基于化学计量方法实现水牛乳中掺水和尿素鉴伪研究
2015-11-08曾庆坤农皓如
黄 丽,林 波,李 玲,曾庆坤,唐 艳,杨 攀,冯 玲,农皓如
(中国农业科学院广西水牛研究所,广西南宁530001)
基于化学计量方法实现水牛乳中掺水和尿素鉴伪研究
黄丽,林波,李玲,曾庆坤*,唐艳,杨攀,冯玲,农皓如
(中国农业科学院广西水牛研究所,广西南宁530001)
以水牛乳7个主要理化指标结合化学计量学为基础,建立了水牛乳中掺水和掺尿素定性和定量模型。聚类分析法较好地区分未掺假乳和掺假乳。Fisher判别分析中典则判别函数能够直观地区分不同掺假含量的样品,线性判别函数能够对未知掺伪乳样品进行定性判别,判别效果良好。多元逐步线性回归法构建的定量模型实测值和预测值的相关系数Rp分别为0.9956、0.9934、0.9937、0.9938、0.9986、0.9991,模型预测值接近于真实值,可实现水牛乳掺假的定量鉴别。
水牛乳,掺假,理化指标,化学计量方法
水牛乳素有“奶中精品”之称,其蛋白质、脂肪、乳糖等营养物质均高于荷斯坦奶牛[1],市场价格较高,非常具有发展前景。一些不法商家在利益驱使下,往水牛奶中掺假,其中掺水和尿素尤为常见,掺水为了提高牛奶重量,掺尿素则提高比重和蛋白质含量。检测掺水最常用感官检测法、比重法和冰点测定法[2-3],检测尿素则采用显色法[4-5],但这些方法费时又费力,不适合生产中大批量的抽样检测。随着检测水平的提高,很多学者借助先进仪器进行乳及乳制品鉴伪研究,利用电子舌[6]、近红外光谱技术[7-9]、低场核磁共振[10]、单频导纳测定[11]等先进仪器进行牛奶掺伪检测,但仪器分析法存在成本高、检测速度慢等问题,不能实现水牛奶的快速检测。牛奶是由多种成分组成的混合体,主要是水和脂肪、蛋白质、乳糖等干物质,干物质的含量影响牛奶稀稠,正常牛奶成分含量基本稳定,会有一定的变动范围[12],水牛乳中掺水和尿素后破坏稳定体系,引起理化指标变化,可通过测定其中主要指标变化分析掺伪情况。
化学计量识别方法包括主成分分析、聚类分析和判别分析等,能有效处理大量数据,通过建立直观的基本假设,同类或相似的“样本”间距离较近,不同样的“样本”间的距离应较远,可根据各样本的距离或距离函数来判别和分类,并利用分类的结果预报未知[13]。本文结合化学计量学中聚类分析、判别分析、多元线性回归等处理方法,分析主要指标变化情况,建立水牛奶中掺水和尿素的定性和定量模型,为水牛乳掺假鉴别提供理论参考依据。
1 材料与方法
1.1材料与仪器
水牛乳取自广西壮族自治区水牛研究所种畜场;超纯水;氢氧化钠、酚酞、尿素(分析纯) 国产。
