Web科技新闻分类抽取算法
2015-03-06朱全银刘文儒张永军刘金岭
朱全银,潘 禄,刘文儒,李 翔,张永军,刘金岭
(淮阴工学院 计算机与软件工程学院,江苏 淮安 223005)
Web科技新闻分类抽取算法
朱全银,潘 禄,刘文儒,李 翔,张永军,刘金岭
(淮阴工学院 计算机与软件工程学院,江苏 淮安 223005)
为了改善从Web上获取的新闻信息的使用价值,针对Web网站存在大量非科技相关新闻的现状,以互联网上政府新闻网站、凤凰网等新闻为研究背景,选取TF-IDF文本加权方法,设计了科技新闻多层次二分类模型,实现了基于TF-IDF的科技新闻文本分类抽取系统,在20万新闻文档和4000多种分类上,实验取得了科技新闻85.3%的识别准确率和非科技新闻82.9%的识别率,为Web科技新闻分类抽取提供有实用价值的参考模型。
科技新闻;文本分类;TF-IDF; 抽取算法
0 引言
国外文本信息的分类和知识发现起步较早,尤其是英语系国家,最早研究文本分类是在20世纪50年代末。美国IBM公司的研究人员H.P.Luhn最早在文本自动分类领域开启研究,1960年左右,Kuhn和Maron在ACM上提出了有关基于关键词的文本分类技术,随后许多著名的情报学家如H.Borko、Sparck等人在这一领域进行了广泛而深入的研究。文本预处理是对文本内容进行固定的格式分析,包含分词、词性标注、人名识别、地名识别、停用词处理等[1]。2005年,Gupta研究了利用粗糙集方法对信息特征进行选择[2],实验结果显示其取得了较好的特征选择效果。目前,比较成熟的特征词权重计算方法有布尔权重法、TF-IDF权重法、对数权重法和平方根权重法[3],其中TF-IDF权重法是应用比较广泛的方法。
本文在以往的基于Web信息提取的基础上[4-12],以政府网站、凤凰网等新闻页面为新闻抽取目标,研究基于Web数据挖掘的科技新闻抽取算法,并对抽取的新闻进行分类研究。为了提高分类的准确性与有效性,还研究了新闻分类的增量训练方法。
1 文本分类方法
1.1 特征降维
向量空间模型VSM采用词袋模型表示文本,是目前文本分类中广泛使用的文本表示形式[13],其基本思想是将文本向量化为多维空间中的一个向量,向量的每一维是一个特征项与特征项权值。该方法表示文本间相似度一般采用余弦距离或欧式距离。在VSM模型中,TF-IDF (Term Frequency-Inverse Document Frequency) 是自动提取文本中的关键词的方法,该方法以“词-权重”为表示方法,是文本局部系数与全局系数的乘积。
(1)
式(1)是TF-IDF函数,TF是指词项对于某篇文章的重要性,即局部系数;IDF是指词项对于训练集的重要程度,能够区分不同类别,即全局系数。
1.2 文本聚类与分类
文本聚类是指事先不划分类别标记,文档的聚类过程分为文档相似度的计算和聚类分析两个方面[13]。
文档相似度计算有欧式距离和余弦相似度。即
(2)
式(2)是欧式距离公式,源于两点之间的距离公式,它将两篇文档看成n维坐标平面中的两个点,计算两点之间的距离差别。
(3)
式(3)是余弦相似度公式,文档是空间中的向量,计算空间中两个向量在方向上的差别。
具有代表性的聚类算法是K-means,通过不断迭代计算每个点的类别,算法简单却高效[14]。但其依赖于种子数,大多时候种子数是难以确定的,因此在K-means基础上发展了K-means++,解决了种子难以确定的问题。
无监督学习是从无任何标记的文本中学习类别,即需要聚类分析过程[15]。文本分类的方法大致可分为基于统计的分类方法与基于规则的分类方法两大类。基于统计的文本分类方法是研究的热点问题,代表性算法有:朴素贝叶斯、类中心向量、K近邻(K-NN)、最大熵模型、最小二乘拟合、支持向量机(SVM)和人工神经网络等[16-17]。常用的基于规则的分类方法有:决策树、粗糙集和关联规则[18]等。近年来,一些研究机构的学者在混合文本自动分类研究过程中也取得了不错的分类效果[19-20],这些算法在特定的领域内有其各自的优缺点。
