一种支持数据源动态加入的交互式数据集成方法
2017-01-04仇丽青
温 彦, 仇丽青, 陈 欣, 张 峰
(山东科技大学 信息科学与工程学院 山东 青岛 266590)
一种支持数据源动态加入的交互式数据集成方法
温 彦, 仇丽青, 陈 欣, 张 峰
(山东科技大学 信息科学与工程学院 山东 青岛 266590)
提出了一种支持数据源动态加入的交互式数据集成方法.该方法利用基于可视化嵌套表格提供所见即所得的即时集成环境,利用语义映射工具提供半自动化的支持,渐进式地向用户推荐可能的集成结果和方式,屏蔽集成过程的复杂性,并保证任意的数据源引入顺序条件下集成结果的正确性.采用增量式的方法计算新数据源加入时的最优集成方案,利用用户反馈有效地进行剪枝,优化集成过程.通过实验验证了此方法的有效性.
数据集成; 交互式; 按需集成; 数据源动态加入
0 引言
互联网正在演变为迄今人类最大的协同计算平台,其上的数据规模呈指数级增长,其中结构化数据显著增加,且用户对结构化对象的查询占据了所有Web检索的一半以上并呈现出跨领域、综合性的特点[1].此外,用户的个性化数据需求愈发明显,具有即时性、不可重复等特点.因此如何支持最终用户快速按需集成互联网数据,成为亟待解决的问题.解决该问题需要克服前所未有的新的挑战,使得传统的重量级集成方法不再适用:数据规模大、动态性强,难以建立和维护统一的中间模式,且需要应对数据源的动态加入和退出[2];数据内容高度自治,缺乏足够的语义信息和统一的语义规范,给集成带来较大困难;即时、个性化的集成需求使得方法必须易于使用.
已有一些工作针对互联网环境下的跨域数据集成,然而这些方法对用户而言是困难的,主要表现在:1) 用户理解并实现复杂的集成逻辑是困难的,包括各类数据处理和控制逻辑操作,且需要按照正确的顺序来引入数据源、执行集成操作.2) 跨域数据普遍存在语义层面的异构性,用户正确指定数据的语义映射关系并进行可视化表示是困难的.3) 面对新数据源动态加入和退出,用户需要即时修正集成逻辑并保证集成结果的正确性,对用户而言也是困难的.
为了克服上述困难,本文基于已有数据服务的模型和其上定义的聚合操作[3],以及嵌套表格提供的所见即所得的集成环境和语义映射工具提供的匹配方法,提供一种渐进式的交互式集成过程向用户推荐可能的集成结果,屏蔽语义映射和集成操作的复杂性,同时保证在任意的数据源引入顺序条件下(即数据源动态加入过程)集成结果的正确性.集成过程采用增量式的方法计算新资源加入时的最优集成方案,并利用用户反馈有效地进行剪枝,优化集成过程,改进用户体验.
1 基本概念
我们在之前的工作中提出了数据服务模型[3],它基于嵌套关系定义,能够表达互联网上常见的结构化和半结构化数据,且具有良好的可视化形式,嵌套关系和数据服务的定义如下.
定义1 (嵌套关系) 一个嵌套关系包含模式和实例.令A是属性名称全集,嵌套关系模式R(S)被定义为:R(S)=(A1,A2,…,Am),其中:R∈A.R是关系模式的名称,S是属性名称列表.Ai是原子属性或者形如Ri(Si)的子关系属性.模式R(S)的一个实例是形如(a1,a2,…,am)的有序元组集合,若Ai是原子属性,则ai是基础数据值;若Ai是关系模式,则ai是Ai的实例.
定义2(数据服务) 数据服务是如下五元组:ds=
在数据服务上定义了基于映射关系的服务输出输入连接(connect)、服务输出连接(join)和合并(union)等操作.基于嵌套关系代数的理论基础,这些操作满足广义交换律、结合律和分配律.
2 集成典型案例
本节通过一个典型案例来说明本文所提方法的基本效果.该案例的目标为获得满足火灾救援需求的设备储备信息视图.假设涉及的数据服务模式如表1~表4中的S1~S4所示,它们均不包含输入参数.