超纯水一体机美国Milli-Q;多功能乳品分析仪Milko Scan FT120丹麦Foss;单通道牛奶冰点测试仪Model 4250美国Advanced。
1.2实验方法
1.2.1水牛乳取样在2014年3、4、5、6月份间随机采取处于正常泌乳期的健康水牛鲜生乳样,每天早上8点采样。其中3月27、28日,4月11日,5月29、30日,6月4、5、6日共采集8批次用于掺水实验;6月16~30日共采集9批次用于掺水和尿素实验,共采集17批次。
1.2.2水牛乳掺假样制备每批生鲜水牛乳采样后立即运回实验室,并立即用500目滤布过滤去除杂质,取一定量的水牛乳,分别掺入比例(v/v)为0%、5%、7%、8%、9%、10%、15%、20%、25%、30%的超纯水,得到不同掺水量的水牛乳样品共80份(10份/批次×8批次),每个比例水牛乳掺水样250 mL,在3 min内充分混匀,用于各个指标的测定,作为训练集建立模型。另取2批次水牛乳采用同样的配制方法制备不同掺水比例,分别是取3月28日的水牛乳样制备1%~4%、6%~9%的掺水样;取6月5日的水牛乳样制备11%~14%、16%~19%、21%~24%、26%~29%、40%的掺水样,均作为验证样,共计25份。
先配制50%(m/m)尿素水牛奶储备液150 mL,超声30 min充分溶解,取一定量的水牛乳,分别将储备液稀释为质量比是0%、0.02%、0.1%、0.5%、1%、2%的水牛乳尿素掺假样品,共获得掺尿素样品54(6份/批次×9批次)份;同时分别制备掺水(v/v)和掺尿素(m/m)的混合掺假水牛乳样品即10%水+0.1%尿素、10%水+1%尿素、20%水+0.5%尿素、20%水+1.5%尿素共36(4份/批次×9批次)份,均作为训练集。另外取6月24日水牛乳采用同样的方法制备不同掺假比例的验证样,分别是0.02%、0.5%、1%、1.5%各2份和2%的5份,共计13份。
1.2.3水牛乳滴定酸度按照GB 5413.34-2010的方法测定,平行3次。
1.2.4水牛乳冰点采用Advanced Model 4250单通道牛奶冰点测试仪测定,平行3次。
1.2.5水牛乳蛋白质、脂肪、全乳固体、非脂乳固体、乳糖采用福斯Milko Scan FT120多功能乳品分析仪测定,平行3次。
1.2.6数据处理采用Excel 2010处理原始数据,采用IBM SPSS 20.0软件进行聚类分析、Fish判别分析和多元逐步线性回归分析,利用Origin 8.6软件制作相关图表。
2 结果与分析
2.1水牛乳中掺水和尿素定性鉴别模型的建立
