汉语未登录词的词义知识表示及语义预测
2016-06-01田元贺
田元贺,刘 扬
(1. 北京大学 中国语言文学系,北京 100871; 2. 北京大学 计算语言学教育部重点实验室,北京 100871;3. 北京大学 计算语言学研究所,北京 100871)
汉语未登录词的词义知识表示及语义预测
田元贺1,2,刘 扬2,3
(1. 北京大学 中国语言文学系,北京 100871; 2. 北京大学 计算语言学教育部重点实验室,北京 100871;3. 北京大学 计算语言学研究所,北京 100871)
在此前的汉语未登录词语义预测中,构词相关的知识一直被当做预测的手段,而没有被视为一种有价值的知识表示方式,该文在“语素概念”基础上,深入考察汉语的语义构词知识,给出未登录词的“多层面”的词义知识表示方案。针对该方案,该文采用贝叶斯网络方法,构建面向汉语未登录词的自动语义构词分析模型,该模型能有效预测未登录词的“多层面”的词义知识。这种词义知识表示简单、直观、易于拓展,实验表明对汉语未登录词的语义预测具有重要的价值,可以满足不同层次的应用需求。
未登录词;词义知识表示;语义预测;语义构词
1 引言
词义知识的表示和获取是文本理解的基础。在中文信息处理的实践中,汉语未登录词的频繁出现,对机器理解提出了很大的挑战,其语义预测对智能信息检索、机器翻译等典型应用具有重要价值。目前这一领域的研究仍处于起步阶段。
未登录词的语义预测涉及两个方面: 预测内容以及预测方法。
在预测内容上,此前的研究[1-7]主要是预测未登录词的语义类别,也有预测概念图[8]和语义构词知识[9]的。语义类别的预测是一种粗线条的预测,只能表示特定语义分类下的大概的词义,而对精细化的词义需求无能为力。例如,对于“选材”一词,语义类别的预测一般将其设定为“获取”这个义类,而“获取”的“具体内容”无法直观得到。相比之下,概念图以图的形式表示构词概念之间的关系,表达的词义信息要多于语义类别,然而,对于未登录词来说,这种表示形式过于复杂,既不直观、也不利于计算。
关于词义,符淮青[10]等多位语言学家指出: 语素义的组合可以在一定程度上体现词义。因此,将语义构词知识作为词义知识表示并对其进行预测将是一种新的选择。这种词义知识表示具有简单、直观的特点,能够全面、充分地反映构词语素对词义的贡献。例如,在“选材”中,“选”的语素义为“挑选”,“材”的语素义为“有才能的人”,其“述宾”结构关系及成分意义,准确地反映了“选材”的语义,在精度上高于语义类别,在复杂程度上低于概念图。吉志薇[9]是目前唯一尝试预测未登录词语义构词知识并给出预测方法的人。但遗憾的是,她只是简单地将未登录词的语义构词知识作为词义知识输出,而没有注意到“多层面”的构词知识在实际应用上的巨大价值,并且,不同的语素及其意义之间无法形成有效的关联,此外,她的实验结果也不太理想。
在预测方法上,目前主要有两类,即基于语料的方法和基于词内部知识的方法。此前,Lu[1]和Chen[2]尝试了基于语料的方法,并用这种方法预测语义类别,Lu的F值为37.1%,Chen的准确率为34.4%。此外,Lu还提供了基于词内部知识的方法。
相比之下,基于词内部知识方法的研究较多,结果也更理想。Lu[1]、Chen[3]、Tseng[4]、Chen[5]、邱立坤[6]等基于《同义词词林》(以下简称《词林》)和《知网》,尚芬芬[7]基于《现代汉语语义词典》,均预测未登录词的语义类别。值得一提的是,他们采用的预测模型,例如,“重叠字模型”、“字类别关联模型”等,都用了语义构词分析的思路,却没有意识到可以将语义构词知识应用于词义知识表示。在结果方面,Lu的准确率为61.6%,Chen[3]对名词的准确率为81.0%,Tseng对名词、动词、形容词的准确率分别为71.4%、52.8%、65.8%,Chen[5]对双音节V-V复合词的准确率为61.6%,邱立坤的F值为64.7%,尚芬芬的准确率为77.9%。此外,张瑞霞[8]基于《知网》预测概念图的准确率为79.3%。吉志薇[9]虽然给出了语义构词知识的预测方法,却没能得到一个整体上的结果,其部分结果(准确率为43.7%)也因为实验样本少而缺乏足够的代表性。
在此基础上,我们研究未登录词的语义预测,既包括预测内容,也包括预测方法。
首先,我们关注系统的语义构词知识与词义知识表示之间的关联,原则上,这种表示对已登录词、未登录词都是适用的。针对完整给出未登录词词义知识的难点,我们探究“多层面”的词义知识表示在应用需求上的价值;接下来,设计针对汉语未登录词的自动语义构词分析模型,预测未登录词的“多层面”的词义知识,实现对未登录词的词义预测。
需要说明的是,二字词在汉语中占据主体,对它的研究具有代表性,因此,目前的研究以二字未登录词为主。本文中的知识表示和预测方法具有良好的扩展性,可以方便地拓展到三字及以上未登录词的情形。
2 汉语的语义构词知识及“多层面”的知识表示
凡是对词的理解有意义的语义构词知识,在中文信息处理应用中都是有价值的。因此,本文所讲的语义构词知识,涵盖词性、构词结构、语素类、语素义等在内的广义知识。汉语未登陆词的语义预测也将以此为基础给出,以便在广泛的意义层面上来表示词义。
课题组研发多年并计划推出的北京大学《汉语概念词典》(以下简称《概念词典》,英文名称the Chinese Object-Oriented Lexicon, 简称COOL)在生成词库理论(GLT理论)[11]、面向对象思想(OO思想)[12]、WordNet理论[13]等观点指导下,以《现代汉语词典(第5版)》(以下简称《现汉》)刻画的汉语的语素及语素义为依据,采用“同义语素集”来表征“语素概念”并建立“语素概念体系”;在此基础上,详尽描述汉语词的构词结构,并实现构词结构下的构词成分(即语素)对“语素概念体系”中的“语素概念”的严格绑定,以此来诱导和表达汉语词义,并提供多种应用程序接口。
《概念词典》包含的词的这些语义构词知识,构成本文工作的一个数据基础。
2.1 语义构词知识
2.1.1 词性知识
《概念词典》为其收录的词都标注了词性,其中,51 454个二字词的情况如表1所示。