2 科技新闻分类抽取算法
2.1 训练集文本预处理算法
文本预处理是文档分类的基础,本文研究过程中使用了目前的文本预处理算法,并针对科技新闻进行了算法优化。
以下是文本预处理与分类中用到的基本公式:
文本预处理局部系数SL,
(4)
文本预处理权重,
Vi=SLGj(Wi)=SLj(Wi)*SG(Wi)
(5)
文本预处理全局系数SLG
SLG={{W1,V1},…,{Wx,Vx},…,{W1,V1},…,{Wy,Vy}}
(6)
具体的算法主要步骤如下:
步骤1,设置全局参数,包括词频统计集DF、词-出现文档数表DWF、局部参数SL、全局参数SG、权重SLG;
步骤2,从训练文本集中取第i个文本Di;
步骤3,根据分词词典,对文档Di进行机械分词,生成文本分词集DW={Wn1, Wn2, …, Wns};
步骤4,根据停用词库SW,对文本分词结果集DW进行停用词处理DWS = DW - SW,DWS = {Wm1, Wm2, …, Wmy} (mi≠ni, DWS∈DW, ms<=ns);
步骤5,对DWS统计词频,DFi= {(Wi,k1, Fi,k1), …, (Wi,ks, Fi,ks)} (ki∈mi, 1 <= k i<= my);
步骤6,根据式(4)计算局部系数,计算结果SLi= {(Wi,k1, Si,k1), …, (Wi,ks, Si,ks)};
步骤7,从DFi取第j个词Wi,如果Wj∈DWF,执行步骤8;否则,执行步骤9;
步骤8,更新词-出现文档数表,DWFt= (Wj, Fj+1),执行步骤10;
步骤9,更新词-出现文档数表,DWFt= (Wj, +1);
步骤10,如果j <= ks,继续执行步骤11,否则跳转步骤7;
步骤11,如果i <= N,继续执行步骤12,否则执行步骤2;
步骤12,根据式(5)计算权重,
计算结果SG = {(Wp1, Kp1), …, (Wpn, Kpn)};
步骤13,根据式(6)计算全局系数
SLG={{W1,1,V1,1},…,{W1,x,V1,x}, …, {Wh,1,V1,1}, …, {Wh,y, V1,y}};特征降维跳转至步骤15;
步骤14,人工评价权重系数,选择合适的阈值和更新停用词库;
步骤15,对SLG特征降维,降维策略是根据阈值进行特征选取,SLG= {{W1,1, V1,1},…, {W1,p, V1,p}, …, {Wh,1, V1,1}, …, {Wh,o, V1,o}} ( p <= x, o <= y)。

图1 训练集的文本预处理算法
2.2 新文本预处理算法
算法主要步骤如下:
步骤1,从训练文本集中取第i个文本Di;
步骤2,根据分词词典,对文档Di进行机械分词,生成文本分词集DW = {Wn1, Wn2, …, Wns};
步骤3,根据停用词库SW,对文本分词结果集DW进行停用词处理DWS = DW - SW,DWS = {Wm1, Wm2, …, Wmy} (mi ≠ ni, DWS ∈DW, ms <= ns);
步骤4,对DWS统计词频,DFi = {(Wi,k1, Fi,k1), …, (Wi,ks, Fi,ks)} (ki ∈mi, 1 <= ki <= my);
步骤5,根据式(4)计算局部系数,计算结果SL = {(Wk1, Sk1), …, (Wks, Sks)};
步骤6,根据式(5)计算权重,全局系数由模型训练生成,
“一滴水能折射出太阳的光辉”!游成令在平凡的岗位上不平凡的付出,演绎出一名基层食药监人甘做群众食品药品安全“守望者”的高尚情怀。
SLG ={{W1, V1}, …, {Wx, Vx}, …, {W1, V1}, …, {Wy, Vy}};