2.1.1聚类分析建立水牛乳掺伪定性鉴别模型聚类分析是研究样品或指标分类问题的一种统计分析方法,根据研究对象特征对研究对象进行分类的一种多元分析技术,把性质相近的个体归为一类,使得同一类中的个体都具有高度的同质性,不同类之间的个体具有高度的异质性,达到分类的目的[14]。本文以7个指标含量平均值为变量,采用组间联接和Pearson相关性的方法对3类水牛乳掺假样品进行聚类分析,其中单一掺水样(0%、7%、8%、9%、10%、15%、20%、25%、30%)为第一类,单一掺尿素样(0%、0.02%、0.1%、0.5%、1%、2%)为第二类,混合掺水和尿素样(10%水+0.1%尿素%、10%水+1%尿素、20%水+0.5%尿素%、20%水+1.5%尿素)为第三类。聚类分析的树形见图1,图中将Pearson相关系数按比例调整到0~25的范围,再用逐级连线的方式将相近的个案并为一类。掺水和尿素改变了正常水牛乳的胶体性液体体系,不同的掺假量影响程度不同,故聚类分析并非区分掺假物种类,而是将理化指标变化相似的样品归类。从图上可以清晰地看出各种掺伪样的分辨情况,通过聚类分析将掺伪样分成了两大类,第一大类为水牛乳中掺入10%水+1%尿素、20%水+1.5%尿素、0.5%尿素、1%尿素、2%尿素,其余为第二大类。在小一级的分类中,如距离系数为0-1的分级,各分类的相关系数在0.893~0.997之间,差异很小,难以区分;而距离系数大于3的分类中,各分类的相关系数在-0.607~0.766之间,能够很好地进行分辨。纯奶在距离系数为2时与0.02%尿素乳、0.1%尿素乳聚类一类,相关性很好,皮尔逊相关系数为0.883,不能很好地分辨,但纯奶在距离系数大于15的更大聚类中皮尔逊相关系数分别为-0.022和-0.607,差异较大,能够和其他掺伪样区分开来。综合上述的结果,聚类分析能够较好地区分未掺假乳和掺假乳,可以用于一定差异水牛乳掺假样的区分,但对差异较小的掺假样分辨能力存在一定的局限。

图1 水牛乳掺伪样聚类分析图Fig.1 Cluster analysis of buffalo milk adulterants
2.1.2Fisher判别分析建立水牛乳掺伪定性鉴别模型Fisher判别分析是用已知分类样本的观测指标构造一些彼此正交(不相关)的综合指标即判别函数,这些综合指标可以将属于不同类的个体尽可能的分开,然后计算出每个类的综合指标的均值,即每个类的中心点。当计算出一个新样品的各个综合指标的值之后,就分别计算出新样品到每个类中心点的距离,把它归于离中心点的距离最短的那一类[15]。以7个理化指标含量为自变量,以不同掺伪量为类别区分依据,使用步进式方法,按照Wilks’lambda原则,使用F的概率小于0.05进入大于0.10删除的标准进行判别分析,逐个分析每个指标对模型判别的贡献能力并剔除贡献不显著的变量,剔除了滴定酸度,其他6个指标进入模型,获得2个典则判别函数,分别如下:
