基于Q学习和TD误差的传感器节点任务调度算法
2017-05-15徐祥伟魏振春
徐祥伟, 魏振春, 冯 琳, 张 岩
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
基于Q学习和TD误差的传感器节点任务调度算法
徐祥伟, 魏振春, 冯 琳, 张 岩
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
针对现有合作学习算法存在频繁通信、能量消耗过大等问题,应用目标跟踪建立任务模型,文章提出一种基于Q学习和TD误差(Q-learning and TD error,QT)的传感器节点任务调度算法。具体包括将传感器节点任务调度问题映射成Q学习可解决的学习问题,建立邻居节点间的协作机制以及定义延迟回报、状态空间等基本学习元素。在协作机制中,QT使得传感器节点利用个体和群体的TD误差,通过动态改变自身的学习速度来平衡自身利益和群体利益。此外,QT根据Metropolis准则提高节点学习前期的探索概率,优化任务选择。实验结果表明:QT具备根据当前环境进行动态调度任务的能力;相比其他任务调度算法,QT消耗合理的能量使得单位性能提高了17.26%。
无线传感器网络(WSNs);传感器节点;任务调度;Q学习;TD误差;协作机制
目前,无线传感器网络(wireless sensor networks, WSNs)广泛应用于军事、环境监测、医疗等领域[1]。合理使用传感器节点受限资源并获得较高应用性能是WSNs研究的关键问题[2]。有效的任务调度机制是解决上述问题的合理途径[3-5]。在目标跟踪应用中,传感器节点根据当前状态和邻居信息动态调度探测、接收、发送、睡眠等任务[4,6],合理使用受限资源,提高应用性能。
传感器节点通常处于动态变化的WSNs中,节点应该根据当前变化环境进行动态任务调度[3-5]。目前,强化学习方法已经被用于研究传感器节点的动态任务调度问题。文献[3]提出了基于独立Q学习(independent Q-learning, IQ)的任务调度框架,将节点映射成Agent,定义状态空间、延迟回报等学习元素,根据ε-greedy方法进行任务选择。文献[4]提出了基于合作Q学习(cooperative Q-learning, CQ)的任务调度算法,使得节点在评估Q值时加权考虑邻居节点的状态值函数进行合作学习,以目标跟踪应用验证CQ比IQ获得更高应用性能。此外,文献[5]研究了目标跟踪应用的任务调度问题,定义基本学习元素,提出基于独立SARSA(λ)学习(independent SARSA(λ)-learning, IS)的任务调度算法,合理使用受限资源。
在多Agent强化学习中,联合动作学习机制存在动作维数灾难、频繁通信等问题[7],不适合大规模部署的WSNs。IQ、CQ和IS均为独立动作学习机制[7],只考虑自身状态空间和动作空间。IQ和IS只注重个体利益,不考虑群体利益。CQ使得节点考虑邻居节点集合的状态值函数进行合作学习,注重个体和群体利益的平衡,但是节点每次调度任务后都发送状态值函数至邻居节点集合,节点间频繁的通信容易导致节点不能正常完成应用的功能性工作、通信负载压力较大、能量消耗较大等问题。
针对CQ合作学习时存在通信频繁的问题,本文提出一种基于Q学习和TD误差(Q-learning and TD error, QT)的传感器节点任务调度算法。在协作机制中,QT结合群体TD误差和WSNs特性,使得节点可以通过降低学习速度来参与群体的协作学习。在探索和利用策略中,QT根据Metropolis准则提高节点学习前期的探索概率,优化任务选择。实验结果表明:QT具备根据当前环境进行动态调度任务的能力;QT消耗合理的能量获得较好的单位性能,可以提高节点的能源利用率。
1 模型的建立
1.1 任务模型
本文以目标跟踪为应用建立任务模型。定义WSNs是由n个同质传感器节点i(i1,i2,…,in)构成的。每个节点ij(1≤j≤n)包括位置坐标p(xj,yj)、睡眠时间tsleep、探测半径rj、邻居半径cj及cj内的邻居节点集合neigh(ij)等属性。假设各个任务不可抢占,且均为原子任务,具体定义如下:
(1) 睡眠。将探测模块、通信模块、计算模块等置于睡眠模式,节省节点能量消耗。
(2) 跟踪目标。持续跟踪探测半径rj内的移动目标m,获得探测包,添加至发送队列。探测包包括的属性为标识、坐标{x,y}、起始时间t和方向dir。假设各移动目标拥有唯一的标识ID。
(3) 发送信息。将发送队列中的探测包发送至该m移动方向最一致的邻居节点,若无该邻居节点,则将探测包发送至下一跳。相比直接发送原始数据至数据中心处理,网内数据处理更加节省整体能量消耗[8]。节点ij根据m的移动方向来预测下一个探测m的邻居节点ik。预测的ik满足如下约束:
|θk-θm|<Δθ,
minimize(|θk-θm|)
(1)
其中,Δθ为偏离阈值,θk为ik的位置方向;θm为m的移动方向。
