一种潜在信息约束的非负矩阵分解方法
2014-07-25高新波王秀美
高新波 王 笛 王秀美
(西安电子科技大学电子工程学院,西安,710071)
引 言
大数据给机器学习、数据挖掘和模式识别带来了新的机遇与挑战。降维分析能有效避免数据维数灾难问题,并且可以在保留高维数据的大部分内在信息的同时将高维数据映射到低维空间,是挖掘海量、高维数据中有用信息的重要手段。传统的降维方法允许降维后的数据存在负值,如局部线性嵌入(Locally linear embedding,LLE)[1],等距映射(Isometric feature mapping,Isomap)[2],局部保持投影(Locality preserving projections,LPP)[3],拉普拉斯特征映射(Laplacian eigenmaps,LE)[4]。但是,实际应用中很多数据具有明确的物理意义,要求非负数值,这种特性被称为“非负性”,如数字图像的灰度值、文本文档中关键词出现的频率等。面对海量高维非负数据,如何针对其非负特性寻找有效的降维方法成为一个亟待解决的重要问题。非负矩阵分解(Nonnegative matrix factorization,NMF)是解决这一问题的经典方法,它将原始非负数据分解为非负基矩阵和非负系数矩阵,使得重构数据是由基矩阵以累加的方式叠加而成,符合人类思维中“局部构成整体”的观念。非负矩阵分解在达到维数约简的同时还能得到非负的数值结果,具有较好的可解释性,成为目前流行的数据处理与分析方法,广泛地应用于图像处理[5]、文本聚类[6]、推荐系统[7]、视 频 跟 踪[8]、特 征 提 取[9]、语 音 信 号 处理[10]等方面。
经典的非负矩阵分解方法提出以后,国内外学者从不同角度提出了改进方法。为了增强非负矩阵分解基矩阵的局部特性,Li等人通过对非负矩阵分解的目标函数增加局部约束项提出了局部非负矩阵分解方法(Local NMF,LNMF)[11]。为了增强非负矩阵分解的稀疏性,Hoyer对非负矩阵分解的目标函数增加了稀疏约束项,提出稀疏非负矩阵分解方法(NMF with sparseness constraints,SNMF)[12]。Cai等人提出图正则化非负矩阵分解方法(Graph regularized NMF,GNMF),该方法根据原始数据的几何结构构造近邻图,然后将近邻图作为约束项添加到非负矩阵分解的目标函数中,从而使得非负矩阵分解在降维的同时保持原始数据的几何结构关系[13]。Zhang等人对图正则化非负矩阵分解的目标函数添加正交约束项使所有基向量正交,从而使得图正则化非负矩阵分解有局部最优的解析解[14]。Wang等人利用不同类型的近邻图的线性组合来代替图正则化非负矩阵分解中的单一近邻图,更好地保持了数据的几何结构信息[15]。上述算法均取得了较好的聚类和识别效果,它们的共同特点是根据特定目标,在非负矩阵分解算法的目标函数中增加约束项来改善非负矩阵分解的性能。
上述基于图正则化的非负矩阵分解方法均利用近邻图来保持数据的几何结构。传统近邻图是通过k近邻方法来构造数据的相似性关系,然而k近邻方法虽然速度快,但是不能保证较小的重构误差,会对非负矩阵分解精确性造成影响,进而降低非负矩阵的判别性能。迭代最近邻方法[16]可以得到数据之间互相表示的重构系数,且重构系数具有稀疏性,并且可以保证较小的重构误差。本文采用迭代最近邻方法得到数据之间互相表示的重构系数,其大小反映了数据之间关系的强弱,称之为数据的潜在信息。利用潜在信息构造反映数据之间真实关系的相似图,基于此,本文提出了一种潜在信息约束的非负矩阵分解算法。该算法利用挖掘出的潜在信息构建相似图,根据相似图构造约束项,并将约束项添加到非负矩阵分解的目标函数中,从而使得非负矩阵分解在降维的过程中保持原始数据之间的相似性关系。
1 非负矩阵分解
对于非负数据矩阵X=[x1,…,xN]∈RM×N,其中列向量xi(i=1,…,N)表示数据样本点,非负矩阵分解的目的是将非负矩阵X近似分解为两个非负矩阵U∈RM×K和V∈RN×K乘积的形式,即