Y1=53.598+122.502X1+4.940X2+2.922X3-3.054X4+ 1.328X5+4.794X6
Y2=-38.403-33.999X1+12.018X2+9.370X3-9.730X4+ 1.430X5+12.968X6
函数中X1~X6分别表示冰点、蛋白质、脂肪、全乳固体、非脂乳固体和乳糖。均为进入模型的6个指标的线性组合,其特征值分别为978.78和19.58,分别能够解释模型方差变化的98.0%和2.0%,累计方差贡献率为99.9%,包含了掺伪样品的主要信息,可以用于区分不同掺伪乳的差异。将各个掺伪乳的6个理化指标代入函数获得判别得分,并作散点图,结果见图2。
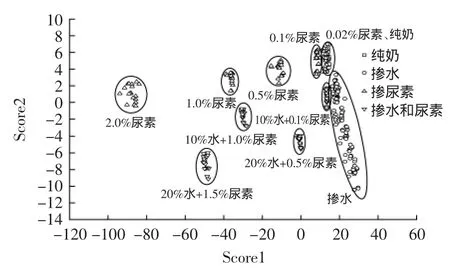
图2 水牛乳掺伪样判别函数得分散点图Fig.2 Scatter plot of canonical discriminant functions on buffalo milk adulterants
由图2可知,同一个掺伪比例不同批次的水牛乳判别得分散开成群,这是因为水牛乳的理化含量受到饲养条件、气候、品种、季节等外在因素的影响会在较小的范围内变动,本研究是在3~6月期间对尼里-拉菲、麽拉、高代三品种杂交、一代杂交等多个品种的水牛进行取样,获得具有代表性的理化指标正常波动范围。从图2中可知,在单一掺水乳中,判别分析法能够较好地区分纯奶与掺入量为7%以上的掺水奶,随着掺水量的增大,数据区域从上到下依次分布。在单一掺尿素乳中,除了掺入0.02%尿素的水牛乳与纯奶的位置部分重合,不便于直观区分,其他掺伪量的水牛乳样品间均能清晰明了地分辨,掺尿素量在0.1%以上的水牛乳均能与未掺假乳区分。建立的判别函数同样能够很好地将四组掺入尿素和水的水牛乳区分开,但是掺入10%水+0.1%尿素的水牛乳与掺水量7%~9%的位置较为接近,原因可能是掺0.1%尿素影响了掺水所引起的水牛乳体系变化,消除了一部分理化指标的波动,使之与单独掺水为8%左右的水牛乳相同。与聚类分析法相比较,判别分析能够更好更直观地区分未掺伪样和掺伪样,掺伪含量差异越大,区分越明显。
典则判别函数直观描述了不同掺伪情况理化指标之间的关系,但不便于对未知掺伪水牛乳的客观判断,为此,建立Fisher线性判别函数对未知样品的掺伪情况进行判别。将全部训练集的乳样品理化指标数据进行Fisher判别分析初探,发现掺入0.02%尿素、0.1%尿素、0.5%尿素、10%水+0.1%尿素的掺假乳有较多的误判情况,说明此方法不能很好的判别低于这些掺假量的水牛乳,故去除这四种掺伪奶样品后用剩下的水牛乳样品重新建立判别模型,以进入模型的6个理化指标为基础,建立4个Fisher线性判别函数,分别描述未掺假乳、单一掺水乳、单一掺尿素乳和掺水和尿素乳的特征。各个Fisher线性判别函数的系数见表1。
