一种新型朴素贝叶斯文本分类算法
2014-07-25段利国
邸 鹏 段利国
(太原理工大学计算机科学与技术学院,太原,030024)
引 言
自动文本分类是自然语言处理领域中的一个研究热点,其研究目的是借助自动分类技术判断文本的类别。数量急剧增长的网络文本成为人们获取信息的主要来源,借助文本分类技术,可以更加快捷、准确地获取用户需要的信息。此外,文本分类技术在电子政务、垃圾邮件过滤、文本情感分析、网络舆情监控等领域都有着广泛的应用。[1]
在英文文本分类方面,Dublin大学Finn等人[2]研究主客观句分类,得出基于词性标注的特征选择方法比词袋效果好。Columbia大学Yu等人[3]对新闻这类主要讲“事实”的文本进行主客观句子识别,利用SimFinder工具计算句子相似度,构造训练集,结合各类词性信息构建贝叶斯分类器,提出多分类器的构建以解决训练集构造的不确定性和训练集质量的问题。Cornell大学Pang等人[4]利用属性相同的句子位置分布较近的特点,将候选句子构成一幅图,从而将主客观句分类转化为求图的最小割问题,实现Cut-based分类器,对主客观句进行分类识别。
在中文文本分类方面,文献[5]提出了一种K近邻元分析分类算法,该算法利用NCA算法对训练集进行距离测度学习和降维,使用了K近邻方法,通过测试集的类条件概率进行类别判定,取得了很好的分类效果。文献[6]提出了一种基于属性频率的朴素贝叶斯算法,该方法放松了属性之间相互独立的假设条件,利用RoughSet可辨识矩阵,对不同属性赋予不同权值,在最后的实验中取得了良好的分类效果。文献[7]提出了一种归一化向量的分类算法,将单个类别中的词频及文档频率用到矩阵投影运算中去,将文本特征的三维空间投影到二维空间上,有效地降低了特征空间维数,提高了分类效率。
综合分析现有研究成果,没有文献对先验概率的计算进行改进,对贝叶斯算法的研究也普遍是为了提高分类的准确率,而很少考虑分类的时间,并且在后验概率的计算中存在的一个小误差没能被很好地改进。因此,本文对传统的贝叶斯算法进行改进,提出了一种新的文本分类算法。
1 贝叶斯相关理论
用于文本分类的机器学习算法主要有SVM,Bayes,KNN,LLSF和决策树等。其中,朴素贝叶斯算法是一种以贝叶斯相关理论为基础的最常用的方法,它以属性之间的相互独立性为前提,当该前提成立时,与其他分类算法相比,朴素贝叶斯算法的准确率往往最高[8]。而在朴素贝叶斯算法中经常会用到全概率公式以及贝叶斯公式。
1.1 全概率公式
设A,B是随机试验的两个随机事件,事件B发生的概率P(B)>0,则称

为在事件B发生的条件下,事件A发生的条件概率[9]。
全概率公式的定义如下:设随机试验E的样本空间为Ω,A为E的一个事件,B1,B2,…,Bn是对空间Ω的一个有限划分,且P(Bi)>0(i=1,2,…,n),则

称为全概率公式[9]。也可以通俗的理解为:事件A发生有B1,B2,…,Bn这n种方法,将每一种方法下事件A发生的概率相加,就可得到事件A发生的概率。
1.2 贝叶斯公式
设随机试验E的样本空间为Ω,A为E的事件,B1,B2,…,Bn为Ω的一个划分,则

称为贝叶斯公式[9]。
1.3 朴素贝叶斯算法
在朴素贝叶斯算法中会用到先验概率,它是指一个假设能够成立的背景知识。在本文中,某个假设h在未进行训练之前的初始概率用P(h)表示,即假设h的先验概率。在实际处理中,当没有先验概率时,可以为每一种假设赋予一个相同的先验概率。同理,用P(D)表示训练样本数据D的先验概率。对于P(D/h),它表示当假设h成立时观察到数据D的条件概率。在机器学习中,通常需要研究的是P(h/D),即给定一个训练样本数据D之后,判断在数据D的基础上假设h成立的条件概率,也把它叫做后验概率,它表示训练样本数据D出现时假设h成立的置信度。
根据贝叶斯公式