表1 《概念词典》中二字词词性统计表
续表

词性数量比率/%例词副词9051.76临时数词570.11好多量词900.17公尺介词360.07为了代词1140.22咱们助词230.04不得叹词100.02呜呼拟声词1150.22乒乓连词1620.31不但合计51454100.00
2.1.2 构词结构知识
在语言学界有两种主流的构词结构体系,一种注重表达构词语素间的语义关系(如主体、客体等),而另一种体系注重表达构词语素间的语法关系(如主谓、述宾等)。对于第一种构词体系,傅爱平[14]指出: 虽然其在表示词义时更具优势,但是其结构体系较为复杂,对计算机来说,识别难度较大。相比之下,第二种构词体系较为简单,结构标准较为统一,且与句法结构有天然的相似性,苑春法[15]的研究表明,基于语法的构词结构与构词语素类和词性之间存在一定的相关性。因此,采用第二种构词体系更有利于计算的开展。实际上,由于后续要求构词成分对“语素概念”严格绑定,我们获得的依然是广义的语义构词知识。
基于以上分析,我们参考杨梅[16]和北京大学中文系郭锐教授对构词结构的研究成果,构建了基于语法的构词体系,并为《概念词典》中所有52 108个二字词按义项区分标注了构词结构(表2)。为保证构词结构知识的可靠性,我们请三位专家对同一词项进行标注,两人以上标注结果相同的一致率为93.46%。

表2 《概念词典》二字词构词结构统计表
续表

构词结构数量比率/%例词定中1958137.58红旗状中42158.09热爱介宾1570.30从小重叠3100.59哥哥名量780.15纸张数量560.11一些方位1890.36野外复量200.04场次前附加6981.34老虎后附加23084.43忘却单纯词20783.99克隆合计52108100.00
2.1.3 语素类知识
语言学上的“语素”指的是“最小的音义结合体”,在本文中,为方便起见,汉语语素暂且限定为一个汉字。由于《现汉》只为部分(主要是成词语素,约48%)语素标注了语素类,我们采用专家人工标注的方式补齐了其余(主要是不成词语素,约52%)的语素类,《概念词典》全部20 175个语素的语素类知识如表3所示。

