基于显著前景块模型的贝叶斯目标跟踪
2016-02-27方贤勇
王 安,方贤勇
(安徽大学 计算机科学与技术学院,安徽 合肥 230601)
基于显著前景块模型的贝叶斯目标跟踪
王 安,方贤勇
(安徽大学 计算机科学与技术学院,安徽 合肥 230601)
光照变化、背景混淆、形态变化等仍然是视频目标跟踪中具有挑战性的问题,有效、自适应的外观模型是基于外观模型的目标跟踪方法用以克服这些问题的关键。针对此问题,提出了一种基于显著前景块模型的在线贝叶斯目标跟踪方法。首先,提出一种精确显著的前景提取方法,建立基于块的显著前景块模型,可以有效抑制非前景因素的影响。同时,提出一种与显著前景块模型适应的模板更新方法,有效适应目标前景的变化。然后,结合多层背景块模型,获得有效、自适应的基于块的外观模型。最后,建立基于贝叶斯框架的目标跟踪方法。经过多组具有挑战性的视频序列测试,该跟踪方法可以有效抑制光照变化、背景混淆及形态变化等问题,具有较好的自适应性。通过对比实验,结果表明该跟踪方法较现有常见的方法有较强的鲁棒性和较好的精确性。
目标跟踪;外观模型;显著前景模型;模板更新
0 引 言
目标跟踪是计算机视觉领域一项基本的研究课题,在许多领域得到了广泛应用,如视频监控、目标识别、机器人、事件分析和无人驾驶汽车等。目前,提出了许多跟踪方法,但是,为了获得有效稳定的跟踪,仍然存在一些挑战性的问题,如光照变化、目标几何变形、快速移动、局部遮挡和背景混淆等。针对这些问题,文中提出了一种基于显著前景块模型的在线贝叶斯目标跟踪方法。
外观模型(appearance model)是跟踪的基础[1-2],其有效性和适应性决定了目标跟踪的精确性和鲁棒性。目前的外观模型可以粗略地分为三类:基于整体的模型(bounding-box model)[3-4]、基于部件的模型(part-based model)[1,5]和基于块的模型(patch-based model)[6-7]。基于整体模型的方法失去了局部空间信息的描述,对目标遮挡、变形等情况非常敏感。基于部件模型的方法需要对各个部件分别初始化、训练和跟踪,增加了计算复杂度,在实时在线的应用中受到限制。Jia等[6]和Kwon等[7]提出了基于块的方法,在目标匹配方面具有一定的灵活性和适应性。但是它们都仅考虑了前景外观信息,没有考虑背景信息,当背景中包含与前景相似的区域时可能会导致目标漂移。同时考虑前景和背景信息的外观建模方法在前背景区分上明显优于只考虑前景建模的方法[8]。针对目前的问题,文中采用基于块的外观模型,通过提取各块的颜色统计直方图特征,建立外观模型。基于块的外观模型可以很好地提取和保留图像局部信息,并具有较好的适应性。同时,为了获得更好的前景和背景区分效果,文中同时进行前景和背景建模。
在大多数在线目标跟踪方法中,目标通常用矩形框来标记[1,3-7]。矩形框内不仅包含了全部的目标前景信息,同时包含了部分背景信息。包含的背景信息,在一定程度上影响了目标前景与背景的区分性,在跟踪效果上有所削弱。Lee等[9]提出了一种较为精确的前景提取方法,但是当目标前景本身包含与背景相似的区域时,其跟踪的有效性和稳定性受到影响。针对此问题,文中提出了一种提取精确的显著前景的方法,建立基于块的显著前景块模型,可以有效增强目标前景和背景的区分,最终获得准确可信的目标跟踪。
综合上述分析,为了克服视频目标领域仍然存在的挑战性问题,如光照变化、背景混淆、目标变形等,同时弥补目前多数跟踪方法中前景模型的精确性不足,文中首先提出一种提取精确的显著前景的方法。该方法在第一帧中把标记目标的矩形框分割成多个小块并统计每块的颜色直方图,以目标矩形框外部周围背景区域为参照,计算选择目标区域显著块来建立显著前景模板。同时,提出了一种与显著前景块模型适应的模板更新方法,根据每帧的跟踪结果提取有效前景特征来补充更新前景模板特征。在此基础上,结合多层背景块模型,建立基于块的外观模型。最后,基于贝叶斯框架,建立了基于显著前景块模型的在线贝叶斯目标跟踪方法。
1 基于显著前景块模型和多层背景块模型的外观模型