可以去掉公式中的P(D),因为P(D)通常是不依赖于假设h的常量,则公式中后验概率P(h|D)的值就取决于P(D|h)P(h)这个乘积,这就是本文所要用到的朴素贝叶斯算法的核心思想。在给定了候选假设集合H以及训练数据D之后,从假设集合H中找出D出现时可能性最大的假设h。简而言之,就是当给定一些训练样本数据集之后,如何让计算机去学习这个训练样本数据集,从而当碰到新的数据时,可以自动将新数据归类到已经定义好的某一个类别中去。
一个数据通常包含多个属性,这里假设数据D中包含a1,a2,…,an这n个属性,而朴素贝叶斯算法基于这样一个假设:给定数据的属性值之间相互独立。该假设说明当给定一个具体的目标值时,a1,a2,…,an同时发生的联合概率等于每个属性单独发生的概率的乘积,用公式表达

则朴素贝叶斯算法中的后验概率就可以表示成[10]

2 朴素贝叶斯分类器设计
当给定一篇中文文本时,计算机只能将其识别成一个很长的字符串,如何让计算机更加细致地识别这篇文本是首先要面对的问题。因此,在利用朴素贝叶斯算法进行文本分类之前,需要对文本进行一些预处理。
2.1 预处理
中文不像英文那样词与词之间都有空格分开,因此中文文本需要进行分词才能够进行下一步的处理。在本次朴素贝叶斯分类器的设计过程中,直接调用了中国科学院计算技术研究所研制的汉语词法分析系统ICTCLAS[11]。
在分词过后,作者利用哈尔滨工业大学信息检索研究中心提供的中文停用词表,对分词结果进行特征提取[12],以去除那些对分类结果无影响的词,比如“的”、“在”这一类词,降低文本向量的维数,提高运算的效率[13]。
2.2 朴素贝叶斯分类器设计
朴素贝叶斯分类器就是将朴素贝叶斯算法应用在分类器的设计上。根据贝叶斯
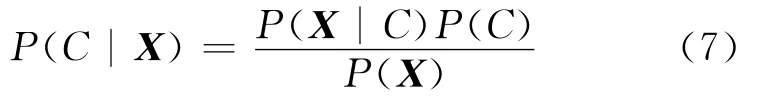
在特征提取之后,待分类的文本就会被表示成一个特征向量X(x1,x2,…,xn),下一步的任务就是将该向量X(x1,x2,…,xn)归类到它最可能属于的类别C(C1,C2,…,Cj)中去。其中,X(x1,x2,…,xn)表示文本的特征向量,C1,C2,…,Cj为给定的j种类别。换句话说,就是求解向量X(x1,x2,…,xn)分别属于C1,C2,…,Cj的概率值(P1,P2,…,Pj),其中,Pj表示将X(x1,x2,…,xn)归类到Cj的概率,那么 max(P1,P2,…,Pj)所对应的结果就是文本X所属的类别[14]。
根据朴素贝叶斯算法可以得到

式中:P(Cj)为待分类文本属于Cj的先验概率;P(x1,x2,…,xn|Cj)表示待分类文本属于Cj时;类别Cj中包含文本特征向量(x1,x2,…,xn)的后验概率。所以求解 max(P1,P2,…,Pj)就可以转化

根据朴素贝叶斯算法的假设,文本的特征属性x1,x2,…,xn之间相互独立,则其联合概率就等于各个属性的概率的乘积,所以,最后用来进行分类的函数就是为求解式(9)的最大值

3 算法改进
在研究的过程中,主要从以下两个方面进行了改进。
(1)通常在给定一篇中文文本时,人们可能会有一个背景知识,根据这个背景知识可以对该篇文本进行大概的分类,这便是传统的朴素贝叶斯算法中的先验概率所起的作用。但在某些实际情况中,事先并不知道它属于哪一类,也就是没有相关的背景知识,因此本着公平的原则,该篇文档属于某一类的先验概率应该相同,不能因为训练文本集中某一类的文本数量多,就认为属于这一类的概率大,这是不公平、不科学的。因此本文就只针对先验概率相等的情况进行后续研究。根据以上观点,就可以去除分类函数中的先验概率的计算,则分类函数为

