基于粗糙集理论的影响高校学生成绩因素研究
2016-02-27蔡兴雨程智炜
蔡兴雨,徐 怡,2,程智炜
(1.安徽大学 计算机科学与技术学院,安徽 合肥 230601;2.安徽大学 计算智能与信号处理教育部重点实验室,安徽 合肥 230039)
基于粗糙集理论的影响高校学生成绩因素研究
蔡兴雨1,徐 怡1,2,程智炜1
(1.安徽大学 计算机科学与技术学院,安徽 合肥 230601;2.安徽大学 计算智能与信号处理教育部重点实验室,安徽 合肥 230039)
成绩是衡量教师教学质量以及学生学习效果的重要指标。由于影响学生学习成绩的因素众多,教师和学生不能清楚地认识影响成绩的关键因素。一方面,教师无法对教学方法做出有针对性的改进,以提高教学质量;另一方面,学生无法对学习方法做出有针对性的改进,以提高学习成绩。为了帮助高校教师及学生准确分析影响学习成绩的关键因素,设计了用于调查影响高校学生学习成绩因素的调查问卷,向该校大一至大四的学生分发调查问卷并收集数据,然后利用粗糙集理论的基于信息熵的启发式属性约简算法,找出影响高校学生学习成绩的关键因素,之后利用基于粗糙集理论的改进的基于分辨矩阵的属性值约简算法,挖掘出影响高校学生学习成绩的关键因素和成绩之间的依赖关系,导出规则集。通过实验验证了该规则集的有效性。研究成果可以帮助高校教师和学生了解影响成绩的关键因素,从而改进教师的教学方法和学生的学习方法。
高校学生;成绩影响因素;粗糙集;规则提取;属性约简
0 引 言
学生成绩在衡量高校教师教学质量以及学生学习效果中意义重大,从成绩中可以看出教师是否完成教学目标,学生对知识的了解和掌握程度是否达到较满意的水平。所以无论是高校教师希望改善教学质量还是学生希望进一步掌握知识,提高成绩都是非常重要的,而影响高校学生学习成绩的因素众多,在面对这么多的因素时,学生和老师可能无法找出哪些是关键性的影响因素,进而无法有针对性地做出努力以有效提高学生成绩。目前对影响学生学习成绩关键因素的研究多是通过调研的方法获取数据,然后利用统计的方法进行分析,很少利用数据挖掘的方法对调研数据做深刻的分析,找出隐藏在数据中的规律性知识。因此,文中设计了影响高校学生学习成绩因素的调查问卷,向该校大一至大四的学生分发调查问卷并收集数据,然后利用粗糙集理论的属性约简算法和规则提取算法,挖掘出影响高校学生学习成绩的关键因素以及这些关键因素和成绩之间的依赖关系,导出规则集,并通过实验验证了规则集的有效性。文中的研究成果可以帮助高校教师和学生了解影响成绩的关键因素,从而改进教师的教学方法和学生的学习方法。
文中所采用的粗糙集(Rough Set,也称Rough集、粗集)理论[1-2]是Pawlak教授在1982年提出的一种能够定量分析处理不精确、不一致、不完整知识与信息的数学工具。该理论最初的原型来源于比较简单的信息模型,它的基本思想是通过关系数据库分类归纳形成概念和规则,通过等价关系的分类以及分类对于目标的近似实现知识发现。粗糙集理论能处理模糊和不确定的知识,在保持分类能力不变的前提下,通过知识约简,导出决策和分类规则。所以文中利用粗糙集对收集的300份中有效的279份成绩样本先进行属性约简,然后进行规则提取,得出了影响高校学生成绩的关键因素。
1 基本概念
文中用到的相关概念介绍如下[3]:
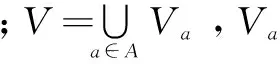
定义2:信息系统S=(U,A,V,f),若A=C∪D,C∩D=∅,C为条件属性集,D为决策属性集,这样的信息系统称为决策表,决策表是一类特殊而重要的信息系统。

定义4:R为一族等价关系P∈R,若ind(R)=ind(R-{P}),则称P为R中不必要的,否则称P为R中必要的。如果每一个P∈R都是必要的,则称P为独立的,否则称P为依赖的。
定义5:对于一个决策表S=(U,C∪D,V,f),B⊆C,若B是独立的,且ind(B)=ind(C),则称B是C的一个约简,记为red(C)。
定义6:核属性定义为core(P)=∩red(P),其中red(P)表示P的所有约简。
核的概念的用处:(1)可以作为所有约简的基础;(2)在知识约简中是不能消去的知识特征集合。

定义8:在信息系统S=(U,A,V,f)中,C∈A,∀a∈A-C关于属性集C的重要性定义为:
sgfc(a)=H(C∪{a})-H(C)
由定义可知,属性a∈A-C关于属性集C的重要性由C中添加a后所引起的信息熵的变化大小决定,此值越大,a关于C越重要。
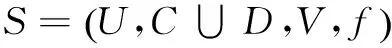
因此,分辨矩阵中元素cij是能够区别对象xi和xj的所有属性的集合;但若xi和xj属于同一决策类时,则分辨矩阵中元素cij的取值为空集∅。显然,分辨矩阵是一个依主对角线对称的n阶方阵,在进行分辨矩阵运算时,只需考虑其上三角(或下三角)部分[5]。
对于规则的质量,有三个衡量标准,分别是置信度、覆盖度和支持度[6]:
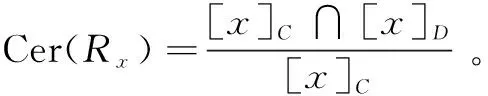
确定性程度Cer(Rx)反映了决策规则的可信性,或者说置信度,是衡量规则r中条件类分配到决策类的精度。

覆盖度Cov(Rx)用来评估决策规则的质量,反映了决策规则条件类对决策类的覆盖程度。
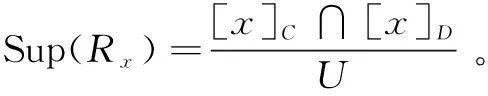
支持度Sup(Rx)用来衡量决策规则的强度,反映了论域中支持此决策规则的对象占全体对象的比例。支持度越大,说明支持该决策规则的对象越多,规则的强度就越大,规则的泛化能力和鲁棒性就越好。
2 属性约简方法
现有的主流属性约简方法有基于正域的属性约简方法、基于属性依赖度的属性约简方法、基于信息熵的属性约简方法和基于差别矩阵的属性约简方法等[7-10]。基于信息熵的属性约简方法利用信息熵来度量属性重要度,算法运行效率和准确性都相对较高。因此,文中采用基于信息熵的属性约简方法,算法描述如下[11]:
输入:信息系统S=(U,A,V,f);
输出:信息系统的核与最小约简。
步骤1:计算H(A)。
步骤2:求Core(A)。
(1)Core(A)=∅;
(2)对每个a∈A,计算sgf(a);
(3)对每个a∈A,IFsgf(a)>0THENCore(A):=Core(A)∪{a};
(4)输出Core(A)。
步骤3:求最小约简。
(1)令C=Core(A),执行以下过程;
(2)若H(C)=H(A),则C为A的一个约简,转(3),否则转(2);

(4)输出约简C。
3 规则提取方法
