结合结构下文及词汇信息的汉语句法分析方法
2012-06-28罗森林陈开江潘丽敏
陈 功,罗森林,陈开江,冯 扬,潘丽敏
(北京理工大学 信息与电子学院信息安全与对抗技术实验室,北京 100081)
1 引言
将自然语言的句法分析进行可计算化处理,需要两个重要元素:语法模型和搜索算法[1]。无论是早期单纯的理性主义和经验主义还是如今的两者结合,都需要建立一种语法模型,并且在分析过程中采取一种搜索算法得到分析结果。最早的语法模型就是简单的上下文无关语法模型。概率上下文无关语法(PCFG)是把概率引入到上下文无关语法规则而形成的语法规则模型。但是,经典的PCFG实际上是建立在一些非常理想化的独立性假设的基础之上的,而这些假设并不符合实际,于是造成了PCFG的实际效果不理想。目前的概率上下文无关语法研究,主要集中在如何突破这些独立性假设上。
中国科学院的张浩和刘群尝试了祖先节点相关,父节点使用的规则相关等几种结构上下文相关的策略,效果良好[2]。北京大学计算语言研究所的冀铁亮等尝试使用了动词子语类框架[3],利用了动词的子语类框架的信息。北京大学的张耀中尝试了融合语义和句型信息[4]。这些方法都对突破上下文无关语法研究中的独立性假设的进行了尝试。利用了结构上文,动词词汇及语义、句型等信息,对于PCFG模型的改进及分析很有参考价值,但是这些方法没有尝试与结构下文相关,本文的工作正是通过在概率上下文无关语法模型中加入结构下文,构成了结构下文相关的概率语法模型。
词汇化的句法分析是目前自然语言处理研究的趋势和热点。概率上下文无关语法由于其独立性的假设,脱离词汇本身,这也是PCFG的一个重要缺陷。基于此,本文在PCFG中引入了词汇信息,构成了词汇化的PCFG,弥补了词汇信息的缺乏。同时,对于模型的分析算法,使用了基于左角分析的Earley改进算法,并引入分层的分析策略,进一步提高了分析效果。
2 结构下文及词汇信息结合的语法概率模型
经典的PCFG基于独立性的假设,对上下文信息利用不足,且没有用到词汇信息。基于此本文提出了结构下文相关的概率模型(S-PCFG)以及结合词汇信息的概率模型(L-PCFG),并在这两个模型基础上,提出了结构下文相关以及结合词汇信息的概率模型(SL-PCFG)。
2.1 经典模型(PCFG)
一个 PCFG 的符号系统包括以下成分:
• 一个终结符的集合,{Wk},k=1,…,V
• 一个非终结符的集合,{Ni},i=1,…,n
• 一个开始符号,N1
• 一个规则的集合,{Ni→ζj},(其中ζj是一个终结符和非终结符的序列)
概率方面,PCFG给出了由一个非终结符节点可能派生出的各种符号序列的概率分布(式(1))。
