伪装语音的听觉识别研究
2016-06-13张巍
张巍

【摘 要】在涉及语音的案件当中,犯罪分子为了掩盖身份,逃避打击,常常采用各种方法对他们的声音进行伪装,从而给案件侦破和语音鉴定工作带来很大困难。因此,对伪装语音进行研究尤为重要。本文采集了10位发音人的正常语音以及提高基频、降低基频、加快语速、减慢语速、捏鼻伪装、咬物伪装、捂嘴伪装、嚼物伪装、耳语伪装和变更方言10种伪装方式的语音样本。另外,因为不同人对声音的敏感程度和对语音的识别依据不同,所以识别结果也就不尽相同。本文的研究结果为伪装语音等疑难案件的检验鉴定提供了一定的参考和借鉴,对于法庭话者鉴别技术应用和发展具有重要意义。
【关键词】伪装语音;听觉识别;语音检验;正确识别率
语音是法庭中常用的证据形式。生理学和心理学的研究结果表明:人类的听觉系统具有很高的敏感性和记忆能力。对于一个听觉正常的人来说,仅仅依靠熟悉的说话人发出的支言片语就可以准确鉴别出发音人。就是不熟悉的说话人,人类的听觉系统也具有相当强的记忆能力,当然不同人的听觉记忆能力不同,识别能力也就不同。另外,由于每个人的发音特点不同,特异性程度因人而异,因此对于一些音质比较特殊的人来说,记忆识别的效果就好些。
听觉鉴别是语音检验的重要方法之一,它是以听音人的听觉感知为基础,对案件语音检材和样本语音材料所进行的语音定性分析。对于伪装语音来说,听觉检验尤为重要。对于一段伪装语音,从听觉上很容易觉察到语音的异变。尽管有时不能准确判断出其伪装发音的具体方式方法,但是识别出伪装的存在还是较为容易的。不同人听觉识别语音的能力不同,对于伪装语音的识别能力也就不同。
本文通过对十种常见伪装方式利用听觉识别检验的方法,分析各种伪装的发音方式并统计出话者鉴别的正确识别率,旨在评价听觉识别伪装语音的可靠性,进而提出伪装语音的听觉鉴别方法。
1 伪装语音及听觉识别检验
1.1 伪装语音的定义及分类
1.1.1 定义
伪装语音(disguised voice)是相对于正常语音(normal voice)而言的。我们可以借鉴Robert D.Rodman①的定义,即“不管原因如何,对于正常的任何改变,扭曲或者偏离都可以称作语音的伪装。”这一定义可以作为伪装语音的广义解释,它涵盖了故意伪装和非故意伪装两种形式。鉴于司法应用而言,更多的则是关注故意伪装,也可以称作狭义的伪装语音。即“以掩盖真实身份为目的,有意识地改变声音,使其模糊,畸变,扭曲的发音方式。”只有对伪装语音进行科学的定义,才便于进一步的分类和进行针对性的研究。
1.1.2 分类
语音伪装从类型上大体可分为故意伪装和非故意伪装,从方式上可分为电声伪装和非电声伪装。其中,电声伪装中依靠电子设备干扰的属故意伪装,信道发生非人为的扭曲为非故意伪装;非电声伪装中采用假声、耳语等方式伪装的属故意伪装,而由于自身本来的原因,如患病,酗酒等就属于非故意伪装。
具体伪装类型主要有调音、音素、韵律及变形几个方式的伪装。在调音伪装中,有改变音高、紧喉音、吸气音及耳语伪装等等;改变音素伪装主要有使用方言、变更方言、鼻音化和模仿说话等;改变韵律的伪装有改变语调,重音位置的调整,音段的拉长和缩短以及言语节奏的变化等方式,而变形主要指依靠外力阻碍正常的发音,如捏鼻子、捂嘴、咬物、嚼物等等。我们在这里主要研究的是故意伪装。
1.2 听觉识别检验
所谓听觉识别检验是以听音人的听觉感知为基础,对案件语音检材和样本语音材料所进行的语音定性分析。进行听觉分析时要注意以下四个方面的特征:
