基于分段散列的服务命名研究
2013-12-14赵国锋贾雯轩
赵国锋,贾雯轩
(重庆邮电大学未来网络研究中心,重庆400065)
0 引言
域名系统(domain name system,DNS)和IP地址是当前网络仅有的2个命名空间[1],并且IP地址同时代表位置(locator)和身份(identifier),使得IP语义超载,限制了很多网络新功能的使用,如移动性、多宿主等。当前网络是一个以IP为传输核心的架构,用户需要找到某个服务或者数据,必须要先将DNS域名转化为IP,再进行寻址查找,一旦IP改变,传输就会中断,并没有一种对服务本身进行查找的方法。现在有很多研究学者都提出对当前网络进行改革,主要分为“革命式”和“演进式”,演进式主要是以一种不断打补丁的方式对当前网络进行“修补”,并没有从根本上对网络架构进行改革。这种方式只是治标不治本,可能会缓解一时之急,但是不能作为长期的策略。要采用革命式的方式来改革网络架构才能从根本上解决移动性、扩展性、多宿主和流量控制等问题。而用户对网络的需求是对网络上服务的需求,用户关心的是服务的内容而不是服务的位置,所以,本文提出的是一种以服务为核心,面向服务的网络,是一种“革命式”的发展模式,将重点转移到服务的内容。
1 服务ID
本文认同 NDN[2](named data networking)思想,认为每一片服务都有自己的名字,并针对服务对服务的identity进行命名。本文是基于身份位置相分离,得到的服务名字和服务位置是一种对应关系,有一个名字位置对(pair),SID:locator。这意味着,每一个服务ID(SID)至少有一个locator与之对应。locator只用于路由,而identifier只在应用层负责对服务身份的判断,不再与locator绑定用于路由。将服务的identifier与locator分离,服务的identifier是不会随着服务迁移后的位置的变化而改变,通信不会发生中断,可很好地解决移动性问题。
当基于身份位置相分离来介绍未来因特网架构,identifier必须满足一些要求。以下是根据ITU[3](International Telecommunications Union)的提议总结的一些通常的要求:
1)服务的名字可以与多个服务位置相关联并且不随位置变化而变化;
2)服务的名字是在应用层;
3)与服务名字有关的session不会因为服务位置的变动而中断;
4)服务的名字在一个指定范围内是全球唯一的。
用户对名字的关心问题有3点不变性、可达性和可信性。不变性是指不管服务迁移到任何地方,服务的名字始终唯一;可达性是指即使网络和服务失败名字的内容或者服务也达;可信性是指用户不考虑内容在哪儿,但是希望内容是可信的。
在未来网络架构中,服务命名基于以上设计原则和用户所关心的问题,提出名字由两部分组成,服务属性和服务提供商。其中服务的属性是一个六元组,S=<N,V,Ts,Te,P,M >,分别由字母和数字组成。N为服务的名字,是对服务的描述性名字,不需要唯一,可以同一个名字对应多个服务,也可以一个服务对应多个描述名字;V为服务的版本号;Ts为服务发布时间;Te为服务的有效时间,在这个时间内服务是可用的,过了有效时间,则需要重新发布或者更新服务;P为服务的私有性,表示该服务是否属于私有,是否允许访问;M表示是否允许迁移,因为有些服务虽然不是私有,但是也不允许迁移,所以,需要将私有性和可迁移性区别对待。这些属性都是由服务提供商来确定的,在这里,统称为服务属性。
在服务名字中,服务提供商(SISP)由字母和数字组成,最终被Hash为一个64位的数。服务属性也同样是被分段Hash为一个64位的值。这2部分的64位值再组合,就得到了最终的128位的UID(unique identifier),这是一个全球唯一的服务ID。保证了服务SID的全球唯一性。N属性和SISP之间的关系为一个SISP可以提供多个N属性;一个N属性也可以是由多个SISP提供的。
例子:news/text/2011.4/2.0/describe/… #sina
2 哈希选择