计算一棵分析树t的概率P(t),需要进行必要的独立性假设。经典的 PCFG认为,施用每一条规则的概率独立于上下文和祖先节点[5]。这样,假设t当中的所有规则构成了一个规则的多重集R,那么[2]:

(2)
所得句法分析树的概率P(t)是建立在PCFG的独立性假设基础上的,主要是以下三条假设:
(1)位置无关性假设:子节点概率与子节点管辖的字符串在句子中的位置无关;
(2)上下文无关性假设:子节点概率与不受子节点管辖的其他字符串无关;
(3)祖先结点无关性假设:子节点概率与导出该节点的所有祖先节点无关。
然而,实际生活中自然语言有着很强的上下文相关性,子节点的概率不仅与其祖先节点有关,还与它的兄弟节点,它所导出的子节点相关,面对这样的歧义,PCFG模型便无法解决。此外,PCFG模型并没有考虑词汇的信息,对于词汇相关的歧义,它也是无法解决。
由此可见,概率上下文无关语法在遇到结构依存和词汇依存问题的时候就显得无能为力了,因此有必要探索其他的途径来进一步提升概率上下文无关语法的功能[6]。
2.2 结构下文相关的概率模型(S-PCFG)
PCFG对于上下文信息的利用是不足的,子树的概率与子树以外的节点无关。针对PCFG的这一点假设,模型认为,一个非终结符重写出来的节点受其子规则约束,符合真实语料中二次重写(子规则)统计规律的非终结符才能在一次重写中应用。例如,dj=np+vp的重写过程中(一次重写)需要考察其中np和vp将会重写成什么符号(二次重写),然后再考虑一次重写是否能成立,这相当于在分析中借助了下文的信息来提前验证上文的预测。这个模型的规则表示成非终结符Ni重写为几个一层子规则r式(2)的形式,而不是重写为两个非终结符(或终结符),如式(3)所示。
Ni=rj+rk+…+rl
(3)
相应地,模型中包含了式(4)所示的概率分布。
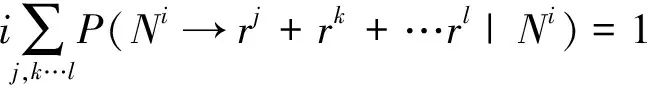
(4)
采用这种改进的PCFG模型,增加了重写规则的分辨率。在自底向上分析或者左角分析的过程中可以快速帮助分析器抉择,减少不必要的子树生成。每一个S-PCFG的规则概率可以理解为一个条件概率,类似于PCFG的规则概率,S-PCFG的规则概率计算式如式(5)所示。
需要说明的是,在重写部分中若出现终结符(词性标记)则不用二次重写。
假设句法树t当中的所有非终结符构成了一个非终结符的集合N,分析树的概率计算公式如式(6)所示。
(6)
模型的规则中所有非终结符均采用节点附着子节点的形式表示,例如字符串形式表示为dj-np-vp=np-nr+vp-v-np(规则左边为节点“dj”附着子节点“np”“vp”),在叶子节点上依然是原来标记作为节点类型,一般是词性标记,若结合下文L-PCFG的话可能是“词汇/词性”的形式。