(1)式中,|θk-θm|<Δθ表示ik偏离m的方向应小于Δθ;minimize(|θk-θm|)表示最接近m移动方向的ik。
(4) 接收信息。接收邻居节点或上一跳的包,按照包类型分别添加至接收队列或协作信息队列。协作信息队列存放节点对应邻居节点集合的TD误差信息。
(5) 处理信息。将接收队列和发送队列中相同ID的探测包,分析处理成新的探测包,重新添加至发送队列。分析处理机制由具体需求决定[3],本文将多条处于间隔ΔT内的相同ID的探测包均值成单条探测包。
1.2 学习模型
强化学习系统如图1所示,图1中,在不确定的外部环境中,Agent确定当前环境状态s,根据学习策略从动作空间中选择动作a执行;在动作a的作用下,环境状态s迁移到新状态s′,同时产生该动作的延迟回报r至Agent,Agent更新学习策略,选择下一动作继续执行。
在任务调度问题中,传感器节点和WSNs环境分别映射成强化学习系统中的Agent和环境。WSNs应用的任务集合和节点的工作状态集合分别映射成Agent的动作空间A和状态空间S。任务执行成功与否的奖惩值映射成延迟回报R。任务调度策略映射成学习策略P,即探索和利用策略。

图1 强化学习系统
传感器节点通过与WSNs环境的不断试错学习,最大化状态值函数Vπ(s),最终目的是找到每个状态下的最优策略π*(s)。根据Bellman最优方程[9],最优策略的值函数V*(s)定义如下:
(2)
其中,折扣因子γ∈[0,1]用来确定当前回报和长期回报的重要程度;R(s,a)为在状态s下执行任务a的期望回报;P(s,a,s′)∈[0,1]表示传感器节点执行任务a后从状态s转移到下一状态s′的概率。最优策略π*(s)可表示如下:
π*(s)=argV*(s)
(3)
在R(s,a)和P(s,a,s′)未知的情况下,Q学习利用Q值迭代找到每个状态s下的最优策略π*(s)。在时刻t,节点i的Q值函数[9]定义如下:
(4)
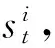
(5)
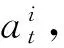

(6)
2 任务调度算法
2.1 协作机制
在CQ中,协作机制主要为传感器节点在评估自身Q值时,需加权考虑邻居节点集合的状态值函数,以此来平衡个体利益和群体利益。节点在每次调度任务后都会主动发送状态值函数至邻居节点集合,从而容易造成节点能量消耗过大、通信负载压力过大等问题,不适合大规模部署的WSNs。
在多Agent强化学习中,协作学习可以通过TD误差的比较,选择合适的学习速度来实现[7]。(4)式中学习速度因子β可改写为:
(7)
其中,0≤α1<α2≤1;coll(ij)为节点ij的协作节点集合;ecoll(ij)为coll(ij)中TD误差大于节点ij的TD误差δ的节点集合;Ncoll(ij)和Necoll(ij)均为集合数目。当Necoll(ij)≥Ncoll(ij)/2时,表示有半数以上的协作节点需要ij参与协作学习,ij选择较小的α1来学习,否则ij选择较大的α2来学习。
当节点ij的δ满足Necoll(ij) (8) 其中,A′为除睡眠任务以外的任务集合;ra为任务a的正反馈;m为任务集合A′的数目。 Tnow-Trs>Texpired (9) 其中,Texpired为过期间隔。 当ij需要发送δ的当前时间Tnow和前一次发送δ的时间Trs满足约束(9)式时,该δ可发送至ij的邻居节点集合。此外,为进一步减小通信负载压力,ij并不主动向邻居节点ik发送协作取消通知,而是通过邻居节点ik约束δ的有效期来取消协作学习。当ik接收ij的δ时间Trs与ik的当前时间Tnow满足过期约束(9)式时,ij的δ过期,ik将不考虑ij的δ进行协作学习。 2.2 延迟回报 延迟回报表示任务执行后的反馈,是任务执行效果的奖惩值。节点i在时刻t执行任务后,t+1时刻获得的延迟回报定义如下: (10) 本文采用适应性判定[3]对任务执行的条件进行控制,如处理信息任务的适应性判定为接收队列不为空。本文结合文献[3],定义性能回报和适应性判定,具体见表1所列。 表1 性能回报和适应性判定 定义探测成功率为跟踪目标任务执行成功数目占跟踪目标任务总数目的比例,接收成功率为接收信息任务执行成功数目占接收信息任务总数目的比例。定义性能为探测成功率和接收成功率之和,单位性能为单位能量消耗下获得的性能。定义平均回报为过去时刻节点获得的延迟回报均值。 2.3 状态空间 (11) 2.4 探索和利用策略 学习型调度算法[3,5]使用ε-greedy方法建立探索和利用策略,始终以探索概率ε选择随机任务,以利用概率1-ε选择最优任务。然而在学习前期,调度算法以利用概率1-ε调度最优任务,使得节点仍有较大概率不能充分调度随机任务。