其中,矩阵U中的所有列向量可以认为是对数据矩阵X进行线性逼近的一组基,而V可以认为是数据矩阵X在新基U下的投影系数。通常情况下,K≪M,N,即非负矩阵分解将原始的M维数据约减成了K维数据,起到了降维和压缩的作用。
在非负矩阵分解中,寻找一个近似的分解过程是最重要的核心问题,这就需要定义一个目标函数,用优化的方式来逼近矩阵的分解。一般地,利用两个矩阵之间的欧氏距离来衡量逼近效果,目标函数为[17]

由于目标函数(2)不是凸函数,要找到一个全局最优解是非常困难的。因此,Lee等人利用乘性迭代算法来寻求目标函数的局部最优解[18],其迭代规则为

重复迭代式(3,4)可以逐渐减小目标函数(2),从而使得目标函数收敛于某个局部最优分解。
2 潜在信息约束的非负矩阵分解方法
高维空间中的数据间通常存在一定的内在关系,可以利用权值大小来描述数据之间关系的强弱,并在降维的过程中保持这种权值关系,从而达到降维后的数据能够保持原始数据之间几何结构关系的目的[19-20]。在非负矩阵分解中,通过构造样本之间的近邻图作为约束条件,以此来保持非负矩阵分解前后样本之间的几何结构关系。然而传统近邻图是通过k近邻方法来构造,由于k近邻方法对近邻数目的强制性约束,会产生较大的截断误差,从而对非负矩阵分解造成较大的重构误差,影响非负矩阵分解的性能。
本文通过学习的方法,挖掘数据之间的潜在信息,并根据数据之间的潜在信息构建一个能够反映数据点之间真实关系的相似图,进而合理利用该相似图改善非负矩阵分解的性能,提高非负矩阵分解的辨别能力。
2.1 潜在信息挖掘
高维数据之间通常会存在一定的内在关系,在降维的过程中保持数据之间的相似性关系至关重要。迭代最近邻方法[16](Iterative nearest neighbors,INN)可以得到数据之间的相似性程度。对于给定的字典D=[d1,…,dN]∈RM×N和一个测试数据q∈RM,迭代最近邻的优化目标函数为

其中K为迭代次数,si∈D,γ∈(0,1)。通过迭代,可以由字典D重建测试数据q,即



式中:ci越大,si对重构q的贡献越大,则说明si与q的关系越强。迭代最近邻算法过程如表1所示。

表1 INN算法Table 1 INN Algorithm
图1为INN算法在Yale人脸数据库的实验结果。本文随机在Yale数据库中选取一幅人脸图像作为测试图像,即为左上角图像,利用INN算法在由其余图像组成的字典中对测试图像进行重构,得到重构系数c。从图中可以看出,测试图像可以由第三行的最近邻样本图像以及对应的重构系数进行重构得到,其中重构图像为右下角图像。在第三行的最近邻样本中,用来重构测试图像的最近邻图像和测试图像均属于同一个人。因此,可以利用得到的重构系数来表示测试数据和字典中数据之间的潜在关系,且重构数据对应的系数越大则代表其和测试数据的关系越紧密。
由于INN算法可以得到测试数据和字典中数据的潜在关系,可以通过这种潜在关系表示数据之间的相似性,进而构建数据的相似矩阵。对于数据xi∈X=[x1,…,xN],将其余数据组成的字典Di=[x1,…,xi-1,0,xi+1,…,xN],利用迭代最近邻求解xi在字典Di中的重构的系数Ci

图1 迭代最近邻算法在Yale人脸数据库的实验结果Fig.1 Experimental result of INN on the Yale face data set

分别对训练数据X中其他样本做相同的处理,最终得到训练集中每个数据点与其他数据点之间的潜在关系,并用矩阵C=[C1,C2,…,CN]表示训练数据间的潜在关系矩阵。
2.2 潜在信息约束的非负矩阵分解方法
为了改善非负矩阵分解的性能,利用上述得到的潜在关系矩阵构造数据的相似图,并根据相似图构造非负矩阵分解目标函数中的约束项,从而使得降维后的数据可以很好地保留原始数据之间的相似关系。
对于数据X=[x1,…,xN]∈RM×N,构造k近邻图W={wij}N×N,利用约束矩阵C调整近邻图W,得到数据之间的相似图={}N×N

