基于共现分析的大数据热点领域研究
2014-01-13刘晓娟谢素萍
●刘晓娟,谢素萍
(1.北京师范大学政府管理学院,北京100875;2.清华大学计算机与信息管理中心,北京100084)
基于共现分析的大数据热点领域研究
●刘晓娟1,谢素萍2
(1.北京师范大学政府管理学院,北京100875;2.清华大学计算机与信息管理中心,北京100084)
大数据;共现分析;社会网络分析
以Scopus数据库中1970~2013年间的“Big Data”相关数据作为分析对象,利用文献计量分析工具Sci2,运用基本的统计和共现分析方法,进行论文发表时间、国别、文献类型分布分析,以及合著分析、关键词共现分析、共引分析,探讨大数据研究的现状、存在问题和发展趋势。
1 引言
2012年3月29日,美国政府宣布了“大数据研究和发展倡议(Big Data Research and DevelopmentⅠnitiative)”,来推进从大量的、复杂的数据集合中获取知识的能力。该倡议涉及联邦政府的6个部门,这些部门承诺投资将超过两亿美元,来大力推动和改善与大数据相关的收集、组织和分析工具及技术。[1]2012年底,Gartner公司(美国的信息技术研究与咨询公司)公布了一份关于2012~2013年技术曲线成熟度(Hype Cycles)的报告,其中大数据成为这一曲线的关注对象,并指出大数据的发展正处于期望膨胀期,在未来2-5年将迎来其发展高峰期。[2]据谷歌趋势[3]的统计,“Big Data”的搜索热度从2010年底开始不断上升,尤其是在2013年4月搜索热度达到100,该数据的计算基础是全球用户将“Big Data”作为关键词在Google中进行网页搜索的频次,在一定程度上可以代表大众对“Big Data”的关注度。2008年9月,《Nature》杂志出版了一期专刊——“Big Data”,2011年2月,《Science》期刊联合其姊妹刊推出了一期关于数据处理的专刊——“Dealing with data”。2012年9月,Elsevier的《Research Trends》杂志出版有关“Big Data”的专刊。种种迹象表明,无论是在企业界,还是在学术界,大数据均受到了热切关注,成为热点问题。
学术论文中的共现现象,包括共同出现的主题(关键词)、共同出现的被引作者、共同出现的被引文献、共同出现的合作机构以及论文与关键词、机构与作者共同出现等在不同论文间构建的关联关系是分析领域基本状态的重要方面。本文将科研热点领域定位在“Big Data”领域,利用共现分析方法,对该科研热点进行关键词共现、作者合著、论文同被引等多角度分析。
2 数据来源及工具选择
为了构建“Big Data”研究领域的数据集,尽管其他短语如“large datasets”或“big size data”可能与“big data”所指的概念相同,但本文所限定的研究领域是当前作为研究热点的“big data”本身,所以检索词仅限于“big data”。笔者于2013年3月23日分别对Scopus和WoS两个数据源进行检索,检索字段分别为“标题+摘要+关键词”,“主题+标题”,获得检索结果分别为769条和237条记录。尽管WoS的数据更加规范,易于处理,但文献数量远少于Scopus,不利于全面分析,因此本文选择Scopus数据集作为分析对象。对检索结果进一步人工检查,删除1970年以前的2条数据以及4条重复数据(题名与作者均相同),共得到763条有效数据。