表1 物资需求(S1)Tab.1 Material reserves(S1)

表2 医疗设备储备(S2)Tab.2 Medical equipment storage(S2)

表3 灭火设备型号登记(S3)Tab.3 Fire extinguishing equipment models registration(S3)
表4 设备库存(S4)
Tab.4 Equipment storage(S4)

设备型号各仓库存量仓库库存量MTZ⁃5S1500S3300MTZ⁃20S3200MTZ⁃50S1400S3300
3 目标模式生成
本文的集成过程分为集成目标模式生成和增量式集成方式发现两个阶段.生成结果的数据模式称为目标模式.该阶段关注新引入服务(设为S)与当前目标模式(设为T)的属性合并、扩展(增加新属性)和层次结构的改变.基本思路为,首先根据S与T之间的原子属性上的基本映射关系形成新的目标模式T′.而后根据S的嵌套结构所反映的数据依赖关系来确定T′的层次结构.
3.1 属性映射关系的计算和推荐
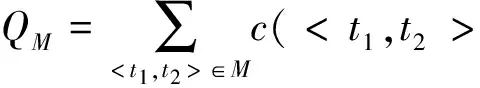
定义3 模式匹配扩展图.嵌套模式R1和R2的所有原子属性集合分别为T和S,在T中为S中的每个元素s构建附加节点s′构成Ts′={s′},并令T′=T∪Ts′,在S中为T中的每个元素t构建附加节点t′构成St′={t′},并令S′=S∪St′.构造二部图G=
1) 若a∈T,b∈S,则w=c(
2) 若a∈T,b=e1,则w=(1-maxbi∈S(c(
3) 若b∈S,a=e2,则w=(1-maxaj∈T(c(
根据上述定义,可直接得到性质1.
性质1 所有扩展节点上只有一条边,连接其源节点.
定义3的2)和3)中除以2的含义为:使得连接两个属性的边通过扩展节点提供的两条扩展边的权值和不大于原匹配属性对的权值.根据性质1,扩展图中的附加节点s′与其源节点s构成的边表示源节点s不与T中的所有节点匹配,即为扩展属性.可在模式匹配扩展图中使用KM算法获得最大匹配.图1为示例.假设两模式原子属性间的匹配及其置信度如图1(a)所示,扩展后如图1(b),两图的带权最大二分匹配为加粗黑线,左图的质量为1.62,右图为1.895,t1、s1为扩展属性.

图1 模式扩展图的最大二部匹配示例Fig.1 Maximum bipartite graph mappings for schema extending graph
3.2 扩展属性位置的计算和推荐
尽管嵌套和解嵌套操作可形成多种合理的层次结构,不存在唯一最优结构,然而合并过程应当尽量保持原嵌套层次表示的数据依赖关系.因此可根据此依赖关系来预测并推荐扩展属性的位置.
定义4 嵌套关系属性的层次关系.嵌套关系模式中的属性(原子、子关系属性)间在嵌套结构上的关系分为4种:上层、下层、平级、无关.属性A为B的上层属性当且仅当A所在的嵌套关系R1可递归包含B所在的嵌套关系R2,此时称B为A的下层属性,R1为B、R2的祖先关系,B、R2为R1的子孙关系/属性,若A和B为同一个嵌套关系的属性,则A、B互为彼此的平级属性,若A、B不满足3种关系,则称A、B无关.A的所有祖先关系与B的所有祖先关系中相交的部分称为A和B的公共上层关系,其中嵌套层次最深的子关系称为A、B的最近公共祖先关系.A、B的距离是指A、B到两者的最近公共祖先关系的嵌套路径长度之和.如嵌套模式A
可根据嵌套结构的形态描述嵌套关系整体及其子结构的数据依赖关系特征,包含全局依赖和局部依赖[5],前者表示在整个嵌套结构上的依赖关系,后者表示仅在某个子关系内部成立的依赖关系.两者主键只包含原子属性.例如S4中“(设备型号,仓库)→库存量”为全局依赖,“仓库→库存量”为局部依赖,可以看出,全局依赖的主键分布在不同的嵌套层次中,形成了局部依赖.
