基于高效离群数据分析方法的客户信息及特征属性挖掘
2012-09-26夏火松
夏火松,魏 翔
0 引言
在Web客户信息处理过程中,面对庞大的数据库,人们所需的信息只是其中的小部分,而且往往是其中较为特殊的一部分信息,它们隐藏在海量数据当中。如何能够快速而有效地找到它们并且能够获知其特殊的原因,就成为当务之急。目前,成熟的信息管理技术能够为用户提供数据获取、存储、管理、搜索等丰富的功能,而以分类、聚类、关联分析为主的数据挖掘技术也不断发展和完善,但离群数据的挖掘技术及其应用却仍然十分有限,其原因在于现有的离群数据挖掘算法的效率依然不高,稳定性也不强,其所得到的离群信息也很有限。针对客户信息管理过程中的这些情况,本文将在传统的离群数据挖掘算法的基础上,以保持挖掘结果稳定性为前提,以提高挖掘效率为目标,尝试探索出新的途径。为了在检测离群数据的同时也能够获得其为什么离群的相关信息,本文将把特征属性挖掘的过程融入其中。
1 理论回顾
1.1 离群数据分析方法
离群数据分析方法主要有以下几种:一是基于统计的方法[1],已知或假定给定数据集符合某种概率分布模型,然后通过对该模型进行不一致性检验来确定离群数据,这一检验过程需要知道数据的分布模型及其参数以及预期的离群数据数目;二是基于距离的方法,定义和计算数据对象与数据集中其它对象的距离并以此来查找该数据对象的邻居数量,离群数据即为那些邻居数量不足的数据对象,该方法不依赖于统计模型及检验;三是基于密度的方法[2~4],从数据对象间的距离的概念出发,结合数据对象的邻居数量或与邻居的平均距离得到了“密度”的概念,该方法能够检测到一类特殊的离群数据——局部离群数据,最有代表性的算法即是Breunig等提出的LOF算法[5];四是基于深度的方法,先把每个数据对象映射为维数据空间中的点并赋予深度值,再依据深度值按层重组数据集,然后在深度较小的层中搜索离群数据,该方法仅在维度低于4的数据集上应用效果较好,有代表性的算法是DEEPLOC算法[6];五是基于偏离的方法[7~8],通过对数据集的主要特征进行检测来发现离群数据,目前该方法及其算法大多数还停留在理论研究上,实际应用较少。本文所做的研究是基于距离的方法展开的。
1.2 基于距离的离群挖掘方法
基于距离的离群数据挖掘方法最初是由Knorr和Ng提出的[9],给定数据集T,如果T中存在超过p部分的数据与某一个数据对象O之间的距离大于D值,则称数据对象O为基于距离的离群数据,记为DB(p,D)-outlier,其中p和D是参数。这一方法的提出,不仅为离群数据挖掘提供了一种新的算法,而且为研究者们打开了思路,为后续离群数据挖掘算法的提出做了铺垫。基于距离的离群数据挖掘算法的优点在于,能够直观地反映离群数据与数据集中其它数据之间的关系,且易于理解和计算,在实际应用中也收到了良好的效果。这种方法实际上已经包含并扩展了早期的基于统计的算法思想,同时相对不一致性检验所需的计算量来看,该方法的计算量已显著降低,故其在应用中能够达到和超越基于统计的算法的效果。另外,它对数据集中数据的维数没有限制,可以完成对高维数据的处理和挖掘工作。
但这种方法也存在很大的缺陷,需要用户给出参数p和D的值才能进行离群数据挖掘,然而这两个参数却很难给的恰到好处,同时其值的微小变化都有可能对最终的结果造成较大影响,这就需要用户凭经验做出判断并对进行p和D的取值反复尝试以求得到较好的结果。这不仅给用户使用带来诸多不便,而且这一不确定性严重影响了结果的稳定性和算法应用的广度和深度。此外,该方法不能有效地反映离群程度,虽然相对基于统计的方法计算量显著下降但其复杂度仍然较高,为O(d⋅N2),其中d为数据集中数据对象的维度,N为数据对象的数量。针对这些主要缺陷,很多学者对算法进行了不同程度的改进,如基于索引的算法[10]引进了索引的思想来改进算法,但建立索引需要一定时间;循环嵌套算法主要通过减少I/O的次数来改善算法的效率;基于单元的算法[11]通过将数据集划分为单元,利用单元及其邻居的性质来发现异常数据,从而提高了检测的效率。
