基于DHMM的语音识别算法及DSP实现
2015-06-13陈兵,尹曼
陈 兵,尹 曼
(中国电子科技集团公司第五十四研究所,河北石家庄050081)
0 引言
语音识别技术是信息技术领域的重要发展方向,非特定人孤立词识别是其一个具有广泛应用背景的分支,在工业控制、智能对话查询系统、语音拨号系统、智能家电、声控点歌系统及声控智能玩具等领域有着重要的应用价值。目前语音识别算法主要分为针对特定人的语音识别算法,如动态时间规划(DTW)技术[1,2]和线性预测编码(LPC)分析技术[3,4]等;针对非特定人的语音识别算法,如人工神经网络(ANN)[5]和隐形马尔科夫模型(HMM)[6]等算法。但这些算法存在针对特定人或运算复杂及不利于实时处理等问题。
针对以上问题,提出了一种基于离散隐形马尔科夫模型的快速语音识别算法,通过仿真验证了算法对非特定人的孤立词语音识别具有高识别正确率,并通过算法的DSP实现说明了识别算法具有良好的处理时效性。
算法首先对语音信号进行预处理和端点检测以提取有用信号,进而完成语音特征参数提取和矢量量化,最后采用DHMM模型利用Viterbi搜索算法实现语音识别,在训练阶段完成码本设计和DHMM模型参数的生成。该算法抗噪性能好,识别率高,具用实时处理能力和广泛应用前景。
1 语音识别算法
语音识别算法典型的实现流程如图1所示。输入语音信号首先要进行预处理和端点检测,包括预加重、分帧和截取有用语音信息等。有用信号经过特征提取和矢量量化后,实现特征参数提取和对特征参数的矢量量化,将一个特征矢量变成标量。矢量量化后的特征标量送入语音识别模块,运用DHMM模型采用相应识别算法完成语音识别,得到识别结果。在语音训练阶段,需要采用相应算法完成对用于量化的码本和用于识别的DHMM模型参数进行训练。

图1 语音识别算法流程
2 算法原理
2.1 预处理
由于语音信号是一种典型的非平稳信号,但它具有短时平稳性,一般认为在10~30 ms短时间内是平稳的[7]。因此需要对语音信号进行分帧处理,以利于采用平稳信号的数字处理算法。为了消除直流成分和50 Hz的工频干扰,弥补高频部分语音信号在传输中的衰减,需要对信号进行预加重滤波,预加重滤波器的传输函数为1-0.9735z-1。本文采样频率设计为8 kHz,每帧数据长度为256点,每帧数据步进为80点。
2.2 端点检测
语音端点检测主要是提取能够区分语音和噪声的语音特征参数,找出二者的分界点,从而实现有用语音信息的检测。语音信号最基本组成单位是音素,音素分为浊音和清音2类。在实际语音中,浊音幅度较大,可通过短时能量来检测,清音幅度很小,接近噪声,但其过零率远大于噪声[5],因此采用短时能量和短时过零率联合检测语音端点。短时能量En和短时过零率ZCR的表达式为:
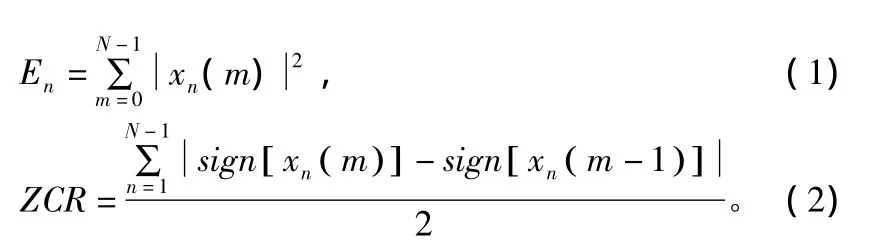
式中,xn(m)为预处理后的语音信号帧;N为每帧数据长度;sign是符号函数。图2是对“山东”2个字的端点检测仿真图。