定义5 嵌套关系的全局依赖关系.对于嵌套关系模式R,其上的全局依赖关系的形式为:(A1,A2,…,An)→GB,其中Ai∈R.TAttr,i=1,2,…,n,B为R中某嵌套层次内的原子属性或子关系属性,表示(A1,A2,…,An)的值能够唯一确定B的取值(B为原子属性时,表示简单值,B为子关系属性时,表示B上的元组集合),并将{A1,A2,…,An}称为B的依赖属性集.假设B所有祖先关系的原子属性集合为A,则A→GB被称为B上的平凡全局依赖关系,并将A称为B的平凡依赖属性集.
定义6 嵌套关系的局部依赖关系.对于嵌套关系模式R,其上的局部依赖关系的形式为:(L1,L2,…,Lm)→LB成立当且仅当存在R上的全局依赖关系(A1,A2,…,An)→GB,使得{L1,L2,…,Lm}⊂{A1,A2,…,An},且(L1,L2,…,Lm)与B在同一子关系内.
根据上述对嵌套结构及其依赖关系的分析,扩展属性位置的推荐原则为维护属性间的数据依赖关系并尽量保持它们在原数据模式中的位置关系,使得相同属性对间的距离在数据服务中和在目标模式中的变化较小.某些全局依赖关系可能不包含在所有的平凡全局依赖关系集合内,但在缺乏明确定义的依赖关系的情况下,推荐均基于平凡依赖关系.根据定义4~6,得到引理1.
引理1 假设在嵌套关系模式R中,存在(A1,A2,…,An)→GB,A1,A2,…,An中不存在不相关的属性对,Rj为(A1,A2,…,An)中嵌套层次最深的属性Aj所在的关系,则若通过嵌套操作使得Rj的某个子关系包含B,则该子关系中所有元组在B上的取值全部相同.
引理2 在关系R的非主键属性上的嵌套操作不会改变数据实例结构.
结合引理1和引理2,设新引入服务模式S中的属性Ri形成了目标模式T中的扩展属性,Ri的所有祖先关系的集合为RS,对于每个关系Rj∈RS,设Rj的原子属性集合为Aj,Aj在T中对应的属性集合为map(Aj),则Ri在目标模式T中的位置可能存在于T内各个Aj的map(Aj)中的属性所在的嵌套层次最深的关系中.此外,对于S中映射属性所依赖的嵌套结构,不同映射属性的最近公共祖先关系构成了它们共同依赖的内容,可以作为共同的上层嵌套结构在T中扩展,而由于下层的属性平凡依赖于上层属性,因此在S中以自顶向下的方式逐步确定扩展属性的位置.算法1如下所示.

算法1扩展属性推荐列表构建算法输入:嵌套关系S,目标模式T,S与T的基本映射关系M输出:推荐列表begin//S的最近公共祖先SCR←S.closestAncestor(S.TAttr∩M.Left)//T的最近公共祖先TCR←T.closestAncestor(M.map(S.TAttr∩M.Left))Head←S⁃SCR//S中不包含于SCR的嵌套结构addRecommend(“Head包含TCR”)//共同的上层嵌套结构//递归时,添加当前子关系对所有上层属性的依赖关系loopforeachRi∈Head.Attr loopforeachrelationRj∈Head.ancestorRelations addRecommend(“Ri与Rj.AAttr中最低层属性同层”);loopforeachRi∈SCR.RAttr∧Ri.TAttr∩M.Left≠⌀ constructRecommendPositionList(Ri,T,M);//递归 endloopendloop //若最近公共祖先内存在映射属性 if∃Ai∈SCR.AAttr∧Ai∈M.Left loopforeachRj∈SCR.Attr∧(Rj∉M.Left∨(Rj.TAttr∩M.Left=⌀))//非映射属性和子关系 //这些属性依赖于Aj addRecommend(“Rj与Ai位于同一关系”); endloopendif//对SCR中各个包含映射属性的子关系 endloopend
以本文的典型案例为例,若S1为当前目标模式,S2为新引入服务的模式,那么在原子映射关系{}之上,扩展属性为S2中的“储备量”.基于S2中的平凡依赖关系“(医疗设备名称,储备量)→储备量”,则可确定扩展属性“储备量与类型”位于同一关系,最终形成新的目标模式:“物资需求<类型,数量,储备量>”.