规则提取即为属性值约简,是在保持决策能力不变的前提下,在属性约简的基础上,进一步删除冗余的属性值以提高生成规则的泛化能力。属性值约简有很多种算法,常见的有一般值约简算法、基于分辨矩阵的值约简算法、基于LEM2的规则提取算法等[12-13]。由于基于分辨矩阵的规则提取方法简单易操作,但效率较低,所以为了提高效率,文中采用一种改进的基于分辨矩阵的属性值约简算法,描述如下[14]:
输出:该决策表的一个决策规则集R。
步骤1:构造M(S)。
步骤2:计算第i行核属性C0。
(1)C0=0;
(2)num(j)为M(S)第i行第j个元素所含的属性个数,对M(S)每一行IFnum(j):=1THENC0:=C0∪cij。
步骤3:修改M(S)。
(1)B←C0;
(2)IFCij∩B≠∅
THENM(S)=M(S)-{Cij}
其中i为定值,即将分辨矩阵的第i行中所有与B相交不空的属性集赋空;
(3)IFM(S)第i行为空,THEN执行步骤4,ELSE转(4);
(4)计算每个c属于C-B的重要性,扩充B,计算c∈C-B在M(S)的第i行中出现的次数,将出现次数最多的属性加入B转(2)。
步骤4:得出规则。
(1)对于第i行IFc∩B:=∅THENDes([x]B)→Des([x]D);
(2)用上述算法对每一行对象进行处理,最终得到决策规则集R。
4 实验分析
4.1 数据收集
为了得到大量相关数据来研究影响高校学生学习成绩的关键因素,设计了一份影响高校学生学习成绩的调查问卷。问卷内容涵盖了学生基本信息、学习态度、学习方法三大方面。其中,基本信息包括学生的个人信息和家庭信息,学习态度包括学习目的与学习动力,学习方法包括学习的时间地点与方式手段。问卷共包括21个问项,前20个构成条件属性,后一个为决策属性。为了便于数据处理与提取,所有问项皆为单选,每个答案独立不重叠。具体的调查问卷见表1。

表1 调查问卷
为了使调研对象的分布较均匀,调研结果更加可靠,调研对象为在校的大一到大四的学生,调研地点有宿舍、图书馆、自习室、考研教室、食堂、校园街道。总共收了300份问卷,剔除其中不符合要求以及明显随意填写无参考价值的21份问卷,剩余279份为真实有用数据。
4.2 数据处理
使用第2节中基于信息熵的属性约简算法对收集的279份数据进行属性约简,约简结果为14个属性:性别*,父母的平均文化程度*,每周上网的时间,上课时一般坐在第几排,母亲职业,图书馆借书频率,爱好,锻炼身体的时间,购买学习辅导书,学习上遇到问题时的解决方式,作业是否独立完成,翘课的频率,努力学习的原因。其中,打*的2个为核属性。
在上述属性约简的基础上利用第3节中改进的基于分辨矩阵的属性值约简算法对约简后的决策表进行处理,得出了33条有效规则,鉴于篇幅有限,在此就不列出了。其中,覆盖度0.5以上,支持度0.3,置信度0.9以上的规则共16条,如表2所示。

表2 规则集
其中,Ci=j中的Ci代表表1中的第i个问题也是第i个条件属性,Ci的值j代表表1中第i个问题的第j个选项也是条件属性的值,D为决策属性,D的值为表1中第二十一个问题的选项也是决策属性值。
为了验证得出规则的质量,从279份数据中分别随机抽出30%、60%、90%的数据作为测试用数据,以验证上述16条规则的分类精度,也就是规则的可靠程度。为了保证结果的准确性,对每种比例的测试数据都抽取了100次,如30%的测试数据,抽取100次,计算每次抽取组的分类精度,取100次分类精度的平均值作为最终结果。不同比例测试数据的分类精度如表3所示。
