基于词共现的文档表示模型
2012-06-28常鹏,冯楠
常 鹏,冯 楠
(1.天津大学 管理学院,天津 300072; 2.天津大学 网络与信息中心,天津 300072)
1 引言
随着信息技术的发展,特别是互联网的普及,电子化的信息资源呈爆炸式增长,已经远远超出了人类的认知与理解能力,只有借助计算机的高效处理才有可能从中获取人们感兴趣的知识与信息。在这些信息资源中,文本信息占绝大部分,而文本信息是一种半结构或无结构的数据,传统数据挖掘算法无法直接适用于文本挖掘,因此,将无结构的文本信息转化为结构化信息是文本挖掘的关键性、基础性的问题。传统的文档表示模型以向量空间模型(Vector Space Model,VSM[1])为主,然而,由于VSM只考虑了词频信息,而忽略了很多重要的信息,它无法达到更高的准确率。近年来很多学者利用自然语言处理的技术,来提高信息检索的性能,其中词的共现(Co-Occurrence)现象是研究的热点之一。本文从词的共现现象着手,分析了词的共现现象与文档主题之间的关系,进而提出了基于词共现的文档表示模型,定义了基于CTVSM的文档相似性度量方法。实验表明CTVSM可以有效地表达文档的主要特征,具有更好的文档区分能力。
2 相关工作
文档建模可以分为基于概率模型的方法与基于空间向量的方法,其中基于空间向量的VSM[1]可以算得上是应用最为广泛的文档表示模型,目前文本挖掘的算法大部分都是建立在VSM之上的。尽管VSM在信息检索与文本挖掘等领域的应用获得了极大的成功,它还是存在一些缺点:1)随着文本规模增大,向量空间的维数也迅速增大,造成了“维数灾难”,现有文本挖掘算法的性能急剧下降;2)由于忽略了词与词之间的语义相关性,同义词与多义词等语言现象导致了算法准确性的下降。
针对于VSM忽略的词间的关联关系,一些学者试着从更高的层次来建立文档表示模型,典型的代表是Feldman提出的从“Term”的层面来建立文本的特征[2],从而提高文本挖掘的质量,其中,“Term”被定义为有意义的词串。词串的引入可以消除词的歧义现象,然而词串的抽取需要满足特定的语法结构,例如,“名词—介词—名词”、“形容词—名词”等,这为词串的抽取带来一定的难度。Hammouda提出一种基于短语的文档标引图(Document Index Graph,DIG)[3]文本表示模型,短语被定义为排序的词的组合,通常运用统计的方法抽取词汇的二元组和三元组。高茂庭等人则提出了基于DIG的相似度计算改进算法[4],将抽取出的短语作为VSM中词向量的补充,提高了DIG的文档区分能力。
