SegT:一个实用的藏文分词系统
2012-06-28刘汇丹诺明花赵维纳贺也平
刘汇丹,诺明花,赵维纳,吴 健,贺也平
(1.中国科学院 软件研究所,北京 100190;2.中国科学院 研究生院,北京 100190;3.北京语言大学,北京 100083;4.青海师范大学, 青海 西宁 810008)
1 引言
藏文各音节之间由音节点分隔,但是词与词之间却没有分隔标记,同汉语类似,分词是藏文信息处理的基础。藏文分词的应用涉及藏文信息检索、文语转换、文本校正、机器翻译、文本分类、自动摘要等多个领域。本文首先回顾藏文分词的研究历史,然后在分析现有藏文分词方法和分词系统的基础上,设计实现一个藏文分词系统SegT,介绍其中的各主要模块的核心功能和实现方法,然后通过实验对系统进行了测试,并对结果进行了分析。
2 相关工作
1999年,扎西次仁在分析藏文分词中词表的不确定性、未登录词、切分歧义等问题的基础上,设计了一个采用最大匹配算法的人机互助藏文分词和登录新词的系统[1],由人监控机器分词的过程,纠正机器犯下的少量错误,但是“该系统尚不具备实用分词的功能”[2]。与此同时,罗秉芬等在500万字藏语真实文本语料分词的实践中归纳出藏文计算机自动分词的36条基本规则[3],首次对藏文的分词规范进行了研究。2003年,江荻以现代藏语形式语法为基础提出了藏语组块分析和块内分词的方法与过程[4]。同年,陈玉忠等在提出了一个基于格助词和接续特征分块的书面藏文分词方案,综合运用藏文字、词、句等各类形态特征,在藏文格助词、接续特征、字性知识库以及词典的支持下,采用逐级定位的确定性算法实现藏文的自动分词。基于此方案实现的分词系统在500句的测试集上的初步测试结果表明系统分词正确率在97%以上,且有不受领域限制、通用性强的特点[5-7]。2006年,祁坤钰在研究藏语形式逻辑格、语义逻辑格、音势论等语法理论的基础上,充分利用藏语上下文语境,在不同藏语句子层面采用不同的处理方法,格切分用于句子结构层面,边界符判定用于短语切分,模式匹配用于词块切分,提出了切分与格框架、标注一体化的藏语三级切分体系[8]。2009年,才智杰设计了“班智达藏文分词系统”,该系统首先使用四个属格助词和四个作格(又称具格)助词共八个“特殊格助词”对藏文进行分块处理,然后使用采用最大匹配方法进行分词,并采用“还原法”识别藏文中的紧缩词[9-10]。同年,孙媛等也在使用格助词分块方法的基础上设计并实现了藏文分词系统,该系统采用双向扫描的方法检测交集型歧义字段,并利用词频信息进行消歧[11-14]。江荻、陈玉忠、才让加、扎西加、关白、多拉等还对藏文词语分类体系和标注集进行了研究,总体上推进了藏文分词以及文本分析研究的进展,不再赘述。
