基于代码结构信息和历史缺陷报告软件缺陷定位研究
2017-10-12刘艾侠刘丹丹宝鸡职业技术学院宝鸡7203中国科学院大学北京00039中国科学院国家授时中心西安70600
刘艾侠, 刘丹丹(. 宝鸡职业技术学院, 宝鸡 7203; 2. 中国科学院大学, 北京 00039;3. 中国科学院 国家授时中心, 西安 70600)
基于代码结构信息和历史缺陷报告软件缺陷定位研究
刘艾侠1, 刘丹丹2,3
(1. 宝鸡职业技术学院, 宝鸡 721013; 2. 中国科学院大学, 北京 100039;3. 中国科学院 国家授时中心, 西安 710600)
静态缺陷定位通常采用信息检索的方法,现有的信息检索方法一般采用源代码与缺陷报告的文本相似性的排序方法,但是这种基于文本相似性的方法没能充分利用源代码结构信息,缺陷定位的准确率较低。为了解决这个问题,提出了一种基于源代码结构信息(如类名、方法名、变量名、注释等)和历史缺陷报告信息进行缺陷定位的方法。对于源代码结构的不同部分,在与缺陷报告进行词语匹配时,赋予它们不同的权重,同时充分利用历史缺陷报告信息,提高缺陷定位的精度。最后为了验证基于代码结构信息的缺陷定位技术的有效性,与以前提出的BugLocator、BugScout等方法进行了比较,结果表明基于代码结构信息的软件缺陷定位方法比BugLocator和BugScout方法准确度有明显提高。
代码结构; 缺陷定位; 缺陷报告; 历史缺陷报告
Abstract: Static bug localization method commonly uses information retrieval method to locate bug. Existing information retrieval methods generally use text similarity between the source codes and bug reports, but the text similarity method fails to make full use of the source code structure information, and has low accuracy. In order to solve this problem, this paper presents a bug localization method using source code structure (such as the class name, method names, variable names, comment etc.) and historical bug report information. When different parts of the source code structure match the bug report, they are given different weights. The paper also makes full use of the historical bug report information to improve the accuracy of bug localization. Finally in order to validate the method, this paper is compared the proposed method with BugLocator and BugScout, the results show that software bug localization method based on source code structure has significant advantage than the BugLocator and the BugScout.
Keywords: Code structure; Bug localization; Bug report; Historical bug report
0 引言
软件缺陷(bug)是影响软件质量的重要因素之一,缺陷的存在经常导致系统的失效和崩溃,给系统的可信运行带来挑战[1]。近年来,缺陷定位技术受到诸多国内外学者广泛研究,并已经取得了较为显著的结果。现今缺陷定位技术主要分为三类,静态缺陷定位技术[2]和动态缺陷定位技术[2]以及动静结合的缺陷定位技术[3]。静态缺陷定位通常使用文本信息检索技术来比较缺陷报告和源代码文件之间的相似性,如常用的向量空间模型和隐性语义索引等。信息检索技术从程序源代码中抽取文本,然后计算与缺陷报告之间的文本相似性,相似性越高意味着源代码文件和缺陷报告关联的嫌疑度越大[4]。但是,现有的信息检索技术仅仅把源代码视为一种普通文本,没有考虑代码文件中的结构信息,如果能充分利用这些结构信息,就可以进一步提高缺陷定位的精度[5]。本文认为一个缺陷报告通常是一个或多个类的代码错误引起的,与通常的文本相似性匹配不同,本文直接分析类与缺陷报告的相似性,研究源代码结构信息对缺陷定位的影响,利用了源代码不同的结构信息、文本信息与缺陷报告之间的相似性,并在其中加入了权重的因素,使其可以根据不同情况进行动态调整。另外,还考虑了用不同缺陷报告之间的文本相似性,来进一步提高定位精准度。
1 基于代码结构的缺陷定位模型
现有的基于信息检索的缺陷定位方法仅仅把源代码视为一种缺乏结构的普通文本,没有考虑代码文件中的结构信息[6]。事实上,源代码丰富的结构如类名、方法名、变量名和注释等有着重要的作用。虽然忽视这些结构能简化缺陷定位运算,但是也失去了用结构化信息提高缺陷定位的机会。源代码丰富的结构,包、类、属性、方法、注释之间有明确的结构关系,而这些结构信息对于缺陷定位有重要价值,可以帮助开发者提高缺陷定位精度[7]。通常这些重要的信息经常迷失在大量的变量名和注释词语中。
为了提高定位精度,本文提出需要充分利用代码结构信息和历史缺陷报告信息进行缺陷定位。缺陷定位流程,如图1所示。