1.3 离群特征属性
在离群数据挖掘算法的应用过程中,用户查找到离群数据后,自然会关心是哪些属性导致离群数据与其它数据不同的,即它为什么离群,于是有学者提出了离群数据知识集[12]的概念。一个高维空间上的离群数据的离群特征往往在该空间的子空间上就会表现出来了。这就需要寻找到能够解释离群数据为什么离群的属性集合。离群数据知识集就是描述离群数据离群的最小属性集合,它通过数据的属性来反映离群数据的异常行为特征,这些属性能够解释离群数据发生异常的原因,可以对离群数据的合理性和有效性进行评价,它们就是离群特征属性。在检测出离群数据并发现其相应的离群特征属性后,离群数据与导致其离群的属性间的对应关系就一目了然了,用户可以直观地了解离群数据之所以离群的缘由。
2 离群数据及其离群属性空间挖掘模型
2.1 模型建立
定义1包含有n个数据对象Ai(i=1,2,…,n),且每个数据对象Ai有d维属性aik(i=1,2,…,n;k=1,2,…,d)的数据集记为Dataset(n,d)。
定义2由d维属性Vk(k=1,2,…,d)构成的属性空间为其子空间SubSpace(Dim)=∏k∈DimVk,其中Dim⊆{1,2,…,d},并用|Dim|表示集合Dim所包含的元素数量,即为子空间SubSpace(Dim)的维数。
根据定义1和定义2,对数据集Dataset(n,d)中各个数据对象Ai(i=1,2,…,n)的每一维属性分量aik(i=1,2,…,n;k=1,2,…,d)有aik∈Vk(i=1,2,…,n;k=1,2,…,d),进而Ai∈Space(d),故数据集可以表示为Dataset(n,d)={Ai|Ai∈ Space(d),i=1,2,…,n}。
距离的定义有很多种,这里引入两种应用最为广泛的距离定义,欧氏距离(即欧几里得距离)和绝对距离(即曼哈顿距离),它们的定义如下:
定义3在多维属性空间SubSpace(Dim)中,数据对象Ai={aik|k∈Dim}与Aj={ajk|k∈Dim}的欧氏距离和绝对距离分别为:
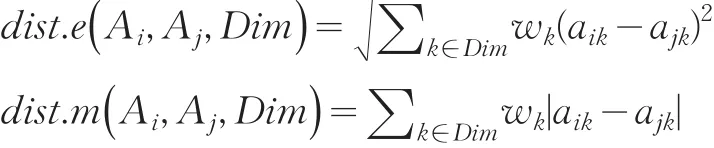
其中{wk}为权重系数集。
定义4在多维属性空间SubSpace(Dim)中,某数据对象Ai与最近的m个最近邻居Aj1,Aj2,…,Ajm之间的距离的平均值,称为平均近邻距离,记为dist_MND,即
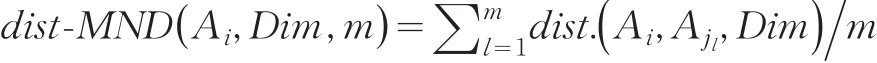
这里dist.表示一种距离,即用欧氏距离或绝对距离进行计算(下文同)。
例如,一个二维空间中的六个数据对象如图1所示,图中用虚线标示出了数据对象A2和A6分别与各自最近的三个邻居的连接,以及相应的平均近邻距离的圆弧大小。很明显,在这六个数据对象中,A6属于离群对象,其平均近邻距离较大,而其它非离群对象的平均近邻距离则相对较小。为了能对其进行数值上的比较,需进一步作一些定义。

图1
定义5在多维属性空间SubSpace(Dim)中,记dist_Max为最大可达距离,即

定义6(离群因子)数据对象Ai的离群因子(Outlier Factor)为:

该离群因子通过计算基于已选定属性空间的每一个数据对象的平均近邻距离与该属性空间中的最大可达距离的比值,来衡量各个数据对象的离群程度,既能通过数据对象与最近邻居的距离来反映其偏离的程度,又可以通过将其与最大可达距离求比值来统一数量等级,以便于对数据对象在基于不同属性空间下的离群因子进行考察和比较。为了进一步研究离群数据对象的离群原因,即其特征属性,下面对离群属性空间作定义。
定义7(离群属性空间)若数据对象Ai在属性空间SubSpace(Dim)及其任意子空间中是离群数据对象,则称该属性空间为Ai的离群属性空间,则|Dim|即为该离群属性空间的维数。
定义8(离群特征属性)数据对象Ai的离群属性空间中的各维属性即构成该数据对象的离群特征属性的集合,记为OFA(Ai)。