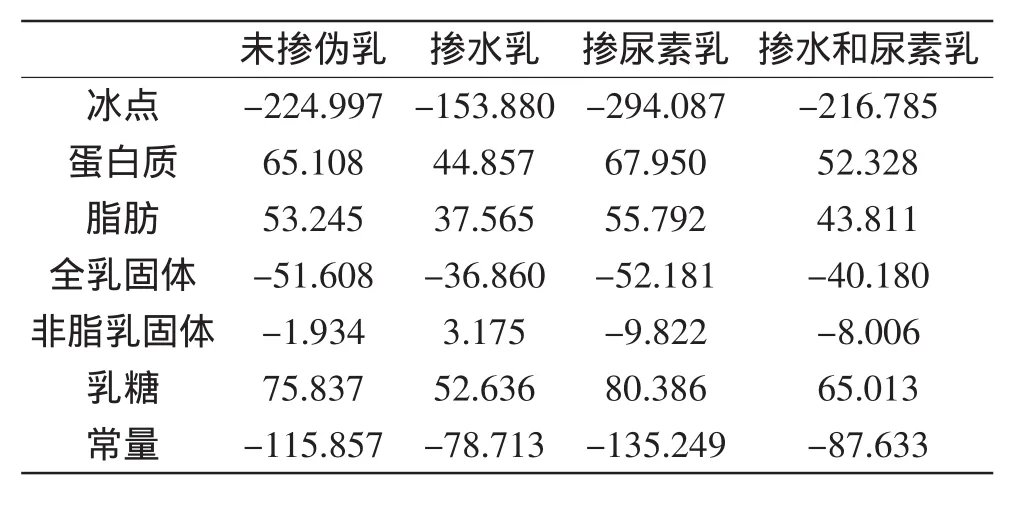
表1 水牛乳掺伪样Fisher线性判别函数系数Table 1 Coefficients of Fisher’s 1inear discriminant functions of buffalo milk adulterants
将任意一个样品的6个理化指标测定数值分别代入4个Fisher线性判别函数,计算得到6个函数值,数值最大者代表该样品属于相应类别,将掺假乳训练集数据回代到4个线性判别函数进行判别结果检验,见表2。最后判别分析结果未掺伪乳和掺水乳样品分别出现2个和6个被误判,掺尿素乳、掺水和尿素的混掺乳样品全部被正确判别,4组掺伪样的判别正确率分别达到93.75%、95.31%、100%、100%,说明建立的判别模型是可靠的,能够用于水牛乳的定性鉴伪。
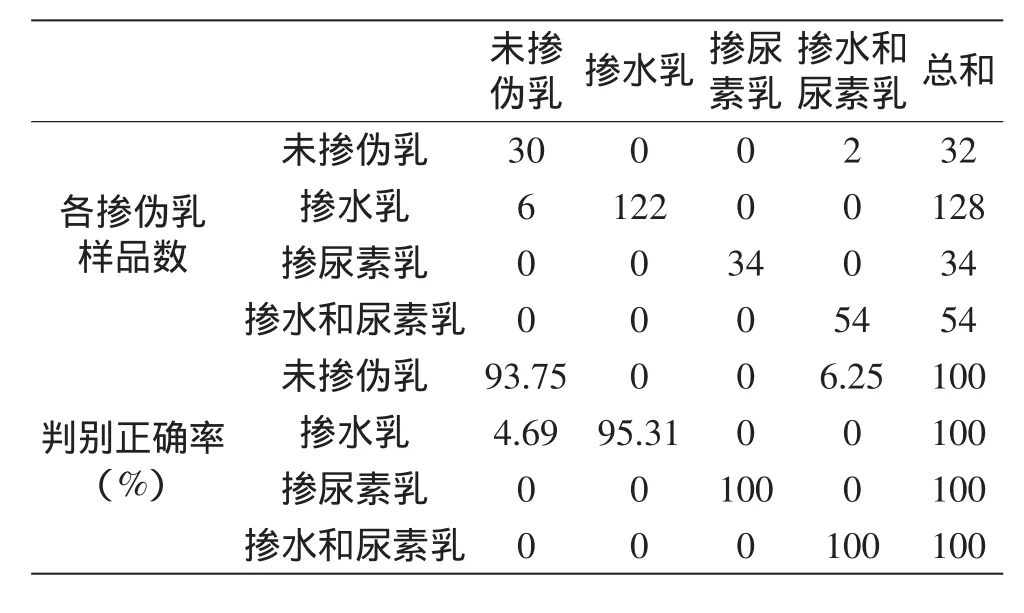
表2 Fisher线性判别函数对原始数据的判别结果Table 2 Coefficients results of original data by Fisher’s 1inear discriminant functions
为了检验构建的判别分析模型的可靠性,将未参与建模的48个不同掺伪情况的样本代入上述4个方程进行预测验证,判别分析结果见表3。从表3可知,48个未参加建模的水牛乳样,未掺假乳类、掺尿素乳类、掺水和尿素乳类全部判别准确,掺水乳类有一个被误判,判别效果良好,可认为这些变量的选择适用于水牛乳掺伪,验证了Fisher线性判别分析应用于掺假水牛乳的鉴伪是成功的。
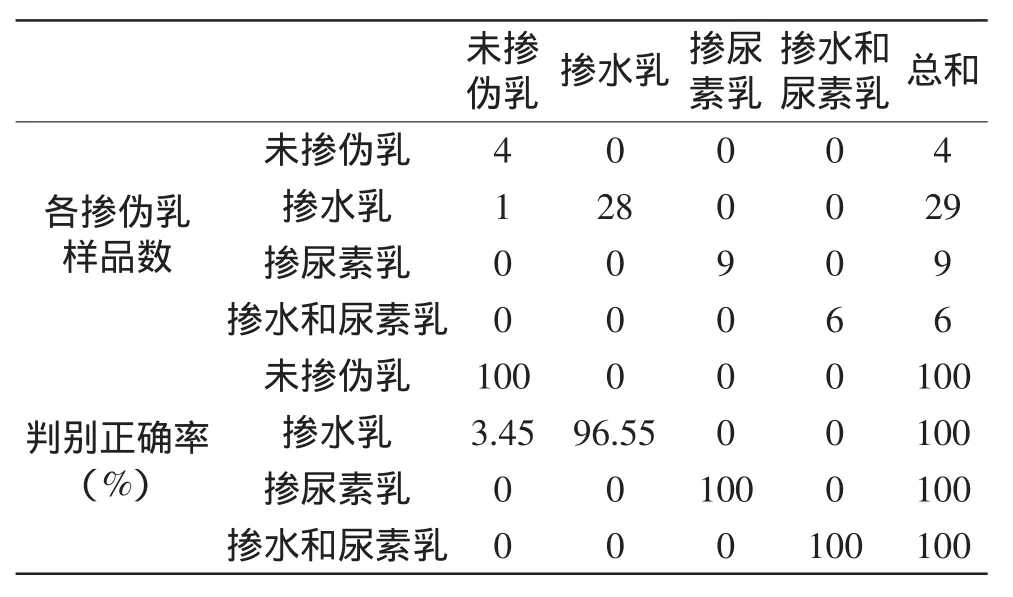
表3 Fisher线性判别函数对验证集数据的判别结果Table 3 Coefficients results of validation sets data by Fisher’s 1inear discriminant functions
2.2多元逐步线性回归建立水牛乳单一掺水和掺尿素的定量预测模型
2.2.1水牛乳中掺水和尿素定量鉴别模型的建立采用多元逐步线性回归建立水牛乳单一掺水和掺尿素的定量预测模型,将16个纯水牛奶样、48个掺杂不同体积比水含量(5%、10%、15%、20%、25%、30%)的掺水乳、40个掺杂不同质量比尿素含量(0.02%、0.1%、0.5%、1%、2%)的掺尿素乳样品作为训练集。以掺混量作为因变量,7个理化指标的数据作为自变量,采用IBM SPSS 20.0对这些变量进行多元逐步线性回归拟合,得到的逐步线性回归方程见表4。所建立定量模型中,R2均达到0.98以上,p小于0.0001,说明所建模型的稳定性和拟合效果较好。
