一种快速的Web用户和URL聚类算法
2015-07-21张线媚
张线媚

摘 要:本文提出一个基于Web日志的用户和URL聚类的快速算法。利用用户浏览行为建立用户事务矩阵,在此基础上综合考虑用户浏览时间以及点击频率来获取用户权值和页面权值,构建带权值的模糊聚类。为了缩小运算量,构造等价事务,进行事务约减;并针对于FCM算法簇数目初始化敏感的问题,提出了一种全局搜索的方法,搜寻最优的类中心数。实验证实,该算法在精度和效率上都获得了大大提高。
关键字:权值距离;等价事务;事务约减;全局搜索
中图分类号: TP274.2 文献标识码:A 文章编号1672-3791(2015)06(a)-0000-00
因为网站的内容及结构的组织形式是否合理直接决定了网站是否受欢迎,所以需要对Web访问信息进行有效的聚类,分析挖掘出合理有效的运行模式和隐含信息等知识,而在Web访问信息的聚类过程中,最常用到的方法是页面聚类和用户聚类。页面聚类方法主要是通过分析页面之间的关联知识来改进站点的组织结构,而用户聚类则是以相似访问喜好的用户作为集合进行聚类,为同一集合的用户提供针对性的服务。因此聚类算法研究在Web访问信息挖掘中起到决定性的作用。
目前多数日志聚类以Web站点的URL为行、以User-ID为列,建立关联矩阵,对用户的访问时间进行离散后用作矩阵的元素值,经过User-ID的相似性分析,得到相似客户群体,经过对URL的相似性度量获得相关Web页面。
本文首先清洗日志数据,然后根据用户的浏览行为建立矩阵,通过对矩阵的列向量和行向量进行模糊聚类,从而得到用户聚类和URL聚类。为了提高聚类算法的精度和整体效率,在确定初始中心时采用了全局搜索方法。
1.日志的清洗
1.1 用户事务集合
WEB服务器日志包括访问日志、引用日志和代理日志,数据清洗主要完成错误和冗余数据的剔除和重复数据的合并操作,用来表示日志信息,利用最大时间间隔法来得到用户事务集合。结合用户在页面上的停留时间及其点击次数,总结用表示用户事务集合,对于, 有:。其中: ,m表示站点的URL数,表示到截止到当前时间用户在上的浏览时间,表示点击次数。
1.2浏览时间的离散化
将用户事务在站点URL上的浏览时间属性用间隔(即离散值)表示,将时间离散化。离散值和实际时间的关系如表1所示:
表1 离散值与浏览时间对照表
在进行离散化时,当用户在URL上的停留时间少于5s时,则离散值取0,表示URL是导航页而不是内容页,应该删除。考虑主页访问的普遍性,所以对主页的研究意义不大,也应该删除,即使用户对网页的浏览时间很长,离散值也只有3。这样可有效判别区分在用户事务的相似性,当用户浏览时间过长或过短时,如果采用连续时间则会造成聚类结果畸变。
1.3用户浏览矩阵和用户点击矩阵
(1)用户浏览矩阵:
其中:代表Web站点URL的个数,代表用户事务数,代表第个用户事务对第个URL 的访问时间总和。
(2)用户点击矩阵:
其中:为Web站点URL的个数,为用户事务数,为第个用户事务对第个URL 的点击次数总和。
用户浏览矩阵中用户对该站点中所有URL的访问情况可表示为,即列向量;所有用户对URL“”的访问情况表示为,即行向量。分别度量二者的相似性,就能得到用户聚类和URL聚类。
2.聚类算法
2.1 模糊聚类