从表3中可以看出,通过运用基于信息熵的属性约简算法以及改进的基于分辨矩阵的属性值约简算法后,得出的16条规则的分类精度均在0.7以上,由此可见从数据集中得出的16条规则是较为可靠的。
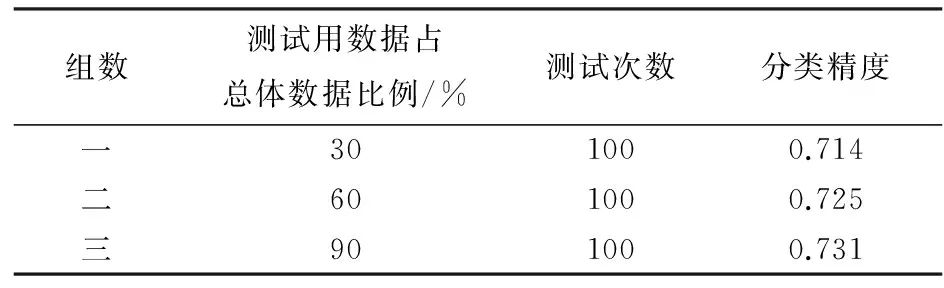
表3 16条规则的分类精度
为了进一步验证文中方法的正确性,从279份数据里随机抽取50%、60%、70%、80%、90%的数据作为训练数据,剩余数据作为测试数据,进行交叉测试,每组交叉测试进行100次。计算结果如表4所示。

表4 交叉测试结果
从表4的测试结果中不难得出,当训练数据量和测试数据量各占总数据量的50%时,分类精度依然可以达到0.6以上,说明文中采用的算法较为恰当,得到的规则的准确度和泛化能力也比较好,从而验证了文中方法的有效性,证明了文中结论的精确性。而且当训练数据增多时,分类精度也逐渐提高。这是因为训练数据越多,所提取规则的质量也越好,这个结果也符合人的直观认识。
从上述实验分析结果可以看出,影响高校学生成绩的因素可以分为两个方面:一是主观态度,包括:上自习时间、上网时间、锻炼身体的时间、上课时坐在第几排、图书馆借书频率、作业是否独立完成以及翘课频率等;二是客观环境,包括:性别、父母文化程度、母亲职业等。再由得出的规则综合来看,一是态度积极向上的学生成绩多优于态度一般的学生,像自习时间、图书馆借书频率、作业独立完成情况、锻炼身体的时间等与学校成绩呈正相关,而上网时间、翘课频率与学生成绩呈负相关;二是女生成绩普遍好于男生,因为女生比较细心,在学习考试当中更容易取得优良的成绩;三是父母文化程度越高孩子成绩越好,因为文化程度高的父母可以为子女提供更好的学习指引,更擅长培养子女良好的学习习惯。从提取的规则中发现有趣的是母亲的职业对孩子成绩的影响要大于父亲职业的影响,也许是受中国相夫教子的传统影响,母亲在子女成长的过程中陪伴的更多,母亲的很多行为习惯比父亲对子女造成的影响更大,所以母亲在孩子的学习生活中扮演着非常重要的角色。
以上研究成果可以帮助高校教师和学生了解在众多的影响因素中有哪些是影响学生学习成绩的最关键因素,以及这些关键因素和成绩之间的依赖关系,从而帮助教师改进教学方法,并帮助学生改进学习方法,以更好地提高成绩。
5 结束语
为了帮助高校教师及学生准确分析影响学习成绩的关键因素,以有效提高学生成绩,文中设计了影响高校学生学习成绩因素的调查问卷,构成决策表,然后利用粗糙集理论的属性约简和规则提取算法,从决策表中提取影响高校学生学习成绩的关键因素以及这些关键因素和成绩之间的依赖关系,导出规则集,通过实验验证了规则集的有效性。研究成果可以帮助高校教师改进教学方法,帮助高校学生改进学习方法。
[1]PawlakZ,Grzymala-BusseJW,SlowinskiR,etal.Roughsets[J].CommunicationsoftheACM,1995,38(11):88-95.
[2]PawlakZ,SkowronA.Roughsets:someextensions[J].InformationSciences,2007,177(1):28-40.
[3] 张文修,吴伟志,梁吉业,等.粗糙集理论与方法[M].北京:科学出版社,2001.