2.2.2水牛乳掺水和尿素定量模型的可行性检验随机选择3个纯水牛乳样、25个不同体积比的掺水乳和13个不同质量比的掺尿素乳样品作为验证集,对建立的定量模型方程进行预测能力检验,采用外部验证方法对所建模型的实际预测效果进行评价。

表4 水牛乳掺假的多元逐步线性回归分析Table 4 Summary of stepwise regression analysis of adulterated-buffalo milk
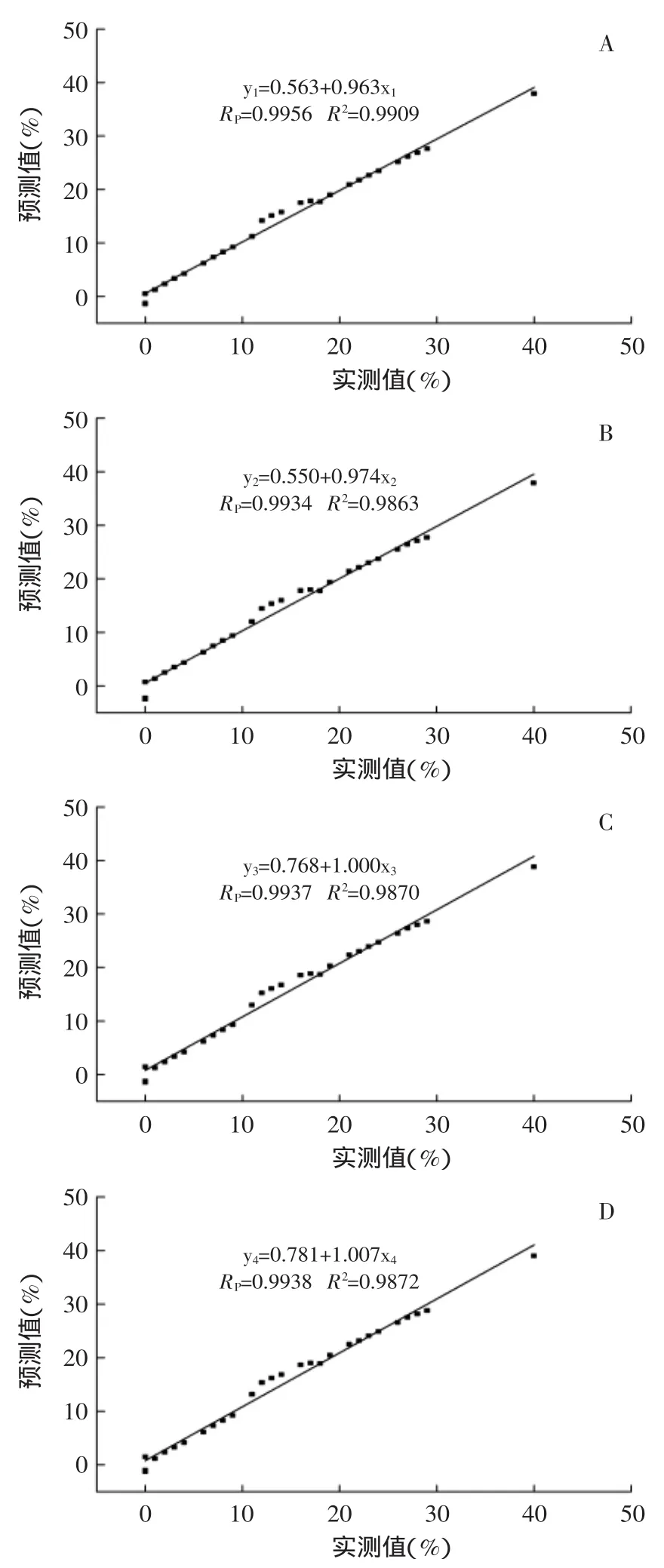
图3 水牛乳掺水验证集样本预测值和实测值之间关系Fig.3 Relation between true concentration and predicted concentration of water in buffalo milk of validation set
图3和图4分别是采用模型对独立的不同水和尿素含量验证集样品实测值(x)和模型预测值函数(y)间关系的线性拟合,6个方程的相关系数RP均大于0.99,R2均大于0.98,说明利用多元逐步线性回归法建立的水牛乳单一掺水和掺尿素定量预测模型可以满足定量分析要求,具有一定的有效性。

图4 水牛乳掺尿素验证集样本预测值和实测值之间关系Fig.4 Relation between true concentration and predicted concentration of urea in buffalo milk of validation set
3 结论
3.1聚类分析法能够较好地区分未掺假乳和掺假乳,可以用于一定差异水牛乳掺假样的区分,但对差异较小的掺假样分辨能力存在一定的局限。
3.2Fisher判别分析中典则判别函数得分散点图能够直观地区分未掺伪样和掺伪样,且掺伪含量差异越大,分区越明显;Fisher线性判别函数能够对未知掺伪乳样品进行判别,对未掺伪乳、掺水乳、0.5%以上掺尿素乳、掺水和尿素乳的判别正确率很高,判别效果良好。
3.3多元逐步线性回归法构建的水牛乳单一掺水和单一掺尿素定量模型可以用于掺杂含量的预测。其中单一掺水乳4个定量模型、单一掺尿素乳2个定量模型实测值和预测值的相关系数Rp分别为0.9956、0.9934、0.9937、0.9938、0.9986、0.9991,模型预测值于真实值很接近,可满足检测需求。
[1]韦升菊,梁贤威,卢雪芬,等.水牛奶和乳牛奶常规乳成分及乳脂脂肪酸组成的初步比较研究[J].畜牧与兽医,2011,43(10):41-43.
