GPS信号FFT捕获的GPU实现①
2011-07-18王可东李鸿田侯绍东
王可东,李鸿田,侯绍东,高 悦
(1.北京航空航天大学宇航学院,北京100191;2.工业和信息化部电信规划研究院,北京100191)
0 引 言
GPS接收机的信号捕获是一种并行处理过程,其中各通道和每个通道的各频点均可并行独立进行,以提高捕获速度,因此,并行捕获算法基于FPGA实现的居多[1-2]。图形处理单元(GPU)近年来在神经网络、模糊系统、元胞自动机、粒子群优化算法和蚁群优化等通用计算方面得到了深入研究和一定程度的应用,证明了GPU在并行计算方面的优异性能[4]。文献[5]探讨了基于GPU实现并行快速捕获的一种方法,其中一个通道内各频点的捕获是并行的,而各通道是串行处理的,捕获32个PRN的时间缩短为使用CPU时的1/16。
在文献[5]的基础上实现各通道的并行处理可以进一步提高捕获速度。因此,提出了一种各通道和各频点均使用GPU并行运算的快速捕获方案,并初步分析了GPU与FPGA进行并行计算的应用对比。试验结果表明:在保证捕获精度的条件下,与基于CPU的运算方案相比,本文捕获方案的捕获时间是基于CPU的1/60,捕获速度提升显著。
1 FFT并行捕获算法
GPS系统采用码分多址(CDMA)的扩频通讯技术,所有卫星信号使用相同的中心频率,被不同扩频码调制。信号捕获的实质是通过本地复现码信号和载波信号,与输入信号进行相关运算,获得卫星的伪随机码的码相位和载波多普勒频移,因此,GPS信号捕获是一种二维搜索过程。衡量捕获性能的主要指标是多普勒频移捕获精度、码相位的分辨率和捕获时间等。
FFT并行捕获算法可以在同一频点上实现1023个码相位的并行搜索,在运算能力足够的情况下,具有快速运算的特点。如图1所示为FFT并行处理算法的一般流程[6-7]:
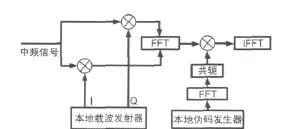
图1 FFT捕获算法的原理
1)将中频数字信号分别与本地载波发生器输出的同相和正交信号相乘,剥离载波信号,获得了一个复信号;
2)对复信号进行FFT运算。同时,对本地伪码发生器输出的伪码采样信号做FFT运算,取其共轭值;
3)将复信号的FFT结果与伪码采样信号FFT的共轭结果相乘,对乘积结果做IFFT,对IFFT的结果取模。
4)如果IFFT模的峰值超过了门限值,则认为捕获成功,尖峰值对应的位置即为伪码相位,此时的载波频率值就认为是信号的载波频率。如果峰值没有超过门限值,则重设本地载波发生器的频率值,重复以上步骤。
整个运算过程中,需要进行单一载波的大点数FFT运算以及多载波的循环搜索,要求处理器的并行计算能力强,否则会由于计算资源消耗过大而导致计算时长增加。
1 FFT并行捕获算法的GPU实现方案设计
2006年NVIDIA公司推出了GPU的通用编程模型CUDA,CUDA的出现简化了GPU的开发流程,由于CUDA是基于C语言进行程序开发的,不需要了解复杂图形编程语言即可进行GPU的通用计算编程。因此,本文将基于CUDA进行FFT并行捕获算法的实现。在进行方案设计之前,先与同样具有很强并行计算能力的FPGA对比,分析基于GPU进行并行捕获的可行性和优势。
1.1 使用GPU完成快速并行捕获的可行性
GPU与FPGA都适合于实现并行运算,但二者的应用方式还是有一定的差异,简单对比如下:
1)开发语言:GPU使用C语言进行开发,FPGA使用VHDL和Verilog等描述性语言开发。对熟悉软件开发的人员来说,不需要学习新的编程语言,有利于降低GPU的开发难度;
2)功耗:GPU的功耗与具体型号有关,在本设计中使用的显卡型号是GeForce9500GT,其总功耗约为30W,其使用的GPU芯片功耗与之相当。FPGA的功耗与所使用的片内资源有关,使用的资源越多功耗也越大,不过,一般要低于GPU的功耗,例如文献[8]使用Altera公司的EP3S70F484C2芯片的功耗约为15W;