图1所示为由S-PCFG模型分析出的句法树。
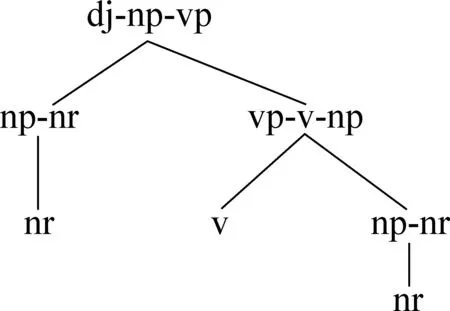
图1 S-PCFG的分析树表示方法
2.3 结合词汇信息的概率模型(L-PCFG)
L-PCFG模型是将一些小集合词性的词汇关联到规则中去,是一种部分词汇化的PCFG,虽然将如名词、动词等词汇考虑到句法分析中后势必会造成数据稀疏,但是对于集合较小,在自然语言使用中更新较慢的词汇则可以考虑到句法分析中去。经对《人民日报》1998年1月的语料进行统计之后,可以确定将词性如表 1所示的词汇作为预终结符(即介于非终结符和终结符之间的词性符号),直接考虑到句法分析中。

表1 词语集有限的词性标记统计
这些词性的集合随着语料增加的分布规律如图2 所示(统计语料来源:《人民日报》1998年1月)。从图 2中可以看出,表 1中所列的词性对应的词汇是一个收敛的集合,将这些词性的具体词汇关联到语法规则中引起的数据稀疏问题并不是很严重,相反,会带来良好的消歧能力。综合考虑数据稀疏及消歧能力,将相应的词汇信息关联到语法规则中还是有利的。
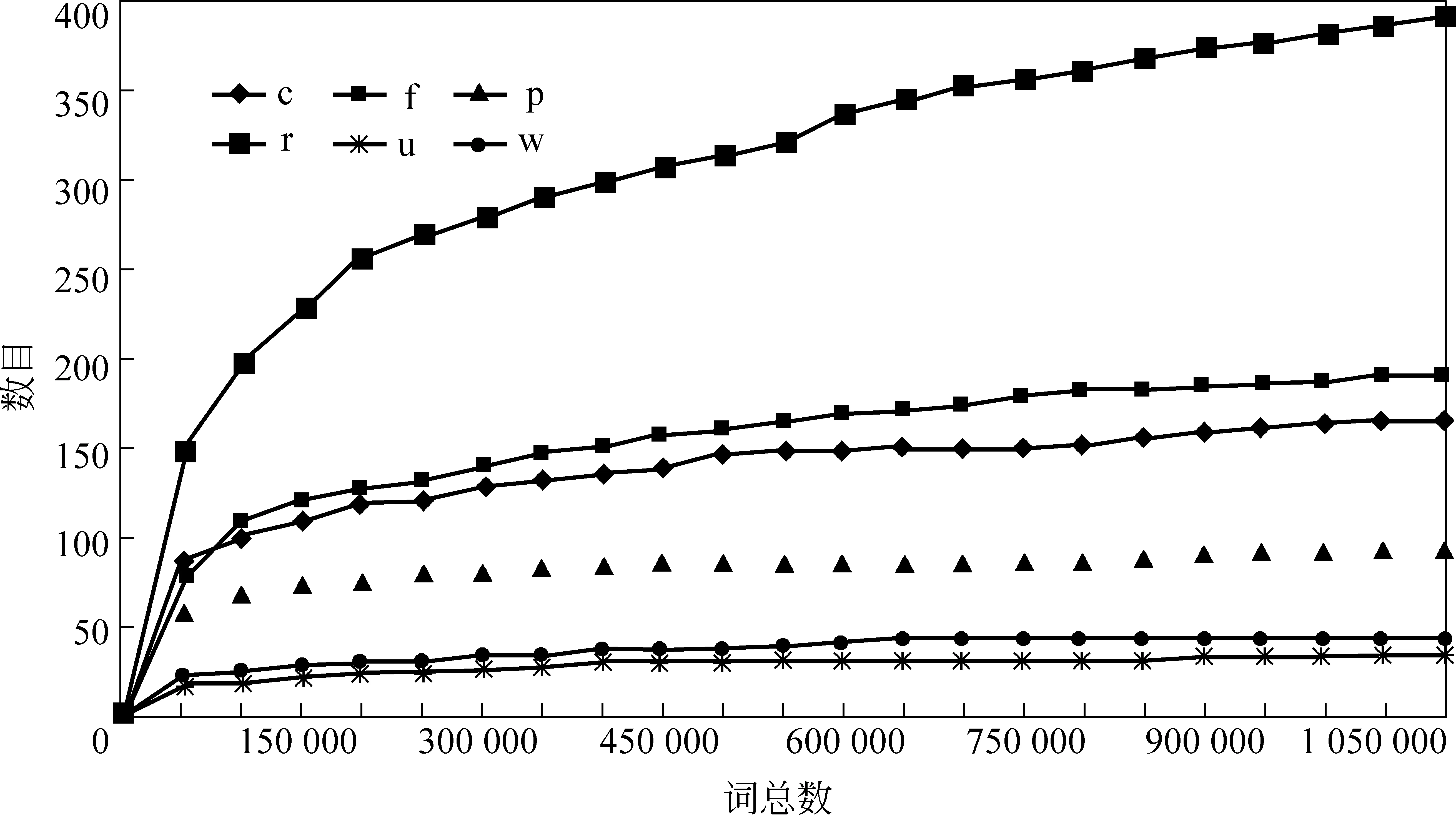
图2 部分词性集合词汇分布规律
为了使规则表示为“非终结符重写为若干预终结符”的形式,以方便和其他概率语法模型使用相同的分析算法以及相同的训练算法,设计L-PCFG将关联词汇的规则表示为在需要关联到词汇时的地方都将词汇和词性连在一起作为一个符号,这相当于扩展了词性标记,示例如图 3所示,规则表示为vbar=v+了/u。

图3 与词汇关联的规则实例
经过上述方式扩展了规则集之后,可以继续使用原来的分析算法进行分析,只是在输入句子后首先要检查句子中是否存在表 1中所列的词性,若有则需进行预处理以方便使用该模型进行分析。
2.4 结构下文相关以及结合词汇信息的概率模型(SL-PCFG)
为实现对句子信息的充分利用来进行句法分析,SL-PCFG.对S-PCFG及L-PCFG模型进行了结合见图4。模型的结合实质上是将各种限制条件叠加使用,叠加的限制条件越多,分析越精确,但是在树库资源有限的情况下,开集测试时召回率会有所下降。

图4 S-PCFG的分析树表示方法
利用以上四种模型对句法分析的效果参见第四节的实验部分。
3 句法分析算法
句法分析算法原理如图 5所示。对于不同的概率模型,采用同样的分析算法,只需在规则提取时采用不同的规则即可,即分别采用PCFG、S-PCFG、L-PCFG或是SL-PCFG的规则。

图5 句法分析算法原理
3.1 规则提取