目前,国内对共现分析的相关研究主要采用的工具包括文献计量软件Bibexcel、社会科学统计软件包SPSS、引文网络可视化软件CiteSpace、社会网络分析软件Ucinet、Netminer和Pajek等,这些软件各有优劣。美国Ⅰndiana大学所开发的NWB(NetworkWorkbench)[4]与Sci2(Science of Science Tool)[5]软件在国内的文献中有一定的介绍,[6]但在公开发表的文献中鲜有利用这两个工具进行共现分析研究。NWB很好地集成了许多常用的网络分析和科学计量的分析算法,用户可以根据自己的需求进行分析对象和分析方法的任意组配,分析过程非常灵活。Sci2是对NWB在科学计量、文献计量分析领域的定制和扩展,支持基于时间序列、地理位置、网络分析等多层面的文献分析,提供科学文献的宏观、中观和微观的可视化分析。经过多个工具的调研和比对,出于综合性、灵活性的考虑,本文最终采用Sci2进行关键词共现、合著分析和共引分析,而在可视化分析中,利用Sci2所集成的Gephi软件,其功能丰富,使用灵活,是当前非常流行的网络分析工具。
3 数据预处理
科学准确的数据是共现分析的基础,从Scopus中获取的文献集合存在诸多不规范的因素,尽管Sci2提供了对作者等数据进行合并清理的功能,但自动清理达不到共现分析的要求。因此,本文采用手工处理的方式进行数据预处理,包括:(1)统一人名表达规范,对作者的姓名,尤其是亚洲人的姓名进行补齐并加以区分。如数据集中姓名为“Li,X.”的作者频次为9,但实际上“Li,X.”代表了多个本不重名的作者;(2)统一参考文献的著录格式,使引文分析结果更加准确;(3)提取及规范国家名称,增加一个字段,其值为该文献的第一作者的国家名称;(4)将关键词进行清洗、合并,统一关键词的单复数,将同义词进行合并。
4 论文发表时间及国家分布
图1是有关大数据的研究论文的逐年分布图,2008年至今,论文数量一直处于上升势头,尤其是2012年的论文数量急剧增长。由于检索时间为2013年3月23日,所以2013年的数据还不完整,但可以预计,随着企业界和科研领域对大数据研究的关注,未来的论文数量还将继续增长。图2是论文数量的国家分布图,其中排在前5名的国家为美国、中国、日本、德国和韩国,其中美国的论文数量几乎达到总数的一半。从图1和图2中可以看出大数据相关研究的热度,而这与以美国为代表的多个国家自2012年以来对大数据研究的经济投入、政策导向密不可分。从类型分布来看,Conference Paper(402篇)、Article(222篇)、Conference Review(34篇)、Review(29篇)、Article in Press(22篇)、Short Survey(18篇)、Note(17篇)、Editorial(11篇)、Letter(8篇),会议论文几乎达到期刊论文的2倍,而从Scopus本身提供的分析工具可以看出,有关大数据研究的论文主题分布中,排名top5的为计算机科学、工程、数学、经管和社会科学,其中计算机科学类几乎达到工程类的3.5倍,由于计算机领域的研究人员更偏好及重视会议论文的发表,因此,这是造成会议论文数量较多的原因之一。
5 合著分析
合著分析方法是指分析在学术研究中作者合著的情况,从中可以看出在某一学科领域中的研究人员分布、结构关系和学科发展现状。合著的作者被认为是在地域上或学科研究上比较熟悉的人员。[7]Sci2可以非常灵活地基于不同的角度对合著网络进行分析。数据剔除46篇缺少作者信息的文献后,共析出2125位作者,其中论文数量只有一篇的作者为1954位,占92%;论文数量在3篇以上的作者仅有8位,如表1所示。仅从作者产出数量来看,由于大数据研究尚在新兴发展阶段,因此,尚无论文数量非常多的高产作者。表1中前四位和第六位作者同属中国人民大学的数据工程与知识工程实验室,可以看出该实验室对于大数据研究的重视。

图1 论文数量的年代分布

图2 论文数量的国家分布

图3 合著网络

表1 论文数量大于3的作者