因为最后是要通过比较得出最大的概率值,所以都去掉先验概率的计算不会影响最后的分类结果。同时,去掉先验概率的计算可以大幅减少计算机的I/O操作,从而增加计算的速度。
(2)在实验中,定义了一个double类型的变量来存放计算出来的后验概率,每个特征词计算出来的后验概率往往都是一个非常小的数,有时候待分类的文本比较长,其特征词就比较多,根据朴素贝叶斯算法计算出来的概率值往往非常小,在实验中发现很多时候计算出来的后验概率都为0.0,当预先定义好的类别数目比较少时,就很有可能影响最后的分类精度。为克服这种误差传播,为每个特征词求解出来的后验概率引入一个放大系数K,这不会影响实验结果,因为最后是要通过比较得出最大的概率值,适当放大一定倍数更有利于减少误差传播,提高分类精度。K值的确定会在下面的实验中给出。分类函数为

4 实验结果与分析
构建朴素贝叶斯分类器需要大量的训练文本集和测试集,本文实验数据来自搜狗实验室提供的reduced版本互联网语料库,该版本包含财经、IT、健康、体育、旅游、教育、招聘、文化、军事等9类文档,每一类文档包含1 990篇文档,实验中随机从每一类文档中抽取出一定数量的文本作为训练文本,再从剩下的每一类文本中抽取一些文本作为测试文本,最后使用准确率作为评价指标,其中

实验时所用机器型号为惠普Compaq 6515b,机器主要配置为AMD Turion 64处理器,1GB内存,2.2GHz主频,使用JAVA 编程语言,Myeclipse8.5开发环境。实验分别对改进前后的算法进行验证,实验数据如表1所示。

表1 分类结果对比Table 1 Classification results comparison
通过表1实验可以看到朴素贝叶斯分类器的准确率还是非常高的,去掉先验概率的计算对分类结果的影响并不是很大,除了军事类和IT类在改进前后的准确率相同之外,其他几类文本的准确率,改进后的分类算法都比改进前的分类算法有小幅度的提高。
此外,实验还从每一类文本中抽取出一篇文本作为测试文本,对其改进前后的计算时间进行了统计,结果如表2所示。计算时间因测试文本的字数而异。

表2 计算时间对比Table 2 Computer time comparison s
从表2的实验结果可以看出,改进后的算法在计算速度上有了明显的提升,9类测试文本在算法改进后所用的时间都比改进前要少。综合表1,2的实验结果,可以得出结论:改进后的算法效率更高。
在改进的算法中,为减小误差传播,为后验概率的计算引入了一个放大系数K,因为最后利用分类函数计算出来的后验概率值非常小,结果有时会显示为0.0。起初将K的值设置为10,但在实验中发现,有些时候放大倍数过大时也会使后验概率的计算结果为0.0。随机从9类文本中,每类随机抽取了100篇测试文本,其中包含一些篇幅比较长的文本,当计算一篇文本分别属于9种类别的后验概率时,9个后验概率中只要出现一次0.0,就将这篇文本标记出来,最后统计了每一类的100篇文本在扩大倍数分别为3,4,5,6,7,8,9,10时被标记出来的文本数,放大系数为1~2倍时对分类性能的影响太小,所以没有列出对应的统计结果。实验结果如表3所示。
通过表3的实验结果可以看出,放大倍数集中于4,5,6,7时被标记出来的文本数相对较少,放大的效果比较好。其中,当放大系数为5时,取得的实验结果相对更好。