基于块的外观模型可以很好地提取和保留图像局部信息,并具有较好的适应性。首先将视频图像划分为多个小块,分别提取颜色直方图。颜色直方图采用HSV颜色空间,每个通道划分16个容器区间,三个通道共48个容器区间。文中对目标前景和背景分别使用基于块的特征提取和建模方法。
1.1 显著前景块模型
通常,目标前景与周围背景存在一定的差异。如图1(a),目标本身与背景差异较大,前景与背景可以较好地区分。但是,现实世界中,受到光照等因素的影响,目标物体的表面可能并不都是与背景容易区分的。如图1(b),由于光照强度较弱,目标区域出现明暗不一的现象,有些区域比较明显,有些区域较暗且与背景的差异较小。图1(c)显示了图1(b)中左图经过灰度化并直方图均衡化的结果,可以直观较清晰地区分目标前景较为明显的区域。若把较暗的部分作为前景模板特征,会影响目标的区分性,最终影响目标的检测与跟踪。人类的视觉机制[10]是通过目标与背景的显著性差异来观察追踪事物的。文中提出了一种提取精确、显著的目标前景的方法,该方法综合利用前景和背景信息,获取目标的显著区域,并提取颜色直方图作为前景特征模板。

图1 分别基于显著前景和全部目标框的概率分布图
在第一帧,通过手动标记或目标检测算法获得目标前景区域,通常用矩形框标记。目标矩形框区域不仅包含整个目标前景,同时包含背景信息,影响目标表示的稳定性和有效性。文中提出的提取精确显著目标前景的方法就是排除矩形框内与背景相似的区域,保留显著前景区域。如图1(a)、(b)所示,左图为原始图像,中间上下两幅分别标记了基于显著前景的前景区域和基于全部目标框的前景区域,右边上下两幅为对应的前景概率分布图。可以看出,显著的前景提取提高了前景概率的准确性,显著前景区域的前景概率较大,而与背景相似的前景区域的前景概率较小,较符合真实的计算结果和观察现象。
从图中观察到,目标矩形框的外部周围是背景信息,与目标矩形框内的背景信息相似。目标前景信息多集中在目标矩形框的中间部分。定义目标矩形框区域为Ω,同时定义一个与Ω同心的扩张矩形框区域ΩE和收缩矩形框区域ΩS。区域ΩE-Ω表示扩张部分的背景区域,标记为ΩB。设Ω的大小为w×h,则ΩE的大小为(w+16)×(h+16),ΩS的大小为0.6w×0.6h。将ΩE划分为8×8大小且不互相重叠的小块,并统计每块的HSV颜色直方图。文献[11]定义一个像素的显著值为该像素到其他像素的颜色距离度量之和,据此文中提出下面的计算公式,分别计算Ω内每块相对于ΩS的显著值SS(i)和相对于ΩB的显著值SB(i)。其中,i代表第i小块。SS(i)表示在ΩS中与第i小块颜色直方图最接近的K个小块的颜色直方图的距离之和。
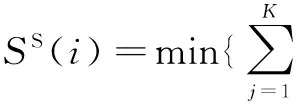
(1)
其中,h(i)表示Ω中第i小块的颜色直方图;hS(j)表示ΩS中第j小块的颜色直方图。
同样的,SB(i)表示在ΩB中与第i小块颜色直方图最接近的K个小块的颜色直方图的距离之和。
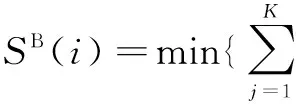
(2)
其中,hB(j)表示ΩB中第j小块的颜色直方图。
可以发现,当第i小块包含背景信息越少时,SB(i)较大,SS(i)较小,小块i前景的概率越大。用式(3)表示小块前景置信度:
(3)
当SS(i)>SB(i)时,φ(i)<0,此时取φ(i)=0。当SS(i) 在式(1)、式(2)中,当参数K取值较大,第i块本身的信息会受到很大的影响,这里选择K=4。计算得到各小块的前景置信度后,选择φ(i)>γ的小块作为前景块,提取前景块的颜色统计直方图特征作为显著前景模板。这里取γ=0.5。 1.2 多层背景块模型 基于块的外观模型在处理光照变化、目标形变等问题上有一定的优势。但是,划分小块的方法也会削弱前景背景的区分性。为了获得更多丰富的背景信息,更好地将背景区域从前景区域中分离,减少因划分小块而削弱前背景区分的影响,文中建立了多层背景块模型。 首先将输入图像划分为互不重叠的8×8小块,每个位置的小块j,其颜色直方图为Bj。在第一帧,对于目标矩形框外部的背景部分,其背景颜色直方图由对应位置小块的颜色直方图表示;对于目标矩形框内部的小块,选择靠近小块几何距离最近的矩形框外部背景小块的颜色直方图来表示。