基于多核处理器的文本并行搜索技术研究
2014-04-02,
,
(中原工学院,郑州 450007)
随着计算机硬件技术的迅速发展,计算机硬盘更新换代的频率越来越快,硬盘存储能力也越来越大,T数量级的硬盘正逐渐成为基本的配置,这为人们存储更多的数据和文件提供了有利条件。伴随着大数据时代产生的海量信息,电脑硬盘里的文件也越来越多,这给数据挖掘、敏感信息发现带来新的挑战。此外,在进行数据挖掘和敏感信息检查时,不仅仅是文件名检查,还包括文件内容的提取分析。在大的硬盘下遍历搜索所有文件的内容,如果设计的搜索算法不合理,将极大增加分析时间成本,影响数据分析的检查效果,尤其是当数据检查工作量较大时,可能成为不可承受之重。
当前多核处理器得到了广泛的应用。在单机多核的架构下, 由于单个线程在某一时刻仅能被一个处理器执行,传统的单线程串行算法不能充分有效地利用多核处理器的计算资源[1-2],只有采用并行计算的方式,才能有效利用系统资源。
本文提出了一种基于多核处理器的并行搜索技术。根据系统的CPU数量以及GPU等硬件信息,基于多核处理器技术设计并行搜索算法,结合C++AMP等最新并行编程技术,通过任务均衡调度算法,实现各线程的任务均衡,从而实现低延迟、高吞吐量和高响应度的并行计算,提高对CPU、GPU等资源的利用率,对数据信息进行高效挖掘,为数据挖掘、敏感信息发现等技术研究奠定较好的基础。
1 相关技术的应用
1.1 并行搜索
并行计算设计主要有两种方式:其一,向量化设计,主要适用于流水作业超标量处理机调度;其二,采用多线程技术进行任务分治,主要适用于多处理机及集群方式[3]。本文设计的并行搜索技术采用的就是这种多线程技术任务分治方法。
在传统意义上,GPU一直是作为图形图像专用处理器。但是,在操作系统支持下GPU也可以完成一些通用的计算任务。因此,可以将并行计算从多核CPU扩展到多核CPU与GPU共同组成的异构硬件平台上。其主要技术有两种:一种是并行异构编程OpenCL,这是众多软硬件厂商共同支持的面向异构系统的通用并行编程开放框架,技术相对成熟;另一种则是微软推出的C++ AMP(Accelerated Massive Parallelism,加速大规模并行计算)编程模型[4]。这两种框架都是底层支持的并行循环模式技术,前者更局限于对图形的处理,后者具有更好的通用性和易用性。
1.2 文本的编码方式及内容分割技术
并行搜索需要调用多个内核完成一个文本的快速匹配搜索,将待搜索的文本内容分割成若干段,以实现多个搜索步骤同时执行。在分割过程中会出现两个问题:一是如何避免将一个检索词(或称为匹配串)分到不同段落里;二是如何避免将一个字符的字节分到不同段落里。
针对问题一,本文采用冗余法。除第一段之外,其余每段的开头需要向前一个段落的末尾至少冗余读取一定长度的字节,字节的长度等于检索词(或称为匹配串)的长度。即如果一个文本里有检索词,就可以确保在某个段落里至少会有一个完整的检索词,保证能够搜索到该检索词。
问题二关系到文本的编码方式问题,因为一个字符可用不同的编码方式表示,保存在文本中的“0、1”代码不同,用的字节个数不同。文本的编码方式主要有4种,分别是ANSI、Unicode、Unicode big edian和UTF-8。字符“A”、“程”、“B”、“序”文本编码如表1所示,表中用4种编码分别表示“A”、“程”、“B”、“序”这4个字符的“0、1代码”。