总的来说,除了考虑藏文语言文字本身的特性以外,藏文分词仍然主要采用基于词典的最大匹配方法,应用于汉语分词的隐马尔科夫、最大熵、条件随机场等模型在藏文分词中还未能得以应用,究其原因,主要是因为目前还没有形成规模的藏文分词语料可用,无法对这些模型进行训练。
3 我们的系统
前述藏文分词的各种方法,主要有以下特点:一是使用了格助词及接续特征进行分块;二是核心算法大多采用基于词典的最大匹配方法;三是在最大匹配的过程中考虑紧缩词的识别。这三点是现有藏文分词系统共同的特点,只不过各个系统的侧重点有所不同。除此之外,已有系统开始考虑歧义字段的识别和消歧。
我们以上述方法为基础,构建一个藏文分词系统,并重点做到以下几个方面:一是增加分词词典的词汇量并提高词典的质量;二是提高格助词分块过程中临界词识别算法的效率;三是在紧缩词识别中采用音节分析技术,充分利用藏文特性提高紧缩词识别的正确率;四是检测交集型歧义字段,并根据大规模词频统计结果进行消歧。
下面首先介绍整个系统的流程,然后针对其中的关键问题介绍我们的方法。
3.1 系统流程
整个系统的流程如图1所示。系统首先对输入文本进行预处理,然后分句,再对每一句藏文使用格助词进行分块,并在分块过程中进行临界词的识别,在块内使用最大匹配方法进行分词,并同时进行藏文紧缩词的识别。分词可以按照正向最大匹配、逆向最大匹配、双向最大匹配等三种方式进行,在进行双向最大匹配之后,检测两种分词结果的歧义,并进行消歧,最后输出分词结果。

图1 分词流程图
3.2 分词词典整理
我们从《藏汉大辞典》、《汉藏对照词典》、《藏汉对照拉萨口语词典》等多部词典中提取藏文词条,并收集整理了普通词典未收录但在分词中应该作为一个分词单位的藏文语言成分,具体请参考藏文分词规范相关的文献。为了保证分词词典的质量,我们投入了大量时间进行人工筛选校对,最终形成分词用藏文词典,共包含近22万藏文词条。
3.3 词频统计
在进行分词消歧的过程中需要使用词频信息,所以如果没有词频信息就不能保证正确分词;然而,如果没有正确切分的藏文语料就不能准确统计藏文词频。我们采用迭代训练的方法进行词频统计来解决此问题。该方法不依赖于所用藏文语料的所属领域、主题、来源等因素,具有通用性。

图2 词频统计方法与过程图
如图2所示,首先对全部藏文语料分别进行正向最大匹配分词和逆向最大匹配分词,并分别对分词结果进行词频统计,然后将两种方法统计的词频(频次)累加作为初始词频。将初始词频作为第一轮迭代词频,使用双向最大匹配分词,检测切分歧义并利用迭代词频进行消歧,这样对全部藏文语料进行切分,形成第一次切分语料,再对切分语料进行词频统计,得到第二轮迭代词频。如此循环,直到本轮迭代词频与上一轮迭代词频的差异小于阈值。最后一轮迭代得到的词频信息在经过人工校对之后可以近似认为是真实文本的词频。