3)体积:GPU 的体积略小于FPGA,Ge-Force9500GT显卡芯片的尺寸是12mm2,而EP3S70F484C2芯片的尺寸是23mm2;
4)成本:本设计中使用的GeForce9500GT显卡的价格约为500元。由于FFT并行捕获运算需要消耗较多的计算资源,需要使用高端的FPGA芯片,价格较高,如单片EP3S70F484C2芯片的价格超过1000元。
综上所述,在开发难度、体积和成本等方面GPU有一定的优势,FPGA在功耗方面有一定的节省,不过,要是应用多片FPGA芯片进行捕获时,还要考虑综合功耗。
1.2 基于GPU的并行捕获方法
在基于FFT的快速捕获算法中,大量数据的FFT耗费了大量时间,一些减少FFT计算数据的捕获算法,可以加快捕获的速度,但要以牺牲码的分辨率为代价[10]。由于各通道各频点捕获的相对独立性,可以使用GPU进行并行运算,加速FFT运算过程[11],在不降低码相位分辨率的情况下减少捕获时间。
CUDA提供了一个CUFFT运算库,可以高效地并行完成多个一维FFT运算,最多可以实现800万个点的FFT运算。文中GPS中频信号的采样频率为5.714 285MHz,中心频率为1.405 396 8MHz,捕获搜索带宽为14kHz,使用FFT快速捕获的方法分别处理两个连续的1ms数据,选取其中信噪比较好的数据完成峰值的确定,以消除导航电文跳变的影响。其中,1ms数据有5714个采样点,通过补零,使用8 192点的FFT运算;采用500Hz的频率步进,每颗卫星有29个频点;在冷启动时要搜索32个PRN卫星。因此,一次并行运算的FFT点数是7 602 176,小于800万,满足CUFFT库的使用要求。
具体捕获流程如下:
1)使用不同频点的载波信号,分别对32个PRN卫星的中频信号进行解调。将32个不同卫星的CA码采样序列,按频点数量扩充,按顺序存储在一块内存里,如图2和3所示;
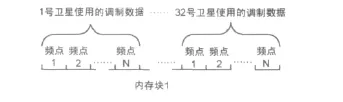
图2 解调后中频数据的存储顺序
2)申请3个显存块,显存1用于接收内存块1中的调制中频信号,显存2用于接收内存块2中的本地CA码采样序列,显存3用于存储运算结果;

图3 本地码的存储方式
3)启动GPU完成中频调制序列的FFT运算,运算结果仍保留在显存1,将FFT运算结果保留在原位的方法可以节约GPU的运算资源;
4)启动GPU完成本地码采样序列的FFT运算,运算结果保留在原位;
5)利用GPU完成两个长序列相乘,将本地码的FFT运算结果取共轭后与输入中频序列的FFT运算结果相乘,进行IFFT后将乘积序列存入显存3;
6)显存3的运算结果拷贝到主机内存,释放GPU的运算资源;
7)使用同样的方法处理第二个1ms的数据,将显存中的数据拷贝到内存;
8)经过以上的步骤已经将32个PRN和29个频点的两个连续1ms的峰值信息数据存入了内存。比较找出两个连续1ms中信噪比较高的数据,完成码相位的确定,流程如图4所示。
2 捕获方案的试验验证
2.1 试验条件
1)硬件环境:CPU是Intel®CoreTM2Quad芯片,主频为2GHz;显卡型号是 GeForce 9500GT,显存为512MB;内存为2GB;
2)软件环境:32位的 Windows®7操作系统,软件开发环境为微软公司的VS2008,还利用了NVIDIA公司提供的CUDA Driver、CUDA Toolkit和CUDA SDK;
3)实验数据:使用GP2010采集的真实中频数据,采样频率为5.714 285MHz,中心频率为1.405 396 8MHz.