为了使对称,令
根据以上规则构造的相似图有如下性质:
(1)是对称的,且∈[0,1];
(3)>cij,如果cij>0。
性质(2)说明当cij大于0,即xi和xj具有较高的相似性,相似图的权值大于近邻图W的权值,从而更好地体现了数据之间的相似性。性质(3)可以保证,当cij值较大时,即使近邻图中权值wij很小,相似图中也会较大。图2为相似图构造过程示意图,图2(a)和图2(c)为黑色数据点x1的k近邻图,其余点距离x1越近,其与x1的对应权值越大,其中红色点代表点x1的k近邻点,蓝色点代表在x1的近邻图中权值较小而潜在关系矩阵中权值较大的点。假设x1的k近邻点对应的潜在关系c1j大于0,根据性质(2),在相似图2(b)中,x1的k近邻点较原始k近邻图2(a)有更强的相似性。根据性质(3),在相似图2(d)中,潜在关系矩阵中权值较大的蓝色点较原始k近邻图2(c)有更强的相似性。因此,根据潜在关系矩阵构造的相似图较k近邻图更好地保持了数据之间的相似性。

图2 相似图构造过程示意图Fig.1 Schematic diagram of construction process for similarity graph
为了保持数据之间的相似关系,本文构造如下约束项

当cij为正时,xi和xj相似性较大,则xi和xj在降维空间中也应该相似,由于较大,为使φ(V)较小,则vi和vj也应该相似。这样,就达到了原始空间中相似性较高的两个数据,在降维空间中也相似的目的,从而让样本之间的相似性关系得以保持。因此,潜在信息约束的非负矩阵分解方法的目标函数为

式中右边第一项是重构项,用来寻找一个新的低维空间表示高维空间中的样本。第二项是约束项,使得高维空间中样本间的相似性关系在低维空间中还能够得以保持。λ用于平衡两部分在降维过程中的比重。
2.3 迭代准则
为了得到最终的迭代准则,可以对式(10)进一步简化

其中是一个对角阵,第i个对角元素为矩阵将式(12)代入式(11)可以得到

由于存在两个约束条件U,V≥0,分别定义Lagrange乘子Ψij和φij,记Ψ=[Ψij]和Φ=[φij]分别表示Lagrange乘子Ψij和φij组成的矩阵。因此,新的目标函数可以写为

为了得到局部最优解,对式(14)分别对U和V求偏导

利用KKT条件,ΨijUij=0和φijVij=0,进一步化简式(15)和式(16)

最终可以得到U和V的迭代公式

3 实验结果
为了验证本文提出的非负矩阵分解算法的有效性,作者在一些标准图像数据库上进行聚类实验,并和本领域的一些主流算法进行对比分析。
3.1 聚类效果评价准则
本文通过对比每个数据的聚类标签和数据集提供的标签,以准确率和归一化互信息准则来衡量算法的聚类效果。
准确率(Accuracy,AC)准则用来计算聚类算法的正确标签比率,衡量算法的准确性。给定一个数据集,样本数为n,样本的真实标签为ri。假定li是通过聚类得到的样本标签,则准确率可以定义为

其中δ(x,y)当x=y时,其值为1,否则,其值为0。map(li)是最优投影函数,将聚类得到的标签li投影为对应的样本标签。本文利用Kuhn-Munkres算法[21]来进行投影。
归一化互信息(Normalized mutual information,MI)准则用来估计两个聚类簇之间的相似性。给定两个聚类簇C和C′,它们的互信息(Mutual information,MI(C,C′))定义为

其中p(ci),p(c′j)分别表示从数据集中的样本属于聚类簇C,C′的概率,p(ci,c′j)表示从数据集中样本同时属于聚类簇C和C′的概率。MI(C,C′)的值介于0和 max(H(C),H(C′))之间,其中H(C)和H(C′)分别为聚类簇C和C′的熵。当两个聚类簇C和C′完全相同时,MI(C,C′)取得最大值 max(H(C),H(C′)),当两个聚类簇完全独立时,MI(C,C′)取得最小值0。在实验中,利用归一化的互信息(C,C′),其值介于0和1之间。

3.2 实验参数设置
为验证算法的性能,本实验比较潜在信息约束的非负矩阵分解方法(Information-restrained nonnegative matrix factorization,INMF)与现有的三个非负矩阵分解的主流算法 NMF[17],GNMF[13],MMF[14]在三个图像数据集的聚类效果。表2给出了各个数据集的相关信息。