规则施用概率的提取采用最大似然估计,不同的概率模型(PCFG、S-PCFG、L-PCFG、SL-PCFG)有着各自的语法规则,但对于规则施用概率提取本质上都是一样的。
随着基于统计的方法在句法分析中逐渐成为主流,语料库的建设对于句法分析的研究来说是不可或缺的,从树库自动抽取语法规则并进行统计以用于模型的分析是有效易行的。对于以上各模型的语法规则及概率获取是比较简单的,一般做法是:首先统计训练语料中出现的规则及其次数,然后利用最大似然估计从规则出现频率估计出规则施用概率[7]如式(7)。

加入结构下文信息或小集合词汇信息模型的规则施用概率的计算公式跟式(7)本质上是一样的,只是将重写规则Ni→ζj改写为Ni→rj+rk…rl的形式,如式(5)所示;或将部分规则中需要关联到词汇时的地方都将词汇和词性连在一起作为一个符号。相应的分析树中的节点标记或部分词性标记也进行变换。
具体的标记变换如图 6所示。
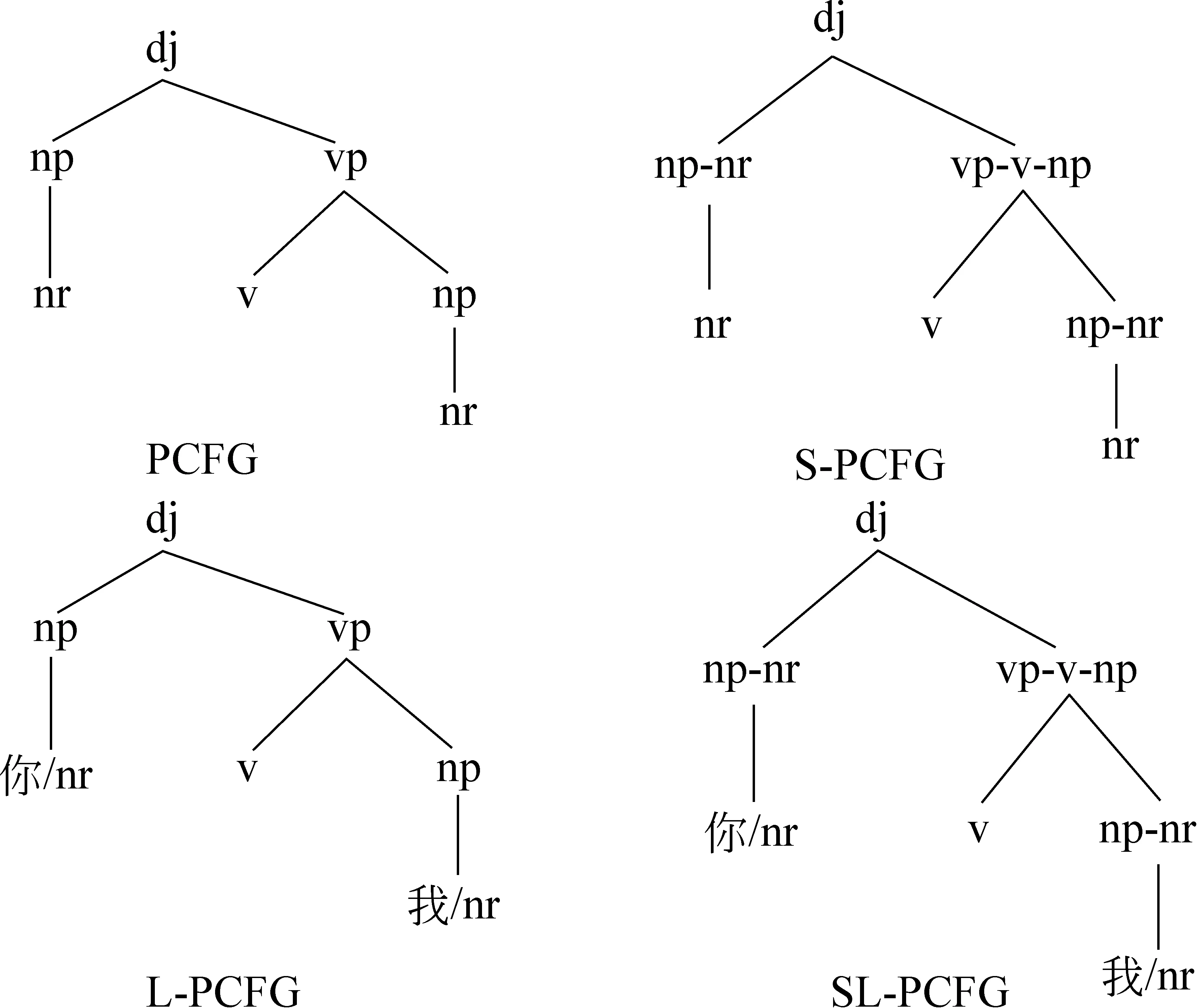
图6 标记变换示例
这样,四个模型的分析算法都是PCFG的分析算法,只要替换不同的规则集,就构造出了结构下文相关、结合词汇信息、结构下文相关以及结合词汇信息的分析器。
3.2 句法结构分析
根据获得的概率规则库,我们采用分层分析的算法对待分析的句子进行句法结构的自动分析。
分析算法对原有的Earley算法进行了改进,并引入了分层的分析策略。原有的Earley算法是一种典型的自顶向下、自左向右的分析算法。通过对Earley算法进行改进,使用自底向上的分析算法,有效地减少了自顶向下的预测过程。使用分层的分析算法,有效地解决了消歧性与鲁棒性间的矛盾。
1)分层分析算法原理
句法分析的难点是歧义消解,歧义存在的原因在于当前模型下无法获取更多的信息来供分析器判定,因此消歧能力越强的模型其语法规则的限制条件越多,进而造成数据的稀疏,使得精确性(准确率)提高的同时,分析的覆盖面(召回率)有所下降。分层构建句法树实质上是用不同的概率语法模型分析,并且不同层之间共享子树,为了在鲁棒性较好的模型中使用到消歧性较好的模型分析出的子树,来达到鲁棒性和消歧双赢的目的。在不同层(使用不同模型)分析过程中,即使某一层未分析成功整个句法树,但是在下一层分析时仍可共享这一层得到的子树片段。
分层分析一共四层,四层模型的特点如图 7所示。只要有一层分析成功,分层分析不再进行下去。分层分析的流程图如图 8所示。

图7 四层模型特点

图8 分层分析流程图
2)分层分析冲突处理策略
由于分层分析时是将不同语言模型下产生的结果放在一起,因此在构建句法树过程中遇到冲突时,采用PCFG模型的概率参数对冲突进行取舍。
