基于可变点的数据展现子系统定制化开发方法
2016-09-26邢戎飞沈立炜赵文耘
邢戎飞 沈立炜 赵文耘
(复旦大学软件学院 上海 201203) (上海市数据科学重点实验室(复旦大学) 上海 200433)
基于可变点的数据展现子系统定制化开发方法
邢戎飞沈立炜赵文耘
(复旦大学软件学院上海 201203) (上海市数据科学重点实验室(复旦大学)上海 200433)
数据密集型系统已经广泛应用于不同的行业与领域。在分层的数据密集型系统中,数据展现子系统是其重要的组成部分。使用软件产品线的方法开发一组具有相似需求的数据展现子系统能够有效提高开发人员的效率。然而,传统的软件产品线构造与定制方法并不能完全适用于该类子系统的可变性特性。针对这种情况,提出一套基于可变点的数据展现子系统定制化开发方法。该方法首先对软件产品线特征元模型进行了扩展,并基于该元模型总结出一套面向需求文档的特征建模过程和可变点实现技术方案。另外,该方法提出两阶段的定制过程支持子系统的定制化开发。最后,通过一个财务数据系统中的数据展现子系统实例验证了方法的可行性与有效性。
软件产品线数据展现子系统可变性
0 引 言
数据密集型系统是以数据为核心,对数据进行收集、分析、处理与展现的软件应用系统[1]。当前,数据密集型系统已经广泛应用于电信、金融、政府、制造等,积累了大规模数据的行业与领域。就数据密集型系统本身的结构而言,它一般具有系统规模大、多应用类型、多层次结构等特点。其中,多层次特性表示一个完整的数据密集型系统,可以被划分为不同实现层次,并由不同的子系统按照一定的规则进行集成后得到。在组成数据密集型系统的一组子系统中,数据展现子系统主要负责以各种方式可视化地展现系统所处理的数据以及处理的结果,例如一种通行做法是以报表的形式展现数据。报表本身又可分为多种类型(由国家、行业规定的报表,或者企业自定义的报表),每种报表也可由不同的数据项组合而成。另外,图表也是一种较为常见的数据展现形式。
通过分析不同的数据密集型系统,我们发现这些系统在数据展现方面具有类似的功能,例如类似的数据预处理以及数据集展现方式等。此外,还包括权限控制等这一类与数据处理、显示无直接关联,但影响子系统使用的功能[2,3]。另一方面,不同的应用对数据展现的需求也存在差异,例如商业报表系统主要以表格的形式展示数据,而地质信息展示平台则需要根据地理坐标等数据在地图上进行绘制。
为了降低重复开发数据展现子系统的工作量,保持数据展现效果的一致性,可以采用软件产品线开发方法以定制化的方式来开发一个数据展现子系统。软件产品线是针对特定领域的、具有一组相似特征,并从预先生产的核心资产开发而来的软件产品的集合[4,5],其开发方法依赖于领域核心平台,通过对领域内的可变性进行定制的方式开发出单个软件产品。相比于传统的面向领域的软件产品线,集成在不同领域应用产品中的数据展现子系统可以视作为一种跨领域的特殊类型的软件产品线。一方面,这种产品线同样涉及需求的共性/可变性分析、可变点的定制方案设计等活动;另一方面,数据展现子系统中的可变性类型更为丰富,例如,商业报表系统在生成的报表范围以及单个报表的内部结构等不同层次方面都存在可变性,同时针对这些可变点的定制也涉及更多的角色与时间点。因此,需要针对这些特性化的需求改造软件产品线的分析与构建过程以及特定的数据展现子系统的定制化开发过程。