对于每一个唯一的服务都有一个唯一的标识,就像每个人都有自己唯一的指纹一样。为了避免重复存储同一个服务,每当新发布一个服务时,新服务在Hash表中就会有相应的记录,以表示这些已经发布的服务,但是若是在Hash表中,直接以字符串的形式存储,既费内存又费查找时间,因为服务的ID字符串是不定长的。若要存储200亿个服务信息本身至少需要2 TB,即为2 000 GB的容量,而哈希表的存储效率一般只为50%,那也就是需要4TB以上的空间,并且就算把这些服务全部存储在计算机内存中,由于服务字符串长度的不固定,以字符串形式来进行查找效率会很低。所以,本文使用一个Hash函数,将服务ID的每一部分随机的映射为一个64位二进制,即8个字节的整数空间,服务的两段标识总共需要128位16字节的整数空间,这样大大地节省了存储服务信息所需要的存储空间,也足以存储互联网上的服务,这128位二进制就相当于服务ID的指纹[4]。只要选择的Hash函数足够好,就可以保证不会产生2个相同的服务ID指纹避免冲突。当一个服务发布到该注册中心时,先在Hash表中查找是否有这个服务对应的服务ID指纹,来决定是否要发布这个服务。对Hash之后的值查找的速度要比直接对字符串查找的速度快几倍到几十倍。
本文选用的是MURMUR哈希函数,该函数生成的结果为64位,并且分布很平均,可以减少冲突概率。本文结合结构化P2P网络信息搜索方式来进行名字与位置关系搜索,利用chord[5]算法来实现对注册中心之间的搜索,而每一个注册中心内部都是一个服务器集群,每个服务器上我们设定只存储10亿的数据,那么只需要保证在10亿的数据内SID得到的哈希值没有冲突就可以了。
对服务名字字符串采用分段哈希,将服务属性和服务提供商分别哈希为64位的哈希值,将服务提供商的64位哈希值经过取模(mod)运算得到的值作为判断存储在chord节点的哪个节点上,将服务属性的64位哈希值作为判断存在注册中心内部哪个具体的服务器上。这样的好处是在服务名字和提供商的内部进行分段Hash,存储时更有利于将相类似的服务存储在一起,方便查找,同时也进一步降低了Hash冲突的概率。
图1是将服务名字分段哈希的示意图,将服务的属性部分和服务提供商部分分别进行哈希处理,最终得到一个唯一的ID值。
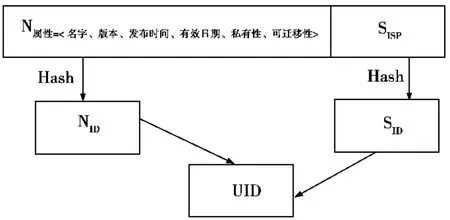
图1 SID哈希生成UID Fig.1 Hash SID to UID
3 位数验证
服务ID由服务名字和服务提供商这2部分组成。这2部分分别由Hash函数进行Hash,每一部分得到64位的Hash值,两者结合生成一个总长度为128位的Hash值。位数的确定是基于2个不可反驳的事实:服务信息总量不会超过存储总量,服务提供商的数量不会超过人口的数量。所以,就目前所有的信息总的来说,算上数字存储设备和模拟存储设备。以目前人类的技术可以存储至少295艾字节(exabytes)的信息,这个数字相当于1后面有20个零。
对于服务名称,设一个服务的大小1 bit,设服务总数量为M,设总存储容量为S,S=295艾字节,则有

实际上一个服务的大小远大于1 bit,则

所以,M< <265,服务总数量远小于264,服务名字也远小于264。
对于服务提供商,设服务提供商有N个,总人口数量为70亿,

所以,服务提供商的数量是绝对远小于264这么多的。
本文采用极值的推算法,如果一个服务只占1 bit的话,264可以表示18 446 744 073 709 552 000这么多个服务,这个18 446 744 073 709 552 000 bit几乎是全球所有的服务器的存储容量的总和,并且服务不可能只占1 bit,所以,服务的数量是肯定比264少,那么,服务的名称也不会比服务的数量多。所以,64位用来存储服务的名字是绝对足够的。对于服务提供商而言,如果说如果地球上有100亿的人口(实际上人口不足70亿),那么每个人都可以同时作为1 844 674 407这么多个ISP,这是不现实的,因为ISP的数量是绝对比人口的数量少的,不可能每个人都是一个ISP,更不可能每个人同时作为1844674407这么大数量的ISP,所以,64位的空间对ISP来说是绰绰有余的。所以,可以证明,分别用64位来表示服务的名字和服务提供商的数量是绝对足够的。
4 Hash函数碰撞
生日悖论,至少需要多少人,才能保证至少有2个人同一天生日的概率大于1/2?
