基于HotRank算法的非结构化数据检索技术的研究
2017-08-16任小娟
任小娟
(山东英才学院信息工程学院,山东济南250104)
基于HotRank算法的非结构化数据检索技术的研究
任小娟
(山东英才学院信息工程学院,山东济南250104)
随着海量非结构化数据的出现,关键词检索的方式逐渐不能满足用户的需要,为了提高检索的准确率,故提出使用HotRank算法来进行解决,并用实验证明之。
非结构化数据;数据检索;关键词检索;HotRank算法
1 背景
近年来,随着移动互联网、物联网、社交网络等技术和应用的兴起,全球范围内数据量迅猛增长。据IDC的研究报告称,到2020年,全球数据使用量预计暴增44倍,将达到35.2ZB,即全球大概需要376亿个1TB硬盘来存储数据。
数据有结构化、半结构化和非结构化之分。结构化数据是指能够用二维关系表达的数据;半结构化数据是指XML、网页这类具有一定结构的数据;而非结构化数据其数据结构不固定,无法使用关系数据库存储,只能以各种类型的文件形式来存放,它涵盖多种数据类型,包括办公文档、各类报表、企业日志、客服/聊天记录、邮件、医生的诊断书、图像和音频/视频等。据统计,企业中20%的数据是结构化的,80%的是非结构化或半结构化的。结构化数据检索的技术已经成熟,对此企业能够将其进行深度挖掘,再将决策信息反作用于企业,企业深得其利。反观占相当比重的非结构化数据却只能被束之高阁,鲜少有人问津,即便是具有钻石一样的价值也难以发挥出它的光芒。企业做决策,除了分析企业内部信息外,外部数据更加必不可少,而这些外部数据对企业来说都是非结构化数据。有数据表明,58%的企业高管在进行商业决策时要依赖于非结构化数据分析,而这个数字随着信息化程度的提升会更高。可见,非结构化数据对企业来说是何等的重要!
2 非结构化数据检索
非结构化数据管理通常包括建立模型、存储、检索、分析、应用等多个方面,企业的全文检索流程图如图1所示。这些非结构化数据如PPT、flash文件、音频视频等,有员工自己创建的,也有来自合作伙伴的邮件,还有从网络下载的,等等。非结构化数据累积地越来越多,想从中搜索到自己需要的文件,有时需要经过多次搜索才能找到,有时还需要手工逐个文件去查找,很耗费时间。搜索过程中我们最常用的方法就是使用关键词检索,它的优点是关键词自己设置,符合普通个人用户习惯,但同时也存在一定的弊端。下面以医院系统中怀孕产检项目为例来说明,如果想要检索与“孕前检查”相关的所有文档,那么就需要输入关键词“孕前检查文档”进行检索,只要文件名中含有“孕前检查文档”类似的文字,那么它就会出现在检索结果中。但也有可能会出现因关键词不完全匹配,从而使得比较重要的数据而且是用户所需要的数据没有搜索到。而且仅凭关键词检索还无法明了用户的想法,因此提供的检索结果极有可能准确度偏低,致使用户不满意。为了能够提高非结构化数据的检索效率和准确率,而且满足用户的需求,我们特提出HotRank算法来解决这个问题。

图1 非结构化数据全文检索流程
3 HotRank的定义和算法描述
3.1 HotRank的定义
为了表征信息单元被关注的程度,我们将对所收集的媒体信息进行相似任务聚类,并根据用户的搜索行为与近期进行的任务来计算其热度,作为搜索结果排序的依据,我们把这个算法称作HotRank。它的基本思想是:用户查询时,先使用关键词检索得到初始检索结果;再将得到的检索结果的任务属性与获取到的用户近期任务列表中的任务属性进行相似度对比;之后再计算访问次数和使用时长数据,根据设置的权重参数数据,计算出数据热度,以此将检索结果重新排序输出。其流程图如图2所示。
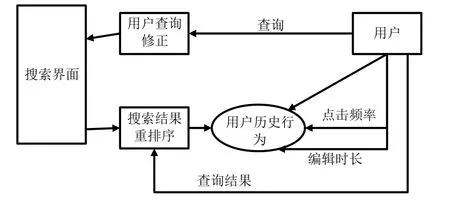
图2 用户搜索的基本流程图
3.2 算法描述