文档间相似度计算算法对文档的区分能力直接影响着文本挖掘与信息检索的效果,因此国内的学者们则普遍关注文档间相似度计算的问题,并取得了一定的成果。潘谦红、史忠植等以属性论为理论依据,建立文本属性重心剖分模型[5],并在属性坐标系中表示文本向量与查询向量,确立了向量间的匹配基准,从而建立了文本与查询式之间的相似度计算公式。晋耀红提出了基于语境框架下的文本相似度计算方法[6],将文本内容抽象成领域、情景与背景三个侧面,从而使文本之间的语义相似度得以量化。曹恬等人则提出利用词共现信息来改进文本相似度计算算法[7],用相关词序列的相似度贡献值来修正基于VSM的相似度计算公式。张燕平等人提出基于词共现的垃圾邮件过滤方法[8],利用词共现模型有效提高了邮件的特征提取准确度。贾西平等人提出基于主题的文档检索模型[9],利用LDA学习文档中的主题分布,从而建立主题向量空间,在主题空间内用文本主题向量的余弦夹角来计算文本相似度。
综合上述国内外学者的研究成果,可以看出文档表示模型及建立在其上的文档相似度计算方法受到了学者们的持续关注。其中大部分学者的工作是建立在VSM基础之上,对其进行了改进研究。从学者们的研究思路来看,主要有两条思路:1)从更高的语言层次描述文档,例如:短语、概念、主题;2)降维处理,选择最能代表文档主要特征的词汇,构造文档特征向量,其中前者是目前学者们最为关注的领域。然而,目前对文本表示模型的研究尚存在一定的局限性,大部分研究并未摆脱VSM的影响。本文从词共现现象开始,分析词共现与文本主题之间的内在联系,在文档建模中引入词共现组合的概念,建立了基于词共现的文档表示模型,从而更加精确地描述了文本的主题特征。
3 基于词共现的文档模型
3.1 词的共现现象
通常,文本中出现的词汇都是为了帮助作者表达其主题思想,因此都可以作为主题相关词汇,只不过与主题的相关程度有所不同。文档建模的目的就是找出与主题密切相关的词汇,进而利用这些词汇代表文档的主要特征。就像客观存在的事物一样,词汇也有其领域标签。因此,相同领域或主题内的词汇共同出现在同一篇文档中的概率相对较高,利用词的共现现象可以判断词汇与主题之间的相关程度。
假设文档空间D上有主题集合T和词汇集合W,其中,di∈D代表第i篇文档,tk∈T代表文档空间中的第k个主题,S(tk)为主题tk的主题相关词集合,wm∈W为文档中出现的词汇。在主题tk出现的情况下,词汇wm出现的条件概率可表示为P(wm|tk)。则有如下定义。
定义1:显著性事件是指发生概率较高的事件,即满足P(•)>θ的事件为被称为显著性事件,其中θ为显著性判别标准。通常显著性事件的判别标准与文档集的规模以及主题在文档空间中的分布有关。