采取如下方式:当同层分析时,遇到范围相同、根节点相同的片段树时,采用PCFG模型的参数计算每个片段树的概率,保留较大概率的片段树。当不同层分析得到相同范围、根节点相同的片段树时,先计算各自在PCFG模型下的概率,较低一层得到的句法树概率大于较高一层分析得到的句法树时选择较低一层得到的树,否则,优先选择较高一层得到的子树。
例如,在第四层未分析成功但是产生了部分片段树的情况下,第三层分析结束后构建出一个片段树T3,并检查到已在上一层构建出相同根节点的片段树T4,则在PCFG下分别计算P(T3)和P(T4),若P(T3)> P(T4)则用T3替代T4,否则选择T4。
4 实验及结果分析
为了验证各语法模型的分析效果及分层分析结果,进行了各语法模型的分析对比实验及分层分析的实验。
本文的算法研究采用BFS-CTC语料库(Beijing Forest Studio-Chinese Tag Corpus)。其原始语料来源于新闻语料中的句子(如Sohu、Sina、人民日报等),句法标注集采用北京大学计算语言学研究所规范[8]。目前语料库中的句子以单句为主,其中的句子基本涵盖了各种句型及常见语法现象。
实验的训练数据来自于BFS-CTC语料库中的词法、句法标注集,表 2所示为训练集,共5 488句。闭集测试集是从训练集中抽样的句子,共549句,平均每句13词;开集测试为对以上5 488句数据源的十字交叉验证。

表2 训练用句子句式分布表
句法分析模型的评测算法采用的是PARSEVAL句法分析评价体系[9]。主要由准确率(Precision,体现准确性)、召回率(Recall,体现全面性)两部分组成。F1值(Precision与Recall的调和均值)是用来综合评价准确性和全面性的指标。
实验中,首先分别利用PCFG、L-PCFG、S-PCFG、SL-PCFG进行单模型的句法分析实验,其结果如表 3所示;结合得到的PCFG、L-PCFG、S-PCFG、SL-PCFG四种模型的概率规则库,采用分层分析算法针对相同数据进行实验,其结果如表 4所示。

表3 各个语法模型对比实验结果

表4 分层分析实验结果
表3的结果表明:集合了S-PCFG和L-PCFG两个模型的SL-PCFG的消歧能力最强,因此在闭集测试时能够得到最好的效果。但是, 与此同时带来了数据稀疏的问题;在开集测试时虽然准确率仍然很高,但是召回率已经锐减到0.272了,说明已经出现了大量分析不成功的句子。S-PCFG模型与PCFG模型相比,准确率与召回率在闭集测试时均有较大程度的提高,但是召回率在开集测试时也有所下降。L-PCFG模型与PCFG模型相比,准确率有了一定程度的提高,说明加入部分词汇信息对于结构歧义的消除有一定效果,但对于句子分析成功与否的作用并不明显。