(1)音质特征。这里的音质是指发音人的嗓音品质,不包括鼻腔等声道的共鸣。由于每个人的喉的结构、尺寸、声带的长短、厚薄、张力的差异,因此嗓音的音质也不相同。描述音质时可以从“粗糙程度”、“声带张力”、“吱嘎声”、“吸气音”等方面进行分析描述。
(2)调音特征。这里是指喉、唇、舌的调音动作和鼻腔声道共鸣的总情况,即调音设置。描述调音特征也有一套专门的术语,如高鼻化、喉化、唇化等等。
(3)方言特征和社会背景特征。主要听那些能够反映说话人的地域以及社会背景线索的调音特征。这些特征对于分析说话人的特点是很有用的。如“n/l”不分、“平/翘”不分等都是很好地表明地域和方言特征的信息。另外,听一个人的谈话,还可以基本判断出说话人的言语水平、文化程度、职业特点等社会背景情况。
(4)个体发音特征。这些个体特征主要是关于辅音、元音发音的方式方法。比较明显的个体特征可以通过听觉感知到,如各种类型的口齿不清,发音的不流畅,结巴,口头语,以及丢词、吞音等等。
2 实验材料和方法
2.1 样本语料的采集
2.1.1 发音人
发音人共10名,男性,他们均为某大学四年级的学生,年龄为22-24岁不等,分别来自中国几个方言区,经过几年大学生活,普通话都比较好,大部分同学发音没有明显的方言特征。
2.1.2 发音文本
该发音文本是模仿实际案例中的三段语句:“你的孩子现在在我们手里,你赶快拿钱来赎。你把钱汇到我的银行账号上,我的账号是263549728134,不许报警,不许让别人知道,否则你的孩子就没命了。”②
2.1.3 采集方法
为了排除背景噪音的干扰,我们的录音地点选择在一个安静的实验室。录音设备采用指向性较好的NOKIA(N70)手机,采样率为8KHz。录音时,先让发音人充分熟悉语音文本,然后分别用正常语音、提高基频、降低基频、加快语速、减慢语速、捏鼻、咬物、捂嘴、嚼物、耳语以及变更方言10种不同伪装方式发音,发音时要求发音人尽可能的模拟犯罪现场条件自然发音。由此,我们采集到了10位发音人的正常语音文本和10种不同伪装方式发音的样本。
2.2 听觉识别检验实验
2.2.1 样本配对
首先将10位发音人的正常语音随机配成10组语音对;再将每个人的10种不同伪装发音方式与正常语音配成语音对,每种伪装方式配10对,5对为同一人语音样本,另外5对为随机配成。
2.2.2 听者要求
另找10位同学对配好的语音对进行听觉识别,10位听音者有5位是与发音者熟悉的同学,另外5位是不熟悉说话人的,让他们判断两次语音是否为同一人所发,作出认定、否定或无法判断等结论,并说明评判依据;最后,将结果进行整理分析。
3 实验结果分析
3.1 熟悉说话人的听觉识别
首先分析熟悉说话人一组听音者的听觉识别检验结果。统计5位熟悉说话人的听觉实验结果,如表1所示。
从表1中可以看出,熟悉说话人的同学对于发音人的正常语音的正确识别率为100%,即全部都能被识别出来。十种伪装方式中,加快语速的识别效果最好,正确识别率与正常语速一致,也为100%。
其它几种伪装方式如降低基频、减慢语速、嚼物伪装和变更方言也有较高的正确识别率,其正确识别率都在90%以上,捏鼻伪装与咬物伪装居中,正确识别率在80%到90%之间,而提高基频与捂嘴伪装则偏低,低于70%,耳语伪装最低,仅为56%。而随机组合的正常语音对,识别率也同样为100%。
此外,从表1中还可以看出,在语音听觉检验过程中,随机组合的语音对正确识别率高于自身比较的语音对,如在耳语伪装中,5位听音者识别相同伪装方式中自身比较的语音对,一共25次只有7次是正确的,而在随机组合的语音对中,有21次都是正确的,其他几种伪装方式正确率基本也是这种情况,只有在减慢语速伪装中,自身比较的正确率大于随机比较的。