根据Hoffman提出的概率潜在语义分析模型(Probabilistic Latent Semantic Analysis,PLSA)[10]。对应潜在的主题变量,定义在W×W上的联合概率模型如定义2所示。
定义2:共现率词汇wi与wj的共现率是指这两个词在同一语言单位中共同出现的概率,即它们在文本空间中的联合概率,如公式(1)所示:
(1)
∀wi,wj∈W
公式(1)的图模型描述如图1所示。
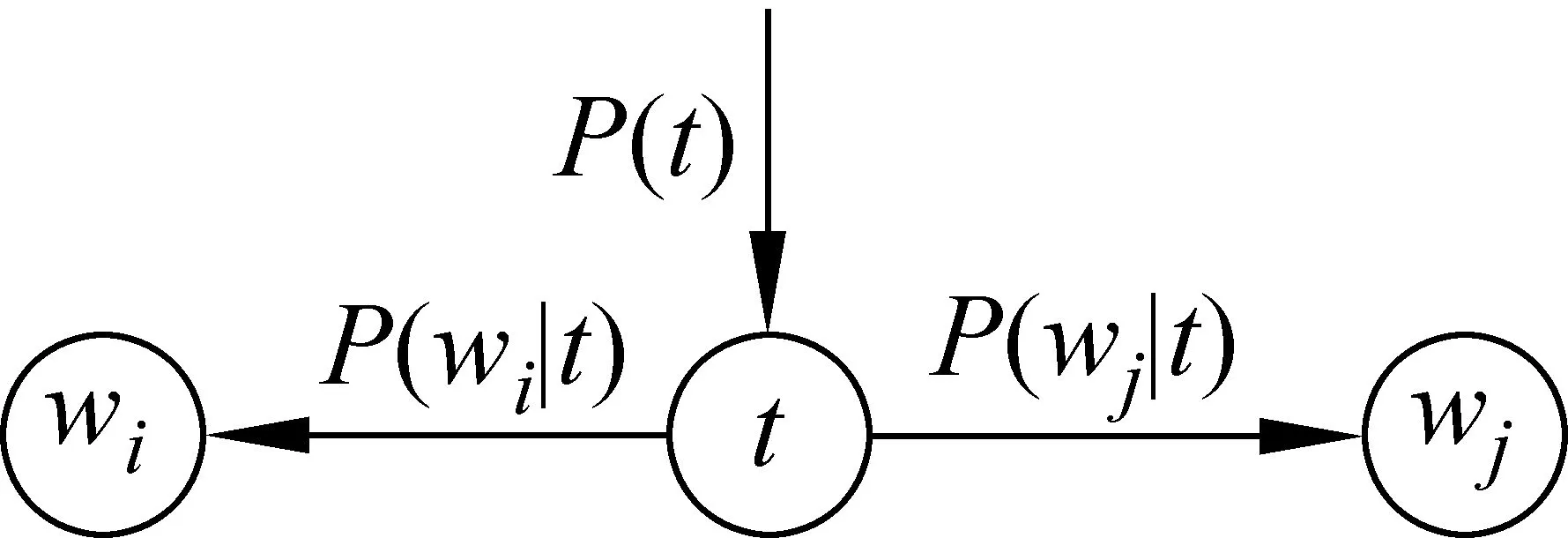
图1 PLSA(相位模型)的图模型
定义3:主题相关当P(wm|tk)为显著性事件时,即P(wm|tk)≥θ,wm是tk的主题相关词汇,称wm与tk主题相关。
定义4:主题无关当P(wm|tk)为非显著性事件时,即P(wm|tk)<θ,wm不是tk的主题相关词汇,称wm与tk主题无关。
推论1:两个词汇的共现为显著性事件,则这两个词汇与某个共同的主题相关。即:当P(wi,wj)≥θ时,∃tk使得P(wi|tk)≥θ且P(wj|tk)≥θ。
证明:
根据定义2可知
已知P(wi,wj)≥θ,不妨设
P(wi,wj)>P(tk)P(wi|tk)P(wj|tk)≥θ
因为P(•)∈[0,1],且在实际数据中词汇在文本集上的后验概率以及主题分布要远小于1,所以:
推论1得证。
在文档空间中,两个词汇的共现率是比较容易通过统计的方式获取的,根据推论1可知,如果两个词汇的共现率超过一定的阈值,就预示着这两个词是主题相关的。
3.2 词的共现率计算
根据定义2可知,词的共现率是两个词在同一主题内同时出现的概率之和,然而在实际文档建模过程中,主题是文本的隐含变量,无法准确获得。因此,通过统计两个词在文本中共现的次数计算它们的共现率。假设一个窗口单元(例如,一句话、一个段落)代表一个主题,文档空间中有n个窗口单元,则主题的先验概率为P(t)=1/n。当词w在窗口单元出现,则其后验概率为P(w|t)=1。则根据公式(1),如果词wi和wj共同出现在x个不同的窗口单元中,它们的联合概率为P(wi,wj)=x/n。因此词的共现率可以由公式(2)计算得出。
式中,Segment(wi,wj)表示文档空间中同时包含wi和wj的窗口单元集合,Segment表示文档空间中的窗口单元集合,‖•‖表示集合中的元素个数。例如,将窗口单元设为一个自然段,则自然段内出现的词汇对视为它们的一次共现。
3.3 共现词组合的抽取