基于以上实际需求,本文旨在搭建一个面向数据展现子系统的软件产品线,并归纳出基于可变点的数据展现子系统的定制化开发方法。首先,本文提出一种扩展可变性类型的软件产品线特征模型元模型,该元模型从数据功能维度和数据展现维度对特征属性进行了扩充,涵盖更多语义。其次,基于该元模型总结出一套针对需求文档的特征建模过程,并为识别出的不同类型的可变性提出了相应的可变点实现技术方案。再次,为了支持基于可变点的子系统实例的定制化开发,提出一套两阶段(开发者定制和用户定制)的可变点定制过程。该过程用于确定在某个阶段应被定制的可变点,并且保证可变点定制结果的一致性。最后,本文基于两阶段定制过程,设计并实现一个半自动化的可变点定制工具。另外,使用该工具配置了一个数据示例系统,验证了可变点实现方案与定制过程的可行性。
1 相关工作
与本文相关的工作分为数据展现子系统的构造以及软件产品线开发方法两个方面。
文献[2,3]分别介绍了基于Web的多维数据平台和地质数据平台的构造过程。开发者基于分模块的原则针对单个数据展现系统分析其需求并设计其架构,设计出的模块包括数据收集、数据存储、数据访问、数据处理和数据展现等。与之相比,本文的工作面向一组具有相似需求的数据展现子系统,采用软件产品线的方法分析其需求的共性与可变性,并以可变点定制的方式支持快速的应用产品开发。
传统的软件产品线开发方法涉及从需求文档到特征模型、再到软件体系结构的映射过程。在软件产品线开发中,特征建模是反映产品线中共性和可变性的一种手段,目的是将领域需求映射为用分层的树状结构表示的特征模型[6,7]。特征建模中一项重要的工作是可变性识别。可变性是指产品线所涵盖的各个产品之间的差异性[8]。可变性一般会关联到某个可变点上。可变点是可变性在产品线所覆盖的软件产品中的具体体现,而变体则是软件产品中各个可变点上各种特定的可变性实例[9]。Kang提出的FORM方法对从特征模型到系统设计的过程进行了细化[10],将领域工程划分为领域分析和领域结构设计[11]。在领域分析中,开发者需要从特征模型中抽取候选对象,并将这些候选模块组织成对象模型。在领域体系结构设计中,将不同层次的软件体系结构抽象为逐步细化的不同层次的模型:子系统模型、进程模型和模块模型。此外,不同的特征从不同的层次对问题域进行了抽象,对于这些不同的特征,可以将其建模为不同的对象。文献[11]中,提出了一系列对不同类型特征建模的原则,如将服务特征建模为服务状态隐藏对象,将操作特征建模为用户角色对象等。文献[12]提出了一种改进过的面向特征的模型映射方法,该方法将软件体系结构分为三种视图,使不同类型的特征对应于不同的视图,即软件开发的不同阶段。
对已经建模完成的特征模型进行实现也是软件产品线中一个重要的主题。在文献[13]中,对影响可变性实现的因素进行了阐述,对从可变性的识别到实现的整个过程进行了详细的介绍,并提出了一些对于不同可变性的实现技术,如常量条件、变量条件等。在文献[14]中,针对不同的特征约束形式推荐了模块的设计方法。在代码级别的实现方面,文献[15,16]进行了较为详细的阐述,包括聚合/代理、继承、框架、反射等面向对象的实现方法,也有面向方面的实现方法。
2 可变性扩展及特征元模型
2.1数据展现子系统的特点分析
基于对数据密集型系统的实际开发经验,软件开发人员发现这些不同的数据密集系统存在结构上的共性,总结出分层、分模块开发的原则。这样能够使不同的层次/模块之间只通过接口和固定的数据格式与约束进行通信,降低模块之间的耦合度。与此同时,这种分层、分模块的开发方式也能够提高系统的可维护性和可复用性。当用户需求发生变动、某个模块的结构或功能发生变化时,其他模块并不会受到影响。
在数据展现子系统中,数据展现部分,或者称为数据展现模块的主要功能是将从数据存储模块或者数据处理模块中的得到的数据集合以约定好的方式展现给使用者。此外,还可能存在一些辅助功能,如用户权限设置,打印格式设置等。本文认为,数据展现模块的输入是一个符合预先定义好的格式的数据集,输出是不同类型的数据显示。