本文结合ε-greedy方法和Metropolis准则确定节点的探索概率[10],具体定义如下: (12) 其中,εp为根据Metropolis准则确定的探索概率;ar为选择的随机任务;ap为对应Q值最大的最优任务;T为温度控制参数;εg为根据ε-greedy方法确定的探索概率;μ∈[0,1]是常量;ns,max为状态集合的数目;ns,t为在时刻t已观察的状态数目;εmin表示探索概率下限,可使调度算法保持较小概率继续探索,突破经验的束缚;εt取εp和εg的较大值作为最终的探索概率。 在学习前期,T较大,而[Q(s,ar)-Q(s,ap)]始终为非正数,使得εp接近于1,εt取εp;在学习后期,T趋近于0使得εp趋近于0,ns,t逐渐增大使得εg逐渐变为εmin,故εt取εg。通过εt取εp和εg的较大值,可保证调度算法在学习前期以接近1的概率εp接受随机任务来充分探索,学习后期以较小的概率εg接受随机任务来保持探索。退火策略采用等比下降策略[10],计算公式如下: T(t)=λtT0 (13) 其中,λ∈(0,1)为系数;T0为初始温度控制参数。为使得调度算法在学习前期可以进行足够多的探索,系数λ取较大值。 2.5 算法描述 根据以上分析,本文建立了动态任务调度算法,具体步骤如下: (1) 初始化Q(s,a),T0等。 (2) 初始化节点i与邻居节点集合的方向。 在步骤(3)~步骤(9)中,步骤(4)、步骤(8)的时间复杂度为O(m),m为动作集合的数目。步骤(7)、步骤(9)的最坏时间复杂度为O(n),n为邻居节点集合的数目。由于m、n可在初始化时确定,因此QT算法每次任务调度的时间复杂度为O(1)。 本文在NS3网络模拟器中编写C++仿真程序进行2组实验。第1组实验详细分析2个节点在QT下的任务调度情况,第2组实验将QT与随机算法[3]、静态算法[3]、IQ[3]、CQ[4]、IS[5]进行分析比较,其中随机算法和静态算法为传统调度算法, IS为SARSA学习型调度算法,QT、IQ和 CQ为Q学习型调度算法。节点发送lbit数据的能量消耗[11]为: ETx(l,d)=lEelec+lξampd2 (14) 其中,l为数据包大小;d为发送距离;Eelec和ξamp由能量消耗模型决定。一般Eelec为50 nJ/bit,ξamp为10 pJ/(bit·m2)。节点接收lbit数据的能量消耗[11]为: ERx(l)=lEelec (15) WSNs参数设置如下:tsleep为0.5 s,r为5 m,c为15 m,协作信息大小为5 Byte,探测包为24 Byte,计算模块每次执行任务的能量消耗为0.5 μJ,探测模块每次跟踪目标的能量消耗为1 μJ。 结合文献[3],算法参数设置如下:rsleep=0.001,rtrack=0.05,rsend=0.1,rreceive=0.2,rprocess=0.05,γ=0.5,α1=0.05,α2=0.2,w1=-0.1,w2=1,εmin=0.1,μ=0.2,T0=500,λ=0.9,Δθ=20°,ΔT=2 s,Texpired=2 s。在其他学习型调度算法中,β取α2。 第1组实验网络示意图如图2所示。设置节点A坐标为(6,5),B坐标为(17,5),A的下一跳为B,B的下一跳为基站。A和B在探测半径r内跟踪移动目标M。M初始坐标为(0,7),以1 m/s速度水平向右移动,25 s后回初始位置再次水平向右移动。仿真时间设置为50 s。 图2 网络示意图 第1组实验下节点A和B的任务执行数曲线如图3所示。 图3 不同节点任务执行数曲线 分析图3可知,除睡眠任务外,执行其他任务成功时,由于正反馈较大,这些任务的调度容易从较小概率的探索转变为以较大概率的利用,对应任务执行数会明显上升。M在2~11 s进入A的监测区域时,A处于学习前期,以较大概率探索随机任务,任务执行数上升不明显;而在27~36 s,A以较小概率探索跟踪目标任务获得正反馈后转变为以较大概率利用,其任务执行数上升较快;M的移动方向与A的邻居节点B方向最一致,A的探测包发送至B处理,故A的发送信息任务执行数上升较快;A始终不接收节点B的探测包,使其处理信息任务的适应性判定始终为假。在13~22 s和38~47 s,M进入B的监测区域,任务执行数趋势同27~36 s的A。在33~36 s,B接收和处理A发送的探测包,并发送至基站,故B的接收、处理、发送信息任务执行数都上升较快。综上可知,QT具备根据当前环境进行动态调度任务的能力。 第2组实验先将50个节点随机地部署在120 m×120 m的地域上,基站固定在(0,0)上。以基站为初始位置,采用Prim算法确定各节点的下一跳,2个移动目标以1 m/s速度在该地域随机游走,仿真时间设为300 s。实验结果为所有节点的实验结果平均值。第2组实验仿真结束后所有节点的任务比例平均值和各指标结果平均值分别见表2各指标、表3所列。 Q学习型调度算法下节点的睡眠任务比例、探测成功率和接收成功率较高,具备何时睡眠和工作的学习能力,而非Q学习型调度算法下节点不具备动态调度任务能力。