共现词组合的抽取过程类似于利用关联规则的数据挖掘方法发现事务中频繁项集的过程。文档中的自然段被视为一个事务,自然段中出现的词汇视为事务包含的项。通过关联规则挖掘算法,挖掘项之间的关系。其中项的支持度由公式(3)表示,置信度由公式(4)表示。
由于共现词组合为二元组,所以只考虑二元组的规则抽取。给定关联规则挖掘空间S=(T,I,R,θ),其中含义如下:
(1)T={t1,t2,...,tn}为S上的事务集合(Transaction Set),其中tn∈T为S上的事务,即文档中的自然段;
(2)I={i1,i2,...,im}为S上的项集(Item Set),im∈I为d上的项,即文档中的候选词汇;
(3)R={r1,r2,...,tk}为T中蕴含的规则,其中rk=(ix,iy),ix,iy∈I,即抽取出的共现词组合;
(4)θ={α,β}为S上的约束,α和β分别为给定的支持度与置信度的阈值。
则在空间S上的“事务—项”矩阵可以表示为m×n的矩阵。其中行向量代表一个事务t,列向量代表项i,矩阵为0-1矩阵。如果事务tn包含项im,则矩阵中对应的第n行m列的值为1,否则为0。则S上的支持度与置信度可以转化为以下的代数形式:
在上述定义的关联规则挖掘空间S上,本文设计了一个简单高效的挖掘算法,算法如下:
算法1:关联规则挖掘算法
输入:事务数据库
输出:规则集
过程:
(1)扫描事务数据库,构造m×n的“事务—项”矩阵;
(2)生成I上的所有二阶的项组合(ix,iy),∀ix,iy∈I
(3)在项组合集上循环,利用公式(5)和(6)计算项组合(ix,iy)的支持度与置信度。如果支持度和置信度大于设定阈值,则将该项组合加入R。
(4)返回规则集R,算法结束
此算法只在算法开始时读取一次数据库,即将所有数据读到内存中,之后利用矩阵运算得到项集上的支持度与置信度。同时算法的复杂度也大大降低,复杂度为O(m2)。
3.4 CTVSM
与VSM的建模思想类似,CTVSM也将文档表示为一个共现词组合的向量。设文档空间D={d1,d2,...,dn}中包含n篇文档,在D上抽取出的共现词组合的集合为C={c1,c2,...,cm},其中cm为抽取出的第m个共现词组合。则文档空间D可表示为一个m×n的矩阵。其中行向量di=(ci1,ci2,...,cim)代表一篇文档,列向量cj=(c1j,c2j,...,cnj)T代表一个共现词汇组合在各文档中的分布情况。矩阵中的元素cij表示文档di中共现词汇组合cj的分布情况,如果共现词汇组合出现则相应的权值为1,如果不出现,则相应权值为0,如公式(7-9)所示。
4 基于CTVSM的文本相似性度量
4.1 文档距离
在CTVSM中,将文档看作高维空间中的一个向量,每个共现词组合作为空间中的一个维度,则文档间的距离定义如下。