步骤7,对SLG特征降维,降维策略是根据阈值进行特征选取,DV = SLG = {{W1, V1}, …, {Wp, Vp}, …, {W1,V1},…,{Wo,Vo}} (p <= x,o <=y )。
2.3 科技新闻多层次二分类算法
本文研究的是新闻类科技情报的分类抽取算法,传统的分类方法是将Web新文本直接放入多分类模型中进行分类,本文在研究传统分类模型的基础上提出了二分类方法,提高了分类模型的准确性。
其算法主要步骤如下:
步骤1,由科技新闻集DM和非科技新闻集DN共同组成训练文本集DN+DM,其中DNUDM=Ø;
步骤2,设中文分词词典Words、设停用词表stopwords={S1,S2, …,Sh},设特征信息词频集DFT、局部变量集SLT、全局变量集SGT、权重集SLGT、词-出现文档数集WCT,设全文文本词-出现文档数集WCA、词频集DFA、全局变量集SGA、局部变量集SLA、权重集SLGA设科技新闻集文本数M,设非科技新闻集文本数N,设训练模型文本数H=M+N;
步骤3,取第i个文本Di,文本内容分为两部分,一部分是特征信息,即特征信息和全文文本,特征信息是文本名和关键词的组合,全文文本是文本名、关键词集合和内容的组合;

图2 新文本预处理算法
步骤4,根据分词表Words对文本进行分词,得到特征信息DWT={Wtw1,Wtw2, …,Wtwx}、全文文本DWA={Waw1,Waw2, …,Wawy};
步骤5,根据停用词表stopwords对分词结果进行停用词处理,得到停用词处理后的结果集DWT=DWT-stopwords= {Wts1,Wts2, …,Wtsm}、DWA=DWA-stopwords= {Was1,Was2, …,Wasn};
步骤6,更新词-出现档次数集WCT= {(Wtc1,Ftc1), …, (Wtcx,Ftcx)}、WCA= {(Wac1,Fac1), …, (Wacy,Facy)};
步骤7,对分词结果进行词频统计,得到词频集词频统计DsFT= {(Wtf1,Ftf1), …, (Wtfx,Ftfx)}、DsFA= {(Waf1,Faf1), …, (Wafy,Fafy)};
步骤8,如果文本Di属于DM(Di∈DM)属于非科技新闻,则执行步骤9;否则跳转至步骤10;
步骤9,更新非科技新闻词频DFTN=DFTNUDsFT= {(Wn,tf1,Fn,tf1), …, (Wn,tfx,Fn,tfx)}、DFAN=DFANUDsFA= {(Wn,af1,Fn,af1), …, (Wn,afy,Fn,afy)};
步骤10,更新科技新闻词频DFTY=DFTY∪DsFT= {(Wy,tf1,Fy,tf1), …, (Wy,tfm,Fy,tfm)}、DFAY=DFAY∪DsFA= {(Wy,af1,Fy,af1), …, (Wy,afn,Fy,afn)};
步骤11,如果i<=M+N,则执行步骤12;否则i=i+1,跳转至步骤3;
步骤12,根据公式(7)
(7)
计算模型的局部系SLA= {{(Wn,al1,Ln,al1), …, (Wn,alx,Ln,alx)}, {(Wy,al1,Ly,al1), …, (Wy,aly,Ly,aly)}};
步骤13,根据公式(8)
(8)
计算模型的全局系数SGA={(Wag1,Gag1), …, (Wagz,Gagz)}
步骤14,根据公式(9)
SLGAj(Wi)=SLAj(Wi)*SGA(Wi)
(9)
计算模型的权重系数SLGA= {(Wn,aw1,Wn,aw1), …, (Wn,awx,Wn,awx), {(Wy,aw1,Wy,aw1), …, (Wy,awy,Wy,awy)}};