在开发的过程中,开发者需要和用户合作对输入数据集的格式进行定义。对于某个特定的数据展现子系统而言,会存在具有多个不同定义的数据集;而对于两个或者一组数据展现子系统而言,会出现它们的数据集定义大部分相同,只存在少许差异的现象。图1列出了两个商业系统的数据集部分定义,该数据集以报表的形式出现。对比之后可以看出,两个数据集定义大部分都相同,只是在“本月数”大项之下所细分的方式不同。当有多个用户的数据集定义出现如示例1和示例2中所示的“大部分相同,少部分不同”的情况时,开发人员可以定制一个通用模版,将部分的数据集定义工作交由具体的用户完成,减少开发人员的工作量。这在开发多个相似系统时对于人力成本的节约尤为突出。


图1 数据集及模板示例
2.2特征元模型
本文的目的是使用产品线来进行面向不同领域,不同行业的数据展现子系统产品的开发。针对数据展现子系统的特点,我们对可变性类型和约束类型进行了不同维度上的扩展。加入扩展可变性类型和扩展约束类型的的特征元模型如图2所示。在该元模型中,特征模型类FeatureModel代表着整个特征模型,其中包含若干对应单个特征的类Feature。一个Feature可以是复合的,即可以包含若干个其他Feature。当存在Feature间的聚集关系时,这个关系对应的是特征模型中特征之间的层次关系。和经典的特征模型相同,在本文提出的元模型中,层次关系分为Mandatory、Optional、Alternative与Or四种,由VariableType属性进行描述。

图2 扩展的特征模型元模型
首先,我们对特征的类型进行了扩展。在元模型中,特征类型由FeatureType属性描述,分为数据集特征和非数据集特征。我们将描述数据集性质的特征称为数据集特征。例如,对一张报表的表头、细目等元素的展现等。相对地,描述系统中除数据集之外其他部分的特征称为非数据集特征。不同领域的不同应用产品对数据集有不一样的要求,根据前文所述数据集的特点,又可以将数据集特征细化为组级特征和组内特征。组级特征对应于数据集本身的定义,组级特征将数据集作为一个整体来分析,主要关注该数据集和数据展现子系统的关系;组内特征对应于数据集内部的定义,组内特征主要关注数据集内部的定义和不同数据集之间的相似关系。在元模型中,FeatureLayer属性描述的是特征所处的层级,其取值范围为NULL、GroupLevel和InGroupLevel。当特征不属于数据集特征时,其取值为NULL;当特征属于数据集特征时,则根据其描述的内容选择取值为GroupLevel或者InGrouplevel。
其次,我们对特征的依赖关系进行了扩展。在元模型中,约束由Constraint关系描述,Target属性指向和当前Feature存在约束关系的另一个Feature实体,其中的ConstraintType属性取值在Require、Exclude、Influence和Sequence中选择。在数据展现子系统产品线中,扩展增加了影响和顺序关系。影响关系表示的是模型中一个特征变体的实现手段或者配置会对另一个特征变体的实现造成影响,但并没有两个变体必须同时绑定的限制。例如在数据展现子系统中,对数据集的合法性检查公式会受到数据集自身定义的影响,那么可以称“数据集定义”对“数据集合法性检查”具有影响关系。顺序关系表示的是两个特征所对应的功能在软件使用过程中固定的执行先后顺序。例如,在每次进行数据集显示之前必须对当前用户的权限进行检查,以确定该用户可以查看哪些显示的数据,那么称“用户权限检查”和“数据集显示”具有顺序关系。
