探讨人工智能在档案开放鉴定中的应用
2017-03-12冯佳
冯 佳
(浙江省嘉善县档案局)
档案工作的根本目的是整合各种档案信息资源以便于社会大众的利用,档案开放是社会大众获取和利用档案信息最基本也是最重要的途径。随着科技的日新月异,电子信息技术也给档案工作带来了巨大的变革,“智慧档案”的概念随之应运而生。新技术的引进和运用不会改变档案工作的根本目的,而是为了更加高效、更加便捷地为社会大众服务。
我国于20世纪80年代开始提出档案开放政策,并于1987年公布的《中华人民共和国档案法》规定:“国家档案馆保管的档案,一般应当自形成之日起满30年向社会开放。经济、科学、技术、文化等类档案向社会开放的期限可以少于30年,涉及国家安全或者重大利益以及其他到期不宜开放的档案向社会开放的期限可以多于30年”。但在档案开放利用的实际工作中,还存在着许多限制和不足。本文旨在探析利用人工智能技术在档案开放鉴定中的应用来解决这些问题。
一、档案开放利用现状分析
(一)我国档案开放程度分析
从全国综合档案馆的馆藏数据和开放数据来看我国档案的开放程度(以下数据来源于国家统计局)。据统计,2015年国家综合档案馆馆藏档案数量为58641.7万卷,2006年国家综合档案馆馆藏档案数量为21656.5万卷,10年间馆藏档案增长率为170.78%。2015年国家综合档案馆开放档案为9266.3万卷,2006年为5746.3万卷,10年间开放档案增长率为61.26%,可以看出开放档案的增长速率相较于馆藏档案缓慢了很多。2015年国家综合档案馆的馆藏数据为58641.7万卷,开放档案数据为9266.3万卷,开放率仅为15.8%,而且开放率逐年在下降。
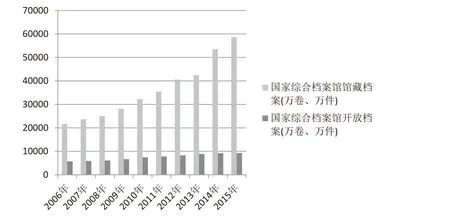
图1 2006—2015年国家综合档案馆馆藏档案数量和开放档案数量
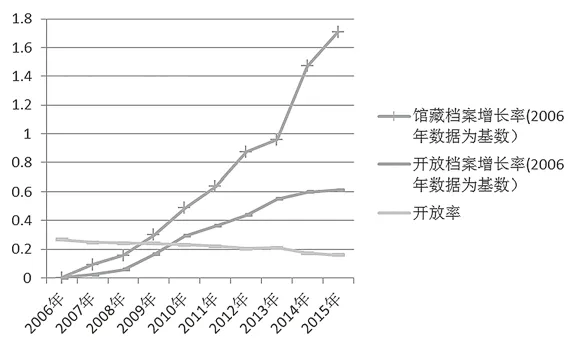
图2 2006—2015年馆藏档案增长率、开放档案增长率和开放率
(二)我国档案利用程度分析
从全国综合档案馆的利用档案数量来看,2006年国家综合档案馆利用档案1166.4万卷,2015年为1978.3万卷,增加率为69.6%。但是2015年的利用档案在已开放档案中利用率为21.3%,相对于整个馆藏数量则仅仅为3.37%,档案资源利用率极低。根据浙江省统计局数据,2015年档案资料利用人次为47.52万人;又根据国家统计局数据,浙江省2015年总人口为5539万人,这些数据表示浙江省档案利用人次仅占总人口的0.86%,意味着浙江省档案资源与99%以上的社会大众无关。
二、档案开放的主要瓶颈
相对于国外档案的高开放率,我国档案自20世纪80年代提出开放以来一直处于比较低的开放率,其主要原因有两个方面。第一,档案法律法规对档案开放时间起着引导性和约束性作用,基本上要形成满30年才能开放。第二,开放鉴定困难,由于人力和能力等方面条件约束,无法准确和准时地理解内容并做出鉴定,保密过度而开放减少,往往会导致开放数量减少。如图3所示,2006年人均管理档案数为0.9545万卷,而到2015年时上升至3.1895万卷。2006年国家综合档案馆数为3154个,专职员工为22689人;而10年后综合档案馆数上升至3322个,人员却降低至18386人(以上数据均取自国家统计局)。
开放鉴定困难造成档案开放率逐年递减,而法律法规导致开放的档案时效性较差,无法满足社会大众的需求,也就产生了上一节档案资源与99%以上的社会大众无关的局面。
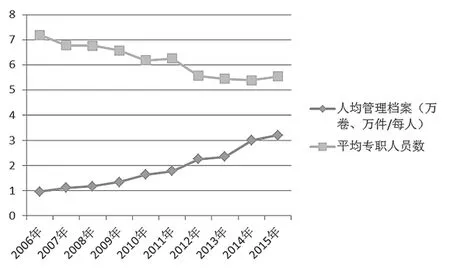
图3 人均管理档案数和档案馆平均专职人员数
三、人工智能技术
随着近年来人工智能技术的兴起,各行各业都引入了人工智能的技术来提升生产力和效率,档案行业也不例外。浙江、江苏、青岛等省市陆续提出了“智慧档案”并进行了试点探索,而本文旨在探讨运用人工智能技术中的深度学习方法来实现档案的开放鉴定工作。
(一)人工智能技术实现原理
