基于熵重要测度权重粗糙集的阿尔法多层凝聚入侵分类
2016-09-26王兴柱颜君彪曾庆怀
王兴柱 颜君彪 曾庆怀
1(湖南文理学院芙蓉学院 湖南 常德 415000)2(湖南文理学院现代教育技术中心 湖南 常德 415000)
基于熵重要测度权重粗糙集的阿尔法多层凝聚入侵分类
王兴柱1颜君彪1曾庆怀2
1(湖南文理学院芙蓉学院湖南 常德 415000)2(湖南文理学院现代教育技术中心湖南 常德 415000)
针对入侵检测数据量大,而文献[1]提出的α核心集的多层凝聚算法计算复杂度过高,影响实际应用的问题,提出一种基于熵重要测度权重粗糙集的α核心集多层凝聚入侵分类算法。首先,基于熵重要测度权重方法利用粗糙集对入侵检测数据进行预处理和属性约简,降低数据维数防止算法陷入“维数陷阱”;其次,用熵重要测度权重距离代替阿尔法多层凝聚算法的欧式距离计算个体相似度,并实现粗糙集输出数据与阿尔法多层凝聚算法的有效对接。通过实验表明,基于熵重要测度权重粗糙集的α核心集多层凝聚入侵分类算法能够更加有效对KDDCUP99标准数据库进行检测分类。
熵重要测度权重粗糙集多层凝聚入侵检测
0 引 言
入侵检测系统(IDS)是对网络中入侵行为进行检测的自动系统,作为入侵安全防范的前提已在许多安全系统中得到广泛应用[1,2]。二十一世纪,网络逐渐成为获取资讯最常用的工具之一,人们对于网络的依赖程度也逐渐增加。如何构建高效的入侵攻击防御系统,对于保障信息安全、维持正常生产、生活秩序意义非凡[3]。
为进一步提高入侵检测算法的整体性能,许多学者致力于入侵检测算法方面的研究。文献[4]基于SVM算法在非线性识别中的特点,提出一种SVM入侵检测算法,去除了机器学习算法的局限性。文献[5]基于神经网络在非线性逼近方面的优势,对特征提取后的入侵攻击行为进行检测。文献[6]基于k-Means算法来降低训练样本量,提高其学习性能和计算效率,通过反向传播学习机制对入侵攻击进行检测。文献[7]基于CACC对算法进行离散化,以此提高数据表达能力,然后基于朴素贝叶斯和k-Means聚类进行入侵估计检测等。
1 多层凝聚算法
学者马儒宁在文献[1]中阐述了一种新的基于α核心集指标的分层次聚类方法(MULCA),称之为多层凝聚算法。有关定义如下:
定义1该定义根据高斯距离概念,给出(入侵)数据xi与xj间的相似性形式如下:
(1)
式中,σ=σ0d,d为数据集的直径。
定义2文献[1]采用α核心集概念,此处给出多层凝聚算法的首要核心集概念。如果对于任意数据集X中的任何一点x*都满足式(2)所述的要求:
(2)
则称任意点x*为任意数据集X的首要核心点。
定义3α个依次首要核心点可定义形式如下:
(3)