ANSI编码是默认的编码方式,ANSI编码中英文字符表示使用标准ASCII编码,标准ASCII是单字节编码系统。其中第一位作为奇偶校验码,后7位总共可以表示128个字符。其他符号和汉字用GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)表示,即每一个汉字及符号用两个字节来表示。GB2312编码规定:一个字节的码值小于127,即表示此字符与标准ASCII编码表示的字符相同。针对ANSI编码,解决方法是判断一个字节的码值。如果码值小于127,则该字符是一个英文字符;否则,该字符是一个汉字或是符号的一部分。然后,再根据GB2312 编码表判断该字符是否是一个有效汉字。用此方法可避免将一个汉字(或是符号)分到不同的段落中。

表1 字符“A”“程”“B”“序”文本编码表
Unicode编码主要指的是UCS-2编码方式,即直接用两个字节表示一个字符。Unicode编码对任何字符都是采用两个字节编码。对Unicode编码分割时,采用每段分的字节个数都是2的倍数,这样就可以避免将一个字符分到不同的段落里。
从表1 可以看出,Unicode编码选用的little endian编码格式,它与Unicode big endian编码选用的big endian编码格式的高低字节刚好相反。采用与Unicode编码相同的方法分段,即可解决分段时遇到的问题二。
UTF-8编码是一种针对Unicode的可变长度字符编码,用1~4个字节编码Unicode字符。表2是UTF-8编码与Unicode编码转换规则表。

表2 UTF-8编码与Unicode编码转换规则表
从表2可以看出,如果一个字节的第一位是0,那么此UTF-8格式字符就占一个字节,并且是一个英文字符;如果一个字节的第一位是1,那么此UTF-8格式字符肯定是汉字(只有英文和中文的文档);从第二位、第三位、第四位这3个位是0还是1,可以确定此UTF-8格式字符占几个字节。如果一个字节的第一位是1,而第二位是0,则此字节是一个字符的中间字节。针对UTF-8编码,通过此方法可以避免在分割文本内容时将一个UTF-8字符分到两个段里。
2 并行搜索模型
2.1 并行循环搜索模型
异步代理库和PPL模式库将编程者引入了一种全新的并行编程模型[5],在很大程度上简化了C++开发者在CPU上编写并行程序的工作。为使C++开发者利用GPU并行编程,微软于2011年6月推出了C++AMP 异构并行编程框架,并在2012年2月的Going Native大会上发布了C++AMP的开放规范,在开发工具中正式提供了对它的支持。C++开发者可以将并行计算从单纯的多核CPU扩展到多核CPU与GPU共同组成的异构硬件平台上[4]。本文采用C++AMP中的并行循环方法——Parallel_for_each实现并行搜索。
并行循环的执行顺序是不确定的,在并行条件下各步骤的操作通常会同步进行,甚至有时候两个步骤的操作顺序会与它们在串行循环中的情况完全相反。但是可以保证的是,当循环完成时,所有的步骤都会被执行到[5]。本文的并行搜索只需要返回检索到的结果,然后对各个线程得到的结果进行整理,得出最后的结论。并行搜索对单个结果的顺序没有严格的要求,符合并行循环的特点。