图1 缺陷定位流程
首先提取软件系统中java源代码文件;运用Eclipse AST抽取java文件中的类名、方法名、变量名和注释,同时进行预处理去除注释中的无用停止词等,然后把这些标识符组成源代码的XML结构化文件;获取新的缺陷报告,提取缺陷报告的摘要和内容,并对其进行预处理;将源代码的XML结构化文件和缺陷报告进行结构化相似匹配运算,并进行加权,这一步称为源代码结构化的软件缺陷定位;获取历史缺陷报告,将新缺陷报告与历史缺陷报告进行VSM相似性计算,获取每一个源代码文件所关联的历史缺陷报告与新缺陷报告VSM相似性最大值作为利用历史缺陷报告进行缺陷定位的相似性分数;将源代码结构化的缺陷定位分数和利用历史缺陷报告进行缺陷定位得出的分数进行加权,进行最终的缺陷定位计算。
2 缺陷定位模型算法设计
(1) 构建源代码中类的XML文档
对源代码使用Eclipse中的JDT技术构建抽象语法树(AST),通过抽象语法树来提取程序结构如:类名、方法名、变量名和注释,对注释内容进行去除停止词等预处理,每个源代码文件的信息储存为一个XML结构化文档[8]。
(2) 源代码结构化缺陷定位计算
为了分析某个源代码文件与缺陷报告之间的结构化相似度,本文先获取一个新的缺陷报告。本文先对缺陷报告进行去除停止词等预处理后,然后用每个源代码文件的结构化信息内容(Class Name,Method Name,Variable和Comment)中的4部分分别对缺陷报告进行词语匹配,统计出现的次数,如表1所示。

表1 源代码结构化信息与缺陷报告词语匹配次数
缺陷与代码结构化相似度计算式,如式(1)。
(1)
其中a,b,c,d分别表示类名、方法名、变量名和注释的权重,通过调整模型中的权重,就可以改变类名、方法名、变量名和注释在缺陷定位时所占的重要性。
给定一个缺陷报告,使用公式(1)中的StructScore计算每个源代码文件和缺陷报告之间的相关分数,根据分数由高到低得出相关源代码文件的排名列表。
(3)历史缺陷报告信息的运用
每个历史缺陷报告关联着若干源代码文件,如果新缺陷报告与历史缺陷报告相似度较高,那么历史缺陷报告关联的源代码文件就有可能是需要定位的缺陷文件。为充分利用历史缺陷报告信息,对于一个新的缺陷报告,本文提出利用该报告与历史缺陷报告的相似性来调整相关源代码文件的排名。这里利用VSM来计算缺陷报告之间的相似性。在VSM中,每个处理后的缺陷报告被作为一个n维向量,n是出现在缺陷报告中词语的个数,wi是n维向量中第i个词语的权重。一个词语t在文档d中的权重可以用式(2)计算。
(2)
其中t表示词语,d表示一个缺陷报告,e,是词语t出现在d中的次数,N是缺陷报告总数,nt是含有词语t的缺陷报告总数,缺陷报告之间的相似性得余弦式(3)。

(3)
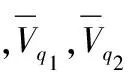
(4) 最终缺陷定位计算
对StructScore和SimiScore进行加权组合,得出一个源代码文件总分数如式(4)。
FinalScore=(1-k)×StructScore+k×SimiScore
(4)
其中k是权重参数,它的范围在0~1之间,参数k根据多次实验,选取最优值。源代码文件按照FinalScore分数,由高到底递减排列,源代码文件排的越高,越是有可能和缺陷报告相关性大。
3 测试分析
本文在实验过程中,使用NetBeans作为开发工具。为了研究使用代码结构化信息和历史缺陷报告信息是否能提高缺陷定位的精确度,本文选取了Eclipse开源项目作为测试集,并且Eclipse的版本和BugLocator方法中Eclipse的版本相同,以便进行比较。Eclipse3.1数据集总共包含了3075个缺陷报告,为Eclipse项目数据集,如表2所示。

表2 Eclipse项目数据集
本文选取了一部分缺陷报告作为历史缺陷报告,以便进行实验。
本文用StructLocato表示本文的源代码结构化缺陷定位方法[8],用StructSimiLoactor表示源代码结构化和历史缺陷报告相结合的方法。对于式(1)中a,b,c,d权重的取值,本文经过一部分实验,选取了其最优取值a=0.6,b=0.2,c=0.1,d=0.1。由于本文和BugLocator[9]使用了相同的Eclipse数据集,因此可以和BugLocator做比较。经过大量实验后,本文获得了源代码文件的前N排名,并计算出了MAP和MRR的值。如表3、表4所示。表3、表4中BugLocator方法的数据来自于他们的论文中。表3显示了使用BugLocator方法和本文的StructLocator方法的缺陷定位比较,由于没有加入历史缺陷报告相似性,所以k=0。实验结果显示StructLocator方法比BugLocator方法能定位更多缺陷。例如,对于Eclipse,使用StructLocator方法返回的相关源代码文件位于Topl的缺陷报告数目占总数的29.4%,而使用BugLocator方法定位到的缺陷报告仅仅只有24.4%,Top5和Top10也有类似的趋势,StructLocator方法的MAP和MRR数值(MAP=0.29,MRR=0.40)要高于BugLocator的MAP和MRR(MAP=0.26,MRR=0.35),表明在Eclipse中StructLoactor方法的缺陷源文件的整体排名比BugLocator的高。