在数学上模糊聚类可用如下的目标函数求极值来表示:
(1)
(2)
综合考虑(1)式的优化和(2)式的约束条件,用拉格朗日乘数法可求得到和分别为:
(3) (4)
对(1)式优化采用FCM算法:
a.取常数,令迭代次数t=0,任选聚类中心;
b.对按式(3)求得;
c.由式(4)算出下一次类别中心;
d.如果,退出迭代;否则,令t的值加1,跳至步骤b;
数据点的分类在每次迭代中同时进行调整,而且聚类中心需要更新。当先后两次迭代隶属度矩阵很接近,则算法处于收敛。在得到用户浏览矩阵以后,分别对行向量和列向量进行聚类,得到相似的用户簇和URL簇。
2.2 带属性权重的欧氏距离
如果采用传统的欧氏距离,度量列向量和的距离公式为: (5)
度量行向量和的距离公式为:
(6)
由于传统的距离公式忽略权重,故提出带权重的欧氏距离公式:
(7)
其中:表示第k维数据的重要性。
由此可以求得带权重的模糊聚类算法目标函数为:
在URL聚类和用户聚类中,分别代表第k个用户的权重和第k个URL的权重。
2.3页面权重
用户具体的浏览行为体现在用户对页面的点击次数和停留时间,采用极值法对点击次数进行归一化处理,则对应的点击权重值为:
(8)
其中:为单页面点击的最大次数,为单页面点击的最小次数。
同理可得到对应的浏览时间权重值:
(9)
其中:为单页面浏览的最长时间,为单页面浏览的最短时间。
结合用户的浏览时间权重和点击权重,构建URL权重计算的线形公式:
(10)
其中:
(11)
(12)
2.4用户权重
同理对于用户访问频率和访问时间,采用权重概念可得到用户权重的计算公式:
(13)
其中:
(14)
(15)
为归一化的点击次数权重,反映了各个用户总的点击次数情况;为归一化的浏览时间权重,反映了各个用户总的浏览时间情况。
3.聚类中心的选取
模糊聚类算法中,目标聚类数目K要提前设定,由于算法的迭代都要求沿着使J减小的方向进行,而J可能有多个极值点。当确定的初始聚类中心靠近一个局部极小点时,则算法收敛到局部最小。为了解决这个问题,在聚类中可以使用全局优化方法中的模拟退火技术,但是这样就增加了计算量,而且收敛速度也会相应减慢,所以实际应用中不常使用。
本文在确定类别数目时采用了全局搜索的方法,即取数据空间中的多个数值进行初始化,则初始中心可分布在较广的范围,而且满足了数据的多样性。在聚类过程中利用有效性度量函数逐步减少聚类数目K的值,直到有效性函数的变化趋向于某个阈值停止。
3.1取样
在初始化时为了减少计算量,对原始数据集合进行取样。采用随机取样,选取能基本代表原始数据特性的数据作为训练集,在训练集中求得初始化中心点,从而可以快速地找到最优的簇数目。
3.2等价事务和事务约减
当两个访问事务的浏览时间以和点击次数相等或相近时,则它们对C个类中心的隶属度也是相同或相近的。
(1)等价事务:
当随机的两个事务对应的与,满足,,其中为事前选定的任意小整数。而且,它们所对应的和,满足:,,其中为事先设定的任意小整数。则它们为一对等价事务。
(2)事务约减:
有了等价事务的概念,原浏览矩阵和点击矩阵可以看成多个子集的并集
,其中:
因为等价事务对各中心的隶属度相同,即:,所以可以利用子集中任意一个事务来代表整个子集,即对访问矩阵和点击矩阵进行约减。
3.3全局搜索