并行循环一般适用于执行一些具有独立性的迭代操作,这意味着并行循环处理的多组数据之间必须具有独立性操作,它们之间不存在对本地内存或磁盘文件的共同写操作[5]。本文采取的方法是将搜索文本分割成若干段,段与段之间的操作具有独立性,且它们之间不存在对本地内存或磁盘文件的共同写操作。所以,本文的文本搜索符合并行循环模式。
本文的目的是测试并行循环搜索模型与多线程并行搜索模型的性能,所以,分割段数分别是处理器个数的1倍、2倍和3倍(针对2核计算机,为了作比较,4核计算机是1/2倍、1倍和2倍)。用分割段初始化数组vc,数组vc中有多少个元素,就有多少个线程来并行执行该搜索任务,这些线程会同时调用多个处理器来完成搜索任务,达到快速搜索的目的。
并行循环搜索算法描述如下:
①根据分割情况建立数组vc,即将每段作为vc的一个元素;
②并行循环搜索
parallel_for_each(
vc.extent;
[&](index<1> idx) restrict(amp)
{
Thread_Strindex_BF(idx,vc,ntemp,flag);
}
);
参数说明:
第一个参数是vc.extent,用于描述并行搜索拓扑结构的对象,vc中有多少个元素,就可以指定多少个线程并行执行这个搜索任务;
第二个参数是一个lambda表达式。Thread_Strindex_BF是匹配搜索函数,每一个并行的搜索线程都会执行这个函数。参数idx是线程编号,参数vc是被匹配段,ntemp是每个段落中的字节个数,flag是检索词(或称匹配串)。从被匹配串的第1个字节开始找第一个与flag相等的子串,直至每个段的最后一个字节为止,成功,返回“1”,否则,返回“0”。
2.2 多线程并行模式
多线程并行模式是指运行程序创建多个并行执行的线程来完成各自的任务。在多线程程序中,当一个线程必须等待时,CPU 可以运行其他线程而不用等待,大大提高了程序效率。但是,并不是开的线程数越多,搜索的速度就会越快,因为线程之间的切换也需要花费时间,所以开线程需要考虑到它的综合性能,可以开与处理器个数相等的线程数,这样每个CPU上运行一个线程,不用来回切换,充分利用每个处理器资源。如果计算机采用的是超线程,即一个CPU上运行两个线程,开的线程数可以是处理器个数的两倍。为了测试两种并行搜索的性能,开的线程数与并行循环搜索模型的线程数相同。多线程并行搜索模型如图1所示。
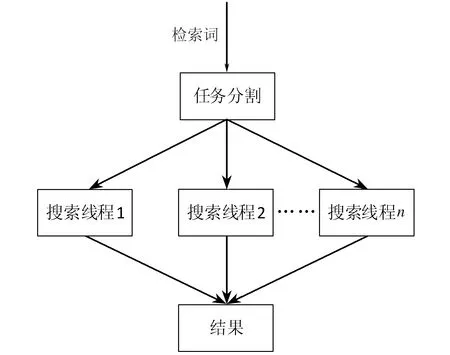
图1 多线程并行搜索模型
多线程并行搜索模型先通过任务分割技术将文本内容分割成n个段,根据分割后的段和搜索函数创建n个线程,开启并执行这些线程,得到各个线程运行结果,然后整理得出最后的结论。
3 实验结果与分析
本文主要研究异构并行计算循环搜索模型与多线程搜索模型的不同性能,为基于多核处理器的并行搜索技术找到更好的搜索模型,因此有必要对这两种并行搜索模型的实验结果进行分析比较。
3.1 实验环境
采用两核电脑1台,电脑配置型号:Intel(R) Core(TM)2 Duo;CPU:E4600 @2.40GHz;内存:4GB;操作系统:windows7 32位。
采用四核8线程电脑1台,电脑配置型号:Intel(R) Core(TM)i7;CPU:870 @2.93GHz;内存:8GB;操作系统:windows7 64位。
