定,且变量间存在大量的非线性关系,基于统计相关性的方法难以准确度量软信息变量与违约变量之间的关系。因此,将统计相关性度量标准和信息度量标准相结合,选取卡方统计值、信息增益、信息增益率三类准则分别对变量进行重要性排序,继而对三个排序结果进行投票得出变量最终的综合排序结果。

图2 变量组合选择方法流程图
(2)封装筛选
为了剔除变量集合中的冗余变量,同时保证软硬信息的组合效果,在经过排序的变量集合上进一步进行封装筛选。将集合中的全部变量作为模型的输入变量,以预测准确率来评价该变量集合的整体效用。结合(1)得到的变量排序结果,运用序列后向选择方法(SBS)依次删除排序最低的变量并生成新的变量子集,将变量子集输入模型得到预测精度,并重复上述步骤。比较已有变量集合的预测精度,选出预测效果最优的变量集合作为模型的最终输入变量集。
3.2 违约预测建模方法
违约预测问题通常被视为分类问题,即对违约借款和非违约借款进行二分类[13-14]。机器学习和集成分类模型在违约预测中具有良好的应用效果[15-16],为了很好地解决软信息变量造成的非线性问题,并同时处理数值型和名词型变量,采用基于决策树的集成模型——随机森林算法,构建P2P借贷的违约预测建模型。
随机森林(Random Forest, RF)是一种组合分类方法,是CART决策树算法与Bagging方法的结合。RF利用bootstrap抽样方法从原始样本中抽取多个样本,对每个bootstrap样本进行决策树建模,然后组合多棵决策树的分类结果,通过投票得出最终预测结果。RF方法具有较高的预测准确率,对异常值和噪声具有很好的容忍度,且不容易出现过拟合。RF算法描述如表1所示。

表1 随机森林算法流程

假设元组集合D包含N个类别的记录,那么其Gini指标为:
(3)
其中,pi为D中元组属于类别i的概率,当Gini(D)=0时,D中元组均属于同一类别。Gini指数考虑每个属性的二元划分,当集合D划分成D1和D2,则这个划分的Gini指数为:

(4)
其中,|D|表示D中元组个数。
针对本文的违约情况分类,元组集合包含2个类别记录:违约借款(标记为1)和非违约借款(标记为0)。模型训练结束后,运用测试集进行模型检验,并采用多数投票法决定最终违约分类结果。
4 实证分析
首先对软信息进行量化处理,进而构建回归分析模型,验证软信息变量对借款违约情况的影响关系。其次,基于3.1节提出的特征选择方法,对软信息和硬信息变量进行组合筛选,并在此基础上,构建基于随机森林算法的P2P借款违约预测模型,对软信息变量的预测能力进行检验,并将模型的预测结果与平台自身的评级结果进行比较分析。
本研究以“翼龙贷”平台为例,收集了该平台从2014年1月到2016年1月的借贷记录,从中随机选取了15806条已经还款结束的交易数据作为样本,其中成功还款9006例,存在逾期未还的借款6800例。根据借款的还款状态,我们将违约变量分为两类:成功完成还款的借款即未违约借款,赋值为0,存在逾期未还的借款即发生违约,赋值为1。样本共包含45个属性,剔除无关属性和缺失严重的属性,本研究共选取28个属性作为模型变量,各变量信息如表2所示。
4.1 软信息量化处理