在进行听觉识别实验的过程中,听音者所反映出来的识别依据大都是熟悉说话人,有的是通过音色识别,或是通过方言口音识别,或是通过对语句中的账号念法识别。
3.2 不熟悉说话人的听觉识别
采用与前组实验同样的方法,统计了5位不熟悉说话人的听者听觉识别检验结果,如表2所示:
表2 不熟悉说话人的听者听觉识别结果统计
从表2中可以看出,因为是不熟悉说话人,所以这组听音者的识别结果与上一组相比有很大区别,正确识别率整体上较熟悉说话人的一组有所下降,但是各个具体发音类型上的情况各异。唯一没有变化的还是10组随机组合的正常语音对的识别结果,正确识别率还是100%。正常语音与提高、降低基频配成的语音对,正确识别率分别为74%、90%,较上一组结果没有太大变化。而咬物伪装与上一组相同,没有变化,正确识别率都为86%。除了以上所述,其它几种伪装方式的正确识别率就有了不同程度的变化。变化最大的是耳语伪装,正确识别率达到了78%。此组实验中正确识别率最低的提高基频伪装,正确识别率为74%。其它几种伪装方式的正确识别率都不是很低,都在80%左右,或者更高,可以说较上一组有显著提高。而关于随机比较与自身比较正确数这项数据的比较就没有上一组反映的那么明显,不好说哪一种正确率高,有的是随机比较的高于自身比较的,而有的则相反。
为了更清楚地表明两组实验获取的正确识别率的差异情况,我们将各组听音人的识别结果制成了柱状图,结果见图1所示。
3.3 综合分析
综合构成语音听觉检验基础的6种语音参数对两组实验中各种伪装方式按具体分类进行综合分析。
3.3.1 调音伪装
首先来看提高基频这种伪装方式。所谓基频指的是声带颤动的基本频率,而在听觉感知中它表现为听者的主观音高。音高也称音调,表示人耳对声音调子高低的主观感受,大致可分为高、中、低三类水平。音高的变化模式以及习惯模式等都是听者识别话着的依据。提高基频其实就是提高音高,也就是俗称的“尖嗓子”说话,或者说是模仿女声,这种伪装方式是比较成功的一种伪装方式,实验也证明了这一点,第一组实验的正确识别率只有72%,第二组也只有74%,在所有伪装方式中的正确识别率都很低。造成这种结果的原因正是基于音高的变化模式以及音高的习惯模式是听者识别话者的常用依据。很多人平时说话声音比较低沉,但当他提高基频以后,声调的变化幅度很大,熟悉他的人就会产生错觉,误认为不是同一个人,而不熟悉他的人就更难做出正确判断了。有的人平时说话音高就比较高,提高基频以后,音调的变化幅度相对的小一些,相对来说,就比较容易辨认出来。
降低基频也是同样道理,两组实验反映出的正确识别率在几种伪装方式中是比较高的,第一组达到了92%,第二组也有90%。降低基频和提高基频这两种伪装方式的正确识别率之所以会相差如此之大,是因为大多数人基频降低的幅度有限,正常语音的音高与低音相差不会很多,所以听音者就比较容易辨认出来。经常唱歌的人应该会有这个经验,用假声唱歌要比唱低音容易得多,这样也就不难理解为什么这两种伪装方式的正确识别率会相差如此之大。
在听觉检验识别过程中,很多听音者会依据音高的异同来判断话者是否为同一人,在平时的日常生活中我们也经常会说某某人的音高高或低,所以音高在伪装语音的听觉识别检验中具有很重要的作用。