定义4数据集X的α核心凝聚矩阵可由式(4)获得:
(4)
从定义4给出的凝聚矩阵计算公式可以看出,该矩阵PX~Xα能够反映出数据集X与其α核心集Xα的相关程度。
定义5Xα的加权相似性矩阵形式如下:
(5)
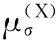
根据定义5,可依次定义得到原数据集X,在凝聚粗化分层过程中,每一层提取结果的α核心集的相似性加权矩阵,形式可定义如下:
(6)
根据定义1-定义5,可获得文献[1]提出的多层凝聚算法的两阶段计算(粗化与细化)过程步骤,如图1所示。
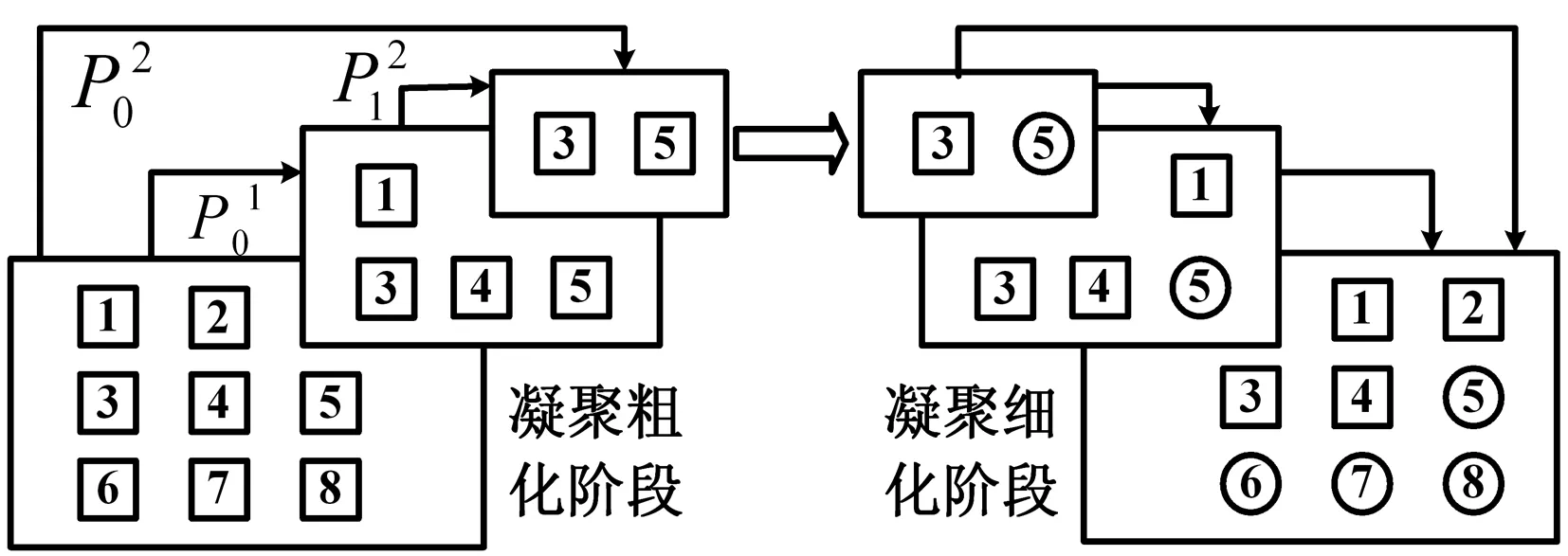
图1 多层凝聚算法过程
2 粗糙集熵属性约简
MULCA算法由于牵涉到凝聚粗化和凝聚细化两个阶段,导致算法计算复杂度的提高,特别是针对如入侵检测系统这种大数据量的分类问题时,如何降低算法的计算复杂度关乎算法的实际应用价值。下面将借助粗糙集熵属性约简来对分类数据进行预处理,以期达到降低算法计算复杂度,提高分类精度的目的[8,9]。
定义6(等价关系族)假设P、Q在集合U中为等价的,Q的P正域可表述为:
(7)

(8)

Gain(A)=I(S1,…,Sm)-E(A)
(9)

sig(C)=rP(C)-rP-Q(C)
(10)
定义9(熵测度权重距离)假设有K个属性,则对于其属性j∈K,其重要性权值可根据定义8表述如下:
(11)
则熵测度权重距离可定义如下:
(12)
利用该熵测度权重距离可以对冗余属性进行删减,从而可以有效地降低计算数据量,并可仿真算法陷入“维度陷阱”,粗糙集熵属性约简步骤如下:
步骤1输入n个对象的数据库,及输出簇的数量k;
步骤2数据初始化,令γΦ=0,Φ→red;
步骤3对任意属性ai∈A-red,计算重要测度:
sig(ai,red,D)=γred∪a(D)-γred(D)
(13)
步骤4选择最重要测度的属性ak,满足下式:
sig(ak,red,D)=max(sig(ai,red,D))
(14)
步骤5若sig(ak,red,D)>0,则更新red集合:red∪ak→red,否则返回步骤4;
步骤6利用上述得到的K维数据库根据定义9计算red集中的个体属性权重ωj;
步骤7任意k个属性对象作为簇中心;
式中,Wx表示相x的质量分数,Ix为积分强度,KxA和KiA可以在JCPDS(Joint Committee on Powder Diffraction Standards,粉末衍射标准联合委员会)的PDF卡片中得到.
步骤8循环执行下列步骤:
(1) 根据簇对象均值,将对象划归到类似簇中;
(2) 更新簇均值和簇中对象均值;
(3) 计算熵测度权重距离d(xk,ci),直到d(xk,ci)值稳定为止;
步骤9输出red、属性簇及d(xk,ci)。
3 改进MULCA算法的入侵检测
多层凝聚算法由于独特的算法结构导致算法的计算复杂度增加,因此,对于大数据量的入侵数据检测,降低数据冗余对于算法的实际应用意义非凡[10]。第1、2节着重介绍了α核心集的多层凝聚算法以及粗糙集熵属性约简的有关定义和算法步骤,本节主要思想是基于粗糙集熵属性约简的数据预处理并结合α核心集的多层凝聚算法实现入侵数据的有效检测。基于改进MULCA算法的入侵数据检测算法框架如图2所示。