图2 端点检测仿真
2.3 特征提取
特征提取是通过运算获得最能反映语音本质特征的参数,它是整个语音识别的基础,直接影响到语音识别结果。目前,语音特征提取的方法很多[8-10],本算法采用 Mel频标倒谱系数(MFCC)分析方法,由于其模拟了人对音调感知度近似正比于该音调频率对数的听觉特征,因此MFCC参数具有抗噪能力强和识别率高等特点。
Mel频率与线性频率的转换公式为:
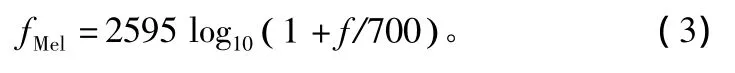
同时,人们并不能有效分辨所有频率分量,只有当2个频率分量相差一定带宽时,才能将其区分,这个带宽称为临界带宽[11]。
根据以上分析,可构造临界频带滤波器组来模拟人耳的感知特性。这组滤波器的中心频率在Mel频率域内呈线性分布,其带宽在临界带宽之内。在8 kHz采样率下,每帧数据N为256时设计的临界频带滤波器组Hm(n),临界滤波器数目M为24,采用汉明窗,临界频带滤波器幅频响应如图3所示。

图3 临界频带滤波器幅频响应
MFCC的参数计算流程如下:
①对每帧数据加汉明窗,进行离散FFT运算,取模平方得到离散功率谱 ()S n;
②计算 ()S n与Hm(n)在各离散频率点上乘积之和,得到M个参数Pm;
③计算Pm的自然对数,得到Lm;
④ 对Lm计算其离散余弦变换(DCT),得到Dm,消除Lm之间的相关性,舍去直流分量的D0,选择 D1,D2,…DK,K=12。
⑤对Dm加倒谱提升窗,即对K个系数分别乘以不同的系数wm,wm的表达式为:

⑥计算差分倒谱参数,得到语音参数的动态特征。差分参数计算公式为:
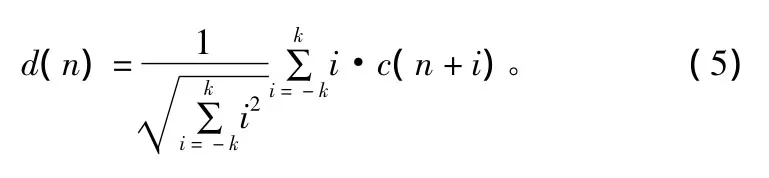
式中,c(n)为一帧静态参数;d(n)为差分参数;k为差分阶数。本算法选取k为2,将MFCC参数和由式(5)得到的差分参数合并,形成一个24阶矢量,作为一帧语音信号的参数。
从上可知,通过特征提取将每一帧256点的数据压缩为24点数据,有效减少了后续运算量。
2.4 矢量量化
矢量量化(Vector Quantization)是将数值连续的矢量信号用离散数字值(称为标号)来表示的过程。它是采用离散隐形马尔科夫模型进行语音识别前所必需的步骤,也有利于减少运算负荷,提高算法处理的实时性。矢量量化的关键技术包括码本设计和搜索策略两方面。
码本是指矢量量化编码器拥有的具有代表意义的矢量集合,码本中矢量称为码字,矢量量化的过程就是将输入矢量与码本对照,寻找与输入矢量最接近的码字,用码字的标号代替输入矢量,因此码本设计的好坏直接关系到量化的质量。
LBG算法是码本生成时最常采用的方法。LBG算法需要预先设置畸变改进阈值δ和最大迭代次数L,δ<<1,以保证最后码本收敛;阈值L保证算法在有限次数内结束,防止发生振荡而不能收敛的情况。同时算法中的初始码字的选择需要考虑,一般可采用分裂法。
码本容量是码本设计中另一个值得注意的问题。码本容量过小,无法描述整个矢量空间;码本容量太大,则存储量和搜索所需计算量过大。实验结果表明,码本容量>64时,码本容量对识别正确率的提高就不明显了,因此,本文码本容量为128。
码本搜索是指如何搜索出与输入矢量最接近的码字的过程。考虑到码本的容量和DSP的运算处理优势,本文采用全搜索算法,比较所有码字和输入矢量的欧式距离,找出距离最小的码字。
因此,通过矢量量化以后,语音数据被进一步压缩,有原来每一帧24点数据压缩为1个数据(即码字的标号),使后面的运算由矢量运算变为标量运算。
2.5 训练与识别
2.5.1 HMM 模型
马尔可夫链是指在时刻t只能处于有限状态θl(l=1,2,…,N)中的一个,用 qt表示,且状态 qt为 θl中的哪一个的概率只取决于前一时刻所处的状态qt-1。因此马尔可夫链在任意时刻为何状态的概率完全取决于初始状态概率矢量π和状态转移概率矩阵A。
若系统在任何时刻t所处的状态qt隐藏在系统内部,外界只能得到此时系统提供的一个随机矢量ot,ot称为观测矢量。ot取何值的概率与时间t无关,只和系统的状态有关,可用输出概率矩阵B来表示,则此系统被称为隐含马尔可夫(HMM)模型。从定义可知,HMM模型可以由3项特征参数π,A,B来表示。
HMM模型可以分为离散HMM(DHMM)和连续HMM模型(CDHMM)。当训练数据充分且训练足够时,CDHMM的效果优于DHMM,但很多情况下,充分训练是比较难达到。考虑到运算量、存储量和实时性等要求,本文选择DHMM作为语音识别的模型。
HMM模型是一个双层随机模型,内部不可见的马尔可夫状态链用以表示语音中相对稳定的短时特性,外部可见的观测序列表示语音中可观测的各种特征矢量,两者用概率联系。这样就将语音信号多变的外部特征和内在的本质特征有机的联系起来。
2.5.2 HMM 模型训练
语音信号通过预处理、端点检测、特征提取和矢量量化后,生成一组码本标号序列。HMM模型训练过程就是根据这些标号序列来确定HMM的3项特征参数,而使系统生成此标号序列的概率最大。本文采用一种基于随机松弛算法[12](Stochastic Relaxation,SR算法)的DHMM参数全局优化算法。该算法以相对较少的计算开销,避免了经典的Baum-Welch算法易陷入局部最优解的问题,可提高识别系统的性能。SR算法进行DHMM模型训练过程如图4所示。

图4 SR算法DHMM模型训练过程
图4中初始温度设置T0=4/128(码本容量为128),降温速度K一般取0.97~0.99。DHMM初始模型参数有初始概率矩阵 π =[1,0,0,0,0];输出概率矩阵B均匀设置,bjk=1/128;转移概率矩阵A为:

还需设置最大迭代次数I及变量ξ作为是否完成收敛的判决条件,ξ的表达式为:

式中,Pm(O|λ)为第m次时在模型参数λ=(π,A,B)下输出变量为O的概率。本文ξ取为0.01;迭代次数I取为200。
2.5.3 语音识别
通过语音训练,为每个孤立词建立DHMM模型。在本文中,语音识别过程是将输入的语音信号与每个DHMM模型进行Viterbi运算,得到每个的输出概率,并通过比较找到最大概率对应的模型,进而得到识别结果,语音识别流程如图5所示。

图5 Viterbi算法语音识别过程
3 仿真分析
3.1 语音识别性能仿真
仿真条件如下:采样频率fs=8 kHz,量化位数为16位,采用PCM编码,存储格式为wav格式。测试3个词:“广东”、“山东”、“贵州”。一共10个人参与录音,其中男生7人和女生3人,每个人每个词读8遍。
所有人每个词的前6遍参与了码本训练。有5个男生和2个女生的每个词的前6遍参与DHMM模型的训练。所有样本均参与识别仿真。语音识别的统计结果如表1所示。