表2 图像数据库Table 2 Image Data Sets
为使对比实验更加合理,本文实验条件参照GNMF的中条件进行设置。实验过程如下:
(1)从每个数据集中任意选择P类图像作为数据集X。
(2)对于每一个数据集X,通过NMF,INMF,GNMF,MMF得到原始数据的低维表示V,并设低维空间维度为类别数P。
(3)利用K-means算法对不同算法得到的低维表示V和原始数据进行聚类。重复运行25次,每次采用不同的初始值,取25次实验中使得K-means代价函数最小的结果作为每个算法的最终聚类结果。
(4)利用不同算法的聚类标签和样本的真实标签进行对比得到其对应的AC和。
(5)对于每个P值,重复以上过程20次,取AC和的平均值作为最终结果。
(6)NMF是无参数方法。GNMF,MMF和INMF含有约束项比重参数λ,均设为100。这3种方法需要构造近邻图W,均采用热核形式,如式(24)所示,其中t设为0.2,近邻阈值设为3。INMF在潜在信息挖掘时含有参数γ,设为0.25。

3.3 结果与分析
3.3.1 PIE人脸数据库
PIE人脸数据库包括68个人的13种不同姿态、43种不同光照和4种不同表情下的41 368张人脸图像。本文利用PIE人脸数据库的一个子集[13]进行实验,包括68个人随光照条件变化的42幅正面人脸图像。每张图像均是32×32的灰度图像。
图3为随着图像类数P的变化,准确率和归一化互信息的变化情况。从图中可以看到,利用非负矩阵分解降维后的数据进行聚类的效果(NMF,GNMF,MMF,INMF)明显优于直接利用原始数据进行聚类的效果。GNMF和MMF在降维的过程中保留了原始数据的几何结构关系,效果优于原始NMF算法。INMF算法由于考虑了原始数据的潜在约束信息,效果要明显优于其他算法。

图3 PIE人脸数据库实验结果Fig.3 Experimental results on the PIE face data set
3.3.2 COIL20数据库
COIL20数据库包含20个物体的1 440幅图像,其中每个物体从72个不同角度进行拍摄。每张图像均是32×32的灰度图像。
图4为随着图像类数P的变化,准确率和归一化互信息的变化情况。MMF虽然降维的过程中保留了原始数据的几何结构关系,但是为了使目标函数具有解析解,该算法在目标函数中添加正交约束使得所有基向量正交,而从图4中看到,这种正交约束反而影响了算法的效果。本文提出的INMF算法的效果要明显优于其他算法。

