基于中文Word Net的中英文词语相似度计算
2010-09-07吴思颖吴扬扬
吴思颖, 吴扬扬
(华侨大学计算机科学与技术学院 福建厦门361021)
基于中文Word Net的中英文词语相似度计算
吴思颖, 吴扬扬
(华侨大学计算机科学与技术学院 福建厦门361021)
介绍一种基于中文WordNet的中英文词语相似度计算方法.在WordNet同义词集的上下位关系图中,引入了距离、密度、深度3个因素来估计同义词集之间的相似度,采用一个自适应的方案来解决候选同义词集组合的权重和取舍问题.实现了一个可以计算英-英、汉-英、汉-汉词语之间相似度的算法,所得结果比较符合人们对词语的理解.
中文Wo rdNet;词语相似度;语义相似度
0 引言
Wo rdNet是按语义关系组织的,它使用同义词集合代表概念,词汇关系在词语之间体现,语义关系在概念之间体现,一个词语属于若干个同义词集,而一个同义词集又包含若干个词语.由于语义关系是一种词义之间的关系,而词义是用同义词集合来表示,因此很自然地把语义关系看作为同义词集合之间的关系. WordNet中词汇概念的语义关系主要包括上下位、同义、反义、整体和部分、蕴含、属性、致使等不同的语义关系.中文Wo rdNet建立在普林斯顿大学开发的英文Wo rdNet词典的原理基础上,实现了一个约118 000中文词和115 400同义词集的中文-中文词典的功能,是使用了现有的英-汉词典库对英文WordNet中的词进行手工翻译而得到的.它同样也具有同义词、同等词、泛词等在英-英词典中提供的功能.
词语相似度的计算方法主要分为两类[1-2]:一类方法称为基于上下文的方法,它利用大规模的语料或词语定义,收集统计数据,来评估词汇语义相似度;另一类是利用词典中的关系和层次结构,如概念之间的上下位关系和同位关系来计算词语的相似度.文献[3]利用了同义词集在WordNet中的最短距离和这条路径的转向次数来计算词语的相似度;文献[4]引入了本体和语料库,以2个同义词集的公共子结点的范围和公共的信息来计算其相似度;文献[1]从WordNet中提取同义词并采取向量空间方法计算英语词语的相似度.但由于Wo rdNet词典的语言限制,它们都局限于英文词语的语义相似度分析.文献[5]讨论了义原的相似度计算方法、集合和特征结构的相似度计算方法,并在此基础上提出了利用《知网》进行词语相似度计算的算法.本文利用中文Wo rdNet,在Wo rdNet同义词集的上下位关系图中,引入了距离、密度、深度3个因素来估计同义词集之间的相似度,用一个自适应的方案来解决候选同义词集组合的权重和取舍问题,设计并实现了一个能计算英-英、英-汉、汉-汉词语之间相似度的算法,所得结果比较符合人们对词语的理解.
1 词语相似度计算方法
要计算2个词语之间的相似度,首先需要分别查出这2个词语所属的所有同义词集,并两两组合计算其相似度,最后根据这些同义词集组合的相似度计算出2个词语之间的相似度.下面分别介绍同义词集和词语的相似度计算.
1.1 同义词集的相似度
在WordNet中,同义词集(synset)之间的上下位关系形成了一个图结构,每个synset有0个或若干个上位和下位synset.因此,基于以下原则来计算同义词集之间的相似度[6]:
1)在上下位关系图中,任意2个synset结点的距离越远,语义相似度越小.
2)图中结点所处的位置密度越高,说明该局部的词义划分越细,相似度越低.
3)在上下位关系图中相同距离的2个synset结点,所处的层次越深,描述的事物越具体,因此相似度越大.
引入距离因子、密度因子、深度因子来衡量同义词集之间的相似度.距离因子σ计算公式为

其中,lenth为2个synset之间的距离,θ为阈值参数.距离越大,σ值就越小,当距离大于阈值θ时,距离因子为0.
密度越大,语义相似度越低.密度的计算可从局部结点的个数入手,具体方法为:分别从2个当前结点出发向上走3层,每一层的结点个数分别记PN1,PN2,PN3.期间2个结点若相遇,则终止,并将其上层结点数计为0,最终计算局部结点个数PN为