表3 《概念词典》语素类统计表
2.1.4 语素义知识
此前,学界对于语素义系统的研究较少。亢世勇[17]曾构建了《汉字义类信息库》,但他所选取的义类体系源于《词林》,用这种词义体系对字义分类的做法难免偏颇。借鉴WordNet理论,课题组成员陆顾婧[18]在其硕士论文中用“语素特征”(现在称其为“语素概念”)来称谓汉语中可计算的最小意义单元,并采用“同义语素集”的形式来加以表示,该集合中的元素为具有相同或基本相同意义(即语素义)的那些语素,其中的每个语素都携有独特的“语素义编码”。例如,语素“选”有多个语素义,其中的一个语素义的“语素义编码”为“选1_04_01”,这表明: 它是该单字在词典中的第1次条目出现(即“选1”),该条目共有4个义项(即“选1_04”),当前为第1个义项(即“选1_04_01”)。
目前,对以上20 175个语素所表达的语素义,我们按释义计算相似度,形成初步的“同义语素集”,并经反复的人工校对、核对,获得了5 113个“语素概念”。在这些“语素概念”之间,我们进一步构建了初步的上、下位语义关系,形成了一个树状结构的“语素概念体系”。在后续的知识表示中,如果确定了特定语素的语素义,携有了“语素义编码”,就意味着该特定语素在该体系中绑定了一个“语素概念”,并接受该体系的意义表达和约束。
以表达“选择、挑选”意义的动语素“语素概念”X为例,X={刷3_01_01,抡1_01_01,拔1_08_03,拣1_01_01,择1_02_01,择2_02_01,挑1_02_01,擢1_02_02,调4_02_02,选1_04_01,遴1_01_01,铨1_02_01},在“语素概念体系”中,其所处的“语素概念”位置如图1所示。
图1 树状结构的“语素概念体系”示例
在标注二字词的构词结构和前、后语素类后,我们继续把《概念词典》中所有二字词的前、后语素按其语素义与对应的“语素义编码”挂钩。于是,二字词的前、后语素与它们在“语素概念体系”中的“语素概念”就建立了严格绑定关系。这样一来,单一的语素义就拥有了更丰富的、便于计算的意义形式。
2.2 已登录词的“全层面”的词义知识表示
对《概念词典》中的二字词,在以上语义构词分析之后,我们获得了由词性、构词结构、语素类和语素义等四方面知识构成的一个“全层面”的词义知识表示。其中,前三个层面属于语法层,最后一个层面属于语义层。以“选材”一词为例,“选”表示“挑选、选择”的“语素概念”,“材”表示“有才能的人”的“语素概念”。鉴于“语素概念”中的每个语素都携有独特的“语素义编码”,为方便起见,语素对应的“语素概念”只以“语素义编码”的形式标出,“选材”的“全层面”的词义知识表示如表4所示。
为了诱导词义的简化的表达形式,我们在构词结构和词义之间搭建意义关联。

表4 “选材”的词义知识表示
亢世勇[17]曾给出包括A+B=A=B、A+B=A、A+B=B、A+B=C、A+B=A+B、A+B=A+B+D、A+B=A+D、A+B=D+B等八种形式的意义结构体系,其中,A、B分别表示二字词的前语素义和后语素义,C代表转义后的意义,D代表附加意义。这种体系分类详细,但转义和附加义的知识较难于获取,在实际应用中面临较大的挑战。陆顾婧[18]提出了一种简单、方便计算的意义结构体系,如表5所示,这也是我们目前采用的方案。需要指出的是,为方便起见,该意义结构体系省略了转义和附加义等附加因素,目前只考虑词的字面意义,即本义。转义和附加义的问题在后续层面单独加以表达和解决,这里不再赘述。例如,“铁窗”有“监狱”的意思,目前只考虑其字面义“铁的窗户”,其转义问题可以在后续阶段加以表示和处理,并不会因此丢失。
在此基础上,我们给出了词的“意义序列”的输出形式。该序列为构词语素的“语素义编码”的排列,内容和顺序基本由构词结构决定,如表6所示。以“选材”为例,其“意义序列”一般为“<选1_04_01,材1_05_04>”,此外,允许在应用需求中依据约定改变序列顺序,以表达计算的灵活性,如“<材1_05_04,选1_04_01>”也是一个合法的“意义序列”。考虑“语素概念体系”的意义表达和约束,词的“意义序列”表达词义的精细程度高于词的语义类别,而复杂程度低于概念图。