定义5:文档距离文档的距离是两篇文档在CTVSM中相异的共现词组合的度量,给定两篇文档di和dj,共现词组合矩阵C,它们之间的距离为(式10):
距离在一定程度上可以反映出两篇文档的相似性,即反映出了两篇文档之间不同的共现词对个数。
4.2 文档的相似性
定义6:文档相似性文档的相似性是两篇文档在CTVSM中相同的共现词组合的度量,给定两篇文档di和dj,共现词组合矩阵C,它们的相似性定义如下:
根据定义可知在两篇文档中共同包含的共现词组合个数越多,它们的相似性越大。
4.3 文档的相关度
在文本处理中,文档之间的相关度比较是个常见的问题,文档之间的相关程度与它们之间的相似度以及距离有关,文档之间的距离越大表明文档的差异越大,而文档之间的相似度越大表明文档的主题重合度越大。然而,仅仅用距离或者相似度是无法准确反映文档之间的相关程度的,例如,在CTVSM中,文档A、B与文档C具有相同的相似度(相同的共现词组合个数),但是由于A、B与C的不同的共现词组合个数不一定相同(距离不相等),实际上应当距离越小的相关度越大。因此,文档之间的相关度定义如下。
定义7:文档相关度文档的相关度是文档之间主题相关的度量,它综合了文档距离及相似度指标。给定两篇文档di和dj,共现词组合矩阵C,它们的相关度定义如下:
5 实验与讨论
5.1 实验数据
本文选用互联网上的新闻文档作为实验数据,从百度新闻搜索中,搜索“天然气”的相关新闻,得到关于“北方降温,天然气短缺”的新闻15篇,关于“天然气爆炸”的新闻5篇,关于“韩国总统卢武铉跳崖自杀”的新闻5篇。其中,大部分文本为报道性的短篇新闻。经过分词和去除停用词(对文档分类作用不大的助词、副词以及常用词)处理后,得到1 480个词汇,其中仅出现一次的词汇数量为862个,出现一次以上的词汇为618个。本章在此文本集上进行了共现词组合抽取、文档相似度计算及分类的操作,以验证CTVSM是否有效。
5.2 实验过程与讨论
(1)共现词抽取
本文首先在文本集上抽取了共现词组合。为了对比不同词语上下文范围对抽取结果产生的影响,本文采用了两种不同的上下文范围。分别以段落和句子为单位进行共现词组合的抽取,即以段落为上下文有效范围的共现词组合抽取中,在一个段落范围内,如果两个词同时出现,则认为它们共现一次;以句子为单位的抽取中,则需要统计它们共同出现在哪些句子中。在进行中文分词的时候,记录每个词出现的段落及句子,以便于统计。