最后,我们对特征的绑定属性进行了扩展。在元模型中,绑定属性由BindOption关系描述,其中包含BindTime和BindRole属性。BindTime属性代表着该特征的绑定时间,其取值范围为Compile-Time、Load-time和Run-Time。BindRole属性代表着该特征的绑定者,其取值在Developer和User中选择,分别代表着开发者绑定该特征和用户绑定该特征。通常来讲,产品的组装及变体的绑定是根据各个可变点约定的绑定时间由开发者进行定制。在实际的应用场景中,会出现通过交互性机制使用户决定可变点变体绑定的情况。对这类可变点的分析、建模及实现不能仅仅依靠可变点绑定时间属性,因为这样并不能识别该可变点是由用户负责选择变体还是由程序根据条件自行选择。在本文中我们扩展增加了绑定角色属性。
3 面向文档的特征建模过程及特征实现设计
数据展现子系统产品线的开发流程总体遵循经典软件产品线的开发流程,需要经过需求规约、明确数据展现子系统范围、特征建模、特征实现等一系列活动。首先,通过分析功能描述文档和数据集定义文档,可以得到特征的规约描述及特征之间的层次关系。其次,通过对用例文档进行分析,可以得到特征之间的约束关系。通过这两步分析,开发者可以确定数据展现子系统的特征模型并将特征模型以特定方式进行存储。最终可根据存储的特征模型采取不同的策略提出特征的实现方案。
在具体的执行过程中,相比经典软件产品线,数据展现子系统产品线对数据集特征和非数据集特征需要有不同的规约和实现策略,这是由数据集本身的性质所决定的。数据集特征有以下两个特点:(1) 包含的特征数量大。在数据密集型系统中,需要被处理并显示的数据集其类型和数量都可能会很庞大。(2) 数据集定义变化迅速。数据密集型系统的业务覆盖面和业务逻辑通常会不断的变化,导致在业务中使用的数据集集合持续的发生改变。
3.1特征规约
对于非数据集特征,其特征规约的来源为功能描述文档。功能描述文档主要包含对数据展现子系统所能完成的功能的列举,对应于一组能够满足用户需求的功能项。开发人员遵循一定的规则对特征进行规约,如将功能描述对应为功能特征,将功能或整个系统的约束描述对应为非功能特征等。随后通过产品—特征矩阵方法确定特征之间的层次关系,以及每个特征的可变性类型,初步确定特征模型。
对于数据集特征,其特征规约的来源为数据集定义文档。数据定义文档不仅和需求文档一样描述了该数据集的名称和在系统中表示的含义,而且定义了数据集内部的具体组织方式。对数据集特征的规约也要分为两部分:数据集描述和内部结构定义。数据集介绍部分的规约可以参照非数据集特征的规约方法。对于数据集内部结构,可以使用XML进行定义。一个使用XML的数据集内部结构定义应如下所示。
…
…
…
我们使用
在对于数据展现子系统的分析中,曾经提到在实际场景中会出现需要对多个数据集抽象出一个模版,在不同用户对系统的使用过程中各自进行定制的情况。在数据集定义中本文引入了抽象类型的概念,类似于面向对象技术中的抽象类,对于抽象部分可以通过不同的实现手段形成用户需要的不同的数据集。如果一个
若要确定哪些块、复合属性、单个属性属于抽象类型,那么需要由开发人员对相似的数据集进行分析,并对其中数据集定义的重合部分进行提取,得到带有抽象部分的数据集定义。本文把每个数据集看作一个特征,被提取出的数据集模版成为这些相似数据集的父特征,这些父特征覆盖了多个产品。在产品的定制中,存在抽象部分的特征需要被其覆盖的一组产品分别定制,即对组内特征进行的定制。而由于在定义中不存在抽象部分的数据集一般对应于单个产品,因此它们不需要被再次定制。
3.2特征约束确定
表示需求的特征之间的约束关系能够从用例文档中获得。首先对于需求文档中的每一个用例,要分析出该用例对应哪些特征以及特征的执行顺序。其次,要对该用例所包含的特征进行分析,确定是否存在约束关系。开发者可以根据以下用例场景来识别约束关系的类型。