词频统计中用到的藏文语料主要包括《邓小平文选》第二卷、《江泽民文选》第一、二、三卷、《中办通讯》、《西藏政报》、《西藏通讯》、国家历年法律法规、西藏自治区地方法规、部分其他书籍以及从部分藏文网站上抓取的网页。语料总规模达到35.6M,共计23万藏文句子,累计词频2 850 322。经过统计,我们发现对于词频统计所用语料来说,分词词典中只有45 740个词条是有效的(词频>0),只占分词词典的21%。因在词频统计过程中暂未全面考虑语料所用藏文文本的代表性和平衡性等因素,该词频数据只在一定范围内有效。但我们保证了所有词的频次是在对相同规模的语料进行统计的基础上得到的,避免使用不同来源的词频数据带来的问题。
3.4 预处理和分句
由于文字处理软件对藏文的断行规则支持不完善,为了符合藏文排版的特性,编辑人员经常在每行的行尾人工插入回车换行符。为了不影响分词结果,需要将这些多余字符删除。

3.5 临界词的快速识别方法
在格助词分块的过程中,我们采用了文献[10]中的方法,以八个“特殊格助词”为标志进行分块。由于部分藏文词本身就包含了“特殊格助词”作为子串(文献[10]中将这些词称为“临界词”),为了不致错误切分,必须识别这些临界词。在我们的分词词典中,包含临界词共计13 936条。采用格助词分块的初衷是利用格助词是藏文天然的词边界这一特性,提高了分词的效率和准确率;而识别临界词是为了避免在格助词分块过程中错误地将词典中包含的词切断。在临界词识别过程中如果采用与最大匹配类似的算法,则将违背其初衷。下面介绍我们的方法。
记“特殊格助词”的集合为:

假设包含“特殊格助词”的藏文句子S由n个音节构成,其中第i个音节是“特殊格助词”,即
若临界词最大长度为m个音节(假设n≥2m-1),则临界词可能的左边界和右边界均有m个,需要查词典共计(1+2+…+m)=m(m+1)/2次,即使词典查询算法的时间复杂度是O(1)的,整个临界词识别算法的时间复杂度也要达到O(m2),这将与最大匹配方法的时间复杂度相同,则整个系统的分词速度与不使用格助词分块直接应用最大匹配方法相比将不可能有明显提高。
我们使用Trie树来降低临界词识别算法的时间复杂度。假设临界词W由n个音节构成,其中第i个音节是“特殊格助词”,即:
则其含格助词前缀是:
含格助词逆序前缀(下称“逆序前缀”)是*严格地讲,藏文音节有多个字符构成,单个音节的逆序与其自身并不相同,方便起见,此处忽略其差异。:
其含格助词后缀(下称“后缀”)是:

3.6 紧缩词的识别
3.7 切分歧义检测
对于任意由n个音节构成的藏文句子S:
若正向最大匹配和逆向最大匹配分别给出了不同的分词结果WA和WB,分别切分出了n和m个词(m≠n),即:
则存在k使得Wak≠Wbk,而对于任意的i 图3 交集型歧义检测示意图 记D(i,j)=Len(Wi)+Len(Wi+1)+…+Len(Wj),i 其中Len(Wi)指藏文词Wi的长度(字符数)。这样D(i,j)就是从第i个词到第j个词的总长度,从k向后扫描,必存在i和j,使得D(k,i)=D(k,j),但对于任意的i′ 在汉语分词中,分词消歧一般采用最大概率分词方法,该方法计算对歧义字段的每种切分方法切分出来的词串的概率,并取概率值最大的词串作为切分结果。但是最大概率分词算法需要对词频统计结果进行归一化和数据平滑处理。我们借鉴最大概率分词的思想,设计了更便于实现的方法。 对于藏文词典G中的词条W,记freq(W)为W的词频(频次),定义消歧能力函数如下: F(W)= 我们认为,对于藏文来说,22万词条的词典规模是相当大的,在消歧过程中应该将词典中不存在的词(应用最大匹配方法此时都是单个音节)和词频为零的词区别对待,所以在消歧能力函数中对这两类词分别取不同的值。而对于词频大于零的词,我们认为词频分别为2 000和1 999的两个词的消歧能力差异要小于词频分别为20和19的两个词的消歧能力差异,为此,我们在消歧能力函数中使用关于词频的对数函数衡量消歧能力。 对于歧义字段的每个候选切分结果来说,整个词串的消歧能力F是其每个词Wi的消歧能力的累加F=∑F(Wi),并取使F最大的切分结果作为消歧结果。 下面,我们通过两个实验分别考察格助词分块对分词系统的效率影响,以及正向、逆向、双向匹配消歧等方法的分词效果。 我们从语料中选择了包含藏文词数最多的六份藏文语料,共包含藏文78 421句,近90万词。对每份语料,我们分别直接按正向最大匹配、逆向最大匹配、双向匹配消歧三种方法进行分词,并分别启用格助词分块功能,与启用之前作比较。表1列出了统计结果,在启用格助词分块功能之前,三种方法对六份语料的分词过程分别耗时19 500ms、19 516ms、29 829ms,在启用之后,耗时分别降为16 580ms、16 673ms、24 578ms,分词速度比之前分别提高了14.97%、14.57%和17.60%。对单个文件的分词,最多节省时间达到了26.72%。图4显示了格助词分块对分词效率的提高效果。这样的测试结果表明,我们设计的格助词分块和临界词识别方法对于分词效率的提高是十分明显的。 表1 启用格助词分块前后的分词时间消耗对比 图4 格助词分块对分词效率的提高 在系统的开发期间,我们从语料库中选择了部分文章作为开发集,进行了较大规模的测试,检查系统中存在的问题,并对所使用的规则和词典进行了初步修正。然后,我们从23万句的藏文语料中随机抽取了4 000个藏文句子。