共现词抽取算法采用本文提出的关联规则挖掘算法,详见算法1。支持度阈值设为0.01,置信度阈值设为0.5。经计算,以段落为单位的共现词组合抽取算法抽取出了273条规则,而基于句子的共现词组合抽取算法只抽取出25条规则,抽取出的部分规则如表1所示。
从两个不同语境单元中,抽取出的具有较高支持度与置信度的共现词组合基本一致,从字面上可以看出,这些共现词组合中的词汇都是主题相关的词汇。从词语的搭配角度来看,以语句为语境单位的共现词抽取结果更为合理, 因为在同一句子中的词汇是具有主题高度相关性和词语搭配可能性更高一些。然而,由于文本集上的句子数量远大于段落数量,因此共现词汇的支持度有所下降,然而置信度却保持了较高的水平。将支持度阈值降低到0.005时,抽取出的规则有所增多,增加到124条。
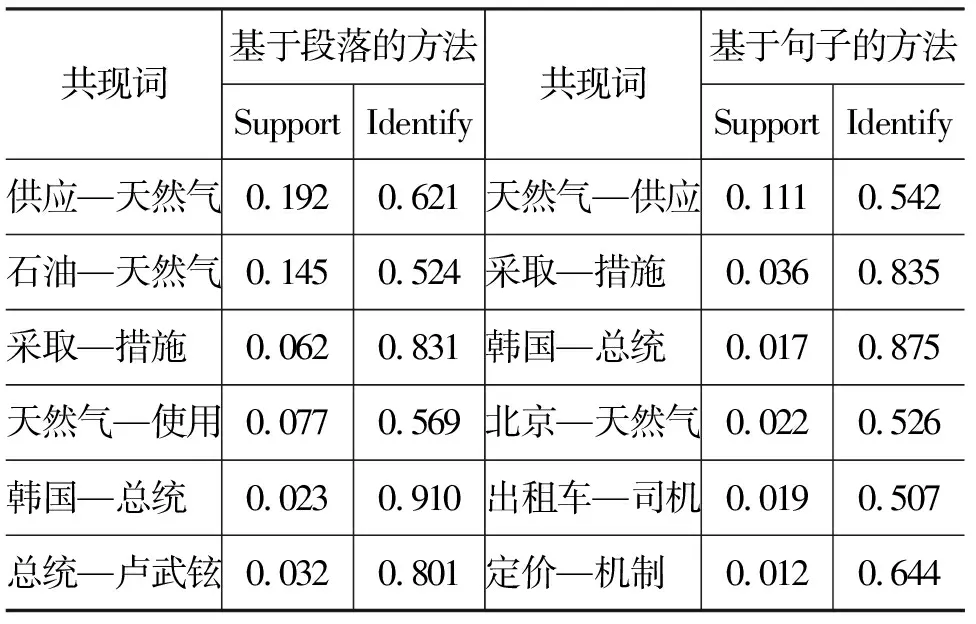
表1 抽取出的部分共现词组合
文档集抽取出的共现词组合数量对文档主题的表达有着直接的影响,降低支持度与置信度阈值相当于降低共现词组合抽取门槛,共现词组合数量增多但是质量降低,而增加相关的阈值参数则提高了质量降低了数量。为了验证此论断,本文选择了一系列不同的阈值进行文档聚类的实验,对比不同阈值下,抽取出的共现词组合对文档主题表达的准确性。实验分别采取固定置信度阈值变动支持度阈值和固定支持度阈值变动置信度阈值的方法,考察不同支持度阈值、置信度阈值组合下对聚类结果的影响。实验结果如图2所示。在不同支持度阈值下的F-measure值变化如图2(a)所示。可以看出在支持度阈值取区间[0.003,0.005],置信度阈值取0.5时,聚类结果准确率最高,达到0.976。即在此参数设置下抽取出的共现词集合的规模是合适的,共现词集合已经可以表现出文档的主要特征。随着支持度阈值的减小,共现词集合规模增大,一些噪音被抽取出,导致了聚类结果的下降。
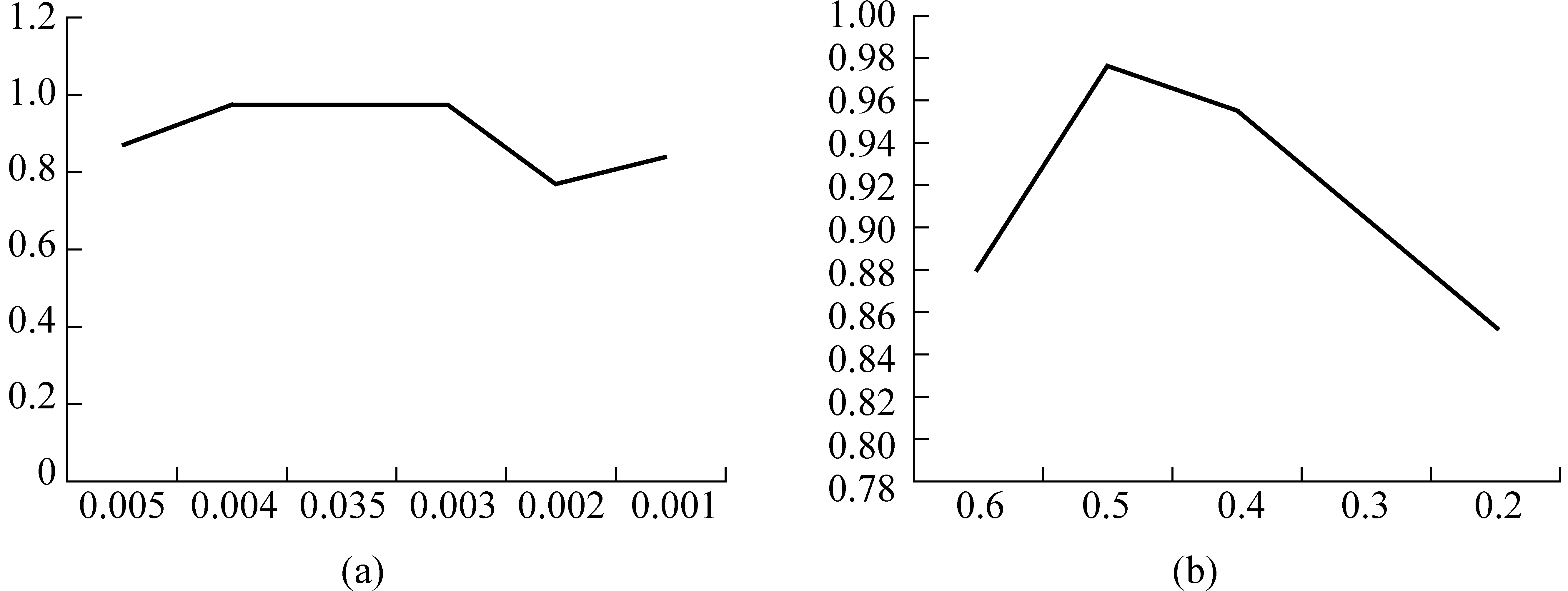
(a)置信度阈值固定,支持度阈值变化; (b)支持度阈值固定,置信度阈值变化
(2)相似度对比实验
在文档的相似度对比实验中,比较了不同文档分布在VSM与CTVSM空间中的相似度。经过分词与去除停用词,得到词汇1 480个。为了减低计算复杂度,将只出现一次的低频词汇去除,得到618个词汇。而在文档集上抽取出的共现词组合数为273条(基于段落)与124条(基于语句)。采用余弦夹角公式计算VSM中的文本相似度;采用公式(12)计算CTVSM中的文档的相关度。实验结果如表2所示。
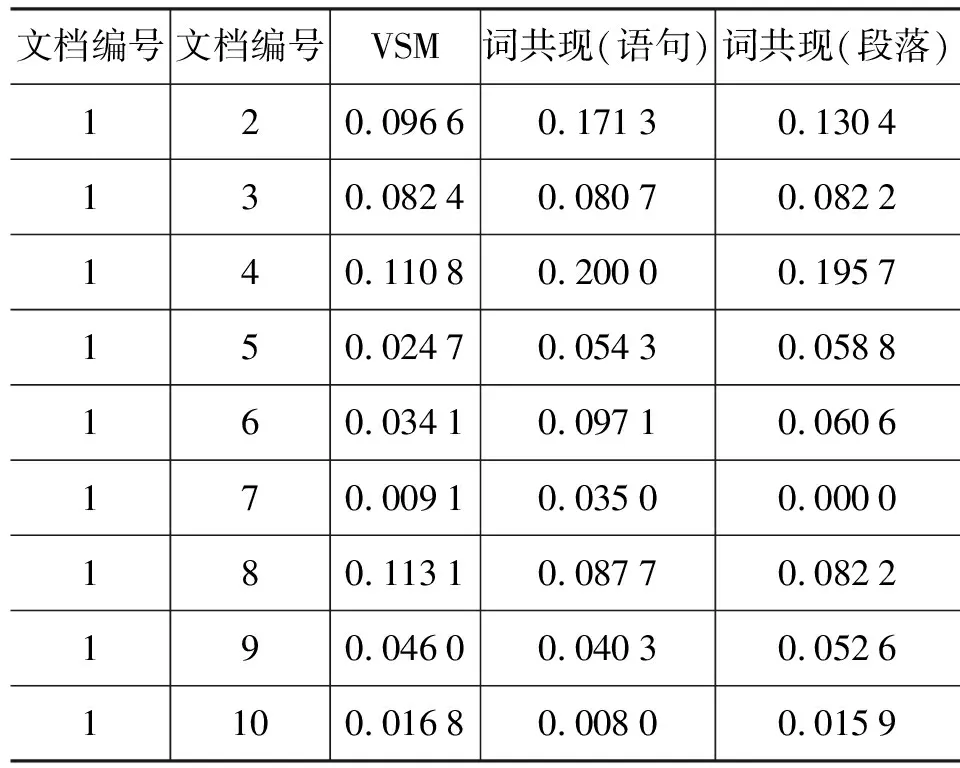
表2 文档相似度对比(部分结果)