耳语伪装的正确识别率在各种伪装方式中也同样很低,在第一组实验中仅为56%,在第二组中也不高,只有78%。说明耳语伪装也是伪装性很好的一种语音伪装方式。耳语就是俗称的“悄悄话”。从发音机理上讲,它是一种单一的发声类型。发声时,声门前部(韧带)完全靠拢,后部(杓状软骨)有一个宽三角形裂隙。气流通过开放区摩擦噪声并出现“耳语音质”。耳语的突出特点是说话时声带不振动,语音完全靠气流与发音器官的摩擦来产生。所以,听音者就很难仅仅依据简单的音高音色等认定出话者。但也不是完全没有办法识别。例如,依据银行账号的念法,单个词组的念法等等;另外,耳语有时候还能反映出话者的方言特征,根据这些都可以进行话者识别。在这里还有一个值得注意的问题,第一组与第二组中,耳语伪装的正确识别率为什么会相差如此之大?首先,对话者的熟悉程度会影响耳语伪装的正确识别率。按常理来说应该是越熟悉话者,正确识别率才能更高,但事实证明恰恰相反,不熟悉话者的人有更高的正确识别率,而且比第一组中高的多,其原因还有待进一步确定。
耳语伪装是一种特殊的伪装方式,在进行实验时,对录音的环境、听音者所处的环境以及听音者的态度都有很高的要求,由于时间关系,要求听音者要连续听很多语音片段,加上天气原因和外界的干扰,听音者难免会产生腻烦情绪,而且在进行耳语伪装的听觉识别时,尤其要认真,每一个细节都有可能是判断的依据,但不可能要求每个人都能够非常认真的去听,这就在一定程度上影响了实验结果的精确性。
3.3.2 改变韵律伪装
这里主要指改变语速的伪装。在两次实验中加快与减慢语速这两种伪装方式的正确识别率都比较高,都达到了80%以上,第一组比第二组的正确识别率要高,其中,第一组加快语速伪装的正确识别率达到了100%;另外,加快语速伪装比减慢语速伪装的正确识别率普遍要高,这是因为话者加快语速时,不会考虑太多,很多个人言语特征容易暴露;而减慢语速时,话者有足够的时间去考虑如何伪装自身的言语特征,给识别增加了难度。可见这两种伪装方式比较容易被识别,伪装性较差。虽然话者变化了语速,但是基本的言语特征和自己的综合语音品质并没有变化。日常生活中,当听某人说话时,人们总会注意他讲话是快速还是慢速,是连续流畅还是时断时续。讲话人的计时性和旋律为听音者提供了另一种语音鉴别线索。所以听音者一听话音就能作出准确判断。
3.3.3 变形伪装发音
变形主要指依靠外力阻碍正常的发音。此次实验中的捏鼻子、捂嘴、咬物和嚼物伪装方式都属于变形伪装发音。语音学所谓的发音是指,发音人调动积极发音器官(舌、唇)和消极发音器官(齿、齿龈、腭)构筑声道形态,阻塞或开放气流,对来自声门的源波进行调制,发出具有不同音色的语音,在这个过程中,说话人动力定型中的一个小小的习惯动作就会在辅音、元音里造成某些区别于他人的东西,如元音共振峰的数值、相对位置和起伏变化。声带形态的习惯造型,在辅音能量集中区辅-元音之间的过渡特征等都会表现出“个人”色彩。发音是最能体现个体习惯动作的活动。
首先分析捏鼻伪装和捂嘴伪装。捏鼻伪装与捂嘴伪装都属于外在干预发音器官,发音器官形状的改变以及发音动作的改变都是被动进行的,不需要主动改变发音器官的习惯“动力定型”,因此,相对提高或降低基频这类改变基频的伪装发音方式较容易实施。两组实验所反映出来这两种伪装方式的正确识别率都算正常,第一组中捏鼻伪装的正确识别率为84%,捂嘴伪装只有76%,而第二组中的捏鼻伪装正确识别率为78%,捂嘴伪装却达到了88%。