2.2 试验结果与分析
分别基于CPU和GPU完成32个PRN卫星和29个频点的搜索,捕获结果和运行时间如表1所示,其中GPU代码运行时间是使用NAVIDA提供的专用计时API测定的,CPU的运行时间是使用MFC提供的计时器函数测定的。
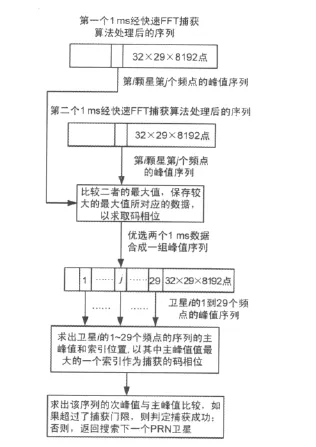
图4 码相位的查找方法
如表1所示,在GPU和CPU中完成的算法是相同的,对PRN和码相位的确定结果完全一致。但是,完成以上的捕获过程,基于CPU的代码需要约3min的时间,而基于GPU加速后的代码只需要约3s的时间,即基于GPU的运算速度大大提升了。
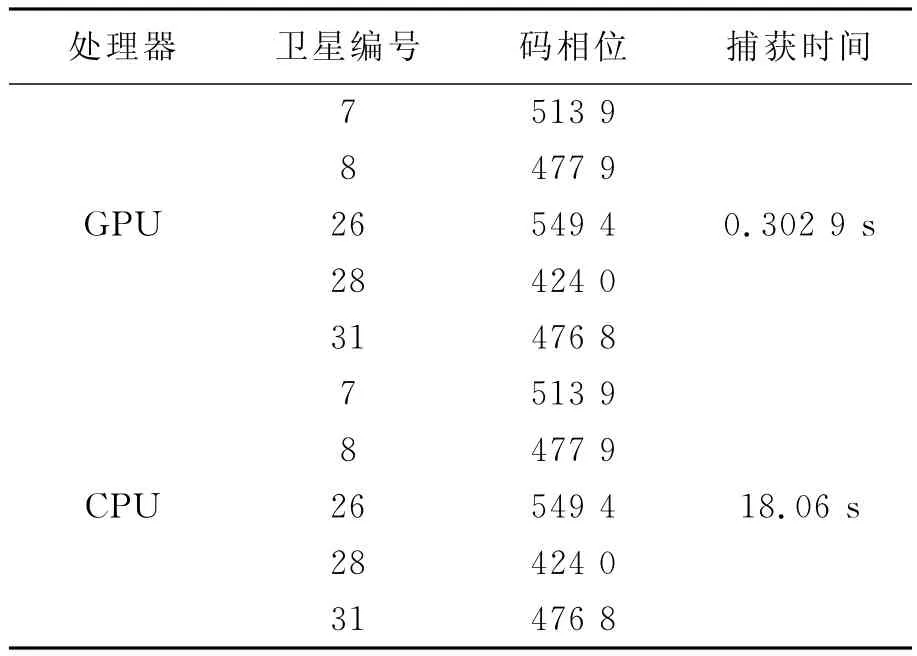
表1 捕获结果
使用GPU运算过程中保存的峰值绘制PRN和频点二维搜索的结果如图5所示,图中坐标X表示捕获到卫星的PRN;Y表示捕获到卫星的频点编号;Z表示捕获峰值的大小。由图5可知,与表1相对应的卫星都存在明显的峰值,证明了PRN捕获结果的正确性。
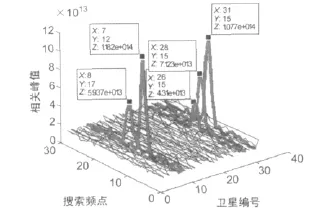
图5 二维搜索的结果
由于使用的是5.714 285MHz的采样频率,1 ms有5 714个采样点,在使用FFT运算时,将采样点补零到8 192点,而表1中的捕获到的码相位都不大于5 714,可初步断定捕获结果的正确性。为进一步分析捕获结果的正确性,绘制了PRN 31的第15个频点的峰值序列,如图6所示。其中,在4 768点处出现的峰值远大于其他位置的,符合CA码的自相关特性,进一步证明了CA码相位捕获结果的正确性。
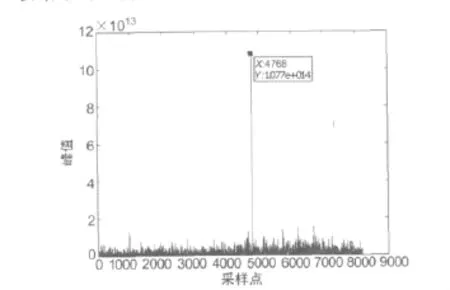
图6 PRN 31卫星的码相位
搜索32个PRN卫星的29个频点的过程中,GPU使用928个线程完成了CPU用单一线程完成的大规模FFT运算,忽略寻找峰值等次要时间因素的影响,理论上捕获使用的时间约是CPU的1/900,但实际上GPU的捕获使用的时间约是CPU代码的1/60.导致这种差距的两个主要因素包括:
1)GPU是多运算核心的处理器,在核心数量上比CPU有很大优势,但是就单独一个运算核心而言,运算能力不如CPU[11];
2)基于CUDA开发的GPU程序,必须由内存拷贝到GPU的显存,才能使用GPU加速,这个过程耗费了一定的时间[11]。因此,基于GPU开发代码时,如果要最大程度地发挥GPU并行运算的优势,则应尽可能让GPU一次处理更多的数据和运行更多的线程。
与文献[5]相比,该算法的运行时间是CPU的1/60,捕获时间更少,这主要是因为该算法的实现不仅对各频点进行了并行计算,而且对各PRN卫星也进行了并行计算,充分发挥了GPU适合于进行大规模并行运算的特点,运行速度更快。
3 结 论
为了减少GPS接收机冷启动的时间,结合GPS信号捕获的并行运算特点和GPU快速并行运算能力的优势,提出了一种基于GPU的并行捕获C/A码的方案,对各通道和各频点均进行并行计算,以最大程度地提高捕获速度。通过真实的中频数据试验验证表明:
1)由于GPS各通道和各频点的捕获都是相互独立的过程,使用GPU实现各通道和各频点的并行捕获与基于CPU实现的串行捕获方案的捕获结果是相同的;
2)基于GPU的并行捕获方案完成一次冷启动的时间远远小于基于CPU的捕获方案。在相同的条件下验证,基于GPU的方案耗时0.3029s,而基于CPU的方案耗时18.6723s,捕获时间缩短为原来的1/60;
3)由于采用了各通道和各频点均进行并行计算的GPU实施方案,与文献[4]的只对各通道进行并行捕获的GPU实施方案相比,运行时间进一步缩短,更充分地发挥了GPU的并行运算优势;
4)使用GPU的捕获方案减少的冷启动时间没有达到理论值。为了充分的发挥GPU的并行运算优势,使用GPU设计捕获方案应尽可能让GPU一次处理更多的数据。
[1]陈熙源,汤新华,祝雪芬.GPS软件接收机捕获算法的FPGA 仿真[J].东南大学报,2009,39(2):26-30.
[2]赵慷慨,汪 峰,李金海.基于FPGA高动态GPS快速捕获协处理器设计实现[J].微电子学与计算机,2010,27(2):39-44.
[3]郑海东,王明江,王进祥,等 .一种AMR语言编码器的VLSI设计及FPGA的实现[J].微电子学与计算机,2010,27(2):39-44.