表5 意义结构与构词结构的对应关系

表6 词的“意义序列”示例
对于三字和多字词,可以采取分层迭代的方法来获取“意义序列”[18]。例如,先将“乱弹琴”输出为“<弹琴,乱1_06_01>”(“乱弹琴”是状中结构),再将“弹琴”输出为“<弹2_06_04,琴1_03_02>”(“弹琴”是述宾结构),而完整收集的“意义序列”为“<<弹2_06_04,琴1_03_02>, 乱1_06_01>”。
2.3 未登录词的“多层面”的词义知识表示
语义构词知识涵盖不同层面,单一层面或多个层面的知识都有助于未登录词的理解,有其独特意义和应用价值。比如,未登录词的词性知识有助于句法分析器性能的提高。再如,未登录词的构词结构知识决定了构词语素对整体词义贡献的差异,对于单纯词类型,获取构词结构知识就够了;对于前附加、后附加、重叠结构、名量结构等类型,还需要获取单一语素义知识;对于其它构词结构类型,在获取构词结构知识的同时,获取单一语素义和全部语素义知识都有价值,这取决于具体的应用需求。例如,对于“红旗”,如果关注对象的属性,那么只需获取前语素义知识,如果关注对象本身,那么只需获取后语素义知识,如果关注整体意义,那么就需要获取所有语素义知识。此外,在某些应用中,甚至语素类都扮演重要角色。例如,如果关注“弹琴”中的独立的实体对象,那么只需分别判别“弹”和“琴”的语素类知识,并据此获取其中的名词性语素的语素义知识即可。
因此,依据应用需求的不同,可以选取不同层面的语义构词知识进行预测并加以组合,以达到对未登录词意义的有效把握,我们称其为“多层面”的词义知识表示。其优点在于,在满足需求的同时,避免了预测“全层面”的词义知识表示的困难,减少了需要预测的知识数目,有助于预测方法性能的提高。
在未登录词的“多层面”的词义知识表示的基础上,其“意义序列”的输出遵循同样的规范,这里不再赘述。
3 基于贝叶斯网络的语义构词分析模型
语义构词知识包括词性、构词结构、语素类和语素义等,苑春法[15]、王淑华[19]等人的研究表明,这些语义构词知识之间具有一定的相关性。因此,可以尝试从二字未登录词的词型出发,以推理的方式获取这些知识。贝叶斯网络正好提供了推理的概率手段,可以用于各种语义构词知识组合性的预测,满足词义知识表示的多层次需求。在本文研究中,我们以贝叶斯最优分类器算法[20]为基础,构建语义构词分析模型。
为表述方便,做如下约定:D表示训练数据,H表示假设空间,X前字表示前语素,X后字表示后语素,X前类表示前语素类,X后类表示后语素类,X前义表示前语素义,X后义表示后语素义,X词性表示词性,X结构表示构词结构。于是,X前类、X后类、X前义、X后义、X词性、X结构构成了二字未登录词ab(X前字=a、X后字=b)的语义构词知识,而V表示依据需求不同而被选入当前词义知识表示的语义构词知识组合的集合。语义构词分析模型的任务就是预测V中最优的语义构词知识组合,如式(1)所示。
进一步,由贝叶斯公式,如式(2)所示。
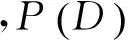
此外,定义:
3.1 假设空间的构建
对于贝叶斯网络来说,不同的假设对应于语义构词知识之间的不同的条件独立性,也对应了不同的网络结构和推理过程。
我们认为,语义构词知识的预测由以下三个任务顺序组成: 1、语素类知识X前类和X后类的预测;2、语素义知识X前义和X后义的预测;3、词性知识X词性和结构知识X结构的预测。其中,任务1有三种推理模式: ①前字->前类,后字->后类;②后字->后类,前字、后类->前类;③前字->前类,后字、前类->后类;任务2有四种推理模式: ①前字、后类->前义,后字、前义->后义;②后字、前类->后义,前字、后义->前类;③前字、后类->前义,后字、 前类->后义;④前字->前义,后字->后义(该推理模式不使用前类和后类的特征);任务3只有一种推理模式: 前义、后义->词性,前义、后义、词性->结构。综上所述,共有(3×3+1)×1=10种推理模式,分别对应了假设空间中10种可能的假设。
举例来说,选取任务1中的推理模式③、任务2中的推理模式①和任务3中的推理模式,它们组成的一种假设的贝叶斯网络如图2所示。