1) 如果某个特征A在执行中需要“用到”其他的特征B或者B的执行结果,即在用例流程中去掉B后,A不能正确运行,则认为特征A依赖特征B,记作require(A,B)。
2) 如果某个特征A和特征B同时出现在一个用例之中时,A和B的执行关系总是确定的,并且A总是在前或者B总是在前,则认为特征A和特征B具有顺序关系,记作Sequence(A,B)或Sequence(B,A)。
3) 如果在用例中,特征A的变体或者参数选择会对特征B的执行逻辑或顺序产生影响,则认为特征A影响特征B,记作Influence(A,B)。
在对每一个用例进行分析后,我们可以得到特征—特征约束对,并对特征的Constraint属性集进行赋值。此外,在该步骤中还可以确定Bind-Time和Bind-Role的值。通常在为用户部署该子系统之前就需要确认的变体所在可变点的Bind-Role为Developer,用户在得到该子系统之后才能决定的变体所在可变点的Bind-Role为User。在系统开始运行前就需要确定的变体所在可变点的Bind-Time一般为Compile-time,在系统启动时才进行一次或者永久设置的变体所在可变点的Bind-time为Load-Time,在系统运行中需要用户动态地进行设置变体所在可变点的Bind-Time为Run-time。
3.3特征模型存储
软件产品线是在不断演化的,需要对这些可变点进行管理使之能适应未来可能的演化。同时,用户的需求也会发生变化,这有可能造成所绑定变体的改变。本文中使用特征配置库对特征进行管理。该配置库可以存储可变点的位置和对变体的选择,并保证了系统本身的相对独立。当变体绑定发生改变时,可以只对配置库进行改变而不侵入代码本身。
一般来说,特征配置库要存储以下四种内容:(1) 存储特征模型,具体的定义如图2中的元模型所示,包括特征的层次关系、特征的属性以及特征之间的约束关系。(2) 数据展现子系统产品线所覆盖的专业领域软件产品,它体现为一个产品列表。(3) 存储特征的范围矩阵,即每个特征覆盖的产品。(4) 特征实现方法,不同类型可变特征的存储方式与内容各不相同,例如可通过配置文件、参数或者数据集定义的方式。一个较为完整的特征配置库定义如下所示。
//具体定义见特征模型元模型定义
其中,
3.4特征实现
对特征的实现同样要针对数据集特征和非数据集特征两部分分别进行。对于非数据集特征,其实现方式可以借鉴文献[15-17]中提出的原则,对不同类型的特征,如Mandatory、Optional、Or和Alternative可以使用不同的方法。例如,可以使用设计模式、继承、参数化方法和面向方面编程等方法进行实现。
对数据集特征的实现指的是对组内特征的定制,即对带有抽象块、抽象复合属性和抽象属性的数据集模版的定制。通常来说对于这样的组内特征的定制场景都是相对一致的,即改变数据集中部分内容的定义。对于这样的场景可以使用配置文件进行实现,数据集特征可以通过对配置文件的修改完成对变体的绑定。一段典型的数据集特征实现代码如下所示。每个数据集实例对应一个ConfigFile配置文件,当该实例初始化时,读入数据集模版DataSetTemplate,并由用户配置其中的抽象部分。初始化完毕之后,基于该数据集可执行填表、显示等一系列操作。
Public Class DataSetTemplate{
Static ConfigFile template;
}
Public Class DataSet{
DataSet(){
ConfigFile AFile = DataSetTemplate.template;
AFile.ConfigAbstract();
//配置抽象部分
AFile.SaveAs(filename);