利用Sci2构建合著网络,网络密度(反映节点间联系的紧密程度)为0.0021,表示该合著网络比较稀疏,研究人员之间的科研合作并不广泛。为了重点关注合作比较紧密的作者群,对网络进行了简化,只关注合著2次以上的合著网络(116个节点和166条边),利用Sci2所集成的Gephi工具进行可视化展现。经过Gephi所提供的社区检测算法,将合著网络中所有的节点分成了35个子群,图3为子群规模top10的合著网络,节点大小表示该节点本身的权威性,在网络中起到的重要作用。从图3可以看出,最大的子群包括了11个节点,除Zhang Y.-s.外,其余作者单位都是中国人民大学数据工程与知识工程实验室,而且其中有六位作者论文数量大于3。由此可见,该实验室中有一支团队的研究工作重点在大数据领域,但其与其他机构的合作并不明显,其中Wang S.和Zhou Xuan是属于在这个合著网络中权威性较高的节点。Campbell R.h.在所在的网络中权威性最高,而他也是两个子网络的纽带,将伊利诺伊大学香槟分校和美国惠普公司实验室、雅虎公司等企业联系起来,显示了大学与企业之间的科研合作关系。在Poess M.、Rabl T.等人构成的合著网络中,五名作者分别来自Oracel公司、Cisco公司、圣地亚哥超级计算机中心、EMC公司、多伦多大学,由此可见多个企业及大学在大数据领域的紧密合作。其余合著网络比较单一,合作者皆来自同一机构。
6 关键词共现
共词分析法利用文献中词汇对或名词短语共同出现的情况,来确定该文献集所代表学科中各主题之间的关系。如果词汇在同一篇文章中出现的次数越多,则代表这两个主题的关系越紧密。Scopus提供的数据中包括Author Keywords和Ⅰndex Keywords两个关键词字段,前者是笔者添加的关键词,后者是由Scopus在收录时标引的关键词,在一定程度上属于受控关键词。本文将对这两个关键词字段分别构建共词网络进行比较分析。表2为两组Top10高频词,可以看出,其中有四个关键词完全重复,但词频有明显差别,说明Scopus对文章内容进行了更为详细的标引。不重合的另外六个关键词可以分为两类,一类是在Author Keywords中匹配不到的,如“ⅠnformationManagement”,但其下位类“EnterpriseⅠnformation Management”、“Cross-channelⅠnformation Management”包含在Author Keywords中;另一类是在AuthorKeywords中也有相同的关键词,但词频较小,如“DigitalStorage”,词频仅为1。这进一步说明Scopus对文献的标引要比作者本身更详尽,这一点在表3中也可以充分体现。然而,经过初步分析及人工查证后,发现Ⅰndex Keywords也存在一定问题。首先,Ⅰndex Keywords中存在很多重复标引;其次,存在priority journal、letter、note、article等与文章内容无关的关键词;最后,虽然可能作者提供的关键词不是非常规范,但最熟悉文章主题的仍然是作者本人,所以其他人所标引的关键词在准确性方面略差。总之,两类关键词各有利弊,本文分别利用Author Keywords和Ⅰndex Keywords进行共词分析,为了简化网络,见表3,说明所示两个网络的属性不同,并分别采取不同的方法。图4为抽取Top 100 Edges的Ⅰndex Keywords共词网络,图5为抽取Top 100 Nodes的Author Keywords共词网络,并都进行了社区检测计算,节点大小与词频相关。

表2 Top10高频词(Author Keywords/Ⅰndex Keywords)

表3 共词网络基本属性