图3 借款描述文本的主题分布
根据主题词分布情况,最终从抽取出的主题中选取6个主题作为借款描述的文本特征,分别是资产、收入、工作、家庭、商业、农业。考虑到文本长度(即文本段落字数)也是重要的语言特征,将其作为借款描述文本的特征之一参与后续分析。最终,借款描述文本共量化为7个变量,如表3所示。
4.2 软信息对借款违约的影响分析
通过构建回归模型来验证软信息变量与P2P借款违约情况之间是否具有相关关系。模型的因变量为违约情况(Default),其中1代表违约,0代表非违约。模型的自变量包括软信息变量和控制变量(Control Variables)。控制变量是借款相关的硬信息变量(A1-A13),软信息变量分为两类:借款人软信息(Borrower Soft Variables,变量A14-A22)和借款软信息(Loan Soft Variables,变量A23-A26)。其中,借款描述文本(A24)经过量化后转换为文本的主题特征变量(T1-T6)及文本长度LEN变量(见表3)。由于模型因变量违约情况(Default)是二分类变量,故采用二元Logistic回归构建模型。为了单独检验软信息变量对借款违约的影响,共构建3个模型,模型1中只包含控制变量,模型2在模型1的基础上加入了借款人软信息变量,模型3在模型2的基础上加入借款软信息变量,具体如下:
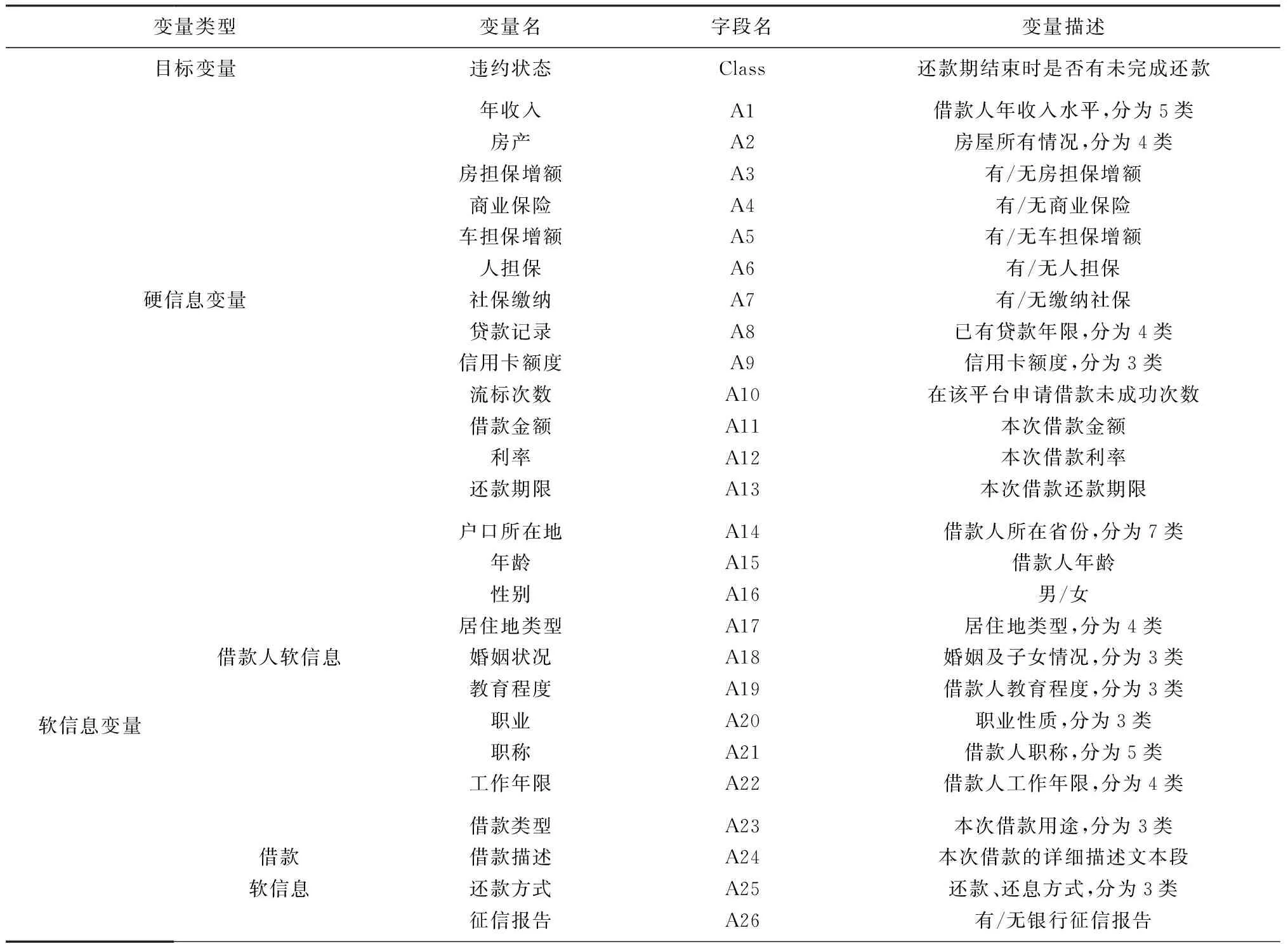
表2 样本数据集变量