[4] 吕林霞,赵锡英,唐占红.一种基于信息熵的信息系统属性约简算法[J].自动化与仪器仪表,2013(5):197-199.
[5]PawlakZ.Roughsetapproachtoknowledge-baseddecisionsupport[J].EuropeanJournalofOperationalResearch,1997,99(1):48-57.
[6]PawlakZ.Roughsets,decisionalgorithmsandBayes'theorem[J].EuropeanJournalofOperationalResearch,2002,136(1):181-189.
[7] 陈 娟,王国胤,胡 军.优势关系下不协调信息系统的正域约简[J].计算机科学,2008,35(3):216-218.
[8] 路松峰,刘 芳,胡 波.一种基于属性依赖的属性约简算法[J].华中科技大学学报:自然科学版,2008,36(2):39-41.
[9]FaustinoAgreiraCI,MachadoFerreiraCM,MacielBarbosaFP.Roughsettheory:dataminingtechniqueappliedtotheelectricalpowersystem[M].Netherlands:Springer,2013.
[10] 杨 萍,李济生,黄永宣.一种基于二进制区分矩阵的属性约简算法[J].信息与控制,2009,38(1):70-74.
[11] 吴尚智,苟平章.粗糙集和信息熵的属性约简算法及其应用[J].计算机工程,2011,37(7):56-58.
[12] 徐 怡,李龙澍,李学俊.改进的LEM2规则提取算法[J].系统工程理论与实践,2010,30(10):1841-1849.
[13]Grzymala-BusseJW.AnewversionoftheruleinductionsystemLERS[J].FundamentalInformation,1997,31(1):27-39.
[14] 饶 泓,夏叶娟,李姆竹.基于分辨矩阵和属性重要度的规则提取算法[J].计算机工程与应用,2009,44(23):163-165.
Research on Factors Affecting College Achievement Based on Rough Set
CAI Xing-yu1,XU Yi1,2,CHENG Zhi-wei1
(1.Department of Computer Science and Technology,Anhui University,Hefei 230601,China; 2.Key Lab of Intelligent Computing and Signal Processing of Ministry of Education,Anhui University, Hefei 230039,China)
Achievement is an important indicator of teaching quality and student learning.Because of many factors that affect student’s achievement,teachers and students cannot clearly recognize the key factors affecting the results.Therefore,on the one hand,teachers cannot make an improvement to teaching methods to improve the quality of teaching.On the other hand,students are unable to make targeted improvements to the learning methods to improve study performance.To help college students and teachers for analysis of key factors influencing academic performance accurately,a questionnaire about factors affecting college student achievement is designed.Those data are collected from the school’s freshman to senior,then using heuristic attribute reduction algorithm based on information entropy in rough set theory to identify the key factors affecting the performance of college students,and next applying improved property values reduction algorithm based on resolution matrix in rough set theory to mine key factors affecting student achievement and college students dependencies between the results derived the rule set.Finally through the experiment,the validity of the rule set is verified.Research can help university teachers and students to understand the key factors that affect performance,thereby improving the way teachers teaching and students learning.
college student;factors affecting achievement;rough set;rule extraction;attribute reduction
2016-01-21
2016-04-26
时间:2016-10-24
国家自然科学基金资助项目(61402005);安徽省自然科学基金项目(1308085QF114);安徽省高等学校省级自然科学基金项目(KJ2013A015,KJ2011Z020);安徽大学大学生科研训练计划项目(KYXL2014064);安徽大学计算智能与信号处理教育部重点实验室开放课题项目
蔡兴雨(1994-),男,研究方向为机器学习、数据挖掘;徐 怡,副教授,博士,研究方向为智能信息处理和粗糙集理论。
http://www.cnki.net/kcms/detail/61.1450.TP.20161024.1114.048.html
TP39
A
1673-629X(2016)11-0200-05
10.3969/j.issn.1673-629X.2016.11.043