如图2所示,B1、B3的值分别来自于B2、B4。从第二帧开始,检测跟踪到目标位置后,更新目标矩形框区域外部的背景块,将此帧对应位置的小块背景信息加入背景模板中对应位置的小块背景信息容器队列,容器队列保留十帧的数据。 图2 图1(b)中视频序列David首帧的背景模型 在线的目标跟踪是在第一帧手动标注或目标检测算法检测目标区域,提取其特征建立特征模板,然后从第二帧开始跟踪目标并更新目标模板。贝叶斯框架是在当前观察情况下根据先前的跟踪结果及观察情况进行当前状态的搜索预测。在第t帧,以t-1帧获得的目标位置为中心,设置目标搜索区域Rt。在搜索区域Rt内,利用前景模板和背景模板,计算各小块内像素的前景概率。根据贝叶斯跟踪框架,搜索跟踪区域内使得贝叶斯后验概率最大的位置作为跟踪结果。为了提高跟踪的稳定性和精确度,克服背景混淆、形变、局部遮挡等因素引发的目标漂移问题,文中同时采用结合目标前景的模板掩码来跟踪。同时,光照变化等因素会改变目标前景的颜色特征,于是文中提出了一种适应前景显著模型的模板更新方法,增强前景特征描述,提高前景背景区分效果,有效抑制光照变化带来的前景块误检和漏检等问题。 2.1 前景概率 假设第t-1帧,目标大小为w×h,则在第t帧,目标搜索区域Rt大小为(w+2δ)×(h+2δ),与第t-1帧的目标矩形框区域同心。同样,将目标搜索Rt划分为互相不重叠的8×8像素的小块,对每一小块i提取颜色直方图h(i)。然后,通过概率计算获得每个小块内像素的前景概率。 首先,对搜索区域内的每一小块i,用k近邻方法[12]从前景模板中选择与小块颜色直方图距离最近的两个小块,计算得到它们的颜色直方图距离之和DF(i)。 (4) 其中,h(i)表示第i小块的颜色直方图;hF(j)表示从前景模板中选择的第j小块的颜色直方图。 其次,再从背景模板中选择与小块直方图距离最近的两个小块。为了减少背景混淆因素的影响,从与小块几何距离较近的25个小块中选择。计算得到它们的颜色直方图距离之和DB(i)。 (5) 其中,h(i)表示第i小块的颜色直方图;hB(j)表示从背景模板中选择的第j小块的颜色直方图。 这样,小块i内的像素u的前景概率表示为: (6) 当DF(i)越小,DB(i)越大,F(u)趋向于1;反之,趋向于0。将F(u)归一化到[0,1]区间,当归一化结果小于0.8时,F(u)=0。 2.2 在线贝叶斯目标跟踪 在贝叶斯框架下,假设xt和zt分别表示第t帧的状态和观察值,在给定观察值zs:t={zs,zs+1,…,zt}(s p(xt|zs:t)=αtp(zt|xt)p(xt|zs:t-1) (7) 其中,αt为正规化项;p(zt|xt)为似然概率;p(xt|zs:t-1)为先验概率。 (8) 文中对先验概率采用了平均分布模型,p(xt|zs:t-1)为常数,则 (9) 在搜索区域搜索目标的位置,根据一般的目标搜索方法,似然概率p(zt|xt)应该是搜索滑动窗口内像素的前景概率值之和。但是考虑到可能的背景噪声影响,加入了目标轮廓信息,即目标前景的模板掩码,可以有效抑制背景混淆和局部遮挡带来的目标漂移问题,如图3所示。将目标前景的模板掩码记为ωm。所以,似然概率p(zt|xt)表示为滑动窗口内像素的前景概率与目标前景的模板掩码的相似度。 目标前景的模板掩码的值在第一帧中由目标矩形框内像素的前景概率初始化。 图3 结合目标前景的模板掩码的目标跟踪示意图 2.3 在线模板更新 在目标跟踪过程中,随着外部光照变化、背景变化,以及目标自身的结构形态变化,统一不变的目标模型是不能适应的。模型更新是在线目标跟踪非常关键的一步,它影响了目标模板的适应性和跟踪的鲁棒性。 显著前景模板更新:随着光照的变化,目标物体表面的颜色也跟着变化。为了适应目标的变化,同背景模型相似,也采用多层的目标显著前景块模型。在t帧,得到目标位置后,把目标矩形框区域内的前景小块的颜色直方图加入到目标前景特征模板中。为了尽可能消除背景噪声的影响,根据目标前景的模板掩码,当小块对应的模板掩码的值ωm(·)>0.75,则将其颜色统计直方图特征加入前景模板中。