以编号为1的文档与其他文档的相似度为例,分别对比了三种计算方法得到它与其他文本的相似度,如图3所示。
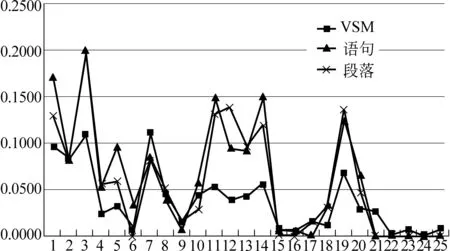
图3 三种相似度的比较
从实验结果可以看到三种相似度的趋势基本保持了一致,即对于相似的文档三种算法得到的相似度较高,而对于不相关的文档相似度都比较低。这说明基于词共现组合的文档表示模型是能够反映出文档之间的差异性的。此外,基于段落语境构建的共现词空间与基于语句语境构建的共现词空间,在空间维数相当的情况下,计算得到的相似度基本一致。这说明语境范围的大小对文档建模精确度影响是不大的,抽取出的共现词组合的个数才是影响建模有效性的关键因素,即文档空间的维数是影响文档表示模型的关键因素。
此外,VSM与CTVSM有一个明显的区别,即VSM的文档相似度的方差较小,即使两篇文档的主题不一致,但是因为它们都包含了相同的词语,从而导致了相似度不会变的很低,然而,CTVSM中,不同主题之间的文档相似度降到很低(低于VSM),而相同主题的文档相似度又变的很高(高于VSM)。例如,在本实验中,关于天然气的两个不同主题,由于它们都是包含天然气这一关键词,因此,在VSM中,这两个主题之间的文档相似度也比较高,而CTVSM中,由于两个主题之间的文档抽取出的共同的词汇组合较少,因此,它们之间的相似度很低。由此,可以看到CTVSM中得到的文档相似度是主题敏感的,他能有效过滤多义词带来的负面影响。特别是在文档分类及聚类研究中,此特性将有助于显著区分不同主题下文档的相似度。
(3)文档聚类实验
对实验数据分别在VSM与CTVSM空间中进行聚类实验,聚类算法采用层次聚类算法,最优层次划分的判断标准采用聚类增益[11]。聚类过程中的聚类增益如图4所示。
在进行到61步附近时VSM与CTVSM中的聚类增益均达到最大值,比较聚类增益取得最大值的层次划分的F-measure值,在VSM中达到最优层次划分时的F-measure值为0.76,而在CTVSM中达到最优层次划分时的F-measure值为0.97。实验结果表明,在CTVSM下聚类结果得到了显著的提高。
6 结论
本文通过对词共现的分析,挖掘出词汇共现现象背后的主题关系,提出词汇的共现在一定程度上可以反映出主题的发生模式。进而设计了一个在文档集上抽取共现词组合的抽取算法,并利用文档空间上的共现词组合构建了文档表示模型。实验证明,该文档表示模型是有效的,在文档相关度的度量中比VSM下具有更好的区分度,而且在CTVSM下文档聚类的效果得到了显著提高。

(a)VSM; (b)CTVSM(0.004,0.5)