由上述对图1的分析,在这二维空间中的六个数据对象中A6是离群数据对象。若分别将它们对两个维度Vk1和Vk2作投影,如下图所示,图2(a)中,A1的投影点明显偏离其它五个数据对象的投影点,说明A2在维度Vk1为离群数据对象,即该维度为离群数据对象A2的一维离群属性空间。图2(b)中,此六个数据对象在维度Vk2上的投影点均没有明显偏离,因而该维度不属于离群数据对象A2的离群属性空间。因此,OFA(Ai)=Vk1,Vk1即为A2的离群特征属性。
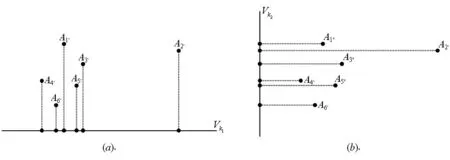
图2
离群数据对象的离群特征属性是反映其离群的主要原因,本文拟从数据对象的每一维属性出发,设计离群数据挖掘方法,以期在挖掘离群数据的同时发现离群数据对象的多维离群特征属性。
2.2 过程设计
步骤1:对数据集中所有数据对象就其在每一维属性Vk(k=1,2,…,d)上的属性值{aik}(i=1,2,…,n),∀k=1,2,…,d,分别进行排序操作得到{as1k,as2k,…,asnk},∀k=1,2,…,d,使 得 as1k<as2k<…<asnk,其 中{s1,s2,…,sn}是{1,2,…,n}的一个排列,相当于是排序后的属性值对应原始数据集中属性值的位置指针。
步骤2:对每一维属性Vk(k=1,2,…,d)上的所有数据对象计算dist_MND(Ai,k,m)值,∀k=1,2,…,d,采用的是绝对距离进行计算。由于步骤1中已经对属性Vk上的属性值进行了排序,因此该值可以通过对{as1k,as2k,…,asnk}中连续的m+1个值计算绝对距离及相应均值即可,并对首尾两处的计算稍作调整,具体如下:
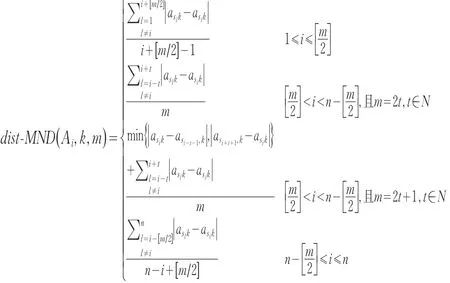
步骤3:计算各维属性Vk(k=1,2,…,d)中的最大可达距离dist_Max(k),∀k=1,2,…,d,由于步骤1中已对属性值排序,并拟采用绝对距离进行计算,则

步骤4:计算每个数据对象Ai(i=1,2,…,n)的一维离群因子OF(Ai,k,m),并将其就所选维度集合Dim求和值作为综合离群因子,即

步骤5:将OF(Ai,Dim,m)值进行逆序排序,取其前p⋅100%项对应的Ai及其中间过程结果作为最终的离群数据挖掘结果输出。这些输出结果包括:综合离群因子OF(Ai,Dim,m),作为离群数据离群程度衡量指标,一般取前0.1%-5%作为离群数据,也可由用户自行选择;一维属性离群因子OF(Ai,k,m),作为离群特征属性判别依据,一般以该离群数据的最大的[|Dim|⋅20%]+1个一维属性离群因子所对应的属性作为离群特征属性。此外,将各数据对象按各一维属性离群因子进行排序,可为进一步分析离群原因提供参考依据。
2.3 挖掘方法说明与比较分析
2.3.1 复杂度比较分析
采用上述方法进行挖掘的主要耗时部分在于步骤1,即对各个数据对象在每一维属性维度上进行排序。目前,排序算法已经非常成熟,我们采用的是稳定的归并排序[13]的方法,其时间复杂度为O(n⋅log2n),空间复杂度为O(n)。因而步骤1的时间复杂度为O(d⋅n⋅log2n),空间复杂度为O(d⋅n),而步骤2、步骤3和步骤4的时间复杂度为O(n),故该挖掘方法的时间复杂度为O(d⋅n⋅log2n),空间复杂度为O(d⋅n)。这与传统的离群数据分析方法的时间复杂度O(d⋅n2)相比,降低了一个数量等级,而空间复杂度并没有增加。
从实际运用角度来看,首先,该方法可以大大缩减数据预处理的过程,而传统方法往往要经过大量的数据处理才能进行进一步操作。其次,该方法充分利用了排序原理,运用成熟的排序算法可以显著调高整体的处理速度。再次,该方法将离群数据分析与其相应特征属性挖掘过程兼并完成,而无需进行二次挖掘。这也是较为突出的一点。
3.3.2 I/O情况分析