捏鼻子发音也会间接改变基频,因为鼻腔的阻塞对声门气流有影响,会增加声门的压力,这样就需要较高的下声门气流压力。所以,如果说话人要提升声门气流,就需要提高基频,这样一来,就造成了正确识别率的下降;而捂嘴伪装使得话者的语音能量发生了变化,也就是声道的强度发生了变化。绝对的声道强度很难量度,因为说话人嘴巴离开话筒的距离稍微变化就会导致声音能量发生很大变化。但是,人们可以听出说话人语音响度是高还是低,能发觉其响度是如何变化的,有时听音者据此也可以判断话者。
咬物伪装和嚼物伪装看似比较相似,但它们的发音方式却有所不同,相对来说,咬物伪装更难完成,因为话者在进行伪装发音时,发音人的积极、消极发音器官如舌、唇、齿等受到了抑制,不能够正常完成发音,但正是因为这样,发音人的很多发音特点也很容易暴露出来。此种伪装方式的正确识别率也是比较高的,而且两组实验的数据也相同,都是86%;而嚼物伪装的正确识别率就不是很稳定了,在第一组中达到了98%,而第二组中却只有82%,虽然嚼物伪装也间接影响发音器官的正常发音,但相比咬物发音,就容易的多,而且所发出的音质、说话语气和正常发音时基本相同,只是在发音时伴有咀嚼食物的动作。因此实施起来较容易,而且具有一定的伪装性,在第一组中正确识别率非常高,是因为熟悉说话人的缘故,所以识别就相对容易了许多。
3.3.4 改变音素伪装
这里所指的改变音素伪装就是变更方言伪装,变更方言伪装的正确识别率较高,在两组实验中分别达到了90%和80%。这种伪装方式的正确识别率和听音者对话者的熟悉程度有关,由于语音实验所选的十位同学来自全国的不同地方,每个人或多或少存在着地域口音,而且每个人都具有个人特色的语言如方言、不常用的言语重音或情感、个体化的语言模式、言语障碍(如口吃)、个体化的拼读(如南、兰不分,平、卷舌不分)等。而熟悉他们本人的听音者通过这些就能很快识别出说话人,即使说话人不同程度的变换了言语方式,但终究掩盖不了自己从小养成的话语习惯。而不熟悉话者本人的,有时也可以根据语料中的一字一句,个人说话习惯等区分出话者。
3.3.5 音色对听觉识别的影响
在此次实验中,听音者在对语音作出判断时,提到最多的就是音色,可见每位话者给听音者留下印象最深刻的就是各自不同的音色。理论上讲,音色又称音品,由声音波形的谐波频谱和包络决定。声音波形的基频所产生的听得最清楚的音称为基音,各次谐波的微小振动所产生的声音称泛音。单一频率的音称为纯音,具有谐波的音称为复音。每个基音都有固有的频率和不同响度的泛音,借此可以区别其它具有相同响度和音调的声音。与音调和音量相比,音色又是一个较为复杂的概念。两位女高音用同样的音高唱同一首歌,但是听众一听就可以准确的分辨出来,为什么呢?其中最主要的原因就是音色的作用。再如:唢呐和小号,同样是吹奏乐器,也同样是高音乐器,但是它们的特点却各不相同,这也是音色在起着最为重要的作用。此外,发音体的发音机制决定了声音的综合品质。人作为发音体而言,没有任何两个人是完全相同的,每个人都是人群中的“这一个”,因此,所发出的语音必然具有自己的综合语音品质。所以听音者有时仅靠一句话或一个词就能识别出话者。
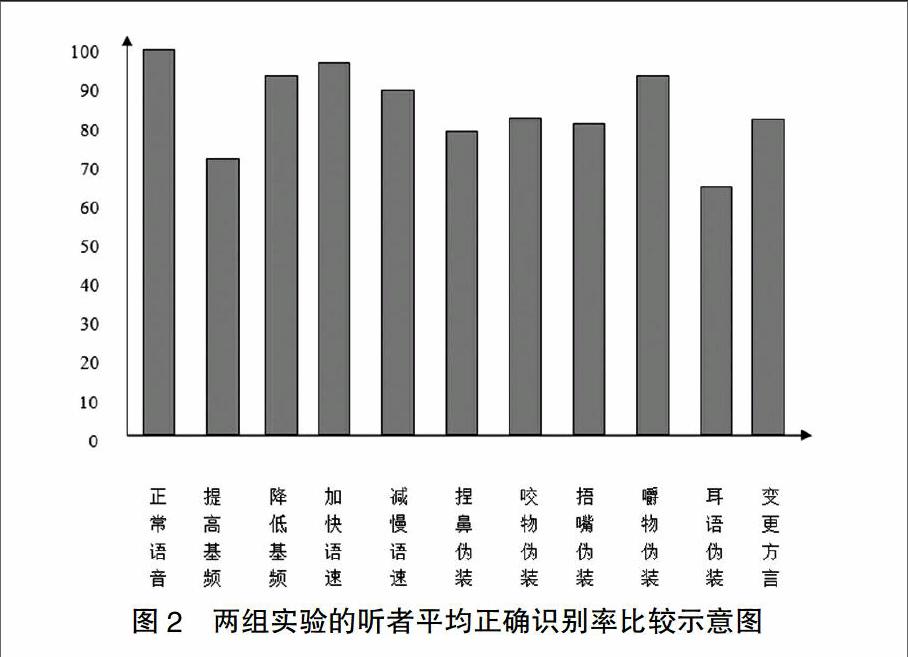
为了综合比较并归纳总结各种伪装方式,我们将所有伪装方式的平均正确识别率结果以柱状图形式表现出来,见图2所示:
图2 两组实验的听者平均正确识别率比较示意图
4 结论