表3 放大倍数实验结果Table 3 Experiment results of amplification factor
5 结束语
通过朴素贝叶斯算法构造文本分类器,是一种简单有效的方法,分类的准确率非常高,速度也相对较快。但由于朴素贝叶斯算法是一种基于机器学习的算法,它的准确率在很大程度上依赖于训练集,因此,如何确定训练文本集的数量将是今后的一个研究方向。在本次放大系数的实验中,只是初步选取了一些整数倍,初步确定了放大倍数的范围,具体放大到什么程度,也有待日后做进一步的研究。此外,当文本中包含一些较复杂的句式时,往往会影响分类的精度,这也将是今后一个主要的研究方向。
[1]Sebastiani F.Machine learning in automated text categorization[J].ACM Computing Surveys,2002,34(1):1-9.
[2]Finn A,Kushmeick N,Smyth B.Genre classification and domain transfer for information filtering[C]∥Proceedings of the 24th BCS-IRSG European Colloquium on Information Retrieval Research:Advances in Information Retrieval. UK:Springer,2002:353-362.
[3]Yu H,Hatzivassiloglou V.Towards answering opinion questions:Separating facts from opinions and identifying the polarity of opinion sentences[C]∥Proceedings of the 2003Conference on EMNLP.USA:ACL,2003:129-136.
[4]Pang B,Lee L.A sentimental education:sentiment analysis using subjectivity summarization based on minimum cuts[C]∥Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics.Morristown,NJ,USA:ACL,2004:271-278.
[5]刘丛山,李祥宝,杨煜普.一种基于近邻元分析的文本分类算法[J].计算机工程,2012,38(15):139-141.
Liu Congshan,li Xiangbao,Yang Yupu.Text classification algorithm based on neighborhood component analysis[J].Computer Engineering,2012,38(15):139-141.
[6]张春英,王晶.一种新型加权朴素贝叶斯分类算法[J].微计算机信息:管控一体化,2010,26(10):222-224.
Zhang Chunying,Wang Jing.A new weighted naive Bayesian classification algorithm[J].Microcomputer Information,2010,26(10):222-224.
[7]钟将,孙启干,李静.基于归一化向量的文本分类算法[J].计算机工程,2011,37(8):47-49.
Zhong Jiang,Sun Qigan,Li Jing.Text classification algorithm based on normalized vector[J].Computer Engineering,2011,37(8):47-49.
[8]吕国云,赵荣椿,张艳宁,等.基于三音素动态贝叶斯网络模型的大词汇量连续语音识别[J].数据采集与处理,2009,24(1):1-6.
LüGuoyun,Zhao Rongchun,Zhang Yanning.Continuous speech recognition for large vocabulary based on triphone DBN model[J].Journal of Data Acquisition and Processing,2009,24(1):1-6.
[9]盛骤.概率论与数理统计[M].北京:高等教育出版社,2010:26-33.
[10]Mitchell T M.机器学习[M].北京:机械工业出版社,2003:126-128.Mitchell T M.Machine learning[M].Beijing:Chine Machine Press,2003:126-128.
[11]中国科学院计算技术研究所.ICTCLAS特色[EB/OL].http://ictclas.org/index.html,2008/2013.
Institute of Computing Technology.ICTCLAS[EB/OL].http://ictclas.org/index.html,2008/2013.
[12]赵世奇,张宇,刘挺,等.基于类别特征域的文本分类特征选择方法[J].中文信息学报,2005,19(6):21-27.
Zhao Shiqi,Zhang Yu,Liu Ting.A feature selection method based on class feature domains for text categorization[J].Journal of Chinese Information Processing,2005,19(6):21-27.
[13]史岳鹏,朱颢东.基于类别相关性和优化的ID3特征选择[J].数据采集与处理,2011,26(2):231-234.
Shi Yuepeng,Zhu Haodong.Feature selection based on category correlation and improved ID3[J].Journal of Data Acquisition and Processing,2011,26(2):231-234.
[14]李晓欧,乐建威.基于小波预处理和贝叶斯分类器的P300识别算法[J].数据采集与处理,2011,26(4):420-423.
Li Xiaoou,Le Jianwei.P300detection algorithm based on wavelet preprocessing and bayesian classification[J].Journal of Data Acquisition and Processing,2011,26(4):420-423.