从输入方面看,该方法自始至终需要用户确定的参数有三个,此三个参数非常容易确定,且可以直接应用默认值,而不会对挖掘结果造成显著影响。这三个参数分别是m,Dim,p。其中,根据方法的内在性质及相关试验表明,对较为紧密的数据集处理时m设定为1或2即可,当检测结果不理想或数据集较为稀疏时可以设定2≤m≤5,一般不超过6。参数Dim实际上是让用户选定对哪几维度进行离群数据和相应特征属性检测,一般选择所有维度或根据需要选择即可。对参数p则可有可无,因为输出结果本身就是将数据对象按OF值的逆序排列结果,参数p则只是用来控制显示的数量。因此,该方法对用户设定参数的要求比较低。
从输出方面看,该方法能够给出传统的基于距离的离群数据挖掘方法所不能给出的离群因子指标,同时还能给出其相应的离群属性空间中的各特征属性的离群因子,使用户可以较清晰地了解各个数据对象的离群程度,以及它们为何离群、是由于哪几个特征属性造成的离群,故该方法的输出结果较为直观、易于理解。
3.3.3 应用分析
针对Web客户信息的数据量大、维数高的特点,我们设计的该挖掘分析方法的重点在于,能够在保持一定的算法稳定性的前提下提高算法的运行速度和执行效率,省去不必要的步骤,以适应处理大量的、高维的数据的要求。同时尽可能地简化操作,方便用户使用。
在对特征属性的挖掘方面,目前的研究思路主要是通过先对离群数据进行分析,再对离群对象的特征属性进行挖掘的两步方法,因而应用过程中需要对数据集进行反复搜索,这并不能适应处理大量的、高维的数据的要求。而本文所述方法的优点即在于能够将离群数据分析及其特征属性挖掘作为一个整体进行处理,从而大大提高离群特征属性的发现效率,避免对数据集进行大规模的重复遍历,这是我们对离群特征属性挖掘研究做的新的探索。
另外,若在允许等量的消耗存储空间的条件下,将原始数据进行了转化并存储,这将有利于简化对新增数据对象的分析处理工作,因而有较高的可扩展性能。

表1 离群数据及其知识集挖掘结果(m=1,Dim={G,A,…,S},p=0.5%)

表2 离群数据及其知识集挖掘结果(m=2,Dim={G,A,…,S},p=0.5%)
4 实验分析
4.1 准确度比较
为了模拟Web客户信息及其属性值,同时反映该方法相对于传统离群数据分析方法的不同特性和效果,这里使用文献[11]中所使用的NHL数据集进行对比研究,该数据集曾多次被用于进行离群数据分析研究。该数据集为NHL(National Hockey League)在1995~1996年度职业球员的比赛统计信息,样本量为991,维度为10,属性名称分别为Goals,Assists,Points,Plus/Minus,Penalties in Minutes,Even Strength Goals,Power Play Goals,Short-Handed Goals,Game-Winning Goals,Shots。实验环境为Matlab7.10,设定参数为m=1,Dim为所有10个维度,p=0.5%,结果见表1。
在给出的前5个离群数据对象中,结合综合离群因子和一维属性离群因子可以看出,前三个数据对象是显著离群,其离群特征属性分别为OFA(Mario Lemieux)={PP,S H},OFA(Jaromir Jagr)={G,GW},OFA(Sergei Fedorov)={+-,GW}。与文献[11]中的结果进行比较,两者均检测到Mario Lemieux和Jaromir Jagr两个离群数据对象,特征属性检测结果也较相近,由于两者数据源有所差异且选取的维度不同,因而对检测结果有一定影响。总体来看,该方法能够达到传统方法所能获得的准确度。
4.2 稳定性测试
为测试检测结果的稳定性,调整参数m=2,结果见表2。
实验结果表明,当参数m由1改为2时,所得到的三个显著离群数据对象的结果不变且其离群因子值没有发生大的变化,这说明本算法对显著离群的数据对象的检测效果比较稳定。
5 结论
本文所设计的离群数据分析方法的时间复杂度为O(d⋅n⋅log2n),空间复杂度为O(d⋅n),且检测结果比较准确、稳定,算法效率较传统方法有大幅度提高,有利于应用于对大量的、高维的Web客户信息的处理工作。该方法能够一次性完成对离群数据的分析和对其相应特征属性的挖掘过程,这对离群数据的特征属性挖掘方法是一项有益的探索。该方法对用户的使用要求较低,参数设置简便,且参数的小幅改变不会对检测结果造成严重影响。通过离群因子OF值来表示离群程度,简单而易于理解。另外还具有一定的可扩展性,其中间过程数据有重复利用的价值。因此,本文所设计的方法为客户信息管理中的离群数据分析工作提供了新的思路和方法。