前景模板中只保留包含当前帧的前5帧的数据。 模板掩码更新:目标的形态也在时刻变化,根据在t帧得到的前景区域及所对应的前景概率值,对目标前景的模板掩码作如下更新操作: (11) 这里λ取0.999 5。 跟踪过程中可能出现最佳的目标位置可信度较低,当p(zt|xt)>0.75时,更新模板。 文中分别在10组视频数据对提出的跟踪方法进行性能测试:Basketball(576×432)、BlurCar1(640×480)、David(320×240)、Gym(426×234)、Lemming(640×480)、Liquor(640×480)、Occlusion1(352×288)、Skating2(640×352)、Tiger2(640×480、Trellis(320×240)。这些数据均可从http://www.visual-tracking.net[13]获取。数据的平均帧数为861帧,文中提出的算法用C++实现且没有经过优化,在3.0GHz处理器、8Gbyte内存的计算机上达到了平均6.6帧每秒。选择四种跟踪方法与文中提出的方法进行比较:CT[14]、LSHT[5]、PPT[9]、DAT[15]。同时,为了从实验上加强证明显著前景模型的有效性,采用以目标矩形框内的全部(bounding-box)作为前景特征提取,与文中提出的基于显著前景块模型的跟踪方法形成对比。 3.1 定性分析 图4给出了CT、LSHT、PPT、DAT及基于全部目标矩形框的跟踪方法(Non-Salient Foreground,Non-SF)和文中跟踪方法(Salient Foreground,SF(Proposed))对2组图像序列的跟踪结果和定性比较。视频序列Basketball、Gym、Skating2中目标物体存在较大的姿态结构变化及遮挡,Basketball、BlurCar1存在目标快速运动和相机抖动。如Basketball(见图4(a))的#647,因目标的姿态变化和背景混淆,对比的方法缺乏有效的模板适应能力,目标跟踪结果发生漂移或错误。而文中方法是建立在基于块的外观模型上,同时结合目标模板掩码,具有较好的适应性,抑制了目标漂移,可以有效跟踪到精确的结果。 图4 文中跟踪方法和其他四种方法的跟踪结果示例 David、Lemming、Liquor、Trellis、Tiger2等序列,光照变化剧烈,目标表面颜色特征变化较大。如David(见图4(b))的#292,目标表面的光照由初始的较暗变到较为明亮,目标颜色变化较大,且初始目标特征不明显,目标框内包含较多背景信息。对比方法采用整框为前景建立模板,受到过多背景因素的影响,同时对光照的剧烈变化适应能力弱,跟踪结果不准确。而文中方法基于显著前景,获得了目标前景的精确表达,有效处理了背景信息的影响,同时实时更新前景模板,对光照的变化有很强的适应能力,跟踪效果明显较好。 3.2 定量分析 表1 六种跟踪方法的平均中心误差统计结果 (ACE代表平均中心误差(AverageCenterError)) 文中给出了在固定重叠率阈值下的成功率,即PASCAL统计得分方法[17],该方法可以在总体上较好地评估跟踪结果的准确率和稳定性,见表2。这里固定重叠率阈值为0.5。 表1和表2分别展示了六种跟踪方法对10组数据的平均中心误差和给定阈值的成功率。相较其他跟踪方法,文中方法总体上具有较低的平均中心误差和较高的成功率。视频序列Gym,因为目标姿态尺度与初始状态变化较大,所以在中心误差较小的情况下成功率仍然较低。 表2 六种跟踪方法的成功率统计结果 (重叠阈值为0.5,SR代表成功率(SuccessRate)) 3.3 实验结论 实验从定性和定量两个方面评价和分析了跟踪结果的优劣。在选取的十组具有挑战性的视频序列中进行目标跟踪测试,相比CT、LSHT、PPT、DAT这四种方法,文中方法在整体上取得了较好的效果。同时,与文中方法形成对比的基于整框的跟踪方法,其效果明显较差,进一步充分表明了显著前景块模型明显提高了跟踪的精确性和鲁棒性。实验结果表明,文中方法有效处理了跟踪问题中的挑战性因素,如光照变化、背景混淆、形态变化以及遮挡等,获得了精确鲁棒的跟踪效果。 