4 集成方式的增量式发现
本节主要说明如何在新的目标模式确定后发现新引入服务与已集成服务的正确集成操作序列.
4.1 基本思路及正确性验证
一般来说,任意数据服务的二元集成过程均可通过”连接+合并”的方式实现,连接是指多个服务通过连接类操作(join、connect)形成全部或部分目标模式,合并是指将多个能覆盖目标模式的连接结果通过集合类操作合并到一起(union).
定理1 (正确性)多个数据服务{S}由任意的join、connect、union操作序列构成的集成形式能够等价变换为由{S}的子集形成的多个连接运算之上的集合运算的集成形式.
证明思路:利用数学归纳法和连接、合并操作的分配律可以得证.此处略.
通过此定理,新引入服务可先与部分已引入服务进行连接,再将多个连接结果合并即可.这种“连接+合并”的表达方式借鉴了传统的查询发现方法[6],是本节方法的依据.
4.2 实现算法
首先规定几个基本定义,对于T上的某一个原子属性Ri,将模式中包含与Ri实现映射的属性的服务集合称为Ri的映射服务集合,将映射到Ri上的服务模式中的属性集合称为Ri的映射属性集合.集成方式的发现方法通过以下3个步骤实现,具体包括:
1) 计算全部和部分覆盖目标模式的服务集合及其覆盖率;
该步骤主要发现可能通过连接操作形成全部或部分目标模式的服务集合,称为候选服务集合.
定义7 候选服务集合.候选服务集合为目标模式各个原子属性的映射服务集合的笛卡尔积.假设目标模式为T,数据服务的模式为S,S与T形成的原子属性间的映射关系为MS,T,对于每个ti∈T.TAttr,令C(ti)={c∃u∈c.TAttr,
上述笛卡尔积包含所有可能的服务连接方式,正确的连接序列为其子集.其中的空元素使得集合能够仅覆盖部分目标模式,表示某些属性取值可为null,或者表示尚未完成连接的候选服务集合.计算过程中也要考虑同一候选服务集合中的不同服务的属性与目标模式的映射关系存在包含的情况.例如服务A和服务B的属性分别与目标模式中的t1及t2均具有映射关系,B包含A.将所有连接方式集合中存在包含关系的被包含的候选服务集删除,将这一过程称为候选服务集合的约减.
每个候选服务集合形成了对目标模式一定程度的覆盖,反映了能够通过连接形成目标模式的完整程度,是候选服务集合排序和选择的重要指标.此外,集合内服务在相同属性上的映射反映了它们的连接条件.
定义8 候选服务集合的覆盖率.假设目标模式为T,其全部原子属性集合为T.TAttr,目标模式上的映射关系集合为M,候选服务集合为L,则将L对T的覆盖率CoverRate定义为T中与L中的服务有映射关系的原子属性占T中所有原子属性的比例.
2) 增量式的集成方式发现方法
增量式集成方法旨在发现新引入服务并与已有集成的结果直接集成.基本原则为尽量选择覆盖程度较低的候选服务集合进行扩展,表明尚有空间在该集合中添加新服务以增加覆盖率.
假设S和T的原子属性集合分别为SA和TA,集成S前T上的候选服务集的集合为L0,其中CoverRate=1的集合为L1,新候选服务集合L和模式T’的计算方法如表5所示.
聚合操作的广义交换律、结合律和分配律保障了上述过程的正确性,实现了任意的服务引入顺序均不影响最终集成结果的正确性,系统能够即时处理数据源的动态加入,用户不必拘泥于严格的服务引入和聚合操作的顺序,并免除了需要多次引入同一服务和存储临时服务等繁琐细节.