3.2 结果分析
通过在两核处理器和四核处理器的计算机上对同一个文件不同线程进行测试,得到不同的测试结果,如图2和图3所示。
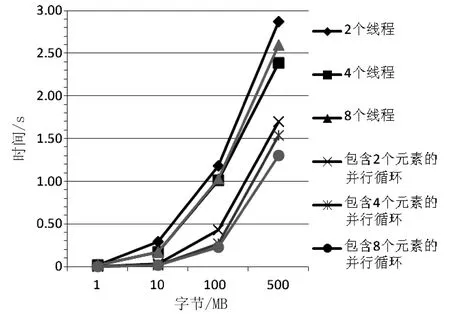
图2 两核处理器计算机对同一文件不同线程测试结果
从图2可以看出,在两核处理器计算机上并行循环搜索的速度优于多线程搜索速度,多线程搜索模型中4个线程比2个线程的速度要快,而8个线程的速度介于2个线程和4个线程之间。这说明并不是并行的线程数越多,速度就会越快。要根据处理器的数量,合理创建并行线程数。并行循环搜索模型与多线程搜索模型比较,有稍许变化,8个元素的并行循环不比4个元素的并行循环速度慢,但是搜索速度提高非常小。按此规律推断,随着并行元素数量的增加,搜索速度同样不会提高反而会降低。在这一点上,两者的特点是相同的。在500 MB的搜索范围内,并行循环搜索的3个模型之间的差别没有多线程搜索模型明显,这说明并行循环搜索模型在这个范围内的速度都很快,也说明并行循环搜索模型优于多线程搜索模型。
由图3可知,四核计算机与两核计算机相比,情况基本类似。总体而言,并行循环的搜索速度优越,而且在四核计算机上运行时,多线程搜索模型中的2个线程的搜索速度几乎没有什么变化,4个线程和8个线程的搜索速度则得到了提高。与图2相比,变化最明显的是8个线程的搜索速度比4个线程的搜索速度快。这说明需要合理创建并行线程数,才能得到较好的性能。
总体来说,不管是在两核处理器电脑上还是在四核处理器电脑上,并行循环搜索模式都比多线程搜索模式搜索的速度优越,也说明将C++AMP异构并行编程运用于文本内容的搜索,可提高搜索性能,并且在某种程度上是优于多线程搜索的。
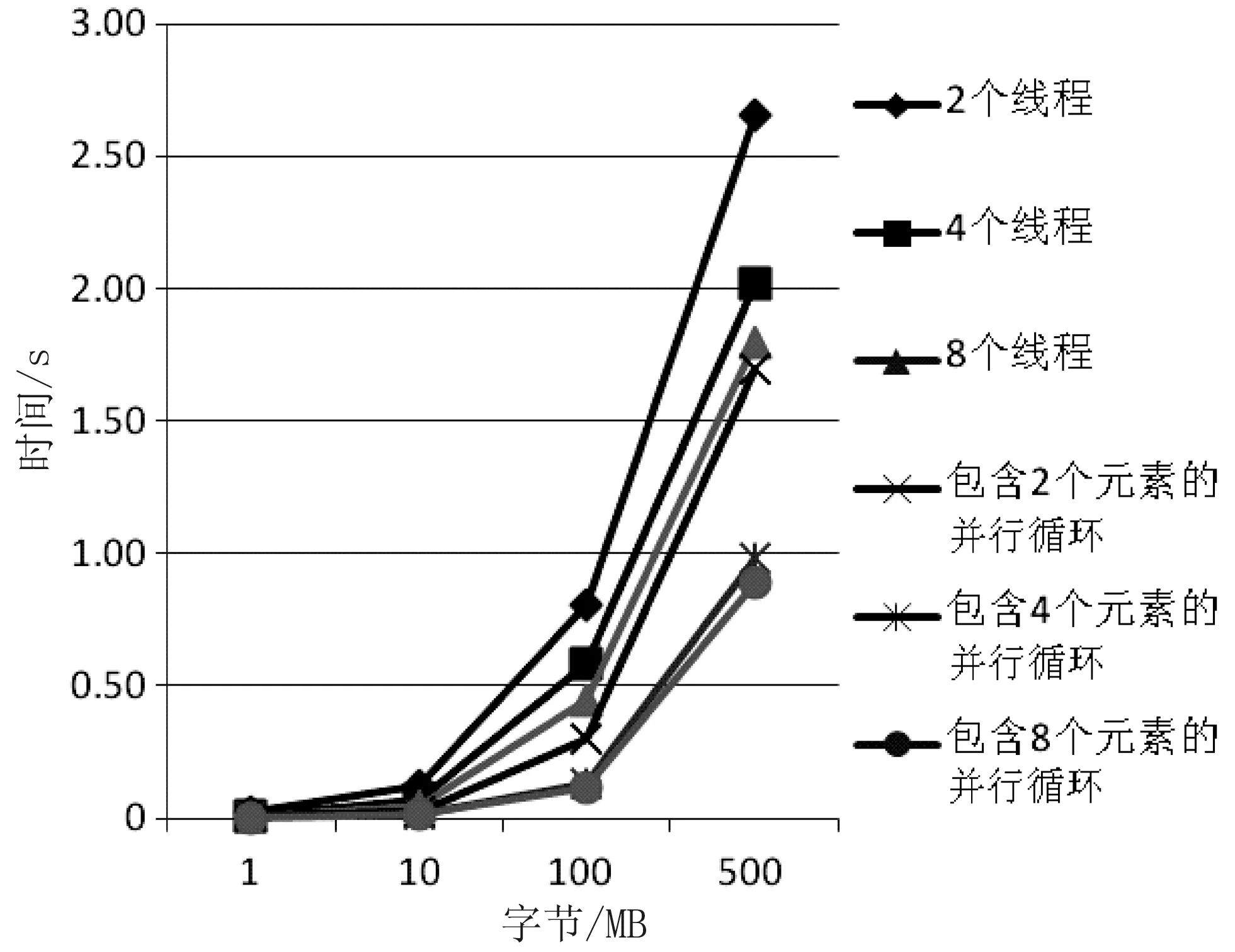
图3 四核处理器计算机对同一文件不同线程测试结果
4 结 语
本文利用多核处理器平台的处理性能,通过并行循环搜索模式和多线程并行搜索模式,使得文本内容搜索速度得到提升。对解决大容量硬盘、大数据的海量信息搜索奠定了很好的基础,有利于数据挖掘和敏感信息等技术的研究。随着多核处理器的快速发展,基于多核处理器的文本内容搜索技术研究会有重要的意义,本文的研究顺应多核技术发展的趋势。有些厂商正尝试将GPU和CPU融合在一起,如果将来的处理器上集成了GPU和CPU,并且可以通过一条总线将二者与内存直接连在一起,本文的研究会有更大的价值。
参考文献:
[1] Knuth D E, Morris J H, Pratt V R.Fast Patternmatching in Strings[J].SIAM Journal of Computing,1997, 6(2):323-350.
[2] 伊君翰.基于多核处理器的并行编程模型[J].计算机工程,2009, 35(8):62-64.
[3] 陈国良.并行算法的设计和分析[M].北京:高等教育出版社,2009:16-26.
[4] 陈冠诚.C++ AMP异构并行编程解析[J].程序员,2012(4):30-34.
[5] Colin C, Ade M.Visual C++并行编程实战[M].凌杰,译.北京:机械工业出版社,2012:22-26.