其中,PN1是当前结点所在层次的结点个数,PN2,PN3依次为其上层结点个数.则密度因子φ为

PN值越大表示密度越大,密度因子越小,且PN≥1,使得0<φ≤1.此外,深度越深,语义相似度越大.深度因子ω的计算公式为
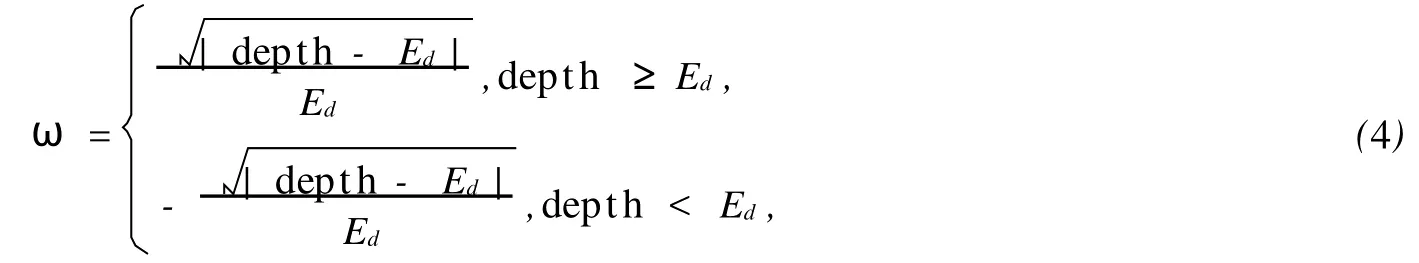
其中,dep th为该节点的深度,Ed为整棵语义树中所有结点的平均深度.即当结点的深度大于均值时,其深度因子为正,否则为负.
综合考虑距离、密度、深度3个因素,则2个同义词集之间的相似度为

若sim>1,则取sim=1.-φ和-ω分别为2个词的密度因子和深度因子的均值;α和β分别为密度因子和深度因子的权重.
1.2 词语之间的相似度
由于每个词语有一个或多个词义(sense),即它属于若干个同义词集,因此采用如下步骤计算2个词语之间的相似度:
1)用联合查询语句在中文Wo rdNet词典数据库的各个翻译版本中,查找出被比较的词(英文单词或中文词语)所有可能出现的同义词集的id.
2)将中文单词所属同义词集的标识synset_id转换为对应的英文同义词集的synset_id.
3)令词a有m个词义(属于m个同义词集),词b有n个词义,即a,b所属的同义词集有m×n对组合.计算这m×n对同义词集的相似度,并排序.
4)从大到小排序后,第1对同义词集所占的比重最大,令其权重为ρ,则第2对同义词集所占的权重为剩余比重×ρ,以此类推.设置一个阈值参数δ(0<δ<1),计算过程中仅考虑所有组合的前百分比阈值,如δ=0.3,则仅计算所有同义词集组合相似度最大的前30%.
在实际操作中,当同义词集组合个数较多时,常出现1对或前几对同义词集的相似度非常大,因此首对权重ρ不宜过大,否则将失去综合权衡的意义.为了能够综合考虑被选取的同义词集组合的影响力,考虑根据选取的同义词集组合的数量来调节各组合所占的权重.因此,提出了一个根据同义词集组合个数num自适应调节参数ρ的公式,使得ρ∈[0.5,0.9],即当入选的同义词集组合个数num越小,首对同义词集的权重ρ越高(最大0.9),而ρ值随num的增加而递减(最小0.5),计算公式为

其中,num=m×n.
2 实验结果与分析
根据上述方法,实现了一个基于中文WordNet的词语相似度计算程序模块.在实验中,根据多次尝试中取得的经验,将文中提到的几个参数设置如下:距离因子中的阈值参数θ=7;深度因子中所有结点的平均深度经计算得Ed=8.624 3;密度因子权重α=0.1;深度因子权重β=0.1;同义词集组合前百分比阈值δ=0.2,即取相似度最大的前20%的组合考虑.
对于词语相似度计算结果的评价,最好是放到实际的系统中(如本课题后期研究的数据空间的进化将利用此结果数据模式进行匹配),观察不同的计算方法对系统性能的影响,在条件不许可的情况下采用人工判别的方法.
对比了文献[5]中介绍的同样能计算中文词语相似度的基于《知网》的词汇语义相似度计算方法,对比结果如表1所示,方法1为文献[5]中介绍的方法,方法2为本文介绍的基于中文WordNet的相似度计算方法.
对比表1结果,方法2的实验结果与人们的理解比较一致,方法1得到的相似度与人们的理解相对差别大一些.例如,方法1对“论文”、“文章”、“文献”这样词义接近的词汇的相似度估计相差巨大,因为方法1中计算词语相似度时采用了2个词之间各个概念相似度的最大值.而方法2计算结果中,“论文”与“文章”、“文献”的相似度比较接近,都在0.91以上,因为方法2对词语各个概念(同义词集)的各种组合采取了一种动态加权和的办法,能自适应地调整组合之间的权重.
本算法的另一个独特之处是兼容中英文双语的相似度计算,表2给出另外一些测试结果.