表5 增量式集成策略Tab.5 Incremental integration rules
3) 用户反馈的学习和集成过程优化
系统计算出新的目标模式和集成方式后,可直接在嵌套表格中呈现,体现为模式变更和数据内容变化.用户对系统推荐的集成操作可提供接受(隐式)或者拒绝(显式)的反馈,并可用于对后续集成方案的优化,实际上是对搜索空间的剪枝,具体策略如表6所示.

表6 基于用户反馈的集成过程调整方法Tab.6 Integration process adjustment based on user-feedbacks
5 实验分析
本文选择一组具有代表性的数据集成需求,如表7所示.数据主要来自于互联网的Deep Web数据和公开的API.实验中,采用包含字符串、WordNet等多个匹配器的混合匹配计算工具.

表7 实验中用户的集成需求列表Tab.7 Integration needs in the experiments
本文所提出的交互式集成过程的效率可从如下两方面评价:1) 推荐的操作数,反映了用户需要提供的反馈的数量,实际中由于正确推荐是隐式的,因此采用拒绝的推荐数作为评价指标.包括:属性合并、属性扩展、位置确定、服务连接等操作.2) 推荐的正确率,反映了用户的体验效果.
由于本文的方法中包含了增量式和用户反馈的机制,通过组合这两种机制,形成下面3种实现方法:有用户反馈非增量式方法、无用户反馈增量式方法以及有用户反馈的增量式方法.
实验结果如图2和3所示.在拒绝数上,基于有用户反馈的增量式方法比有反馈非增量式和无反馈增量式的实现方法分别减少了52.5%和88.4%.在正确率上,基于有用户反馈的增量式机制的正确率比无用户反馈的增量式实现方法提高了0.52倍,与有用户反馈非增量式的方法的正确率基本持平.
对结果分析如下:无反馈的方法无法纠正错误的映射关系,从而无法优化后续服务连接方式,因此需要推荐的操作数相当多,正确率也较低.无增量式的方法需重复执行已确认的步骤,错误的操作数多,但对错误率没有多少影响.但反馈机制会大大减少错误的匹配数,因此步骤数没有剧增.此外,服务数量越多,所需的操作数也就越多.相同方法在不同组别中的差异的原因在于模式的异构性的程度和规模不同,同时网页抽取出的模式与Web API相比较为简单.由上述实验结果可以看出,本文方法在推荐的操作数和正确率上均有较好的表现,能够提供良好的用户体验.
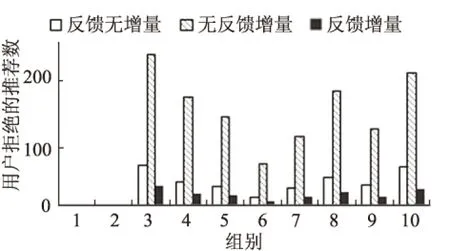
图2 不同的机制下的各组实验中用户拒绝的推荐数Fig.2 Number of rejections of different groups

图3 不同的机制下的各组实验的推荐正确率Fig.3 Recommendation accuracy of different groups
6 相关工作
集成逻辑的复杂性和用户有限的操作能力之间的矛盾是用户实现多源数据按需集成的主要障碍.解决这一问题可从两方面考虑,一方面可以向用户提供简单的可视化集成操作,另一方面可以利用已有的自动化集成技术,进行人机协作的集成过程.
前者包括各类数据mashup系统,它借鉴了最终用户编程的思想,向用户提供各类易于操作的界面级构件和操作方法.Spreadsheet[7]和流程图[8]是两种主要形式.对于各类Mashup方法而言,尽管存在多种优化方法,它们仍然是由用户完全主导的,用户需了解各类操作的含义和用法以及复杂集成逻辑的构造过程,对用户的技术要求仍然较高.
近年来出现的演化式数据集成方法提供了一种用户操作更为简单的数据集成方式.为了应对开放互联网环境下数据源的大规模、动态、不确定、缺乏统一规范等特征,出现了包括数据空间、Pay-as-you-go的渐进式集成方法、不确定性数据集成[4,9]等概念和技术.对于演化式集成方法,尽管能够大大降低用户操作的复杂性,但却在集成结果的正确性和完备性上存在较大的局限性.