图2 一种假设的贝叶斯网络


于是,有式(5):
(5)
进一步,由全概公式,有式(6):
(6)

特别地,当hi为图2所示的假设时,有式(7):
(7)

(8)
其它假设和语义构词知识组合的计算方法与此类似。
3.3 数据稀疏问题的应对方法
对于数据稀疏问题,有两种应对方法:
方法1是使用结构简单的假设推理。在假设空间的十种假设中,既有贝叶斯网络结构十分复杂的假设(图2);也有十分简单的假设(图3)。理论上,这种假设可以覆盖《概念词典》中的全部二字词,增强了模型的适用性。

图3 一种结构弱化的贝叶斯网络
方法2是在推理中使用“语素概念体系”中的上层“语素概念”节点。由于在全体“语素概念”间构建起了树状结构,当使用上层节点的语义知识进行推理时,发生数据稀疏问题的可能性大大降低。
4 实验结果与数据分析
4.1 实验数据说明
如前文所述,我们请多位专家对《概念词典》中所有的二字词标注了构词结构、语素类和语素义等语义构词知识。对以上标注结果,按如下原则计算人工标注的准确率: ①如果三人标注一样,则认定三人均正确;②如果两人标注一样,则认定标注一样的两人正确,另一人错误;③如果三人标注均不相同,则认定三人均错误。人工标注的准确率见表7,由于《概念词典》中已有词性知识,不需要人工标注,所以没有给出相关数据。

表7 语义构词知识人工标注情况
对全部二字词整理之后,共得到41 472个不同词型的语义构词知识,这些将作为我们的实验数据。未登录词通常从语料中筛选并使用模型对其进行语义预测,但是,这样的未登录词缺乏作为判定标准的语义构词知识,无法给出模型的预测准确率,无法评价模型效果。基于这些考虑,本文实验的训练数据和测试数据均选自《概念词典》,我们将以上词型随机十等分,采用十折交叉验证的方法来检验模型效果,即轮流将其中九份作为训练数据,剩下一份作为测试数据。这样一来,对模型而言,每轮测试数据中的词即未登录词。
4.2 实验结果和分析
首先,在未对实验数据做筛选的情况下,语义构词分析模型可以处理所有二字未登录词,不同语义构词知识及其组合的预测准确率,如表8—表10所示。从这些结果不难看出,随 着预测语义构词知识种类的增多和叠加,其准确率也随之下降。结合前文分析,这也表明,使用自动方法获取“全层面”的语义构词知识是有难度的,在当前,“多层面”的词义知识表示更具有现实意义。

表8 语法层的语义构词知识预测准确率

表9 语义层的语义构词知识预测准确率

表10 “语法+语义”层的语义构词知识预测准确率
接下来,将人工标注的准确率和自动方法进行比较,如表11—表13所示。由于无需人工标注词性,所以表中没有“词性”和“词性+构词结构”的比较项目。可以发现,人工标注的准确率在一些项目上并不高,例如,人工在“词性+构词结构+前语素义+后语素义”项目的准确率为61.87%,而这一结果是建立在标注专家已知词性和词义的基础上的。这意味着,如果让人和机器处于同样的条件下——只知词型而不知词义和词性,那么人工标注的准确率应该比目前的更低。这恰好表明,使用自动方法准确获取“全层面”的语义构词知识在目前充满挑战,即使预测模型能够改善,人工标注的准确率也是可供参考的上限。相反,预测部分的语义构词知识,即“多层面”的语义构词知识,由于其准确率较高,更应成为自动方法关注的焦点。