表5列出了相关中文句法分析器在宾州中文树库测试集上的结果。其中分析效果比较显著的有Jiang作业论文[15]将Collins模型移植成中文句法分析器,F1值达到了81.1%;中国科学院的米海涛[16]等(2008)利用多子模型句法分析系统将中心词驱动模型和结构上下文模型按照对数线性模型融合在一起,形成多子模型句法分析器,F1值达到了82.5%的较高水准;Petrov & Klein[17](Berkeley Parser)在PCFG模型基础上利用隐含特征(PCFG-LA),同时并行的采用EM算法进行训练,得到了一个不依赖于特定语言的句法分析器,Mary P.Harper & Zhongqiang Huang[19]用此句法分析器在CTB上对汉语进行了句法分析,得到了82.7%的准确率及83.1%的召回率,一定程度上减小了中、英文在句法分析结果上的差距;哈尔滨工业大学的曹海龙等[18]以著名的中心驱动模型为基础,结合中心成分决策表和基本名词短语,采用CYK分析算法,在CTB公共测试集上得到了85.89%的准确率和85.61%的召回率,这是目前已知的中文句法分析的最好分析结果。

表5 汉语相关句法分析性能比较
表4所示为论文中所述汉语句法分析的分析结果。与表5所示各汉语句法分析器实验结果相比,虽然结果较好,但由于采用的是实验室自己的语料,可比性存在着一定的问题。因此,暂时只能跟传统的PCFG模型进行比较,以体现结合结构下文信息,结合部分词汇信息对PCFG模型描述能力的提高。同时,有力地说明了结合结构下文及部分词汇信息的分层分析方法的有效性。
结合表 3、表 4可以看出,分层分析在开集和闭集测试都能得到良好的效果。分层分析中依靠消歧能力较强的SL-PCFG和S-PCFG提高分析的准确率,依靠鲁棒性较好的L-PCFG和PCFG来提高分析的全面性,从而得到准确率与全面性的共同提高。开集测试的结果尤为明显。
5 结论
PCFG模型上下文无关的假设是必须要进行突破的,同时词汇信息的引入也是必不可少的[2]。本文基于以上的两点考虑,首先在PCFG结构独立性假设基础上引入了结构下文信息;然后在PCFG中引入了词汇化。实验结果表明,基于以上两点所做的改进很大程度上增强了句法分析的消歧能力。同时,针对由于S-PCFG及SL-PCFG引入了较多的规则条件,而出现数据稀疏的问题,本文采用了分层分析算法。利用SL-PCFG和S-PCFG消歧能力较强的特点,利用L-PCFG和PCFG鲁棒性较好的特点,结合不同模型的优点,兼顾了句法分析的准确性以及全面性。
[1]苗夺谦,卫志华.中文文本信息处理的原理与应用[M].北京:清华大学出版社,2007.