本文利用10位发音人的正常语音及伪装语音,进行熟悉说话人和不熟悉说话人的伪装语音的听觉实验研究。结果表明:对于提高基频、降低基频、加快语速、减慢语速、捏鼻伪装、咬物伪装、捂嘴伪装、嚼物伪装、耳语伪装和变更方言10种伪装发音方式来说,话者鉴别的平均正确识别率在90%以上的有降低基频、加快语速和嚼物伪装三种,80%~90%的有减慢语速、捏鼻伪装、咬物伪装、捂嘴伪装和变更方言五种,70%~80%的只有提高基频一种,耳语伪装最低,只有67%,也就是说耳语伪装的识别难度最大,伪装性最好。耳语伪装也是受听音人对话者的熟悉程度影响最大的一种伪装方式,但是这种伪装方式受客观条件的影响也最大,因此可靠性也不是很高,包括捂嘴伪装和嚼物伪装也是如此。熟悉和不熟悉说话人的听者听觉正确识别率之间都存在很大差距,而其他几种伪装方式的识别可靠性则相对高一点。实验证明:对说话人越熟悉,语音材料的质量越好,语言学知识培训和听觉检验程序越好听觉识别的正确率就越高;相反,不熟悉说话人,非同时性语音,说话人语音彼此相近,这些都会使听觉识别的精度下降。
语音伪装一方面受发音器官生理结构和调制能力的限制,另一方面又缺乏稳定性和持久性,所以它是有一定规律可循的,如最能体现每个人语音特色的音色;平时说话的个人习惯,如手机号码的念法,有的人习惯4个数字一起念,有的人习惯3个数字一起念;再如有的人说话鼻音重,有的人说话喜欢咳嗽、加字减字等等,这些都能为伪装语音的听觉识别提供依据。
本文着重分析伪装语音听觉检验的识别结果及听觉伪装效果,下一步的研究应重点考虑影响实验结果的因素,增加分析指标,重点对耳语、捂嘴和嚼物等受外界条件影响较大的伪装形式进行研究。
【参考文献】
[1]吴宗济,林茂灿.实验语音学概要[M].北京:高等教育出版社,1989.
[2]孔江平.论语言发声[M].北京:中央民族大学出版社,2001.
[3]崔景旭.视听资料检验[M].沈阳:中国刑警学院内部教材,2004.
[4]林焘,王理嘉.语音学教程[M].北京:北京大学出版社.1994.
[5]郭锦桴.综合语音学[M].福州:福建人民出版社.1993.
[6]张翠玲.耳语伪装语音的声学研究[J].沈阳:中国刑警学院学报,2005,4.
[7]张翠玲.捏鼻伪装语音的声学研究[J].沈阳:中国刑警学院学报,2006,3.
[8]Kunzel,H.J.Effect of Voice Disguise on Speaking Fundamental Frequency,Forensic Linguistics, 7(2): 2000.
[9]Masthoff,H.A Report on a Voice Disguise Experiment,Forensic Linguistics3(1),1996.
[10]Markham,D.Listeners and Disguised Voices:the Imitation and Perception of Dialectal Accent.Forensic Linguistics 6(2): 1999.
[11]Robert D.Rodman,Speaker Recognition of Disguised Voices:A Program for Research, North Carolina State University, Raleigh, North Carolina, 2003.
注释:
①崔景旭.视听资料检验[M].沈阳:中国刑警学院内部教材,2004.
②Robert D.Rodman,Speaker Recognition of Disguised Voices: A Program for Research,North Carolina State University,Raleigh,North Carolina,2003:132[Z].
[责任编辑:杨玉洁]