CQ的接收成功率高达88%,是因为每次调度任务后邻居节点集合都会向节点发送状态值函数,使得接收任务调度的频度和成功率都很高。相比CQ,QT的探测成功率、接收成功率和性能虽不是最优,但是消耗较小的能量获得较好的单位性能,使协作学习消耗的能量在可接受范围内。相比IQ和IS、QT的性能较高表明QT下节点获得更好的智能表现。QT的平均回报较高表明QT的任务执行成功趋势较高,学习效果较好。 表2 任务比例平均值 表3 各指标结果平均值 第2组实验下所有节点的平均能量消耗曲线如图4所示。 图4 平均能量消耗曲线 CQ由于使得节点每次调度任务后均向邻居节点集合发送值函数,其能量消耗最大,上升较快,不适合大规模部署的WSNs。QT由于使得节点协作学习,其能量消耗的上升趋势略高于IQ,但是相比CQ,QT的能量消耗在可接受范围内。 第2组实验中Q学习型调度算法下所有节点的平均回报曲线如图5所示。 图5 Q学习型调度算法的平均回报曲线 由表3可知,非Q学习型调度算法平均回报小于-0.024,而Q学习型调度算法的平均回报变化较一致,呈上升趋势。在学习后期,QT的平均回报高于IQ和CQ,表明QT在概率意义上使有利于节点学习的任务被调度的趋势加强,使不利于节点学习的任务被调度的趋势减小。 针对CQ合作学习时存在频繁通信的问题,本文提出一种基于Q学习和TD误差(QT)的传感器节点任务调度算法。具体包括建立目标跟踪应用的任务模型,建立邻居节点间的协作机制,定义延迟回报、状态空间等基本学习元素。实验结果表明:QT具备根据当前环境进行动态调度任务的能力;相比其他任务调度算法,QT的能量消耗适中、应用性能良好,可以提高节点的能源利用率。 [1] 王文光,刘士兴,谢武军.无线传感器网络概述[J].合肥工业大学学报(自然科学版),2010,33(9):1416-1419. [2] KO J G,KLUES K,RICHTER C,et al.Low power or high performance? a tradeoff whose time has come (and nearly gone)[M]//Wireless Sensor Networks.Berlin Heidelberg: Springer-Verlag,2012:98-114. [3] SHAH K,KUMAR M.Distributed independent reinforcement learning (DIRL) approach to resource management in wireless sensor networks[C]//IEEE Internatonal Conference on Mobile Adhoc and Sensor Systems.[S.l.:s.n.],2007:1-9. [4] KHAN M I,RINNER B.Resource coordination in wireless sensor networks by cooperative reinforcement learning[C]//IEEE International Conference on Pervasive Computing and Communications Workshops.[S.l.:s.n.],2012:895-900. [5] KHAN M I,RINNER B.Performance analysis of resource-aware task scheduling methods in Wireless Sensor Networks[J].International Journal of Distributed Sensor Networks,2014,2014:765182-1-765182-11. [6] 魏振春,徐祥伟,冯琳,等.基于Q学习和规划的传感器节点任务调度算法[J].模式识别与人工智能,2016,29(11):1028-1036. [7] MATIGNON L,LAURENT G J,FORT-PIAT N L.Hysteretic Q-learning: an algorithm for decentralized reinforcement learning in cooperative multi-agent teams[C]//IEEE International Conference on Intelligent Robots and Systems.[S.l.:s.n.],2007:64-69. [8] FASOLO E,ROSSI M,WIDMER J,et al.In-network aggregation techniques for wireless sensor networks: a survey[J].Wireless Communications IEEE,2007,14(2):70-87. [9] 王雪松,朱美强,程玉虎.强化学习原理及其应用[M].