针对目前视频目标跟踪领域仍然存在的问题,如光照变化、背景混淆、形态变化等,文中提出了一种基于显著前景块模型的在线贝叶斯目标跟踪算法。一方面,通过显著前景的提取,提高了前景模型的精确性,削弱了目标框中背景因素的影响,并且增强了前景背景的区分。另一方面,通过建立多层背景模型并结合目标前景模板掩码,有效抑制了背景混淆、形态变化的影响。同时,目标模板的实时更新增强了模板的适应性和鲁棒性。 由于文中在目标尺度变化问题上没有做针对性的处理,尽管在有些视频数据中跟踪结果的中心误差相对较小,但成功率会有所降低。未来的工作将会围绕尺度自适应问题,以期在保持较小的中心误差下获得更好的成功率。 [1] Zhang L,van der Maaten L.Structure preserving object tracking[C]//Proceedings of IEEE conference on computer vision and pattern recognition.Portland,Oregon,USA:IEEE,2013:1838-1845. [2] Li X,Hu W,Shen C,et al.A survey of appearance models in visual object tracking[J].ACM Transactions on Intelligent Systems and Technology,2013,4(4):58. [3] Comaniciu D,Ramesh V,Meer P.Kernel-based object tracking[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2003,25(5):564-577. [4] Hare S, Saffari A, Torr P.Struck:structured output tracking with kernels[C]//Proceedings of international conference on computer vision.Barcelona,Spain:IEEE,2011:263-270. [5] He S,Yang Q,Lau R W,et al.Visual tracking via locality sensitive histograms[C]//Proceedings of IEEE conference on computer vision and pattern recognition.Portland,Oregon,USA:IEEE,2013:2427-2434. [6] Jia X,Lu H C,Yang M H.Visual tracking via adaptive structural local sparse appearance model[C]//Proceedings of IEEE conference on computer vision and pattern recognition.Providence,Rhode Island,USA:IEEE,2012:1822-1829. [7] Kwon J,Lee K M.Highly non-rigid object tracking via patch-based dynamic appearance modeling[J].IEEE Transaction on Pattern Analysis and Machine Intelligence,2013,35(10):2427-2441. [8] Minka T. Discriminative models, not discriminative training[R].