表11 语法层的人工与模型准确率比较

表12 语义层的人工与模型准确率比较

表13 “语法+语义”层的人工与模型准确率比较
进一步,结合各种构词结构的统计数据(表2),我们发现“多层面”的词义知识表示的价值更加突显。例如,如果只获取后语素义知识,那么对3.28%(连谓)+21.90%(联合)+37.58%(定中)+8.09%(状中)+0.59%(重叠)+0.11%(数量)+0.36%(方位)+1.34%(前附加)=73.25%的二字词有较准确的意义把握。
最后,将实验结果与前人研究进行比较: (1) 假定二字词的后语素义基本决定了它的语义类别,那么我们对语义类别的预测准确率达到66.23%,这一结果和现有的研究[1,3-7]基本相当,区别在于,我们给出了精确的语素义,其背后有“语素概念体系”的表达和约束,而此前给出的是单一的语义类别; (2) 在此前的实验中,预测语义类别以及预测概念图的研究[8],都是将语料中出现的未登录词作为测试数据——实际上,“能产性构词”类型的未登录词在语料中占了很大的比例,其语义预测更加有规律可循。相比之下,本文实验的测试数据是在《概念词典》中随机抽取,其中属于“能产性构词”类型的词并不多。在测试数据的预测难度和适用范围上,本文研究优于此前的研究; (3) 同样预测语义构词知识的研究[9]给出了预测方法,但该方法建立在71个专门挑选的未登录词上,不具有代表性,也没能给出完整的实验结果。与该方法的部分实验结果(其准确率为43.7%)相比,我们在“语法+语义”层的预测结果与之大致相当,此外,我们在“语素概念”基础上建立不同语素及其意义之间的广泛关联,语义构词知识的广度和深度都有新的提升。
5 结语
综上所述,本文研究的贡献体现在如下两个方面。
(1) 在预测内容上,此前的汉语未登录词语义预测,构词相关的知识一直被当做预测的手段,而没有被视为一种有价值的知识表示方式,我们在“语素概念”基础上,深入考察汉语的语义构词知识,给出未登录词的“多层面”的词义知识表示方案。这种“多层面”的词义知识表示,针对未登录词的完全语义预测的困难,可以依据不同的任务性质和指标要求,给出不同的语义构词知识及组合,表现出高度的灵活度和可裁剪性,预测结果简单、直观、易于应用。
(2)在预测方法上,针对“多层面”的词义知识表示的需求,我们采用贝叶斯网络方法预测未登录词的多样化的语义构词知识。该模型实现简单,可以依据任务需求的变化快速给出相应结果,可以预测任何汉语二字词,表现出良好的适用性。与同样预测语义构词知识的此前方法想比,本文方法首次给出了整体实验结果,该结果与此前部分实验结果的预测准确率相当。此外,该方法能够预测精确的语素义,其背后也有“语素概念体系”的表达和约束,而此前给出的多是单一的语义类别。
总体上看,未登录词的语义预测仍旧是研究上的难点,“多层面”的词义知识表示不失为一种有效的应对方案,它通过对预测内容的选取和组合,可以满足不同应用对不同层面词义知识的灵活需求。但是,也应看到,我们对未登录词的词义知识表示和语义构词分析进行了初步的探索,所使用的语义资源和分析技术仍有较大的提高和改善的空间,这也是未来需要继续展开的工作。此外,目前只探讨了汉语二字词的情形,三字及以上词的相关资源仍在加紧开发中,将研究成果由二字词拓展到多字词,也是我们下一步需要展开的工作。
[1] Lu X. Hybrid Models for Semantic Classification of Chinese Unknown Words[C]//Proceedings of the HLT-NAACL,2007: 188-195.
[2] Chen H H, Lin C C. Sense-tagging Chinese corpus[C]//Proceedings of the second workshop on Chinese language processing: held in conjunction with the 38th Annual Meeting of the Association for Computational Linguistics-Volume 12. Association for Computational Linguistics, 2000: 7-14.
[3] Chen K J, Chen C. Automatic semantic classification for Chinese unknown compound nouns[C]//Proceedings of the 18th conference on Computational linguistics-Volume 1. Association for Computational Linguistics, 2000: 173-179.
[4] Tseng H. Semantic classification of Chinese unknown words[C]//Proceedings of the 41st Annual Meeting on Association for Computational Linguistics-Volume 2. Association for Computational Linguistics, 2003: 72-79.
[5] Chen C J. Character-sense association and compounding template similarity: Automatic semantic classification of Chinese compounds[C]//Proceedings of the 3rd SIGHAN Workshop on Chinese Language Processing,2004: 33-40.
[6] 邱立坤.现代汉语未登录词词类和语义类标注研究[D].北京大学博士学位论文,2010.