步骤15,模型参数存储,存储停用词表stopword={S1,S2,…,Sh}、科技新闻数N、非科技新闻数M和模型训练总数H、DFT= {{(Wn,tf1,Fn,tf1), …, (Wn,tfx,Fn,tfx)}, {(Wy,tf1,Fy,tf1), …, (Wy,tfm,Fy,tfm)}}、WCT= {(Wtc1,Ftc1), …, (Wtcx,Ftcx)}、SGA= {(Wag1,Gag1), …, (Wagz,Gagz)}、SLGA= {(Wn,aw1,Wn,aw1), …, (Wn,awx,Wn,awx), {(Wy,aw1,Wy,aw1), …, (Wy,awy,Wy,awy)}};二分类模型训练结束;
步骤16,根据词典Words对新文本DY分词,特征信息分词DYWT= {Wty1,Wty2, …,Wtyx};
步骤17,去除停用词DYWT=DYWT-stopword= {Wts1,Wts2, …,Wtsz};
步骤18,对分词结果统计词频DYFT= {(Wty1,Fty1), …, (Wtyx,Ftyx)};
步骤19,如果DYWT∪DFTN≠ Ø&&DYWT∪DFTY≠ Ø,执行步骤20;否则跳转至步骤27;
步骤20,根据公式(10)
(10)
计算DY局部参数SLYT={(Wty1,Lty1), …, (Wtyx,Ltyx)};
步骤21,根据公式(11)
(11)
计算模型的全局系数SGT= {(Wtg1,Gtg1), …, (Wtgz,Gtgz)};
步骤22,根据公式(12)
SLGYTj(Wi)=SLGYTj(Wi)*SGT(Wi)
(12)
计算文档的权重系数SLGYT={(Wty1,Wty1), …, (Wtyx,Wtyx)};
步骤23,根据公式(13)
(13)
计算模型局部系数SLT= {(Wn,tl1,Ln,tl1), …, (Wn,tlx,Ln,tlx), {(Wy,tl1,Ly,tl1), …, (Wy,tly,Ly,tly)}};
步骤24,根据
SLGTj(Wi)=SLTj(Wi)*SGT(Wi)
(14)
计算模型的权重系数SLGT={(Wn,tw1,Wn,tw1), …, (Wn,twx,Wn,twx), {(Wy,tw1,Wy,tw1), …, (Wy,twy,Wy,twy)}};
步骤25,计算向量相似度Stk=Sim(SLGTY,SLGYT)、StNK=Sim(SLGTN,SLGYT);
步骤26,如果Stk>=StNK,则跳转至步骤34;否则跳转至步骤35;
步骤27,根据词典Words对全文文本分词,分词结果DYWA= {Wam1,Wam2, …,Wamx};
步骤28,对去除停用词,得到停用词处理后的结果DYWA=DYWA-stopword= {Wtm1,Wtm2, …,Wtmx};
步骤29,对停用词处理结果DYWA进行统计词频DYWA=DYWA-stopword= {Wam1,Wam2, …,Wamx};
步骤30,根据公式(15)
(15)
计算DY局部参数SLYA={(Wak1,Lak1), … , (Wtkx,Lakx)};
步骤31,根据公式(16)
SLGjA(Wi)=SLAj(Wi)*SGA(Wi)
(16)
计算文档的权重系数SLGYA= {(Wak1,Gak1), …, (Wtkx,Gakx)};
步骤32,计算向量相似度SaK=Sim(SLGAY,SLGYA)、SaNK=Sim(SLGAN,SLGYA);
步骤33,如果相似度SaK>=SaNK,执行步骤34;否则跳转至步骤35;
步骤34,更新M=M+1,更新DFTN=DFTN∪DYFT,将文档标记为非科技新闻DY∈DM;
步骤35,更新N=N+1,更新DFTY=DFTY∪DYFT,将文档标记为非科技新闻DY∈DN;
步骤36,更新WCT=WCT∪DYWT;
步骤37,更新模型参数;
步骤38,新文本数量达到训练文档数量的1%,即(M+N-H)/H>0.01,执行步骤39,否则结束;
步骤39,模型重新训练,执行步骤2。
3 实验分析
实验包括文本预处理、新闻文本二分类模型、新闻文本标准分类模型和新闻文本分类抽取。