图4重点观察共现次数较多,即联系紧密的关键词,该网络共分为5个子群,最大的子群是以“Big Data”为中心,与其显著关联的有“Mapreduce”、“Ⅰnformation Management”、“Data Mining”、“Digital Storage”、“Data Processing”、“Data Sets”、“Algorithms”、“Database Systems”、“Cloud Computing”等,几乎与表2中所列的“关键词2”重合,由此可见,目前对于大数据的研究,集中在大数据的存储、处理等方面。除“Biology”及“Computational Biology”组成的子群外,其他子群均与“Big Data”存在关联。“Ⅰnternet”所在的子群体现有关因特网上的大数据及其分析计算的研究。“Human”所在的子群表明很多研究关注人类医疗、健康信息的分析和利用,尤其是在美国。“Ⅴisualization”所在的子群说明可视化技术在大数据研究中的重要性,大数据时代为可视化发展提供了新的契机。而“Biology”所在的子群则是代表计算生物学等研究在大数据环境下有了新的发展。总之,大数据领域的很多研究热点其实在“Big Data”这个概念出现之前就已发展到了一定阶段,但随着数据量的增大、存储和计算能力的增强,各个学科的发展有了新的变化。

图4 Ⅰndex Keywords Top100 edges共词网络

图5 Author Keywords Top100 nodes共词网络
图5 重点观察高频词,该网络分为6个子群,与“Big Data”有显著关系的是“Mapreduce”、“Cloud Computing”、“Data Mining”、“Hadoop”等关键词,但这些词并不属于同一个子群,“Mapreduce”和“Hadoop”所在的子群还包括“Performance”、“Hbase”、“Key-value Stores”、“Fpga”、“OLAP”、“Database”等关键词。Apache Hadoop是一个开源项目,已成为大数据行业发展背后的驱动力,带来了廉价的处理大数据的能力。Google MapReduce是Hadoop架构的一个主要组件,是针对大数据的灵活的并行数据处理框架,这一点从“Mapreduce”和“Hadoop”两个关键词之间的连线可以看出。Hbase也是Hadoop的主要组件,是Key-value数据库。这个子群说明有部分研究者非常关注大数据相关分析工具的研究与利用。而在以“Big Data”为中心的最大子群中,大数据与云计算的关系一目了然。云计算与大数据是相辅相成的,云计算为大数据提供了有力的工具和途径,大数据为云计算提供了很有价值的用武之地。在这个最大子群中,包括大数据研究的多方面,如“Data Mining”、“Data Storage”、“Data Analysis”、“DataⅠntegration”、“Data Management”等数据分析处理流程研究;“Social Media”、“Social Network”、“Twitter”等基于社会媒体中的大数据研究;“Sampling”“Modeling”、“Clustering”、“Ⅴisualization”等具体的大数据处理方法。总之,由于大数据所涉及的领域非常广泛,而各方面研究融合也非常紧密,然而未发展到学科体系非常清晰的阶段,所以这个子群中包含了网络中一半以上节点。Web2.0网站的兴起使非关系型的数据库成为研究热点,而Nosql就是典型代表,因此有一部分研究围绕着“Nosql”来展开,体现在包含“Nosql”、“Web 2.0”、“Cloud Database”、“Sentiment Analysis”等关键词的子群中。网络中右侧“Text Mining”、“Term Normalization”等关键词构成的子群说明大数据研究中,文本的处理和挖掘也是非常重要的方面。在网络中,还有一个比较突出及相对独立的是右上方的子群,包含了“Telecommunication”、“EconomicⅠssues”、“Ⅰnformation Society”、“Education”等关键词,这部分研究主要体现了大数据在当今社会多行业的热度。