图2 入侵检测算法过程
基于改进MULCA算法的入侵数据检测步骤如下:
步骤1输入待分类的入侵数据集X及所需要聚类的个数K;
步骤3利用熵测度权重距离d(xi,xj)取代定义1相似度定义,令μ(xi,xj)=d(xi,xj),利用粗糙集熵属性约简后的数据集作为多层凝聚算法的输入数据集X′;

步骤5参照第1节有关定义执行细化过程,对数据集进行分类,输出最终的入侵数据分类结果C={C1,C2,…,Cm}。
4 仿真实验与分析
4.1算法测试
仿真对比实验,选取文献[11]PROCLUS算法、文献[12]EWKM算法、文献[13]FWKM算法和文献[14]FCS四种算法作为对比算法。本文对比实验采用文献[11]使用的数据合成方法进行实验数据生成。


表1 仿真数据集实验参数
由表2对比结果可以看出,RSMULCA算法在四种对比测试数据上的识别精度式中最高。作为对比算法在某些数据集上识别精度接近于RSMULCA算法,如FCS算法在数据集DB1和DB4上的聚类识别精度,在个别数据集上其算法性能受制于参数影响,如在数据集DB2上,α=2.1上FCS算法的识别精度为0.9582,但是当α=3.0时,识别精度降为0.8846,在其他数据集上参数依赖程度不大。从表2对比数据中可看出,PROCLUS、EWKM和FWKM三种算法也有不同程度的参数依赖性,相比RSMULCA算法对实验的自适应能力要强于对比算法。

表2 聚类识别精度对比
因为PROCLUS算法是基于数据抽样的,仿真过程中算法每次运行结果都不同。EWKM、FWKM和FCS算法不会出现此情况。对于同一实验数据,5种算法各运行20次取平均性能。
下面主要测试算法聚类时间及数据点数、维数和簇数三个参数对RSMULCA算法运行时间的影响程度,仿真结果如图3所示。
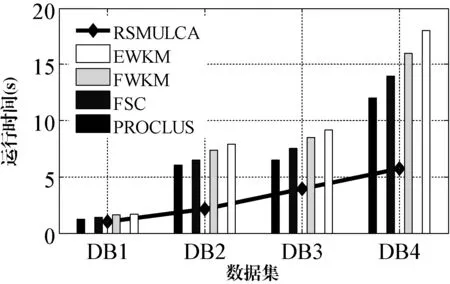
图3 运行时间对比结果
图3给出几种对比算法的运行时间对比情况,从中可以看出,RSMULCA算法在运行时间上要优于所采用的对比算法,主要原因是RSMULCA算法采用粗糙集熵属性约简算法有助于降低分类数据的计算数据量。其他几种算法运行时间情况是:PROCLUS优于FCS算法,两者优于EWKM和FWKM算法,而FWKM要优于EWKM算法,主要原因是EWKM算法参数确定需要较复杂的计算步骤。
4.2入侵检测实验分析
在以往入侵分类算法的文献报道中,KDDCUP99数据库[15,16]是常用到的实验对象,为了方便与相关文献算法的对比,这里依然沿用其他文献的做法,以KDDCUP99数据库作为实验对象。该数据库最具有代表性的主要有4种网络入侵数据:DOS、Probe、U2R和U2L。这四种类型网络入侵数据信息如表3所示。