//存储配置文件
}
}
Public Class Report{
CreateDataSet(){
DataSet D;
D.ReadConfigFile(filename)
D.Fill();
//填表
D.Show();
//显示
}
}
4 两阶段可变点定制过程
本文提出了两阶段配置数据展现子系统的策略,即开发者配置和用户配置,分别通过开发者配置工具和用户配置工具完成。开发者配置工具主要完成的工作有两项:(1) 对Bind-Role属性值为Developer的特征进行配置。(2) 选择用户配置工具可以选择的变体范围。而用户配置工具的主要工作就是从开发者配置工具选择的变体范围中进行选择和配置。两阶段的可变点定制流程如图3所示。

图3 两阶段的定制流程
从两个角度来明确特征的总体定制顺序。一方面,对于绑定角色不同的特征存在定制顺序。在产品线的每一次迭代过程中,开发者定制在前,用户定制在后,开发者定制的结果是用户定制的前提。另一方面,具有关联的特征之间存在定制顺序。对绑定角色的定制顺序算法如算法4所示,该算法根据特征的绑定角色属性对特征进行分类。首先,要获得标注为开发者配置的特征列表DevConfigList,由开发者按照该特征列表进行配置。其次,需要获得覆盖了当前专业领域产品的特征列表UserConfigList,该列表根据特征配置库中的特征范围部分得到。最后用户根据UserConfigList列表对相应特征进行定制。
For each Feature in Repository.Featuremodel
If Feature.Bind-Role = Developer
Add Feature to DevConfigList
Else If Feature.Bind-Role = User
Add Feature to UserConfigList
ConfigFeature(DevConfigList
For each Feature in UserConfigList
If Product not in FeatureScope.Feature.Product
Delete Feature from UserConfigList
ConfigFeature(UserConfigList
而对于已经确定的特征列表,如DevConfigList,UserConfigList的特征定制顺序算法如算法5所示。在定制中,有以下几个原则可以作为确定特征顺序的参考。(1) 对于特征层次关系,定制的顺序为先定制子特征,再定制父特征。(2) 对于特征依赖关系 require(A,B),定制的顺序为先定制被依赖特征B,再定制特征A。(3) 对于特征顺序关系A 和特征B之间的顺序关系Sequence(A,B),按照其顺序的先后关系对特征A、B进行定制。(4) 对于特征影响关系influence(A,B),按照先定制影响特征A,后定制被影响特征B的顺序进行。
Set 0 to SeqMatrix
For each Feature in List
Set 1 to SeqMatrix(Feature, Father(Feature))
For each Constraint in Feature
If Constraint.ConstaintType is require or Sequence or influence
Set 1 to SeqMatrix(Feature, Constraint.target)
For each Feature in List
If Colomn(Feature) = 0
Set Feature to StartList