设S为有S个元素的集合,从S中随机选取一个的选法有1/S种,再选第2个和第1个冲突的概率为1/S,再选第3个和前2个冲突的概率为2/S,从S中选取第r个元素和之前的元素相同的概率为(r-1)/S。则从S中随机任选r个元素互不相同的概率为,因为有ex=,当x=,S→∞时,有原式≈,所以,2个元素相同的概率所以,当p=1/2,S=366时,得到r≥23。这比我们直观想象的值要小的多。
“生日攻击法”,生日攻击[6]方法没有利用Hash函数的结构和任何代数弱性质,它只依赖于消息摘要的长度,即Hash值的长度。一个64位散列函数,它有2种可能的散列值,要想100%地找到一组碰撞,就需要264+1次约等于1019次攻击。但是基于生日攻击[2]的原理,只需要232+1约等于109次攻击,就有约50%的概率能够找到一对相同的值。
一般认为,对于n比特输出的理想Hash函数,碰撞攻击的复杂度上界为O(2n/2),对于随机选取的2n/2个消息,MURMUR为64位的Hash函数,n=64,即S=264,r=232代入,得到P为找到一对碰撞的概率约为0.39[7-8]。对于随机选取的2n+1/2个消息,找到一对碰撞的概率为0.63。分段Hash后,2端同时冲突的概率为0.39×0.39等于0.152 1。对于所有64位的哈希函数冲突率为这么大,结合存储容量和查找时间复杂度考虑,我们认为64位的MURMUR哈希函数是符合实验要求的。
5 结论
本文的目的主要是在基于面向服务的未来网络的大环境下,提出对服务名字的命名规则以及选择适当的哈希函数对其进行处理,并对哈希函数性能的判断。最后得出服务名字六元组和选择的MURMUR哈希函数进行分段哈希是合理的,更利于保持服务身份和位置的对应关系,便于服务的搜索查找。借鉴P2P的信息存储方式来存储服务的名字和位置的对应关系。
[1]BALAKRISHNAN H,LAKSHMINARAYANAN K,RATNASAMY S,et al.A layered naming architecture for the Internet[J].ACM SIGCOMM Computer Communication Review,2004,34(4):343-352.
[2]ZHANG L,ESTRIN D,BURKE J,et al.Named data networking(ndn)project[EB/OL].[2012-10-30].http://ccn-uff.wdfiles.com/local—files/projetos/NDN%20Project%20Technical%20Report.pdf.
[3]KAFLE V P,OTSUKI H,INOUR M.An ID/locator split architecture of future networks[C]//Innovations for Digital Inclusions,K-IDI 2009.Kaleidoscope:IEEE press,2009:1-8.
[4]董芳,费新元,肖敏.对等网络Chord分布式查找服务的研究[J].计算机应用,2003,23(11):25-28.FANG D,FEIXIN Y,MIN X.Research on Peer-to-peer network Chord distributed lookup service[J].Journal of Computer Applications,2003,23(11):25-28.
[5]吴军,数学之美[M].北京:人民邮电出版社,2012.JUN W.The beauty of mathematics[M].Beijing:People’s Posts and Telecommunications Press,2012.
[6]WAGNER D.A generalized birthday problem[M].Heidelberg:Springer-Verlag,2002:288-304.
[7]魏悦川.Hash函数的安全性分析与设计[D].长沙:国防科学技术大学,2007.WEI Yuechuan.Hash function security analysis and design[D].Changsha:University of Defense Technology,2007.
[8]STOICA I,MORRIS R,LIBEN N D,et al.Chord:a scalable peer-to-peer lookup protocol for internet applications[J].IEEE/ACM Transactions,2003,11(1):17-32.