[2]张浩,刘群,白硕.结构上下文相关的概率句法分析[C]//第一届学生计算语言学研讨会.北京,2002,46-51.
[3]冀铁亮,穗志方.词汇化句法分析与子语类框架获取的互动方法[J].中文信息学报.2007(01):120-126.
[4]张耀中.融合语义和句型信息的中文句法分析方法研究与实现[D].北京大学,2009.
[5]Manning,C.,Schütze,H.Foundations of Statistical Natural Language Processing[M].Massachusetts:MIT Press,1999.
[6]冯志伟,自然语言处理中的概率语法[J].当代语言学.2005(2).
[7]Charniak,E.Treebank Grammars[R].Providence:Department of Computer Science,Brown University,1996.
[8]周强.汉语语料库的短语自动划分和标注研究[D].北京:北京大学,2002.
[9]Charniak,E.1997.Statistical Parsing with a Context-free Grammar and Word Statistics[C]//Proceedings of National Conference on Artificial Intelligence(NCAI)-1997,598-603.
[10]Daniel M.Bikel,David Chiang.Two statistical parsing models applied to the Chinese Treebank[C]//Proceedings of ACL 2nd Chinese Language Processing Workshop,2000.1.
[11]Roger Levy,Christopher D.Manning.Is it harder to parse Chinese,or the Chinese Treebank[C]//Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics,2003.439.
[12]Deyi Xiong,Shuanglong Li,QunLiu,Shouxun Lin,and Yueliang Qian.Parsing the Penn Chinese Treebank with semantic knowledge[C]//Proceedings of IJCNLP’05,2005.
[13]Daniel M.Bikel On the Parameter Space of Generative Lexicalized Statistical Parsing Models[D].Pennsylvania:Thesis of University of Pennsylvania,2004.
[14]David Chiang,Daniel M.Bikel.Recovering latent information in treebanks[C]//COLING ’02 Proceedings of the 19th international conference on Computational linguistics-Volume 1,2002.
[15]Zhengping Jiang Statistical Chinese parsing[D].Singapore:National University of Singapore,2004.
[16]米海涛,熊德意,刘群.中文词法分析与句法分析融合策略研究[J].中文信息学报.2008,22(2):10-17.
[16]Slav Petrov,Dan Klein.Improved inference for unlexicalized parsing[C]//Human Language Technologies 2007:The Conference of the North American Chapter of the Association for Computational Linguistics; Proceedings of the Main Conference.Rochester,New York,2007:404-411.
[18]曹海龙,赵铁军,李生.基于中心驱动模型的宾州中文树库(CTB)句法分析[J].高技术通讯.2007,17(1):15-20.
[19]MaryP.Harper,Zhongqiang Huang.Chinese Statistical Parsing[C]//Joseph Olive,John McCary,and Caitlin Christianson (eds).Handbook of Natural Language Processing and Machine Translation.Defense Advanced Research Projects Agency,Reston Virginia,2011:90-102.