For each Feature in StartList
Config(Feature)
If SeqMatrix(Feature, NextFeature) = 1
Set NextFeature to StartList
Delete Feature from StartList
5 工具与实例
5.1工具实现
本文对数据展现子系统的定制需要经过开发者定制和用户定制两个阶段,可变点定制工具也分为开发者定制工具和用户定制工具两部分来实现。开发者定制工具和用户定制工具的设计结构如图4所示。
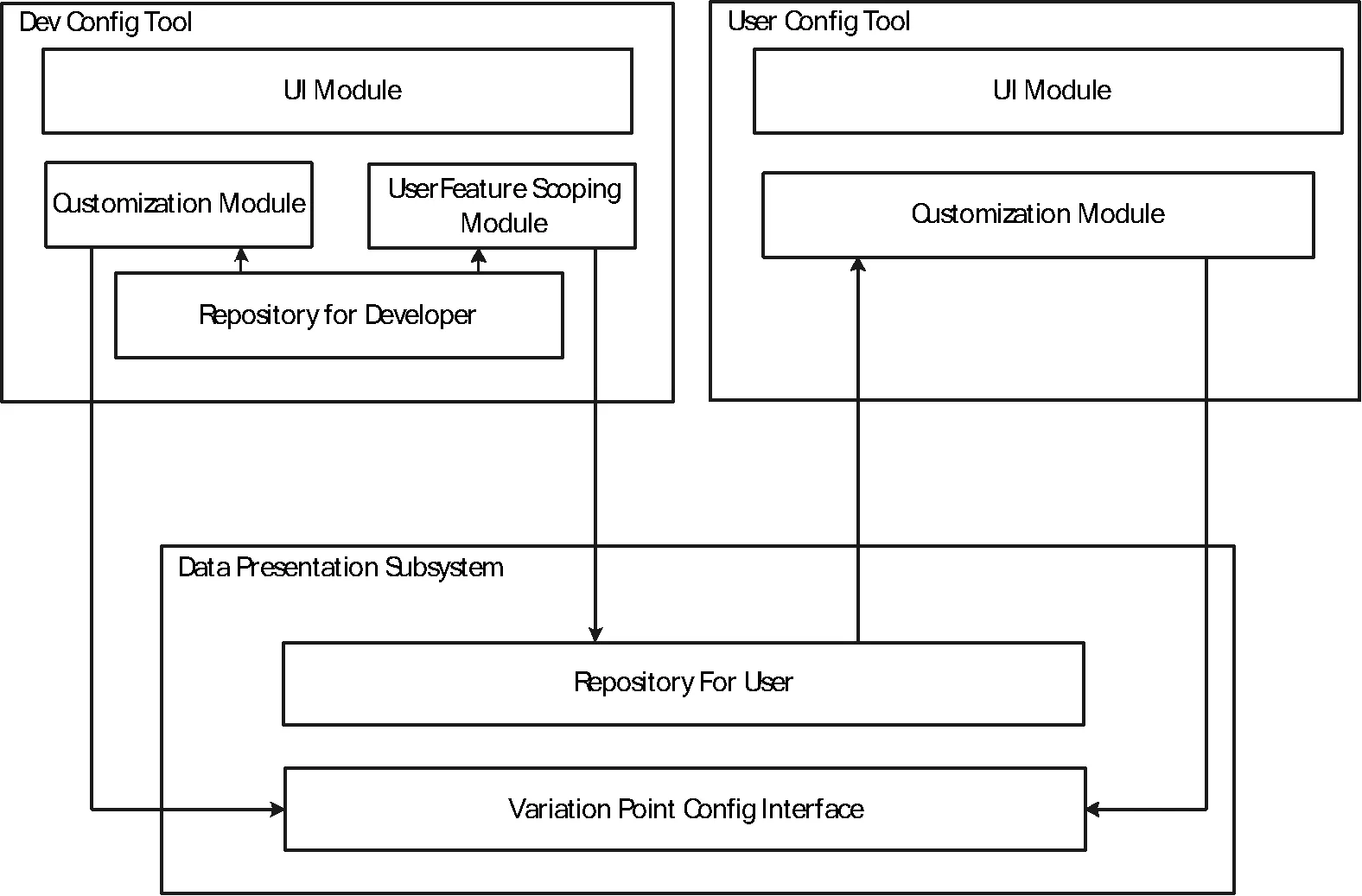
图4 开发者定制工具和用户定制工具的结构
在实际的定制流程中,数据展现子系统向定制工具提供一个定制接口,使定制工具可以对特征进行变体绑定。不同特征接口具有不同的实现方法,例如由开发者工具维护一个整体的特征库,其中存放了覆盖整个数据展现子系统产品线的特征定义。当需要进行某一个具体的数据展现子系统的定制时,首先由开发者工具在总体的特征库中进行选择,对Bind-Role属性为Developer的特征进行定制,然后将选择好的Bind-Role属性为User的特征及其相关信息复制到特定的数据展现子系统中的特征库,并把该未定制完成的子系统分发给用户。用户收到该子系统后,通过用户配置工具读取子系统中的配置库信息,并根据工具提供的特征绑定顺序依次进行定制。
5.2实例分析
商业报表系统是面向企业或事业单位的一个专业领域应用系统,其中存储有大量以报表形式存在的数据集。同时,该系统具有数据展现的需求。本节以商业报表系统为示例进行系统定制,以验证配置工具和配制方法的有效性。在进行定制之前,要先进行特征的建模和约束确定工作。对数据展现子系统的功能进行分类总结和分析建模后,生成的非数据集特征模型如图5所示。由于篇幅原因,本文仅在图6中展示数据集特征所对应的部分XML语句。

图5 非数据集的特征模型

图6 数据集特征的部分XML表示
对数据展现子系统的定制取决于存放在特征配置库中的对数据集特征和非数据集特征的分析结果,由配置工具根据算法4和算法5中所述算法确定定制步骤,并引导开发者和用户进行可变点配置工作。在开发者和用户的两阶段定制完成后,我们对生成的数据展现子系统进行测试,其功能符合预期。
6 结 语
数据展现是普遍存在于数据密集型系统中的一类功能,其中包含了一些类似的对数据集的操作。基于此前提本文将数据展现模块视为集成在其他数据密集型系统之中的、相对独立的子系统,这些子系统具有功能上的相似性。基于这些系统间的共性与可变性,本文采用软件产品线方法搭建可复用平台并通过定制化的手段开发单个数据展现子系统。为了应对数据展现子系统需求的特性,本文对特征模型元模型进行了扩展,提出了对应的实现手段和两阶段的数据展现子系统定制方法。最后,通过一个定制的实例验证了本文所提出方法的可行性。目前本文的工作涉及的需求场景较为简单,而且在实际情况中数据展现子系统一般不会独立存在,而是被集成在特定专业领域的数据密集型系统之中。在未来的工作中,不仅要对更复杂的需求场景进行深入分析,扩充相应的实现方案,而且需要考虑开发完成的子系统与其他系统的集成问题。
[1] Wang L Z,Tao J,Ranjan R,et al.G-Hadoop:MapReduce distributed data centers for data-intensive computing[J].Future generation computer systems-the international journal of grid computing and escience,2013,29(3):739-750.