[4]LANGDON W B.Graphics processing units and genetic programming:An overview[J].Soft Comput,2011,15(8):1657-1669.
[5]XU Shi-ming,LIN Hai-xiang,XUE wei.Sparse matrix-vector multiplication optimizations based on matrix bandwidth reduction using NVIDIA CUDA[C]∥9th International Symposium on Distributed Computing and Applications to Business,Engineering and Science,Hong Kong,China,August 10-12,2010:609-614.
[6]程俊仁,刘光武,张 博.基于CUDA的GPS信号快速捕获 [J].宇航学报,2010,31(10):2408-2410.
[7]VAN NEE D J R,GOENEN A J R M.New fast GPS code-acquisition technique using FFT[J].Electronics Letters,1991,27(17):158-160.
[8]JIANG Yi,ZHANG Shu-fang,HU Qing,et al.A new FFT-based acquisition algorithm for GPS signals[C]∥International Workshop on Education Technology and Training and International Workshop on Geoscience and Remote Sensing,Shanghai,China,December 21-22,2008:416-419.
[9]XU Bao-wen,CAI Ti-jing.C/A code of GPS software receiver fast acquisition based on FPGA[C]∥International Conference on Electric Information and Control Engineering,China,April 15-17,2011:4030-4033.
[10]O’Driscoll C,Murphy C C.Performance analysis of an FFT based fast acquisition GPS receiver[C]∥Institute of Navigation,2005National Technical Meeting.San Diego,CA,United states,January 24-25,2005:1014-1024.
[11]BEER D,VEN ORMODT R,DI CESARE D,et al.Accelerating batched 1D-FFT with a CUDA-capable computer:Calling CUDA library functions from a Java environment[C]∥IEEE International Conference on Imaging Systems and Techniques,Thessaloniki,Greece,July 1-2,2010:446-451.
[12]SONG Li,YIN Zhang-ke,WANG Jian-ying,et al.FFT-based matching pursuit implementation on CUDA platform[C]∥2nd International Conference on Information Science and Engineering,Hangzhou,China,December 4-6,2010:1181-1184.
[13]张 舒,褚艳利.GPU高性能运算之CUDA[M].北京:中国水利水电出版社,2009.