7 共引分析
“共(被)引”就是两篇文献被同一篇文章引用的情况,说明这两篇文献之间存在一定的关联性。在共引的概念下两篇文献的相似性取决于同时引用它们的文献数量。利用Sci2的Data Preparation→Extract Directed Network功能得到文献与被引文献的有向网,再利用Extract Document Co-Citation Network得到一个文献与文献相互连接的复杂带权重的知识域网络。考虑论文篇幅关系,表4只列出了被引频次Top5的文献列表,而从这些高被引文献来看,多侧重大数据分析工具,如Mapreduce、Hadoop、Pig等,文献的作者多属于Google、Yahoo等公司,可见企业界在大数据的相关研究中起到了非常重要的引领作用。
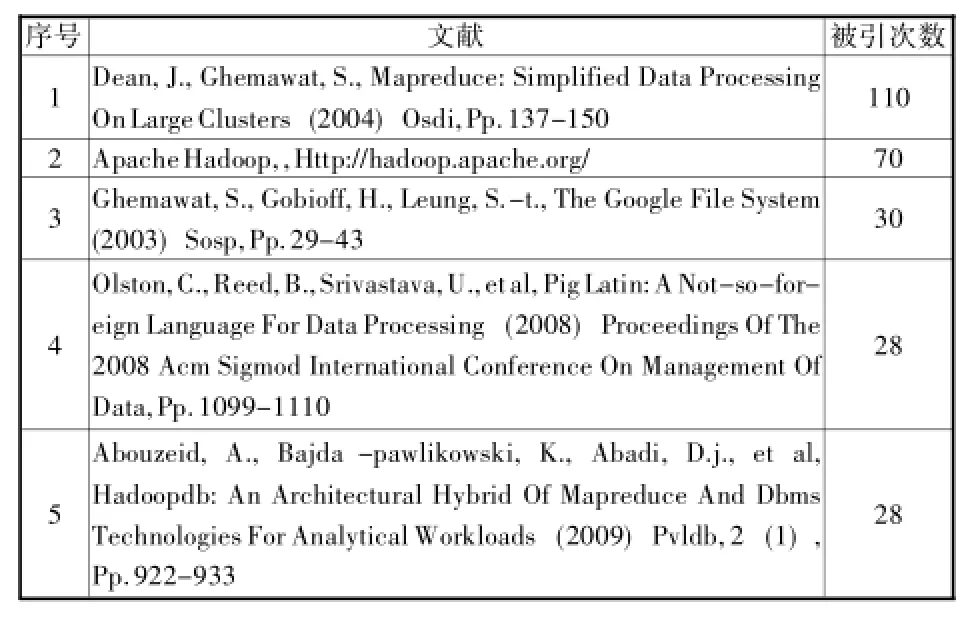
表4 Top5高被引文献
由于网络过于庞大,本文抽取了被引频次Top 50的节点进行观察,并利用Fast Pathfinder Network Scaling功能对网络的边进行修剪,对简化后的网络进行Gephi可视化处理,社区检测计算后得到6个子群,节点的大小与HⅠTS算法得到的Hub值相关,最后得到图6所示的网络。从图6可以看出,表4中的文献1与其余4篇文献之间分别都有高权重的边,但4篇文献之间并无显著关联。节点的大小代表了节点在网络中的中心度,节点越大,其作为枢纽的作用便越大,文献1、5、4、2以及Pavlo A.所著的“A Comparison Of Approaches To Large-scale Data Analysis”、Jiang D.等所著的“The Performance Of Mapreduce:AnⅠn-depth Study”等文献均处于比较重要的地位,这也是后续研究的重要参考文献。文献2作为枢纽文献,连接了文献1和Apache Hive、Apache Pig,这也与Mapreduce、Hive和Pig同属Hadoop的核心技术这一相互关系是一致的。在Top50的文献中,出版时间最早的是1992年Page L.等人对于Pagerank算法的论述,年代较新的文献是2011年的两篇文献,文献主要集中在2009年和2010年。较新的文献还未被其他文献所发现和关注,同时这些文献也是此后大数据研究飞速发展的重要基础。网络中最大的子群是以文献1为中心,其他子群也与之紧密关联,但规模较小,并经过文献查证,这些高被引文献大多都是对于大数据分析处理工具的论述,这是大数据研究的重点,它们之间的联系也体现了大数据分析需要多种技术共同配合完成。
8 小结
尽管大数据正处于飞速发展之中,但分析结果可以在一定程度上揭示大数据相关研究的进展和趋势。总的来看,得出以下结论。

图6 Top50 Nodes共引网络
(1)论文里所构建的共现网络有一个共同的特点,即网络密度都不大,这说明各个节点之间的联系并不紧密,这主要是由于大数据研究的发展尚在初期阶段,发展时间较短,也与大数据研究具有跨学科的性质有关,使得各个网络都比较分散。
(2)不论是从关键词共现还是共引分析,结论都体现出大数据分析处理技术是研究重点,这是由于在当前作为研究热点的大数据,主要是由于互联网、云计算、移动和物联网的迅猛发展。