要想计算任务属性的相似度,过程如下:通过记录用户近期访问过的文件的集合Fn,每个文件均具有任务属性,用向量表示为fTask(ftask1,ftask2,…ftaskn),其中ftaskn是任务属性标记;由fTask来构建近期访问的任务向量recentTask=(rtask1, rtask2,…rtaskn),其中rtaskn代表每个任务。向量Query=(k1, k2,…kn),其中kn代表査询关键词。关键词提交后,系统进行初次检索,用InitF表示初始检索结果集,taskNum、accessNum和usetimeNum分别代表任务数,访问数和使用时长数,按照一定的权重数值进行综合计算热度,最后按照数据热度值将检索结果重新排序。其数据热度的算法如下:设simillar(fileTask,re⁃centTask)是文件fx任务属性和近期任务向量属性的相似度,则有:
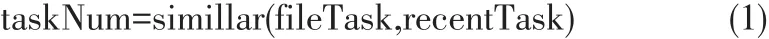
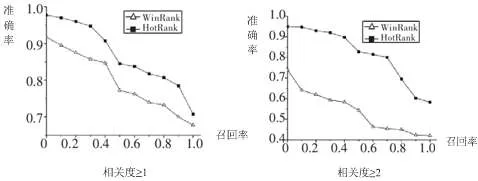
设文件fx的访问次数为ax,A={am|0 设文件fx的使用时长为utx,UT={utm|0 数据热度可表示为: 其中,m、n、q1、q2、q3是各个Num在计算热度时的权重值。 为了充分展示HotRank算法的优点,本实验特地采用对比的方式来进行。先是采用windows系统自带的search搜索功能(其实就是关键词检索)获得初步的检索结果,然后在此结果的基础上采用HotRank算法对任务数、访问频率和使用时长等参数进行度量,计算出热度,从而对检索结果进行重新排序。本实验从两个不同的领域着手进行,选取300条数据(每个检索的结果都超过10条,我们选取前10条)进行实验,根据不同的相关程度,从准确率和召回率两个角度来评估,得出实验结果,如下图图3所示。很明显,HotRank算法的准确率比windows search要高,从而验证采用HotRank算法重新排名的方法可行。 图3 P-R图 本文提出采用重排名算法HotRank,考虑了访问次数、使用时长等相关因素,更加能够满足用户的要求,也能使非结构化数据在检索的时候提高准确率。由于计算结果比较依赖于各因素的权重比例,如果比例设置一旦出现偏差,那么检索结果也会受其影响,因此找出一个最优的比例数据是下一步的研究工作中要进行的。 [1]韩晶,宋美娜,鄂海红,等.HotRank:热度敏感的非结构化数据[J].计算机应用研究,2013,30(5):1306-1308. [2]罗学礼.电力企业的非结构化数据检索研究[J].计算机与数字工程,2014,4(294):729-733. [3]徐树振.企业非结构化数据检索研究[J].信息技术,2014(4): 196-200. [4]陆铭.WEB2.0网络热点发现与个性化检索研究[D].合肥:中国科技大学,2012. [5]韩晶.大数据服务若干关键技术研究[D].北京:北京邮电大学,2013. Study on the Technology of Unstructured Data Retrieval Based on HotRank Algorithm REN Xiao-juan With the emergence of massive unstructured data,keyword retrieval way gradually cannot meet the needs of users,in order to improve the accuracy of retrieval,the proposed HotRank algorithm is used to solve,and the experimental results proves it. unstructured data;data retrieval;keyword retrieval;HotRank algorithm TP311 A 1009-3044(2017)19-0173-02 2017-05-16 山东省统计局课题(课题号:KT16140) 任小娟(1976—),副教授,硕士,研究方向为软件工程、数据挖掘等。
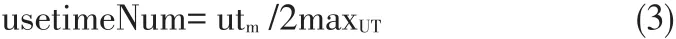
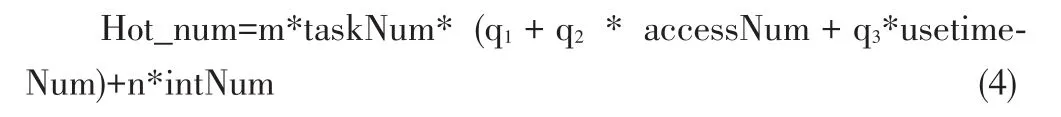
4 实验过程及分析
5 结束语
(School of Information Engineering,Shandong Yingcai University,Jinan 250104,China)