[2]林芳栋,蒋珍菊,曹蕊.牛奶掺假掺杂现状及检测方法的研究进展[J].西华大学学报:自然科学版,2011,30(3):94-96.
[3]ADAM AAH.Milk Adulteration by Adding Water and Starch at Khartoum State[J].Pakistan Journal of Nutrition,2009,8(4):439-400.
[4]李靖,贺俊英,王慧,等.原料乳中尿素掺假检测方法的研究[J].中国食品工业,2013(4):58.
[5]曹殿洁,黄信龙,冯学花,等.原料乳掺假物质及其快速检测技术[J].广州化工,2012,40(15):132-133,141.
[6]范佳利,韩剑众,田师一,等.基于电子舌的掺假牛乳的快速检测[J].中国食品学报,2011,11(2):202-208.
[7]张鑫,顾欣,倪力军,等.基于近红外光谱技术的掺假生鲜乳识别平台的研发[J].中国奶牛,2012,(13):53-57.
[8]杨仁杰,刘蓉,徐可欣,等.二维相关光谱结合偏最小二乘法测定牛奶中的掺杂尿素[J].农业工程学报,2012,28(6):259-261.
[9]杨仁杰,刘蓉,徐可欣,等.基于中红外光谱检测牛奶中掺杂的尿素[J].光谱学与光谱分析,2011,31(9):2383-2385.
[10]姜潮,韩剑众,范佳利,等.低场核磁共振结合主成分分析法快速检测掺假牛乳[J].农业工程学报,2010,26(9):340-344.
[11]MABROOK MF,PETTY MC.A novel technique for the detection of added water to full fat milk using single frequency admittance measurements[J].Sensors and Actuators B,2004,96:215-218.
[12]何彬.基于红外光谱技术的牛奶掺杂判别方法的研究[D].天津:天津大学,2010.
[13]陈燕清.化学计量学在食品分类鉴别及防腐剂含量分析中的应用[D].南昌:南昌大学,2010。
[14]张成飞.植物油模式识别与掺混量检测方法的研究[D].长春:吉林大学,2009.
[15]李亮,丁武.掺有植物性填充物牛奶的近红外光谱判别分析[J].光谱学与光谱分析,2010,30(5):1238-1242.
Study on authentic identification of water and urea in buffalo milk based on chemo metrics methods
HUANG Li,LIN Bo,LI Ling,ZENG Qing-kun*,TANG Yan,YANG Pan,FENG Ling,NONG Hao-ru
(Guangxi Buffalo Research Institute,Chinese Academy of Agricultural Sciences,Nanning 530001,China)
The qualitative identification and quantitative prediction model of buffalo milk adulterated with water and urea were established by seven main quality indicators of the buffalo milk combined with chemo metrics methods.The cluster analysis was well able to distinguish pure and adulterated buffalo milk samples.Canonical discriminant function coefficients could intuitively distinguish mixed samples adulterated with different contents of adulteration,and coefficients of Fisher’s linear discriminant functions worked well for qualitative identification of unknown buffalo milk adulteration.Multiple linear step regression method built six quantitative models,which the correlation coefficients RPof real value and predicted value were 0.9956,0.9934,0.9937,0.9938,0.9986,0.9991,respectively,and could quantitative identification of authentic buffalo milk.
buffalo milk;adulteration;physical and chemical indicators;chemo metrics methods
TS252.7
A
1002-0306(2015)16-0053-05
10.13386/j.issn1002-0306.2015.16.002
2014-11-18
黄丽(1986-),女,硕士研究生,研究实习员,研究方向:乳品科学,E-mail:huangli00206@163.com。
曾庆坤(1968-),男,硕士研究生,研究员,研究方向:食品科学与技术,E-mail:zqk456@163.com。
“十二五”农村领域国家科技计划课题(2013BAD18B12-03);广西科技攻关计划项目(桂科攻12118011-2A);2014年广西水牛研究所基本科研业务费项目(水牛基1404005)。