本文尝试寻找两者平衡,一方面能够利用自动化集成技术和用户反馈学习方法降低用户代价,另一方面也希望能够提供正确性、表达能力等方面的保障.
7 结论
本文提出了一种支持数据源动态加入的交互式数据按需集成方法,该方法在可视化的嵌套表格中实现,利用语义映射工具提供半自动化的支持,渐进式地向用户推荐可能的集成结果和方式,屏蔽集成逻辑和语义映射关系定义的复杂性.提供了增量式的最优集成方案的计算方法,最大程度重用已有集成结果,并且利用用户反馈有效地进行剪枝,优化集成过程.该方法保证任意的数据源引入顺序条件下集成结果的正确性,即能够支持新数据源的动态加入.通过实验分析,验证了本文具有良好的推荐效果和用户体验.
[1] CAFARELLA M J, HALEVY A, MADHAVAN J. Structured data on the web[J]. Communications of the ACM, 2011, 54(2): 72-79.
[2] TALUKDAR P P, IVES Z G, PEREIRA F. Automatically incorporating new sources in keyword search-based data integration[C]//Proc of the 2010SIGMOD Int’l Conf on Management of Data. Indianapolis, 2010: 387-398.
[3] 温彦, 刘晨, 韩燕波. 一种用户主导的跨组织数据按需集成方法[J]. 西安交通大学学报(自然版). 2013,47(2):116-123
[4] 刘晓光, 谢晓尧. 一种结合遗忘机制与加权二部图的推荐算法[J].河南科技大学学报(自然科学版),2015, 36(3): 48-53.
[5] HARA C S, DAVIDSON S B. Reasoning about nested functional dependencies[C]//Proc of the 18thACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems. Philadelphia, 1999: 91-100.
[6] MILLER R J, HAAS L M, Hernandez M A. Schema mapping as query discovery[C]//Proc of the 26thInt’l Conf on Very Large Data Bases. Cairo, 2000: 77-88.
[7] LIU C, WANG J, HAN Y. Mashroom+: an interactive data mashup approach with uncertainty handling[J]. Journal of grid computing, 2014, 12(2): 221-244.
[8] JONES M C, CHURCHILL E F. Conversations in developer communities: a preliminary analysis of the yahoo!Pipes community[C]//Proc of the 4thInt’l Conf on Communities and Technologies. University Park, 2009: 195-204.
[9] BELHAJJAME K, PATON N W, EMBURY S M, et al. Incrementally improving dataspaces based on user feedback[J]. Information systems, 2013, 38(5): 656-687.
(责任编辑:王浩毅)
Interactive Data Integration Method Supporting Dynamic New Source Incorporation
WEN Yan, QIU Liqing, CHEN Xin, ZHANG Feng
(CollegeofInformationandEngineering,ShandongUniversityofScienceand
Technology,Qingdao266590,China)
A method of interactive data integration was proposed, which could support dynamic data sources incorporation. The method used data service model which could provid a visualized inbeded table as the just-in-time integration environment, and used semantic mapping tool to provide semi-automation support. This approach ensured that random data source introducing order would not affect the correctness of the results. An incremental method was provided to generate optimal integrated solutions when new sources were introduced, and user-feedbacks were used to prune and optimize the subsequent integration process. The experimental analysis proved that the proposed method was valid.
data integration; interactive data integration; on-demand data integration; dynamic data source incorporation
2016-07-04
教育部博士点基金(20133718120011);2014青岛市博士后研究人员应用研究项目;国家自然科学基金资助项目(61502281).
温彦(1984—),女,山西晋中人,讲师,主要从事数据集成、Web数据管理的研究,E-mail:wenyanxxxy@163.com.
温彦,仇丽青,陈欣,等.一种支持数据源动态加入的交互式数据集成方法[J] .郑州大学学报(理学版),2016,48(4):36-43.
TP312
A
1671-6841(2016)04-0036-08
10.13705/j.issn.1671-6841.2016650