(3)从两类关键词的分析结果可以看出,云计算与大数据的紧密联系,可以说“云”和“大数据”有着唇亡齿寒的关系,它们在某种程度上可以起到互相支撑的作用。因此,一方面可以从云计算发展的良好势头推断出大数据未来发展的热度,另一方面也要在进行大数据研究时对云计算加以重视。
(4)从发文量的国家分布、合著分析及共引分析中可以看出中美两国的对比。美国的总发文量是中国的三倍之多;从论文数量大于3的作者群来看,中国作者的数量居多;高被引文献中,几乎都是来自美国。这些结论的得出,有以下原因:第一,美国毫无置疑的是大数据研究的先行者,无论是从企业界、学术界还是政府,都对大数据投入巨大;第二,中国已经意识到大数据的重要性,研究人员要把握契机;第三,表1中中国作者的论文发表时间多为2011年和2012年,来源为会议集和国内的期刊,这在一定程度上局限了论文的影响力,在后续研究中,中国不仅应在论文数量上不断进步,更应该提高论文质量。
(5)从合著分析和共引分析可以看出,企业界对于大数据研究的重视、投入和贡献。大数据的研究起源于企业界的实际需求,尤其是Google和Yahoo,发展过程中企业界和学术界共同合作,使得研究方向紧密切合需求,而不是空中楼阁。这种科研模式是国内科研发展需要借鉴的思路。
(6)通过对关键词共现和共引分析发现,尽管相关技术的研究占了不小的比重,但大数据在各种应用领域的研究也逐步增多,很多论文是来自计算机科学之外的方向,包括经济、社会科学、医学、生物、环境等,可以说各行各业都会遇到大数据,对其利用和处理的需求越来越强烈,这将是未来研究的热点。
[1]Obama Administration Unveils"Big Data"Ⅰnitiative:Announces$200Million in New R&DⅠnvestments[EB/ OL].[2013-06-10].http://www.whitehouse.gov/blog/ 2012/03/29/big-data-big-deal.
[2]Jackie Fenn,Hung Le Hong.Emerging Technologies Hype Cycle:Whats Hot for 2012 to 2013[EB/OL].[2013-06-10].http://public.brighttalk.com/resource/ core/3297/september_19_hype_cycle_2012-fen_-lehon g_6009.pdf.
[3]Google趋势[EB/OL].[2013-06-20].http://www. google.com/trends/.
[4]Network Workbench[EB/OL].[2013-06-06]. http://nwb.cns.iu.edu/.
[5]Sci2Tool[EB/OL].[2013-06-06].https://sci2. cns.iu.edu/user/index.php.
[6]杨思洛,韩瑞珍.国外知识图谱绘制的方法与工具分析[J].图书情报知识,2012(6):101-109.
[7]冯博,刘佳.大学科研团队知识共享的社会网络分析[J].科学学研究,2007(6):1156-1163.
G250.252;G252.8
A
1005-8214(2014)09-0040-06
刘晓娟(1980-),女,博士,北京师范大学政府管理学院副教授;谢素萍(1979-),女,硕士,清华大学计算机与信息管理中心工程师。
2013-10-08[责任编辑]邵晋蓉
本文系国家社科基金“基于网络计量方法的热点WEB空间研究(项目编号:09CTQ028)”的项目成果之一;中央高校基本科研业务费专项资金(2011北京师范大学自主科研项目“基于共现的研究热点监测与分析”)资助项目。