表3 测试数据选取数量
在对入侵检测算法进行评价时,常用到的评价指标主要有检测率和错检率。所谓检测率指的是算法检测出的入侵数据个数与入侵数据总数的比值;错检率指的是被误报为入侵的正常数据数量与正常数据总数的比值。对于表3选取的测试数据集,分别选取RSMULCA算法、PIDE[10]算法和KTID算法[15]的入侵检测分类结果进行比较如表4所示。

表4 分类结果对比(%)
检测率如式(15)所示,错检率如式(16)所示[13]:

(15)

(16)
表4所示分别为RSMULCA、PIDE和KTID三种算法在标准测试数据库上,根据式(15)、式(16)的实验对比数据。从该对比数据可以看出,在DOS、U2R、U2L和Probe四种数据分类中,RSMULCA算法在检测率和错检率上的识别性能均要比PIDE和KTID算法更优异。PIDE与KTID相比,前者在U2L和U2R两种网络入侵数据上的识别效果要优于KTID算法。在错检率方面,PIDE算法在U2L和DOS两种入侵数据上的识别效果要优于KTID算法。总体上,PIDE入侵检测算法和KTID入侵检测算法的性能各有千秋。通过数据对比可以得到这样的结论,本文所提RSMULCA入侵检测算法是可行的,能够有效地提高入侵检测的识别率,降低错检率。
为进一步验证RSMULCA算法的入侵数据识别性能优势,分别选取MULCA和UMID[17]两种算法进行对比。标准测试数据库仍选用KDDCUP99,入侵数据数量如表3所示,仿真对比结果如图4、图5所示。