其中的3 000句作为训练集,使用本系统切分,由人工检查其中存在的问题,然后对规则和词典进行了进一步修正。另外1 000句作为测试集,由系统初步切分,然后经过反复数次的人工校对,形成标准文本,用于系统评测。 我们将采用正确率(P)、召回率(R)、F值三个指标对系统进行分词正确性评测。这三个指标的计算方法如下: 测试数据如表2所示,系统正确率(P)最高达到了96.987 5%,召回率(R)最高达到了96.911 2%,F值最高达到了96.949 3%。图5对正向最大匹配、逆向最大匹配、双向匹配消歧三种方法的分词效果作了对比,其中逆向最大匹配方法的效果最差,相比之下,正向最大匹配方法的效果提高了约1.8个百分点,双向匹配消歧的效果最好,比正向最大匹配方法提高了约1.5个百分点,说明我们的歧义检测和消歧方法是有效的。 表2 分词正确性测试数据 图5 三种方法的分词正确性对比 图6 使用格助词分块前后的切分正确率对比 在测试中,使用双向匹配消歧方法共有421个词切分错误。其中有306个由交集型歧义引起,占72.68%,有71个由组合型歧义引起,占16.86%,有28个由未登录词引起,占6.65%,另有少部分错误由其它因素引起。在统计分词错误的过程中我们发现,如果继续对词典进行修正,系统的正确率还有进一步提高的可能。 在分析现有藏文分词方法的基础上,我们设计实现了一个藏文分词系统SegT,该系统使用格助词分块和最大匹配方法进行分词,采用双向切分检测分词歧义并使用预先统计的词频信息进行消歧。实验数据显示,本文所设计的格助词分块和快速临界词识别方法可以将分词速度提高15%左右。 由于最大匹配分词方法对词典的依赖性非常大,我们在分词词典整理工作上投入了大量的时间。最终在1 000句的测试集上进行了系统评测,系统的分词正确率为96.98%,基本达到了实用水平。我们同时测试了格助词分块对于分词结果的影响,测试数据表明,格助词分块对于分词正确率没有明显提高或者降低。 本文所用分词词典和测试语料由西藏大学工学院杨毛卓玛、官却多杰、索南扎西人工校对,作者在此表示衷心的感谢! [1]扎西次仁.一个人机互助的藏文分词和词登录系统的设计[C]//中国少数民族语言文字现代化文集,北京:民族出版社,1999. [2]江荻.藏语文本信息处理的历程与进展[C]//中文信息处理前沿进展——中国中文信息学会二十五周年学术会议论文集.北京:清华大学出版社,2006:83-97. [3]罗秉芬,江荻.藏文计算机自动分词的基本规则[C]//中国少数民族语言文字现代化文集,北京:民族出版社,1999. [4]江荻.现代藏语组块分词的方法与过程[J].民族语文,2003,(4):31-39. [5]陈玉忠,俞士汶.藏文信息处理技术的研究现状与展望[J].