表1 识别结果统计
由表1可知,本文算法可以完成非特定人孤立词的识别,识别正确达到97.5%,由此可见,算法能够满足大部分语音识别应用的要求。
3.2 DSP 实现仿真
测试条件设置同语音识别性能仿真,算法在ADI公司Blackfin系列BF533芯片上进行DSP实现,采用Visual DSP++4.5开发软件进行算法编程和功能仿真。DSP芯片主频为600 MHz。语音识别算法占用时间(不含语音数据采集和码本训练及DHMM模型训练占用时间)如表2所示。
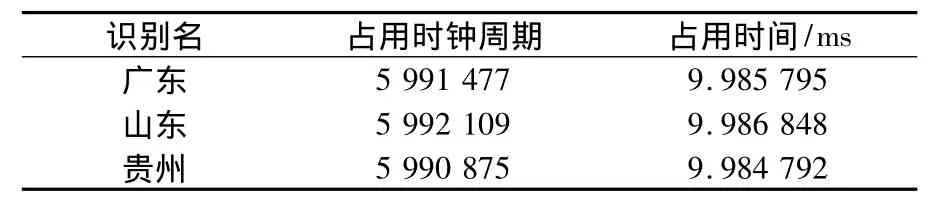
表2 识别算法占用时间
从表2可知,本文语音识别算法占用时钟周期最大为5 992 109个,占用时间为9.986 848 ms,运行时间优于10 ms,识别算法具有实时处理能力,满足实际工程应用。
4 结束语
提出了一种基于离散隐形马尔科夫模型的快速语音识别算法,详细阐述了对非特定人孤立词语音识别的算法原理和实现流程,进行了识别算法的有效性仿真,并采用DSP芯片完成识别算法硬件实现,验证了识别算法的处理实效性能。理论分析和仿真试验表明,本文算法具有抗噪性能好,识别率高和实时处理能力,在智能家电、智能汽车和人机交互等领域有广泛应用前景。
[1]TTAKURA F.Minimum Prediction Residual Principle Applied to Speech Recognition[J].IEEE Trans.ASSP,1975,23(1):67 -72.
[2]刘 静,王 儒,曲金玉,等.基于DTW改进算法的孤立词语音识别仿真[J].山东理工大学学报(自然科学版),2013,27(1):63 -66.
[3]MAKHOUL J.Linear Prediction:a Tutorial Review[J].Proceedings of the IEEE,1975(63):561 -581.
[4]张玲华,郑宝玉,杨 震.基于LPC分析的语音特征参数研究及其在说话人识别中的应用[J].南京邮电学院学报,2005,27(6):1 -6.
[5]王建雄,刘应龙.基于人工神经网络的数字识别系统的研究[J].计算机技术与发展,2006,16(15):26-30.
[6]WILPON J G,LEE C H,RABINER L R.Application of Hidden Markov Models for Recognition of a Limited Set of Words in Unconstrained Speech[C]∥ ICASSP,1989:24-30.
[7]韩纪庆,张 磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2004.
[8]DAVIS S B,MERMELSTEIN P.Comparison of Parametric Representations for Monosyllabic Word Recognition in Continuously Spoken Sentences[J].IEEE Trans.On Acoustics,Speech,and SignalProcessing,1980,28(4):357-366.
[9]HUNT M J,LEFEBVRE C.A Comparison of Several Acoustic Representations for Speech Recognition with Degraded and Undegraded Speech[C]∥Proceedings of ICASSP,1989:262 -265.
[10]FAVERO R F,KING R W.Wavelet Parameterization for Speech Recognition:Variations in Translation and Scale Parameters[C]∥ Proc.International Symposium on Speech.Image Processing and Neural Networks,Hong Kong,1994:694 -697.
[11]杨行峻,迟惠生.语音信号数字处理[M].北京:电子出版社,1995.
[12]方绍武,戴蓓倩,李宵寒.一种离散隐Markov模型参数的全局优化算法[J].电路与系统学报,2000,5(3):78-81.