原始数据是一篇文档的内容,内容包括文档标题、新闻主题内容和关键词。图3是训练集原始数据,左边数字为文本编号,编号右边是文本内容,内容包括文本标题、关键词和文本正文,图中选取了10篇新闻文章作为预处理实验的示例。

图3 训练集原始数据
图4是训练集分词和停用词处理后的结果集,数字是文本编号,后面是分词后统计完词频的结果集。“=”左边是词项,右边是词在文本中出现的次数。

图4 训练集分词和停用词处理结果
图5是训练集局部系数,数字代表文本编号,后面是计算的词项局部系数值集。“=”左边是词项,右边是词项的局部系数。
图6是训练集全局系数,每一个词项及其代表的全局系数的值。
研究选取了一定数据集对模型进行训练,由于没有专门的科技新闻和非科技新闻数据集,因此,实验中的数据集是经过人工筛选的科技新闻和非科技新闻集。表1是数据集的描述,数据集包括两部分,科技新闻和非科技新闻,维度2表示每一个文本包括两部分:标题和内容;样本数是标书该数据集中文本数量。
表2是实验结果描述,462个样本中,科技新闻是41篇,识别为非科技新闻类为6篇,识别率为85.3%;非科技新闻为421篇,识别为非科技新闻为349篇,识别率为82.9%。

图5 训练集局部系数

图6 全局系数
表1 实验数据集描述

数据集名称数据集描述维数样本数类别名ScienceData24053科技新闻NonScienceData23533非科技新闻NonClass2462测试数据
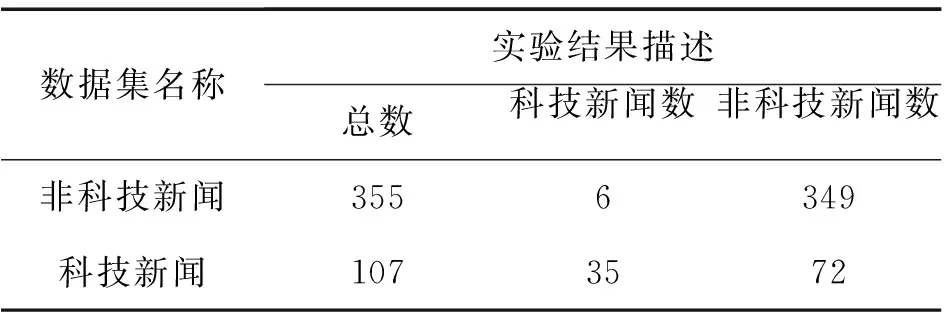
表2 实验结果描述
实验结果分析:样本输入集为462篇新闻文档,其中41篇科技新闻,421篇非科技新闻,这符合Web上存在大量非科技新闻的现状。经过人工测试,多层次二分类模型的识别率在80%以上,虽然没有达到99%以上的科技新闻识别率,但是能够为新闻推荐提供一定的参考价值,同时多层次分类策略能够提高分类效率。在未来的实验改进方面可以针对扩大科技词汇库,进而提高对科技新闻的敏感度。
4 结束语
为了改善从Web上获取的新闻信息的使用价值,提高科技新闻的推送准确率,设计并实现了基于TF-IDF的科技新闻文本分类抽取系统。文本预处理是文本向量化的过程,采用词频模型表示文本形式,归一化方法和特征降维能够减小模型计算量和文本长度不一致的影响。文本聚类使用K-means算法,针对Web科技新闻分类信息不统一、分类信息不完整等情况,聚类很好的解决了从无分类到有分类的过程,但Web科技新闻具有信息量大与格式多样等特点,因此聚类分析很难取得非常理想的效果,本文主要研究利用论文库和专利库的分类与科技词汇初始化新闻分类,取得了良好的分类效果。科技新闻多层次二分类模型构建了科技新闻与非科技新闻二分类模型,采用基于TF-IDF的向量模型,能够从未分类的文本中识别出绝大部分的科技新闻,取得了一定的效果,为分类提供一定的参考价值,模型优化可以通过论文库关键词强化科技词汇,进而提高二分类模型的分类准确率。用户检索和分类抽取算法中利用百度指数获取相关词集,提高对相关文档集的搜索能力,多层次搜索策略有效的降低了检索次数,提高抽取速度和准确率。在研究科技新闻分类抽取算法的过程中也发现了科技新闻需要建立标准的分类和分类向量,这是未来的研究方向。
[1] 谢松山,唐雁.基于左归词频向量空间模型的中文文本抄袭检测算法[J].西南大学学报:自然科学版,2015,37(5):158-161.
[2] 段洁,胡清华,张灵均,等.基于领域粗糙集的多标记分类特征选择算法[J].计算机研究与发展,2015,52(1):56-65.
[3] 邱云飞,王威,刘大有,等. 一种词频与方差相结合的特征加权方法[J].计算机应用研究,2012,29(6):2132-2134.
[4][7] 刘金岭,谈芸,李健普,等.基于多因素的中文文本主题自动抽取方法[J].计算机技术与发展,2010,20(7):72-79.