表3 借款描述文本的量化结果
模型1:
Logistic(Default1)=αiControlVariablesi+εi
模型2:
Logistic(Default1)=αiControlVariablesi+βiBorroweVariablesi+εi
模型3:
Logistic(Default1)=αiControlVariablesi+βiBorroweVariablesi+γiLoanSoftVariablesi+εi
模型的Logistic回归结果如表4所示。由表可知,在控制变量中,与借款人违约情况显著相关的变量有:年收入、商业保险、信用卡额度、流标次数、利率和还款期限。其中,信用卡额度和借款利率与违约情况呈显著正向相关,其余呈显著负向相关。在模型2中,职称、工作年限与借款违约在1%的水平上显著相关,户口所在地、居住地类型在5%的水平上显著,而职业则在10%的水平上显著。以上5个变量都与借款违约情况呈负向相关。在模型3中,还款方式变量以及从借款描述文本中抽取的主题变量都与违约情况在1%的水平上显著相关,其中,借款描述文本的资产主题和文本长度变量与违约情况负向相关,其余为正向相关。这表明借款描述中涉及的资产描述信息越多,或文本越长,该笔借款发生违约可能性相对较小。反之,若借款人描述的信息中涉及家庭、工作、收入、农业和生意的内容越多,其发生违约的可能性相对更大。通过比较可以看出,加入借款人软信息变量和借款软信息变量后,模型的分类准确率分别提升了3.8%和7.9%,这说明加入软信息后,Logistic回归模型的解释能力有所加强。
为了进一步判断不同类型的软信息对借款违约的影响情况,选取部分样本进行对照实验。同样以硬信息变量为控制变量,根据回归分析结果,与违约呈显著相关的硬信息变量有年收入、商业保险、信用卡额度、流标次数、利率和还款期限,考虑到利率和还款期限与具体的借款金额密切相关,因此不作为对照组的控制变量。实验共设置4组对照组:组1中,年收入水平为12万以下,无商业保险,信用卡额度为0(无信用卡),流标次数为0;组2中,年收入水平为12万以上,其余变量与组1相同;组3和组4的信用卡额度大于0(有信用卡),其余变量分别与组1和组2相同。对各组进行Logistic回归,结果见表5。

表4 Logistic回归分析结果

续表4
注:***、**、*分别表示l% 、5% 、10%的显著水平;表中哑变量只列出显著水平
由表5可以看出,当借款人的年收入处于中低水平时,不使用信用卡的借款人,其教育程度、职称水平与违约情况呈负向相关,即教育水平越高、或职称等级越高,其违约概率越小;使用信用卡的用户,其工作年限与违约情况呈正向相关,同时还款方式也呈现显著相关性。当借款人的年收入水平较高时,使用信用卡的借款人,其违约情况仅与职称水平负向相关;无信用卡的借款人中,用户的职业类型与违约情况呈现显著相关性。另外,从借款描述文本中抽取的主题变量在4组实验中都相对显著,其中“资产”主题和文本长度与违约概率呈负相关,其余为正相关。

表5 违约影响对照实验比较结果
注:表中值为模型系数,***、**、*分别表示l%、5%、10%的显著水平;控制变量结果未置于表中
4.3 借款违约预测建模
基于随机森林模型,构建P2P借款的违约预测模型,并对预测结果展开比较分析。首先验证各类软信息对借款违约的预测能力。将不同类型的软信息变量与硬信息相结合,共设定了4组变量集合进行建模:模型A仅包含硬信息变量;模型B包含硬信息变量与借款人软信息变量;模型C包含硬信息变量与借款软信息变量;模型D包含上述3种变量。这里采用10折交叉验证对模型进行训练和评估,以准确率(Accuracy)、F值(F-mesure)和ROC曲线下面积(AUC)作为模型的评估标准。实验结果见表6。
通过表6可以看出,基于硬信息所构建的模型A,其违约预测的准确率仅为63.58%,AUC值为0.664;在此基础上分别加入有关借款人和借款的两类软信息后,模型B和模型C的准确率对应上升了8.96%和10.65%,AUC分别提升了0.125和0.154。若同时添加两类软信息,即模型D,其准确率达到了76.02%,AUC为0.837,显著高于前三者。同时,在借贷违约预测中,P2P平台更关注能否识别出可能发生违约的借款(能否识别出违约变量1),因此我们对4个模型的第二类错误率做了进一步比较。基于硬信息构建的模型A,其第二类错误率高达0.521,而加入软信息变量后,模型D的错误率下降为0.329。可以看出,融入了P2P平台软信息可以有效提高违约预测的准确率,同时能够更好地识别出可能发生违约的借款,具有良好的实用性。

表6 模型预测结果
其次,为保证模型结果的有效性,采用3.1节提出的两阶段组合方法对软信息和硬信息进行变量筛选。结合卡方统计值、信息增益、信息增益率三种准则对所有变量进行重要性排序,并对结果进行投票,得到变量重要性的综合排序。将排序后的变量集进行封装筛选,考虑到随机森林是决策树的组合模型,基于森林的封装方法复杂度过高,因此,选择CART决策树作为变量重要性的评价模型。变量排序和筛选结果见表7。通过排序结果可以看出,经过量化的软信息变量在所有变量中具有较高的重要性,软信息与借款人的违约行为存在较强的相关关系。