[1]Salton G,Wong A,Yang C S.A vector space model for automatic indexing[C]//Communications of the ACM,1975,Vol.18 (11):613-620.
[2]Feldman R,Aumann Y,et al.Text Mining at the Term Level[C]//Proceedings of the 2nd European Symposium on Principles of Data Mining and Knowledge Discovery.Nantes,France,1998,23-26.
[3]Hammouda K,Kamel M.Efficient Phrase-based Document Indexing for Web Document Clustering [J].IEEE Transactions on Knowledge and Data Engineering,2004,16(10):1279-1296.
[4]高茂庭,王正欧.基于文档标引图模型的文本相似度策略[J].计算机工程,2008,34(7):19-22.
[5]潘谦红,王炬,史忠植.基于属性论的文本相似度计算[J].计算机学报,1999,22(6):651-655.
[6]晋耀红.基于语境框架的文本相似度计算[J].计算机工程与应用,2004,16:36-39.
[7]曹恬,周丽,张国煊.一种基于词共现的文本相似度计算[J].计算机工程与科学,2007,29(13):52-53.
[8]张燕平,史科,徐庆鹏,等.基于词共现模型的垃圾邮件过滤方法研究[J].中文信息学报,2009,23(6),61-66,71.
[9]贾西平,彭宏,郑启伦,等.基于主题的文档检索模型[J].华南理工大学学报(自然科学版),2008,36(9),37-42.
[10]Thomas Hofmann.Unsupervised Learning by Probabilistic Latent Semantic Analysis[J].Machine Learning,2001,42:177-196.
[11]Yunjae Jung,Haesun Park,Ding-Zhu Du,et al.A Decision Criterion for the Optimal Number of Clusters in Hierarchical Clustering[J].Journal of Global Optimization,2003,25:91-111.