北京:科学出版社,2014:41-59. [10] GUO Maozu,LIU Yang,MALEC J.A new Q-learning algorithm based on the Metropolis Criterion[J].IEEE Transactions on Systems Man & Cybernetics,2004,34(5):2140-2143. [11] DENG J,HAN Y S,HEINZELMAN W B,et al.Scheduling sleeping nodes in high density cluster-based sensor networks[J].Mobile Networks & Applications,2005,10(6):825-835. (责任编辑 闫杏丽) A Q-learning and TD error based task scheduling algorithm for sensor nodes XU Xiangwei, WEI Zhenchun, FENG Lin, ZHANG Yan (School of Computer and Information, Hefei University of Technology, Hefei 230009, China) In order to solve the problems like frequent communication and large energy consumption in existing cooperative learning algorithms, a Q-learning and TD error(QT) based task scheduling algorithm for sensor nodes is proposed with the task model of target tracking applications. Specifically, the task scheduling problem for sensor nodes is mapped to the learning problem solved by the Q-learning, and the collaboration mechanism between neighbour nodes is established. QT also defines some basic learning elements such as delayed reward and state space. The collaboration mechanism based on individual and group TD errors can allow each sensor node to balance its own interests and the group interests by changing learning speed dynamically. Moreover, QT increases the exploration probability of early learning stage based on Metropolis criterion to optimize the task selecting process. The experimental results show that QT has the ability to schedule its tasks dynamically according to current environments, and compared with other task scheduling algorithms, QT improves the unit performance by 17.26% with reasonable energy consumption. wireless sensor networks(WSNs); sensor node; task scheduling; Q-learning; TD error; collaboration mechanism 2016-01-21; 2016-03-29 国家自然科学基金资助项目(61370088;61502142);国家国际科技合作专项资助项目(2014DFB10060) 徐祥伟(1990-),男,江苏盐都人,合肥工业大学硕士生; 魏振春(1978-),男,宁夏青铜峡人,博士,合肥工业大学副教授,硕士生导师. 10.3969/j.issn.1003-5060.2017.04.008 TP393 A 1003-5060(2017)04-0470-07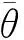




3 仿真分析






4 结 论