表7 软信息和硬信息变量排序和筛选结果
本文选取Hajek等[10]、Malekipirbazari和Aksakalli[5]等在研究中提到的相关性选择方法(CBF)、信息增益选择方法(IG),以及卡方统计分析方法,作为对比方法。实验以融入软信息后的全部变量为初始变量集合,以RF算法为分类模型,比较基于不同变量选择方法构建的分类模型准确率,结果如图4所示。
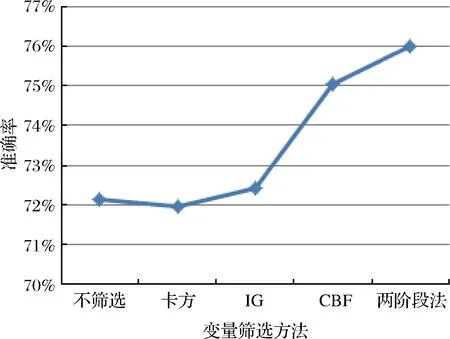
图4 变量选择方法比较结果
图4展现了不同变量选择方法对模型准确率的影响程度。在融入软信息变量后,不经过变量筛选而直接构建的模型,其分类准确率为72.14%;基于卡方检验筛选出的变量,其相应的模型准确率反而下降至71.96%,可见基于单一的统计检验值不仅没能选出有效的变量集,反而剔除了部分有用变量。基于信息增益方法的模型准确率也仅为72.41%,效果并不明显。结果表明,CBF方法和本文提出的两阶段法对融入软信息的变量集合来说效果较好,准确率分别为75.05%和76.02%,本文的方法效果更优。通过比较可以看出,本文提出的两阶段选择法更适用于融入了软信息的变量集,从中筛选出相对有效的变量集合。
最后,将本文构建的借款违约预测模型所得到违约预测结果与P2P平台自身的信用评级结果进行了进一步比较。该平台的用户信用等级共分为15级,首先我们选定拟接受借款的信用等级,计算出相应的借款接受比例阈值,进而在相同阈值下,根据RF模型生成的分数找出拟接受的借款,计算并比较两者的错误率,即拟接受借款中实际发生违约的借款比例。比较结果如图5所示。
当借款接受率较低时,利用平台信用等级选出的拟接受借款,其违约率高达30%;仅利用硬信息构建的模型A所选出的拟接受借款,违约率为18%;在此基础上分别加入有关借款人和借款的两类软信息后,模型B和模型C的违约率分别为10%和5%。而综合考虑软硬信息(模型D)所选出的拟接受借款,违约率仅为4%。随着接受比例的升高,两者选出的借款违约率逐步上升,但基于本文模型选出的拟接受借款,错误率明显低于前者。同时,综合考虑借款人和借款软信息的借款违约预测模型在各个贷款接受率下的错误率均为最低。这表明平台现有的信用评级方法难以准确识别借款人的违约情况,而使用本文方法对P2P借款进行违约预测则更为有效。