[s.l.]:Microsoft Research,2005. [9] Lee D Y,Sim J Y,Kim C S.Visual tracking using pertinent patch selection and masking[C]//Proceedings of IEEE conference on computer vision and pattern recognition.Boston,USA:IEEE,2014:3486-3493. [10] Mahadevan V, Vasconcelos N. Biologically inspired object tracking using center-surround saliency mechanisms[J].IEEE Transaction on Pattern Analysis and Machine Intelligence,2013,35(3):541-554. [11] Cheng M M,Zhang G X,Mitra N J,et al.Global contrast based salient region detection[C]//Proceedings of IEEE conference on computer vision and pattern recognition.Colorado,USA:IEEE,2011:409-416. [12] Muja M,Lowe D G.Fast approximate nearest neighbors with automatic algorithm configuration[C]//International conference on computer vision theory and applications.Lisboa,Portugal:INSTICC Press,2009:331-340. [13] Wu Y,Lim J,Yang M H.Visual tracking benchmark[EB/OL].[2015-12-14].http://www.visual-tracking.net. [14] Zhang K,Zhang L,Yang M H.Real-time compressive tracking[C]//Proceedings of European conference on computer vision.Florence,Italy:IEEE,2012:864-877. [15] Possegger H, Mauthner T, Bischof H.In defense of color-based model-free tracking[C]//Proceedings of IEEE conference on computer vision and pattern recognition.Boston,USA:IEEE,2015:2113-2120. [16] Wu Y,Lim J,Yang M H.Online object tracking:a benchmark[C]//Proceedings of IEEE conference on computer vision and pattern recognition.Los Alamitos,USA:IEEE Computer Society Press,2013:2411-2418. [17] Everingham M,Gool L,Williams C,et al.The pascal visual object classes (VOC) challenge[J].International Journal of Computer Vision,2010,88(2):303-338. Bayesian Object Tracking Based on Salient Foreground Patch Model WANG An,FANG Xian-yong (School of Computer Science and Technology,Anhui University,Hefei 230601,China) Illumination variation,background clutter and