表1 与文献[5]结果对比Tab.1 The results compared w ith literature[5]

表2 本算法的测试结果列举Tab.2 Some examp les w ith the p roposed method
从实验结果可以看出,“父亲”和“father”同为正式用语,相似度高于“父亲”和“爸爸”,而同为口语的“爸爸”和“dad”也有较高的相似度;“中国”和“亚洲”的相似度高于“中国”和“欧洲”也是较为合理的;“猫”直接类属于“动物”,因此“猫”和“动物”的相似度大于“猫”和“狗”的相似度.总体上看,该方法得到的大部分结果是较为准确的.
3 小结
本文主要分析了中文WordNet的体系结构,根据影响词语相似度的距离、密度和深度3个因素,定义了完整的同义词集之间的相似度算法,并采用了自适应的方法对被查词语的同义词集组合进行了取舍和权重定义.最后,实现了一个计算中英文词语相似度的算法,并进行了实验.测试结果表明:本方法得到的结果与人工判别结果基本一致,比基于《知网》的词汇语义相似度计算方法更符合人们的理解.下一步研究将把词语相似度算法应用于数据空间管理系统的进化和检索中,使数据空间的查询结果更为准确有效.
[1] 荀恩东,颜伟.基于语义网计算英语词语相似度[J].情报学报,2006,25(1):43-48.
[2] Sebti A,Barfrous A A.A new wo rd sense similarity measure in WordNet[C]//Proceedingsof the International M ulticonference on Computer Science and Information Technology.Washinton D C:IEEE Computer Society,2008:369-373.
[3] Hirst G,St-Onge D.Lexical chains as rep resentationsof context fo r the detection and correction of malap ropisms[M]// WordNet:an Electronic Lexical Database.Cambridge M A:M IT Press,1998.
[4] Resnik P.Using information content to evaluate semantic similarity in a taxonomy[C]//Proceedingsof the 14th International Joint Conference on A rtificial Intelligence.San Francisco:Mo rgan Kaufmann Publishers Inc,1995:448-453.
[5] 刘群,李素建.基于《知网》的词汇语义相似度计算[J].计算语言学及中文信息处理,2002,7(2):59.
[6] 张承立,陈剑波,齐开悦.基于语义网的语义相似度算法改进[J].计算机工程与应用,2006,42(17):165-166.
Chinese and English Word Sim ilarity Measure Based on Chinese WordNet
WU Si-ying, WU Yang-yang
(College of Com puter Science and Technology,H uaqiao University,X iamen 361021,China)
A method for measuring similarity of Chinese and English words based on Chinese WordNet is introduced.In the hypernym relative graph of synonym set(synset),the factors of distance,density and dep th are used to measure the similarity of synset,and the weight of the combination pairs of the two words’synset is settled in adap tive mode.An algorithm that can measure English-English,Chinese-English and Chinese-Chinese word similarity has been imp lemented.Experiment results show that the similaritiesmeasured by the p roposed algorithm accord w ith the judgment of the peop le.
Chinese WordNet;word similarity;semantic similarity
TP 391
A
1671-6841(2010)02-0066-04
2009-12-01
福建省科技计划重点项目,编号2008 I0021;福建省自然科学基金资助项目,编号2009J01289.
吴思颖(1985-),男,硕士研究生,主要从事数据库应用技术研究,E-mail:w usy85@gmail.com;通讯联系人:吴扬扬(1957-),女,教授,主要从事数据库技术和数据挖掘研究,E-mail:w uyangyang@sina.com.