图4 COIL20人脸数据库实验结果Fig.4 Experimental results on the COIL20face data set
3.3.3 AR人脸数据库
AR人脸数据库包括116人不同表情、光照、遮挡和老化的3 288幅图像。实验时将每幅图像调整为60×60大小。
图5为随着图像类数的变化,准确率和归一化互信息的变化情况。图5(a)中,各个算法的准确率相差不多,但INMF整体优于其他算法。图5(b)中,INMF在归一化互信息准则下要明显优于其他算法。
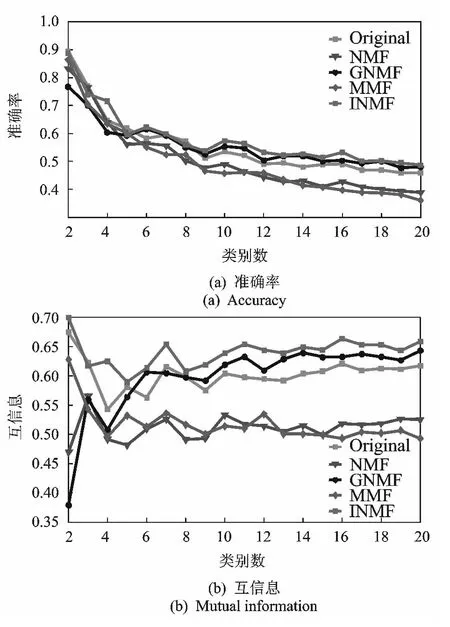
图5 AR人脸数据库实验结果Fig.5 Experimental results on the AR face data set
4 结束语
本文提出一种潜在信息约束的非负矩阵分解方法,利用迭代最近邻方法构造近邻图,可以在保证最小化重构误差的同时,使得构造的近邻图有较好的稀疏性,从而使非负矩阵分解可以在降维的过程中很好地保持原始数据的相似性关系,进而提高非负矩阵分解方法的判别能力。理论分析和实验结果表明,本文方法具有较好的精确性和有效性。然而本文方法是一种无监督方法,尚未考虑数据的先验信息。当数据有先验信息存在时,可以考虑融合先验信息和潜在信息,从而得到更合理的数据相似图,以便更加有效地提升非负矩阵分解的判别能力。
[1]Roweis S,Saul L.Nonlinear dimensionality reduction by locally linear embedding[J].Science,2000,290(5500):2323-2326.
[2]Tenenbaum J,Silva V,Langford J.A global geometric framework for nonlinear dimensionality reduction[J].Science,2000,290(5500):2319-2323.
[3]He X,Niyogi P.Locality preserving projections[C]//Advances in Neural Information Processing Systems.Whistler,British Columbia,Canada:MIT Press,2003,16:234-241.
[4]Belkin M,Niyogi P.Laplacian eigenmaps and spectral techniques for embedding and clustering[C]//Advances in Neural Information Processing Systems.Vancouver,British Columbia,Canada:MIT Press,2001,14:585-591.
[5]Guillamet D,Schiele B,Vitria J.Analyzing non-negative matrix factorization for image classification[C]//Proceedings of 16th International Conference on Pattern Recognition.Quebec,Canada:IEEE Computer Society,2002,2:116-119.
[6]Shahnaz F,Berry M,Pauca V,et al.Document clustering using nonnegative matrix factorization[J].Information Processing & Management,2006,42(2):373-386.
[7]Zhang S,Wang W,Ford J,et al.Learning from incomplete ratings using non-negative matrix factorization[C]//Proceedings of 6th SIAM Conference on Data Mining.Bethesda,MD,USA:SIAM,2006.
[8]Bucak S,Gunsel B.Video content representation by incremental non-negative matrix factorization[C]//Proceedings International Conference on Image Processing.San Autonio,Texas,USA:IEEE,2007,2:113-116.
[9]Zafeiriou S,Tefas A,Buciu I,et al.Exploiting discriminant information in nonnegative matrix factorization with application to frontal face verification[J].IEEE Transaction on Neural Networks,2006,17(3):683-695.
[10]孙健,张雄伟,曹铁勇,等.基于卷积非负矩阵分解的语音转换方法[J].数据采集与处理,2013,28(2):141-148.
Sun Jian,Zhang Xiongwei,Cao Tieyong,et al.Voice conversion based on convolutive nonnegative matrix factorization[J].Journal of Data Acquisition and Processing,2013,28(2):141-148.
[11]Li S,Hou X,Zhang H,et al.Learning spatially localized,parts-based representation[C]//Proceeding Conference on Computer Vision and Pattern Recognition.Kauai,HI,USA:IEEE Computer Society,2001,1:207-212.
[12]Hoyer P. Non-negative matrix factorization with sparseness constraints[J].The Journal of Machine Learning Research,2004,5:1457-1469.
[13]Cai D,He X,Han J,et al.Graph regularized nonnegative matrix factorization for data representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(8):1548-1560.
[14]Zhang Z,Zhao K.Low rank matrix approximation with manifold regularization[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,35(7):1717-1729.
[15]Wang J,Bensmail H,Gao X.Multiple graph regularized nonnegative matrix factorization[J].Pattern Recognition,2013,46(10):2840-2847.
[16]Timofte R,Gool L.Iterative nearest neighbors for classification and dimensionality reduction[C]//Proceedings of 16th International Conference on Computer Vision and Pettern Recognition.Providence,RI,USA:IEEE,2012,2456-2463.
[17]Lee D,Seung S.Algorithms for non-negative matrix factorization[C]//Advances in Neural Information Processing Systems. Denver, Colorado, United States:MIT Press,2000,13:556-562.
[18]Lee D,Seung S.Learning the parts of objects by non-negative matrix factorization[J].Nature,1999,401(6755):788-791.
[19]胡昭华,宋耀良.基于一种连续自编码网络的图像降维和重构[J].数据采集与处理,2010,25(3):318-323.
Hu Zhaohua,Song Yaoliang.Dimensionality reduction and image reconstruction based on continuous autoencoder network[J].Journal of Data Acquisition and Processing,2010,25(3):318-323.
[20]Yan Xuemei,Zhang Limei,Guo Wenbin.Dual-sparsity preserving projection[J].Transactions of Nanjing Aeronautics and Astronautics,2012,29(3):284-288.
[21]Plummer M,Lovasz L.Matching theory[M].North Holland,1986.