[7] 尚芬芬,顾彦慧,戴茹冰,等.基于《现代汉语语义词典》的未登录词语义预测研究[J].北京大学学报(自然科学版),2016,01: 10-16.
[8] 张瑞霞,杨国增,闫新庆.基于知网的汉语普通未登录词语义分析模型[J].计算机应用与软件,2012,08: 126-130.
[9] 吉志薇,冯敏萱.面向普通未登录词理解的二字词语义构词研究[J].中文信息学报,2015,05: 63-68,83.
[10] 符淮青.词义和构成词的语素义的关系[J].辞书研究,1981,01: 98-110.
[11] Pustejovsky, J. The Generative Lexicon[M]. Mass: MIT Press, 1995.
[12] Grady Booch, Robert A. Maksimchuk, Michael W. Engle, etc. Object-Oriented Analysis and Design with Applications, 3rd Edition[M]. Addison-Wesley Professional, 2007.
[13] Fellbaum C. WordNet: An Electronic Lexical Database [M]. Mass: MIT Press, 1998.
[14] 傅爱平.汉语信息处理中单字的构词方式与合成词的识别和理解[J].语言文字应用,2003,04: 25-33.
[15] 苑春法,黄昌宁.基于语素数据库的汉语语素及构词研究[J].世界汉语教学,1998,02: 8-13.
[16] 杨梅.现代汉语合成词构词研究[D].南京师范大学博士学位论文,2006.
[17] 亢世勇,李毅,孙道功,等.汉语系统语料库的建设与词典编纂[C]//上海辞书学会.2004年辞书与数字化研讨会论文集.上海辞书学会: 2004: 7.
[18] 陆顾婧.汉语构词分析与词义知识表示研究[D].北京大学硕士学位论文,2013.
[19] 王淑华.双字组合理解模式探索[J].上海大学学报(社会科学版),2007,03: 43-47.
[20] Tom M. Mitchell著,曾华军,张银奎译.机器学习[M].北京: 机械工业出版社,2014: 125-126.
Lexical Knowledge Representation and Sense Prediction of Chinese Unknown Words
TIAN Yuanhe1,2, LIU Yang2,3
(1. Department of Chinese Language and Literature, Peking University, Beijing 100871, China;2. Key Laboratory of Computational Linguistics (Ministry of Education), Peking University, Beijing 100871, China;3. Institute of Computational Linguistics, Peking University, Beijing 100871, China)
In the previous researches in sense prediction of Chinese unknown words, the lexical knowledge related to word-formation has been used but not regarded as a valuable form of knowledge representation. This paper, on the basis of the morphemic concepts, provides a multi-level solution to knowledge representation of Chinese unknown words. A model based on Bayesian network is also constructed to analyze semantic word-formation of Chinese unknown words, effectively predicting the multi-level lexical knowledge of Chinese unknown words. This kind of lexical knowledge representation is simple, intuitive and easy to expand. Experimental results show that, this knowledge representation is of important value in sense guessing of Chinese unknown words, and can meet the application needs on different levels.
Chinese unknown words; lexical knowledge representation; sense prediction; semantic word formation

田元贺(1994—),本科,主要研究领域为应用语言学、语言知识工程、中文信息处理。E-mail:tianyh94@sina.com刘扬(1971—),博士,副教授,主要研究领域为语言知识工程、中文信息处理。E-mail:liuyang@pku.edu.cn
1003-0077(2016)06-0026-09
2016-09-27 定稿日期: 2016-10-20
国家社科基金(16BYY137);国家重点基础研究发展计划资助项目(2014CB340504);国家社科基金(12&ZD119)
TP391
A