表3 没有使用历史缺陷报告下的实验对比
表4显示了使用BugLocator方法和本文的StructSimiLoactor方法的缺陷定位比较,经测试比较,本文选取k权重因子为k=0.2。对于Eclipse的测试结果:
1) 在Topl中,使用StructSimiLoactor方法定位的缺陷报告占总数的32.7%而使用BugLocator方法定位的缺陷报告只占29.1%
2) 在Top5中,使用StructSimiLoactor方法定位的缺陷报告占56.0%,而使用BugLocator方法定位的缺陷报告只占53.8%}
3) 在Top10中,使用StructSimiLoactor方法定位的缺陷报告占65.3%,而使用BugLocator方法定位的缺陷报告只占62.6%
4) StructSimiLoactor方法的MAP和MRR数值分别是MAP=0.32}MRR=0.43而BugLocator的MAP和MRR数值分别是MAP=0.30}MRR=0.410
以上数据表明在Eclipse中StructSimiLoactor方法的缺陷源文件的整体排名比BugLocator的高。

表4 StructSimiLoactor和BugLocator的实验对比
本文也同BugScout做了比较[10],如图2所示。

图2 在Eclipse中不同的缺陷定位方法对比
Nguyen等人使用了Eclipse数据集作为他们的实验项目的一部分来评测BugScout,由于本文的Eclipse数据集和BugScout中Eclipse的版本不同,本文只列出了BugScout在Topl、Top5、Top10的概率。从图2中可以看出:
1) 在Topl的位置,3个方法的缺陷定位概率大小比较是:
StructSimiLoactor>Buglocator>BugScout。
2) 在Top5和Top10的位置也有1)中类似的趋势。
以上数据表明,StructSimiLoactor比Buglocator和BugScout表现出色。
4 总结
本文提出了使用源代码结构化信息(如类名、方法名、变量名、注释等)来提高缺陷定位的方法,本文将源代码文件结构的不同部分分别与缺陷报告进行匹配,对每一部分赋予不同的权值,然后进行加权求和,获得源代码结构化的缺陷定位。为了更好的提高缺陷定位的精度,本文还充分利用了历史缺陷报告信息。对历史缺陷报告和新缺陷报告进行VSM相似性计算,将每个源代码关联的所有历史缺陷报告分别与新缺陷报告进行相似性计算,将相似性计算的最大值作为这个源代码文件的利用历史缺陷报告的缺陷定位分数。将源代码结构化的缺陷定位和利用历史缺陷报告的缺陷定位分别赋予不同的权值,进行加权组合,获得最终的缺陷定位排名。最后对于所有的源文件,排名最高的文件嫌疑度最大。
[1] National Institute of Standards and Technology(NIST). Software Errors Cost U. S. Economy $59. 5 Billion Annually[R], June 28, 2002.
[2] 梁成才, 章代雨, 林海静. 软件缺陷的综合研究 [J]. 计算机工程, 2006, 32(19):88-90.
[3] 古可, 刘超, 金茂忠, 等. C++代码缺陷自动检测工具的研究与实现[J]. 计算机应用研究, 2009, 26(5):1628-1631.
[4] 丁晖, 陈林, 钱巨, 等.一种基于信息量的缺陷定位方法[J]. 软件学报, 2013, 24(7):1484-1494.
[5] 赵磊, 王丽娜, 高东明,等. 基于关联挖掘的软件错误定位方法[J]. 计算机学报, 2012, 35(12):2529-2539.
[6] Moreno L, Bandara W, Haiduc S, et al. On the Relationship between the Vocabulary of Bug Reports and Source Code[C]// 2013 IEEE International Conference on Software Maintenance. IEEE Computer Society, 2013:452-455.
[7] 梁广泰, 王千祥. CODAS:一个易扩展的静态代码缺陷分析服务[J]. 软件学报, 2012, 39(1):14-17
[8] 陈翔, 鞠小林, 文万志, 等. 基于程序频谱的动态缺陷定位方法研究[J]. 软件学报, 2015, 26(2):390-412.
[9] Poshyvanyk D, Uueheneuc Y G, Marcus A, et al. Feature Location Using Probabilistic Ranking of Methods Based on Execution Scenarios and Information Retrieval[J]. IEEE Transactions on Software Engineering, 2007, 33(6):420-432.
[10] Manning C D, Raghavan P, Schiatze H. Introduction to information retrieval[J]. Citeseer, 2008, 43(3):824-825.
ResearchofSoftwareDefectPositioningBasedontheCodeStructureInformationandHistoryDefectReport
Liu Aixia1, Liu Dandan2,3
(1. Baoji Vocational Technology College, Baoji 721013, China; 2. University of Chinese Academy of Science, Beijing 10039, China; 3. National Time ServiceCenter, Chinese Academy of Science, Xi’an 710600, China)
TP311
A
2017.06.26)
刘艾侠(1982-),女,陕西周至人,硕士,讲师,研究方向:计算机技术。 刘丹丹(1983-),女,河南焦作人,硕士,助理研究员,研究方向:计算机软件设计。
1007-757X(2017)09-0047-03