为了避免FCM算法中事先确定聚类数目带来的难题,引入Xie-Beni聚类有效性度量: (16)
可以设定一个较大,(为约减后的事务数目)。确保在最小化Xie-Beni聚类有效性度量的情况下,使得设定的目标函数最优,从而得到的簇数目为最优值。
过程执行步骤如下:
(1)对原始数据集进行取样,进行数据约减,得到
(2)对簇数目进行初始化
(3)任选k个对象为最初的簇中心集合
(4)计算对象的隶属度矩阵
(5)由隶属度矩阵得到新的簇中心集合
(6)重复隶属度和簇中心的计算过程,当目标函数处于收敛时结束。
(7)迭代XB函数,令,阈值为,当时停止迭代,最后得到簇数目k;否则继续,令k=k-1,跳转至(4)
因为最优簇数目是从训练集求得中,故计算量大为减少。全局的聚类和迭带是在全局搜索求得最优化簇数目后进行的,而且求解的结果在训练集中,所以聚类的效率大为提高。
4.算法仿真及分析
仿真数据来自站点的日志数据,下载URL为598的WWW服务器日志文件,选取40000条记录,对日志进行清洗,最终得到1034个用户事务。算法的性能分析从算法的有效性和效率两方面进行比较。
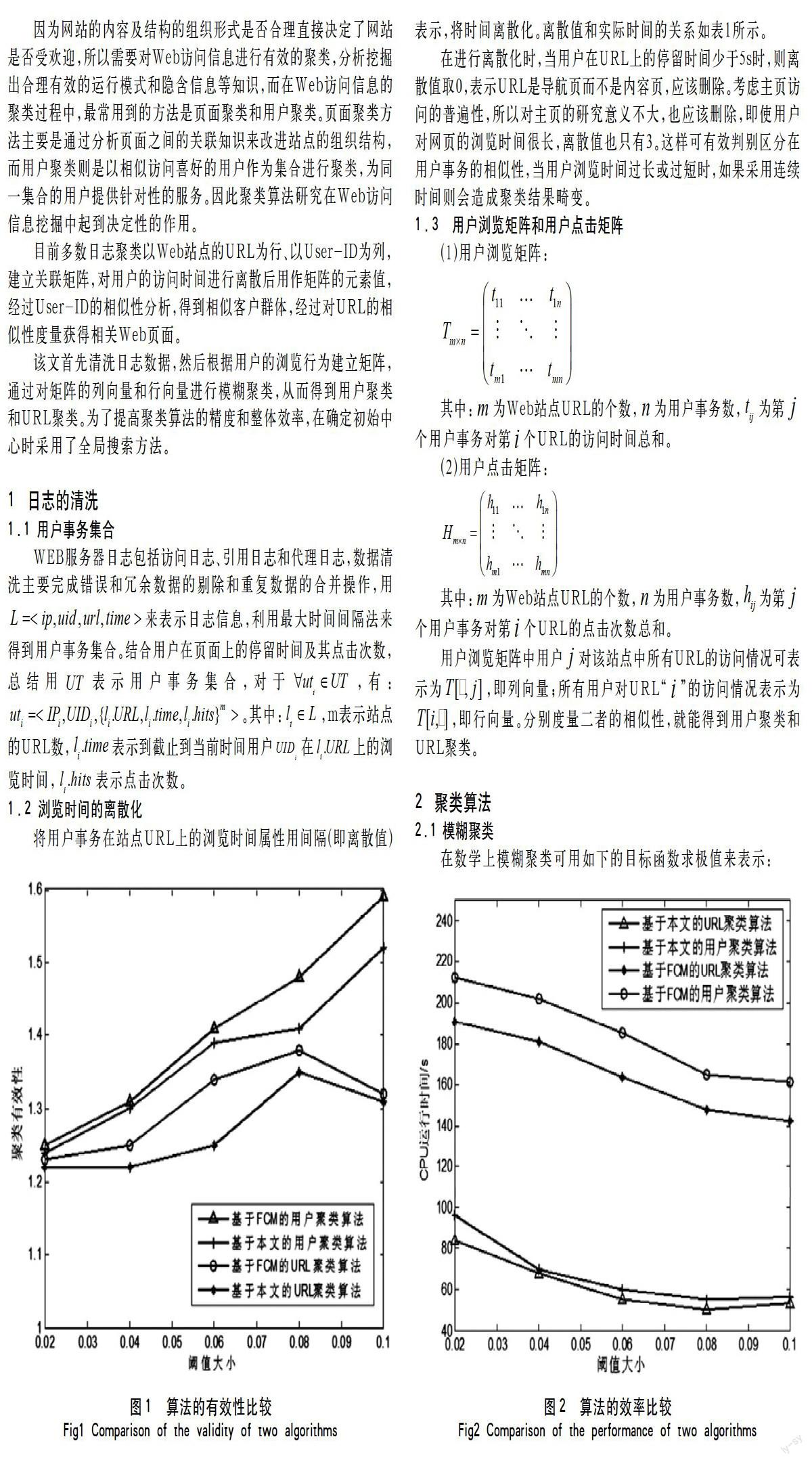
(1)算法的有效性:与传统的FCM算法比较,适当地调整聚类阈值,得到图1。
图1 算法的有效性比较
Fig1.Comparison of the validity of two algorithms
通过图1中的对比,可以看到本文的算法在用户聚类和URL聚类上,有效性都是高于FCM算法。
(2)算法的效率比较:仿真得到如图2结果。
图2 算法的效率比较
Fig2.Comparison of the performance of two algorithms
算法的效率主要通过CPU运行的时间来衡量,从图2的显示结果我们看到本文的算法在进行用户聚类和URL聚类时,CPU运行时间比FCM算法要小得多,即本文算法在效率上远胜于FCM算法。
5.结语
本文在对用户浏览时间做了离散处理后提出了一个基于用户离散化时间、以用户浏览次数为度量的新的聚类算法,可以进行Web用户和URL的聚类。新算法在传统FCM算法基础上,利用访问时间和频率确定用户和URL权值,构建了带权值的模糊聚类。另外,通过事务约减和全局搜索的方法来确定最优的初始簇中心。与已有的FCM算法对比,仿真结果表明,新算法在有效性和效率上都有很大提升。
参考文献:
[1]宋春江,沈钧毅.一种新的Web用户群体和URL聚类算法的研究[J].控制与决策.2007,22(3).
[2]田生文,黄明明.密集簇中心二次模糊聚类算法[J].计算机工程与设计.2007,28(2).
[3]Jiawei Han, Micheline Kambr.数据挖掘概念与技术[M].北京机械工业出版社,2002.223-224.
[4]Xie X,Beni G.A validity measure for fuzzy clustering[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1991,13(8):841一847.
[5]刘小览,赵英凯,陆金桂.数据挖掘中Fuzzy C-means的自适应聚类算法[J].南京化工大学学报(自然科学版),2001,23 (5).