传统意义上,计算机使用方式是我们通过鼠标或者键盘等输入装置给它一连串指令,然后计算机按照指令去执行并输出结果,一一对应,非常明确。而人工智能最大的不同点在于,它接受的是数据,自己分析,然后输出结果。
以一个经验丰富的档案工作者鉴定一份档案是否开放为例,他首先需要了解这份档案的内容,然后根据自己的经验来给出鉴定结果。如图4所示,我们人工智能技术的原理就是模拟这种方式,利用已有的历史数据,得出某种模型,并利用这种模型来预测未知属性。人工智能中计算机学习的方式与人脑思维的经验过程是非常相似的,不过计算机能考虑更多的可能性,执行更加复杂的运算,也拥有更快的速度。利用这种技术,我们便可以使用计算机来对档案做开放鉴定。

图4 人工智能与人类的对比
(二)自然语言处理
在分析数据前,首先要让计算机“读懂”数据,也就是自然语言处理。机器处理自然语言的历史一般认为是从1950年Alan Turing在Mind杂志上发表的“计算的机器和智能”开始的,经过了60多年的发展,这个领域已经取得了实质性的突破。机器自然语言处理从用语法规则去理解自然语言,转变成了基于数学模型和统计的方法去分析自然语言(吴军,2014)。在中文中,词是表达语义的最小单位,机器处理自然语言是建立在词的基础上的,所以中文分词就是把一整段的句子分成单独的几个词。
自然语言处理包括句法语义分析、信息抽取、文本挖掘、机器翻译、信息检索、图像识别等等,结合现下jieba分词、Word2Vec等几个最流行的工具,机器就能“读懂”档案的内容了。注意,这里读懂被加了引号,是因为现阶段自然语言处理都是基于统计模型的,而不是基于语义模型。
(三)学习方法
计算机能读懂档案后,就需要进行学习。计算机学习主要有训练和预测两个方面,对应于人类的归纳和推测。计算机学习的方法有很多种,比较经典的有回归算法、神经网络、SVM支持向量机、聚类算法、降维算法、推荐算法、朴素贝叶斯等等。按训练的历史数据有无标签,我们可以将算法基本分为监督学习算法和无监督学习算法。因为档案开放只有可开放和不可开放两种结果,所以需要使用监督学习算法,而神经网络算法是当下非常流行的一种监督学习算法,递归神经网络(RNN)非常适合运用于自然语言处理,例如Socher et al.(2013c)成功使用了递推神经网络来预测语句情感,并取得了80.7%的准确率。所以,神经网络算法也非常适合计算机来做档案开放鉴定。
神经网络算法是人工智能中的一个新的领域,它的原理是模仿人脑的机制来解释和处理数据,建立大脑神经网络系统传递信息,可以用于分析图像、声音和文本。所谓深度学习神经网络,就是拥有层数非常多的神经网络。举个例子,想要在图5的三个图中让电脑识别是否有人脸,设计几个神经元来判断是否有眼睛,是否有鼻子,是否有嘴巴,是否有头发,等等,然后依靠最终神经元的输出判断是否有人脸,如图6所示。如果想判别是男人的脸还是女人的脸,或者判定其他更复杂的东西,就需要增加更多的神经网络层。
神经网络算法运用到档案的开放鉴定中分为两个步骤:训练和预测。训练的意思就是把已经由人工划分好的历史数据让机器学习,得出一个模型。经过不断地参数调整,这个模型就可以拥有较高的档案开放鉴定准确率了。机器鉴定档案会有以下三个优点:鉴定标准统一,效率高,无须相关专业知识即可鉴定。

图5 判别人脸的例子
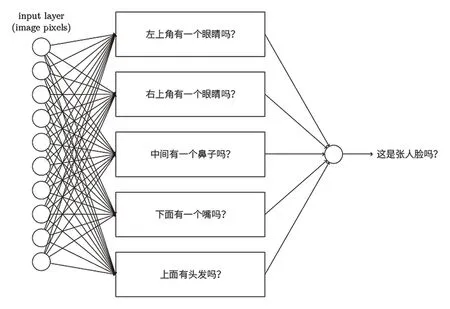
图6 简易神经网络
(四)不足与展望
运用人工智能技术中的神经网络算法来鉴定档案是否开放,还存在着许多实际操作中的问题。第一,模型训练需要档案全文数字化,导致训练数据的数量需求量非常大,至少千万级别,而2015年全国开放档案才9266.3万卷,训练数据获取难。第二,算法设计和参数调整需要相当大的人力和时间,神经网络是一个非常年轻的领域,理论建立并不完备,很多方面都要摸索着前进。第三,可能会有部分误判,由于模型预测过程完全是黑箱模式,无法知道判别的具体依据。尽管有着诸多困难,但这些在实现“智慧档案”的道路上是不可避免的,人工智能技术的引入会加快“智慧档案”的实现。