[2] 曹剑.基于Web的多维数据工具的设计与实现[D].华中科技大学,2009.
[3] 林关煜.地质数据的展现,传输及格式转换的相关研究[D].中国地质大学,2013.
[4] Clements P,Northrop L.Software product lines: practices and patterns[M].Reading:Addison-Wesley,2002.
[5] Nyholm C.Product line development-an overview[R].Extended report for “Building reliable component-based systems”,I. Crnkovic, M. Larsson (eds), Artech House,2002.
[6] Reid Turner C,Fuggetta A,Lavazza L,et al.A conceptual basis for feature engineering[J].Journal of Systems and Software,1999,49(1):3-15.
[7] Chen K,Zhang W,Zhao H,et al.An approach to constructing feature models based on requirements clustering[C]//Requirements Engineering,2005.Proceedings.13th IEEE International Conference on.IEEE,2005:31-40.
[8] Jaring M,Bosch J.Representing variability in software product lines:A case study[M]//Software product lines,Springer Berlin Heidelberg,2002:15-36.
[9] Van der linden F,Pohl K.Software product line engineering:foundations,principles,and techniques[M].Springer-Verlag Berlin and Heidelberg GmbH & Co.K,2005.
[10] Lee K,Kang K C,Chae W,et al.Feature-based approach to object-oriented engineering of applications for reuse[J].Software-Practice and Experience,2000,30(9):1025-1046.
[11] Kang K C,Kim S,Lee J,et al.FORM:A feature-oriented reuse method with domain-specific reference architectures[J].Annals of Software Engineering,1998,5(1):143-168.
[12] 刘东云,梅宏.从需求到软件体系结构:一种面向特征的映射方法[J].北京大学学报:自然科学版,2004,40(3):372-378.
[13] Lee K,Kang K C.Feature dependency analysis for product line component design[M]//Software reuse: methods, techniques, and tools. Springer Berlin Heidelberg,2004:69-85.
[14] Svahnberg M,Van Gurp J,Bosch J.A taxonomy of variability realization techniques[J].Software:Practice and Experience,2005,35(8):705-754.
[15] Gacek C,Anastasopoules M.Implementing product line variabilities[J].ACM SIGSOFT Software Engineering Notes,ACM,2001,26(3):109-117.
[16] 祝家意,彭鑫,赵文耘.基于OOP和AOP的软件产品线实现技术研究[J].计算机科学,2009,36(7):120-123.
A CUSTOMISED DEVELOPMENT METHOD FOR DATA PRESENTATION SUBSYSTEM BASED ON VARIATIONS
Xing RongfeiShen LiweiZhao Wenyun
(SchoolofSoftware,FudanUniversity,Shanghai201203,China) (ShanghaiKeyLaboratoryofDataScience,FudanUniversity,Shanghai200433,China)
Data-intensive systems have been widely used in different industries and sectors. Data presentation subsystem is an important constituent element of the layered data-intensive system. To develop a group of data presentation subsystems with similar requirements based on the software product line method can effectively helps to increase the efficiency of developers. However, traditional construction and customisation methods for software product line are not fully applicable to such data presentation subsystem due to its variation characteristics. In view of this, we propose a variations-based customised development method for data presentation subsystems. First, the method extends the feature meta-model of software product line. Based on it, the method summarises a set of required documents-oriented feature modelling processes and technical solutions for variations implementation. Besides, the method proposes a two-step customisation process to support the customised development of subsystems. In end of the paper, we verify the feasibility and effectiveness of the method through an example of data presentation subsystem in a financial data system.
Software product lineData presentation subsystemVariability
2014-11-28。邢戎飞,硕士生,主研领域:软件工程。沈立炜,讲师。赵文耘,教授。
TP3
A
10.3969/j.issn.1000-386x.2016.03.007