中国藏学,2003,(4):97-107. [6]陈玉忠,李保利,俞士汶,等.基于格助词和接续特征的藏文自动分词方案[J].语言文字应用,2003,(1):75-82. [7]陈玉忠,李保利,俞士汶.藏文自动分词系统的设计与实现[J].中文信息学报,2003,17(3):15-20. [8]祁坤钰.信息处理用藏文自动分词研究[J].西北民族大学学报(哲学社会科学版),2006,(4):92-97. [9]才智杰.班智达藏文自动分词系统的设计[C]//中国少数民族语言文字信息处理研究与进展——第十二届中国少数民族语言文字信息处理学术研讨会论文集,2009. [10]才智杰.藏文自动分词系统中紧缩词的识别[J].中文信息学报,2009,23(1):35-37. [11]孙媛,罗桑强巴,杨锐,等.藏语自动分词方案的设计[C]//中国少数民族语言文字信息处理研究与进展——第十二届中国少数民族语言文字信息处理学术研讨会论文集,2009. [12]Yuan Sun,Zhijuan Wang,Xiaobing Zhao,et al.Design of a Tibetan Automatic Word Segmentation Scheme[C]//Proceedings of 2009 1st IEEE International Conference on Information Engineering and Computer Science,2009:1-6. [13]孙媛,罗桑强巴,杨锐,等.藏语交集型歧义字段切分方法研究[C]//中国少数民族语言文字信息处理研究与进展——第十二届中国少数民族语言文字信息处理学术研讨会论文集,2009. [14]Yuan Sun,Xiaodong Yan,Xiaobing Zhao,et al.A resolution of overlapping ambiguity in Tibetan word segmentation[C]//Proceedings of 2010 3rd International Conference on Computer Science and Information Technology,2010.222-225. [15]胡书津.简明藏文文法[M].昆明:云南民族出版社,2000.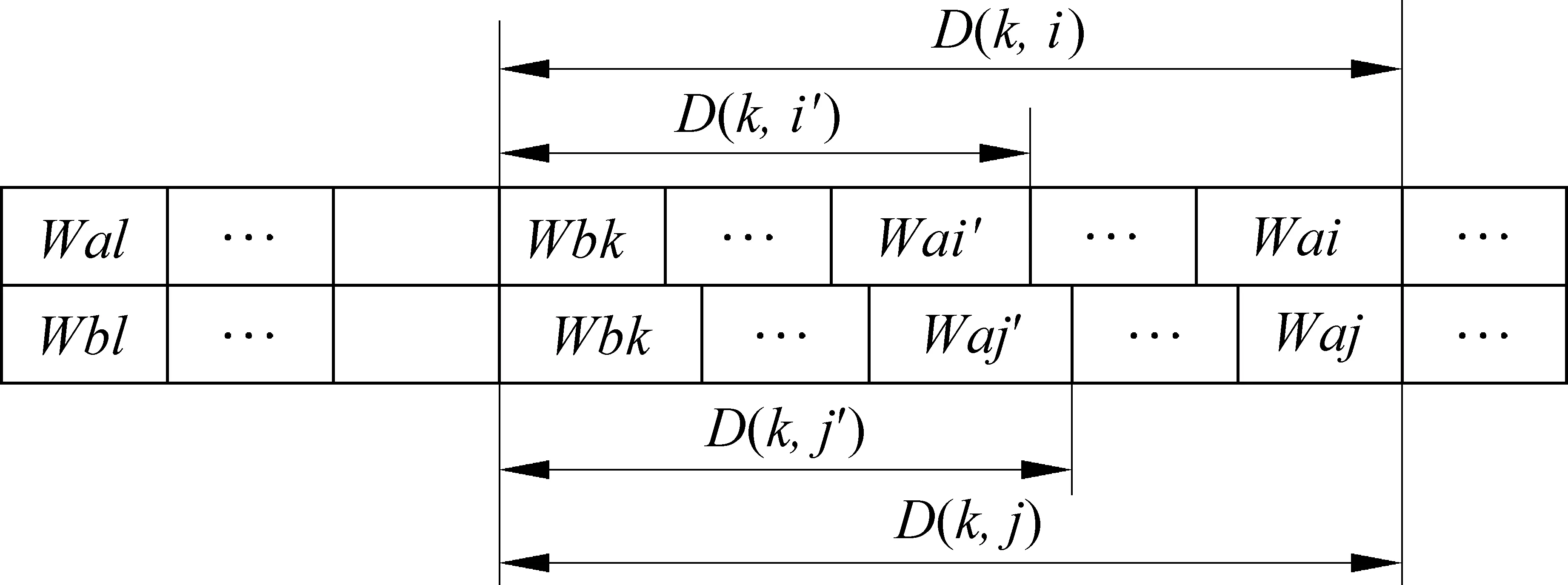
3.8 分词消歧
4 实验方法与结果
4.1 格助词分块的效率


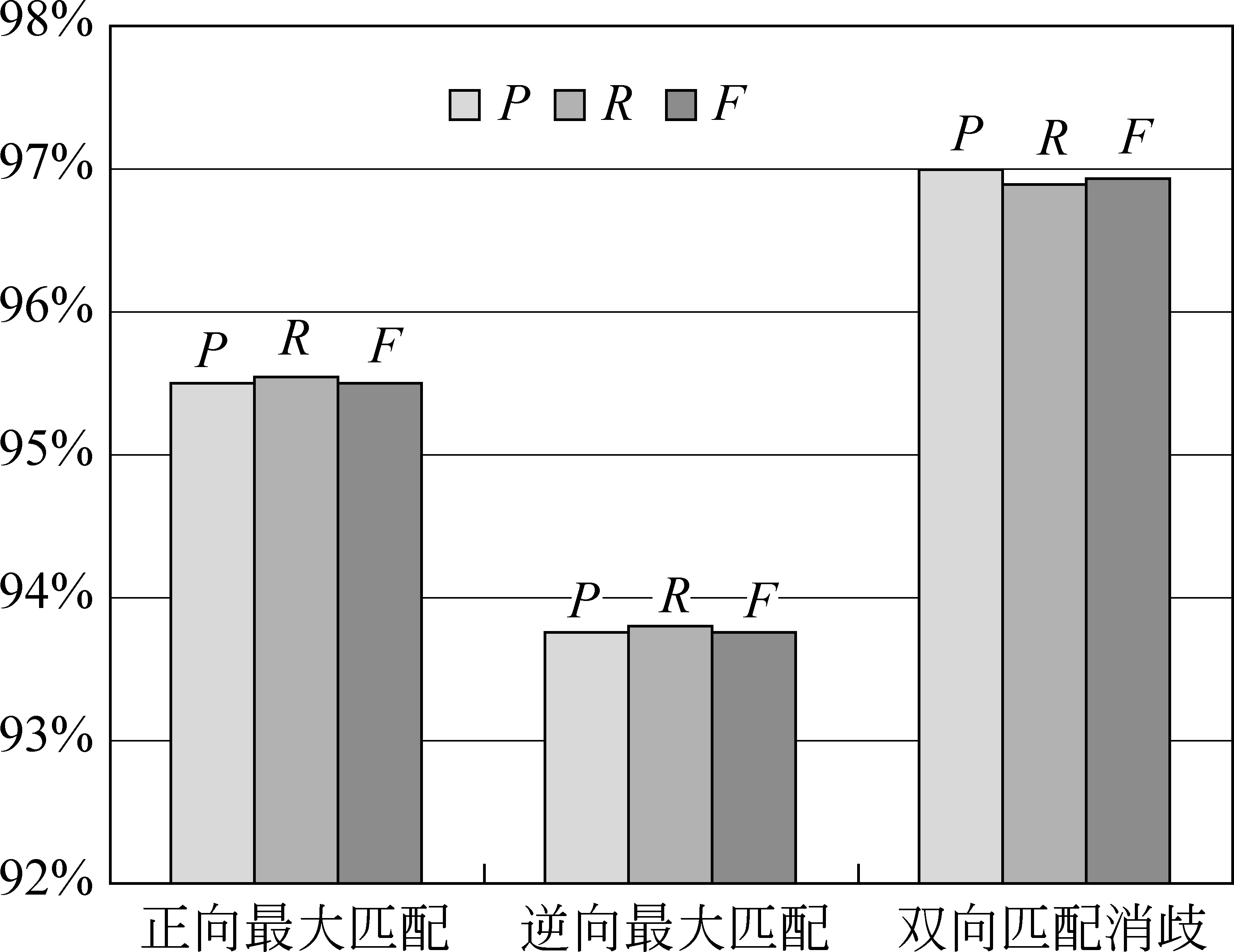
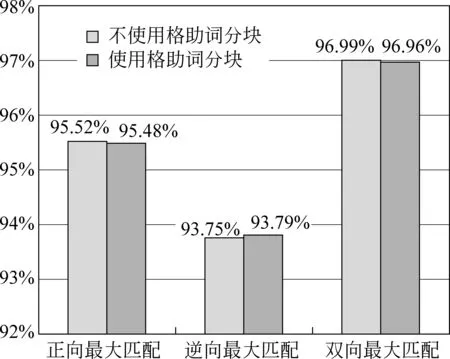
4.2 分词正确性评测


5 结束语
致谢