图5 预测错误率比较
5 结语
随着P2P网络借贷的兴起,借款违约成为制约P2P模式发展的重要因素。针对P2P借贷平台在违约预测中面临的硬信息缺乏问题,提出将软信息融入借款违约预测模型,以提高P2P借款违约预测的准确率。首先,对与违约行为有关的软信息进行了分类讨论,并采用主题建模方法对非标准化的文本软信息进行量化处理。其次,针对软信息与硬信息的差异性,设计了一种适用于软、硬信息的两阶段变量选择方法,从而为预测模型筛选出有效的变量集合。最后,运用随机森林算法,构建了借款违约预测模型,并进行了实证研究,结果表明,将P2P平台中有价值的软信息融入违约预测模型能够明显提高预测准确率;同时,所提出的两阶段变量选择方法能够很好地应用于软信息与硬信息的融合建模。
本文重点围绕与借款有关的文本类软信息进行分析,然而P2P平台还可以收集用户的社交关系等多种非标准化数据,如何从更丰富的软信息中提取影响借款违约的关键因素有待进一步研究。
[1] Pope D G, Sydnor J R. What's in a picture?: Evidence of discrimination from prosper.com[J]. Journal of Human Resources, 2011, 46(1):53-92.
[2] Michels J. Do unverifiable disclosures matter? evidence from peer-to-peer lending[J]. Accounting Review, 2012, 87(4):1385-1413.
[3] Emekter R, Tu Y. Evaluating credit risk and loan performance in online peer-to-peer (P2P) lending[J]. Applied Economics, 2015, 47(1):54-70.
[4] Angilella S, Mazzù S. The financing of innovative SMEs: A multicriteria credit rating model[J]. European Journal of Operational Research, 2015, 244(2):540-554.
[5] Malekipirbazari M, Aksakalli V. Risk assessment in social lending via random forests[J]. Expert Systems with Applications, 2015, 42(10):4621-4631.
[6] Dorfleitner G, Priberny C, Schuster S, et al. Description-text related soft information in peer-to-peer lending - Evidence from two leading European platforms[J]. Journal of Banking & Finance, 2016, 64:169-187.
[7] 刘征驰, 赖明勇. 虚拟抵押品、软信息约束与P2P互联网金融[J]. 中国软科学, 2015,(1):35-46.
[8] 王会娟, 何琳. 借款描述对P2P网络借贷行为影响的实证研究[J]. 金融经济学研究, 2015,(1):77-85.
[9] Gao Q, Lin M. Linguistic features and peer-to-peer loan quality: A machine learning approach[R]. Social Science Electronic Publishing, 2013.
[10] Cubiles-De-La-Vega M D, Blanco-Oliver A, Pino-Mejías R, et al. Improving the management of microfinance institutions by using credit scoring models based on Statistical Learning techniques[J]. Expert Systems with Applications, 2013, 40(17):6910-6917.
[11] Hajek P, Michalak K. Feature selection in corporate credit rating prediction[J]. Knowledge-Based Systems, 2013, 51(1):72-84.
[12] Petersen M A. Information: Hard and soft[R].Working paper, Northwestern University, 2004.
[13] 陈庭强, 何建敏. 基于复杂网络的信用风险传染模型研究[J]. 中国管理科学, 2014, 22(11):111-117.
[14] Lessmann S, Baesens B, Seow H V, et al. Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research[J]. European Journal of Operational Research, 2015, 247(1):1-32.
[15] 衣柏衡, 朱建军, 李杰. 基于改进SMOTE的小额贷款公司客户信用风险非均衡SVM分类[J]. 中国管理科学, 2016, 24(3):24-30.
[16] Finlay S. Multiple classifier architectures and their application to credit risk assessment[J]. European Journal of Operational Research, 2011, 210(2):368-378.
[17] Kruppa J, Schwarz A, Arminger G, et al. Consumer credit risk: Individual probability estimates using machine learning[J]. Expert Systems with Applications, 2013, 40(13):5125-5131.
The Default Prediction Combined with Soft Informationin Online Peer-to-Peer Lending
JIANGCui-qing,WANGRui-ya,DIGNYong
(School of Management, Hefei University of Technology, Hefei 230009,China)
P2P lending is a new type of loan mode formed by the intersection of Internet and traditional finance. It provides a more convenient loan platform and has been developing rapidly in China.However, the phenomenon of collapse in P2P is getting worse as P2P loans is facing default risk and bad debt losses seriously. Credit evaluation is an important basis for managing loan default risk and supporting lending decision. Compared with traditional loans, the financial data of borrowers collected by P2P platform is limited, which is also called the hard the information.However,there is lots of soft information generated during the loan application, such as loan description text,also involving some information about loans and borrowers. Therefore, a default prediction method combined with soft informationfor P2P lending is proposed. Firstly, the soft information is categorized according to the characteristics of P2P, and the LDA topic model is used to quantify valuable factors in the text of soft information. Secondly, some regression analysis and contrast experiments are performed to test the effect of soft information on P2P default probability. Moreover, a two-stage method is designed to selecteffective variablesets for default modeling, and the default prediction model is constructed through the random forest (RF) method.Finally, based on the data from a Chinese P2P platform—eloan.com, an experimental research is conducted to verify the effectiveness of methods we proposed.The results show that the soft information can improve the recognition rate of loan default, which can be used as the basis of P2P credit evaluation. The feature combination selection method proposed in this paper and the credit evaluation model based on Random Forest have achieved good classification accuracy.And the proposed method can improve predictionperformancesobviously compared withthe platform's own rating method, which has certain reference significance for the credit evaluation of P2P network lending.
P2P lending; default prediction; soft information; topic model; variable selection; RF model
1003-207(2017)11-0012-10
10.16381/j.cnki.issn1003-207x.2017.11.002
F832.4
A
2016-07-06;
2017-04-20
国家自然科学基金资助项目(71731005,71571059)
王睿雅(1992-),女(汉族),安徽合肥人,合肥工业大学管理学院,硕士研究生,研究方位:大数据分析、信用评价,E-mail:wrylr@163.com.