deformation are still challenging problems in visual object tracking.Efficient self-adapting appearance model can be one of the keys to overcome these limits.In view of these problems,a new online Bayesian tracking method is put forward based on salient foreground patch model.First,a new method is introduced to extract an accurate and salient foreground for constructing a patch-based salient foreground model.The foreground patch model can effectively suppress the affections of non-foreground factors.A template update method is also presented to adapt the changes of foreground.Then,an efficient and self-adapting patch-based appearance model incorporating the patch-based multiple background patch model is obtained.Finally,the objects can be tracked based on the Bayesian framework.Experiment on more groups video sequence test with challenge demonstrates that the proposed tracking algorithm can effectively suppress the illumination variation,background clutter and deformation and outperform conventional tracking algorithms in robustness and accuracy. object tracking;appearance model;salient foreground model;template updating 2016-01-10 2016-04-20 时间:2016-10-24 国家自然科学基金资助项目(61502005);安徽省自然科学基金(1308085QF100,1408085MF113) 王 安(1990-),男,硕士研究生,研究方向为图像处理和计算机视觉;方贤勇,教授,通讯作者,研究方向为计算机图形学和计算机视觉。 http://www.cnki.net/kcms/detail/61.1450.TP.20161024.1105.012.html TP301 A 1673-629X(2016)11-0025-06 10.3969/j.issn.1673-629X.2016.11.006
2 在线贝叶斯目标跟踪方法
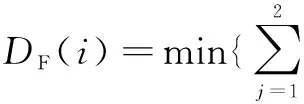
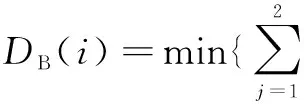
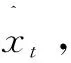
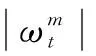
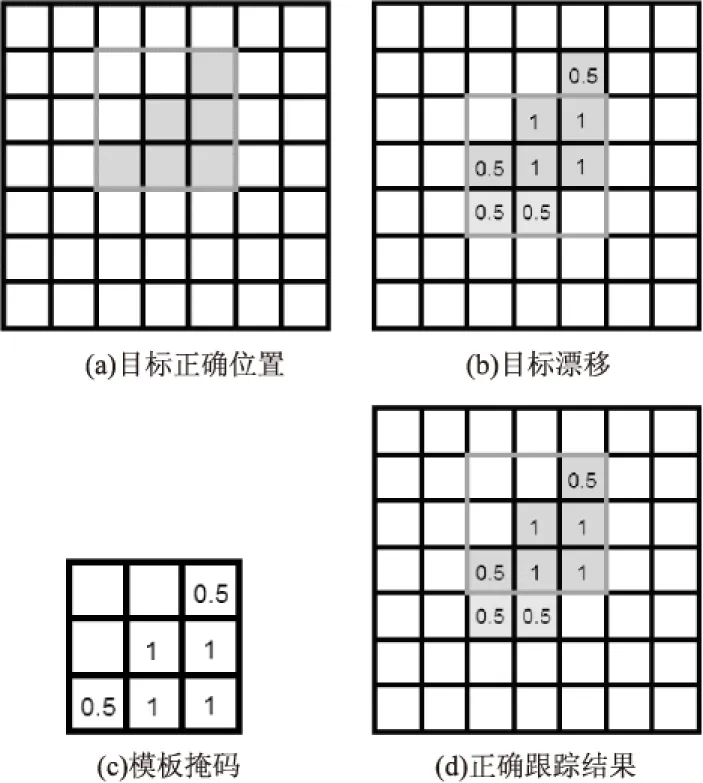
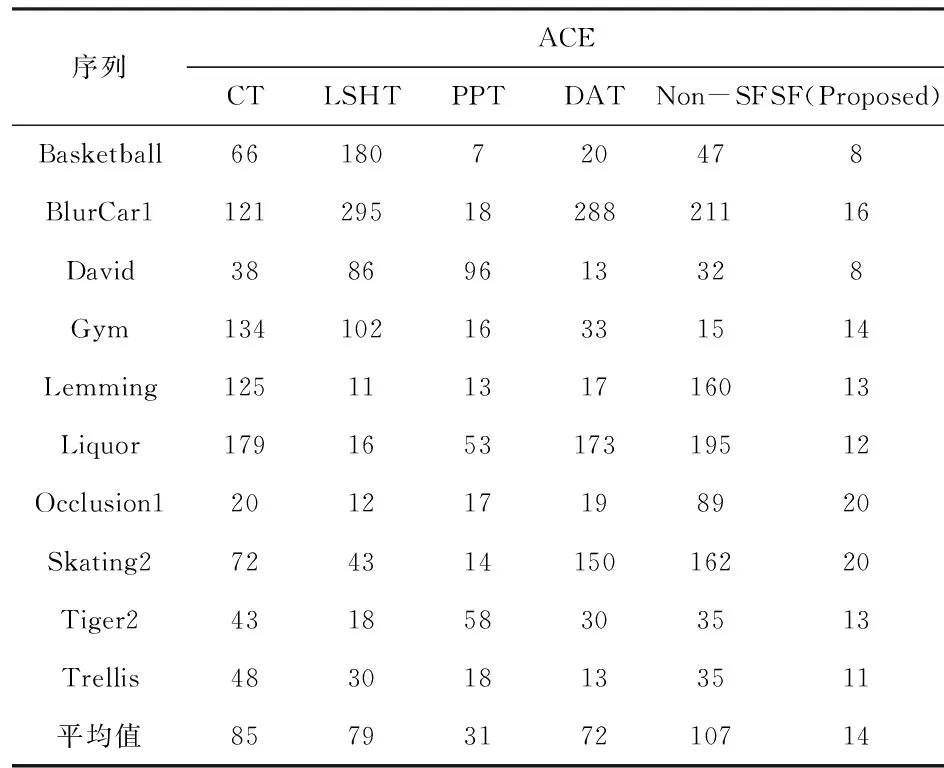
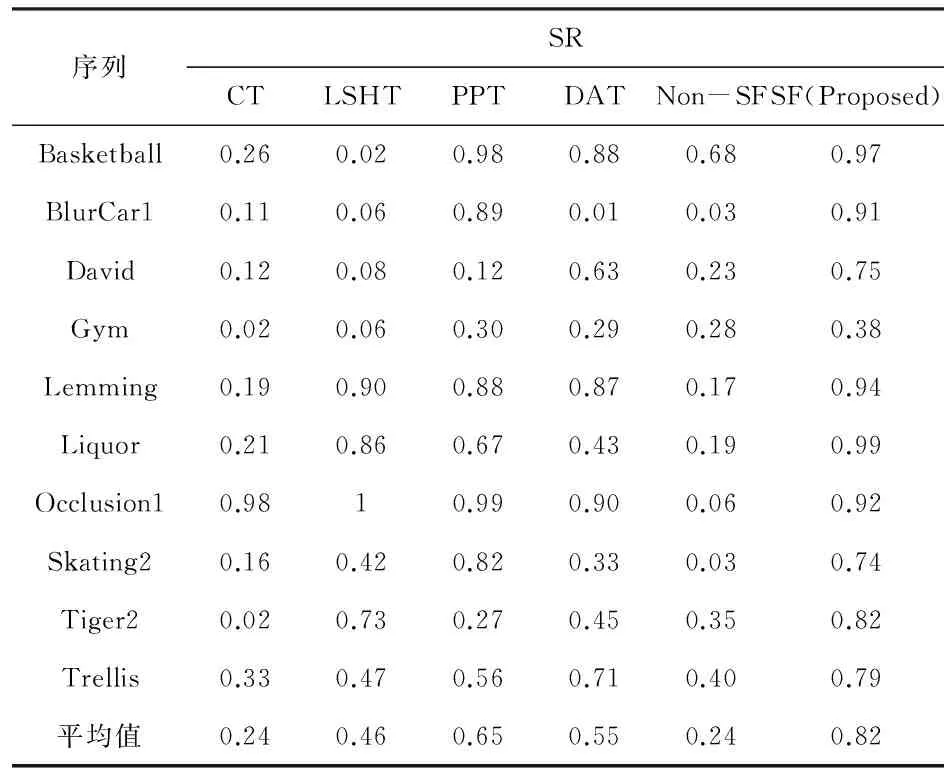
3 实验结果


4 结束语