[1]Barnett VLT.Outliers in Statistical Data[M].New York:John Wiley&Sons,1994.
[2]Breunig MM,Kriegel HP,Ng RT,et al.OPTICS-OF:Identifying Lo⁃cal Outliers[C].In Proceedings of the 3rd European Conference on Principles and Practice of Knowledge Discovery in Databases,Prague,1999.
[3]熊君丽.高维空间下基于密度的离群点探测算法实现[J].现代电子技术,2006,(15).
[4]崔贯勋,朱庆生.一种改进的基于密度的离群数据挖掘算法[J].计算机应用,2007,27(3).
[5]Breunig MM,Kriegel HP,Ng RT,et al.LOF:Identifying Densi⁃ty-Based Local Outliers[C].In Proceedings of ACM SIGMO 2000 In⁃ternational Conferenceon Management of Data,Dalles,TX,2000.
[6]Struyf A,Rousseeuw PJ.High-dimensional Computation of the Deep⁃est Location[J].Computational Statisticsand Data Analysis,2000,3.
[7]郑建国,焦李成.偏差检测挖掘方法研究[J].计算机工程,2001(8).
[8]黄洪宇,林甲祥.离群数据挖掘综述[J].计算机应用研究,2006,(8).
[9]Knorr EM,NgRT.Finding Intentional Knowledge of Distance-Based Outliers[C].In Proceedings of the 25th VLDBConference,Edinburgh,Scotland,1999.
[10]Sephen DB,Mark S.Mining Distance-based Outliers in Near Linear Time with Randomization and a Simple Pruning Rule[C].In Proceed⁃ings of the Ninth ACM SIGKDD International Conference on Knowl⁃edge Discovery and Data Mining,Washington DC,USA,2003.
[11]Anguylli F,Pizzuti C.Fast Outlier Detection in High Dimensional Spaces[C].In Proceedings of the Sixth European Conference on the Principles of Data Miningand Knowledge Discovery,2002.
[12]Chen Z,Tang J,Fu AW.Modeling and Efficient Mining of Intention⁃al Knowledgeof Outliers[C].Hong Kong:2003.
[13]Jyrki K,Tomi P,Jukka T.Practical In-Place Mergesort[J].Nordic Journal of Computing,1996,(3).