图4 三种算法的检测率对比

图5 三种算法的错测率对比
图4给出RSMULCA、MULCA和UMID三种算法的检测率对比结果。可以看出,RSMULCA算法在DOS、U2R、U2L和Probe四种入侵数据上的检测准确率性能均要比MULCA和UMID两种对比算法优秀。而后两种算法,在DOS和U2R两种入侵方式中,MULCA算法的入侵数据检测率优于UMID算法,在U2L和Probe两种入侵方式中,UMID算法的入侵数据检测率优于MULCA算法。图5给出RSMULCA、MULCA和UMID三种算法的错检率对比结果。可以看出,RSMULCA算法在四种入侵数据上的检测错误率要低于另外两种对比算法,其中在U2R、Probe和U2L三种攻击方式中MULCA算法的入侵数据错检率要高于UMID算法。综上所述,实验结果表明RSMULCA算法对入侵数据检测是可行和高效的。
5 结 语
从提高入侵检测系统对新的入侵数据检出率的角度,结合文献[1]提出的α核心集的多层凝聚算法设计了无监督的入侵检测分类系统,并且为了解决多层凝聚算法计算复杂度过高的问题,采用基于熵重要测度权重粗糙集对入侵数据进行预处理,并和多层凝聚算法实现有效对接,降低数据维数防止“维数陷阱”,提高了分类的准确率。
[1] 马儒宁,王秀丽,丁军娣.多层核心集凝聚算法[J].软件学报,2013,24(3):490-505.
[2]ChiragM,DhirenP,BhaveshB.Asurveyofintrusiondetectiontechniquesincloud[J].JournalofNetworkandComputerApplications,2013,36(1):42-57.
[3]FaraounKM,BoukelifA.InternationalJournalofComputationalIntelligence[J].NeuralNetworksLearningImprovementusingtheClusteringAlgorithmtoDetectNetworkIntrusions,2007,3(2):161-168.
[4]BoppanaRV,SuX.OntheEffectivenessofMonitoringforIntrusionDetectioninMobileAdHocNetworks[J].IEEETransactionsonMobileComputing,2011,10(8):1162-1174.
[5]MaLC,MinY,PeiQQ.ADynamicIntrusionDetectionMechanismBasedonSmartAgentsinDistributedCognitiveRadioNetworks[J].GeneticandEvolutionaryComputing,2014,238(2):283-290.
[6] 杨雅辉,黄海珍,沈晴霓.基于增量式GHSOM神经网络模型的入侵检测研究[J].计算机学报,2014,37(5):1216-1224.
[7]ValenzuelaJ,WangJH,BissingerN.Real-timeintrusiondetectioninpowersystemoperations[J].IEEETransactionsonPowerSystems,2013,28(2):1052-1062.
[8]AnilKB,BipanT,JayashriR.OptimizationofSensorArrayinElectronicNose:ARoughSet-BasedApproach[J].IEEESensorsJournal,2011,11(11):3001-3008.
[9] 唐继勇,宋华,孙浩.基于粗糙集理论与核匹配追踪的入侵检测[J].计算机应用,2010,30(5):1202-1205.
[10]FungCJ,ZhangJ,BoutabaR.EffectiveAcquaintanceManagementbasedonBayesianLearningforDistributedIntrusionDetectionNetworks[J].IEEETransactionsonNetworkandServiceManagement,2012,9(3):320-332.
[11]AggarwalCC,ProcopiucC,WolfJL.Fastalgorithmforprojectedclustering[C]//Proc.oftheACM.SIGMOD.NewYork:ACMPress,1999:61-71.
[12]JingL,NgMK,HuangJZ.Anentropyweightingk-meansalgorithmforsubspaceclusteringofhighdimensinoalsparesedata[J].IEEETransonKnowledgeandDataEngineering,2007,19(8):1-16.
[13]HnangJZ,NgMK,RongH.Automatedvariableweightingink-meanstypeclustering[J].IEEETransonPatternAnalysisandMachineIntelligence,2005,27(5):657-668.
[14]GaoG,WuJ,YangZ.Afuzzysubspaceclusteringalgorithmforclusteringhighdimensionaldata[J].LectureNotesinComputerScience,2006,24(3):271-278.
[15]MengYX,LiWJ.Towardsadaptivecharacterfrequency-basedexclusivesignaturematchingschemeanditsapplicationsindistributedintrusiondetection[J].ComputerNetworks,2013,57(17):3630-3640.
[16]HassanzadehA,XuZY,RaduS.PRIDE:PracticalIntrusionDetectioninResourceConstrainedWirelessMeshNetworks[J].InformationandCommunicationsSecurity,2013,23(3):213-228.
[17]ShakshukiEM,SheltamiTR.EAACK—ASecureIntrusion-DetectionSystemforMANETs[J].IEEETransactionsonIndustrialElectronics,2013,60(3):1089-1098.
INTRUSIONCLASSIFICATIONFORALPHAMULTILEVELAGGREGATIONBASEDONROUGHSETWITHENTROPYIMPORTANTMEASUREMENTWEIGHT
WangXingzhu1YanJunbiao1ZengQinghuai2
1(Furong College,Hunan University of Arts and Science,Changde 415000,Hunan,China)2(Modern Educational Technology Center,Hunan University of Arts and Science,Changde 415000,Hunan,China)
Intrusiondetectionhaslargedataamount,andthemultilevelaggregationclusteringalgorithmofαcore-setpresentedbyliterature[1]hastoohighcomputationalcomplexity,whichaffectsthepracticalapplication.Aimingatthisproblem,weproposedanintrusionclassificationalgorithmforαcore-setmultilevelaggregationclustering,whichisbasedonroughsetwithentropyimportantmeasurementweight.First,basedonentropyimportantmeasurementweightmethoditusestheroughsettocarryoutpretreatmentandattributereductiononintrusiondetectiondata,andtodecreasedatadimensionforpreventingthealgorithmfromfallinginto"dimensiontrap";Secondly,itreplacestheEuclideandistanceofalphamultilevelaggregationclusteringalgorithmwithentropyimportantmeasurementweightdistancetocomputetheindividualsimilarity,andimplementstheeffectivedockingofoutputdataofroughsetandalphamultilevelaggregationclusteringalgorithm;Finally,itwasdemonstratedthroughexperimentsthattheproposedalgorithmcouldmoreeffectivelydothedetectionandclassificationonKDDCUP99standarddatabase.
EntropyImportantmeasurementWeightRoughsetMultilevelaggregationclusteringIntrusiondetection
2014-11-23。湖南省自然科学基金项目(14JJ2124)。王兴柱,副教授,主研领域:网络与信息安全,现代教育技术。颜君彪,教授。曾庆怀,副教授。
TP311
ADOI:10.3969/j.issn.1000-386x.2016.03.075