[5][8] 王红艳,朱全银,严云洋,等.商品价格数据的两种WEB挖掘算法比较[J].微电子学与计算机,2011,28(19):168-172.
[6]Quan-yinZhu,Su-qunCao,PeiZhou,etal.PriceForecastingforCellPhoneMarketUsingAdaptiveSlidingWindowandAdaptiveRBFNN[J].JournalofAlgorithmsandComputationalTechnology,2013,7(4):395-422.
[9] 朱全银,周培,尹永华,等.基于Web挖掘的多因素科技专家信息提取方法[J].淮阴工学院学报,2013,22(5):23-27.
[10]QuanyinZhu,JinDing,YonghuaYin,etal.AHybridApproachforNewProductsDiscoveryofCellPhoneBasedonWebMining[J].JournalofInformationandComputationalScience,2012,9(16):5039-5046.
[11]QuanyinZhu,PeiZhou,SunqunCao,etal.AnovelRDB-SWapproachforcommoditiespricedynamictrendanalysisbasedonWebextracting[J].JournalofDigitalInformationManagement,2012,10(4):230-235.
[12]Quan-yinZhu,Yong-huaYin,Hong-jianZhu,etal.EffectofMagnitudeDifferencesintheOriginalDataonPriceForecasting[J].JournalofAlgorithmsandComputationalTechnology,2014,8(4):281-312.
[13]NouriV,Akbarzadeh-T,MR,etal.Ahybridtype-2fuzzyclusteringtechniqueforinputdatapreprocessingofclassificationalgorithms[A].ProceedingsofIEEEInternationalConferenceonFuzzySystems[C].Beijing:IEEEComputerSociety,2014:1131-1138.
[14]XiaohuiHuang,YunmingYe,HaijunZhang.ExtensionsofKmeans-TypeAlgorithms:ANewClusteringFrameworkbyIntegratingIntraclusterCompactnessandInterclusterSeparation[J].IEEETransactionsonNeuralNetworksandLearningSystems,2014,25(8):1433-1446.
[15] 马海兵,毕久阳,郭新顺.文本分类方法在网络舆情分析系统中的应用研究[J].情报科学,2015,33(5):97-101.
[16] 李琼,陈利.一种改进的支持向量机文本分类方法[J].计算机技术与发展,2015,25(5):78-82.
[17] 胡吉明,陈果.超球支持向量机文本分类方法改进[J].现代图书情报技术,2014(9):71-80.
[18] 季铎,毕臣,蔡东风.基于类别信息优化的潜在语义分析分类技术[J].中国科学技术大学学报,2015,45(4):314-320.
[19] 李保利.基于类别层次结构的多层文本分类样本扩展策略[J].北京大学学报:自然科学版,2014,51(2):357-366.
[20] 马成龙,姜亚松,李艳玲,等.基于词矢量相似度的短文本分类[J].山东大学学报:理学版,2014,49(2):18-35.
(责任编辑:尹晓琦)
Categorization Extraction Algorithm for Scientific-Related News on Websites
ZHU Quan-yin, PAN Lu, LIU Wen-ru, LI Xiang, ZHANG Yong-jun, LIU Jin-ling
(Faculty of Computer and Software Engineering, Huaiyin Institute of Technology, Huai'an Jiangsu 223005, China)
There are a lot of non-scientific-related news on Websites. In order to improve the useful value for the news information, a novel multilevel dichotomous model of text automatic categorization extraction system for technology news based on TF-IDF was designed and implemented. The news offered by government news website and Phoenix as the research background in scientific news categorization extraction. Experiments showed a 85.3 percent accuracy for scientific-related news and 82.9 percent recognition rate for nonscientific-related news respectively in the test containing two hundred thousand documents and more than four thousand news classifications. The results showed that the proposed method offered a useful reference model on website scientific intelligence.
scientific-related news; text categorization; TF-IDF; extraction algorithm
2015-07-30
国家星火计划(2011GA690190);江苏省科技支撑计划(2015);江苏省高校自然科学研究面上项目(15KJB
朱全银(1966-),男,江苏盱眙人,教授,主要从事智能信息处理、接口与通信研究。
TP181
A
1009-7961(2015)05-0018-07
520004);淮安市科技支撑计划(HAG2014023,HAG2014028);淮安市“533英才工程”项目
