车辆定位监控系统数据库的设计与优化
2010-08-24仰燕兰费树岷
仰燕兰 叶 桦 费树岷
(东南大学自动化学院,南京 210096)
(东南大学复杂工程系统测量与控制教育部重点实验室,南京 210096)
开发一个数据库应用系统时,系统功能所依赖的数据库模型设计是最关键的一个环节.从数据库的概念设计到逻辑设计,任何一步稍有差错,整个应用系统便犹如建立在危房之上,随着开发过程的不断深入,会遭遇各种难以预料的风险.开发者可能会为修改或重新设计数据库付出巨大的代价.因此,创建合理的数据库结构模型是一个具有高性能的应用系统所必需的.另一方面,数据库应用系统的多数功能都是基于数据库访问的,数据库自身性能的好坏直接影响了应用系统的运行效果.特别是系统的实时响应能力,对数据库的I/O读写速度提出了较高的要求.对于一个结构合理的数据库模型,还要从数据访问效率、可扩展性、分布局限性等方面考虑其优化问题.本文主要针对车辆定位监控系统,面向这一类应用系统特定的任务需求,探讨后台数据库的结构设计及其优化问题,使系统的整体性能得到有效提升.
1 车辆定位监控系统
随着全球定位系统(GPS)的普遍应用及GSM/GPRS无线通信技术的不断成熟,这2项技术的有效集成实现了远程车辆的移动信息化.根据实际应用领域的需求,各类车辆远程监控系统迅速发展起来,并得到了广泛应用.例如大家所熟知的银行运钞车、城市出租车远程管理系统等,均已成为人类社会智能交通系统(ITS)日益发展、成熟的重要标志.
车辆定位监控系统一般由车载终端、监控中心和监控客户端3个部分构成,图1为系统的详细架构.车载终端实现GPS定位信息以及车辆运行状态的实时采集,并通过GSM/GPRS无线通讯方式将这些信息周期性上传到监控中心.监控中心的通讯服务器接收所有上传信息,按照指定协议解析后存储到数据库服务器.监控客户端为用户提供一个友好的可视化GIS监控平台,并基于互联网向监控中心的Web服务器请求业务数据,间接实现对系统数据库的远程访问.

图1 车辆定位监控系统架构
2 数据库需求分析及设计
由系统工作原理可知,后台数据库是监控中心的核心组成部分,作为一个数据共享平台在整个系统中发挥着举足轻重的作用.同时,它也是建立监控客户端与移动车辆之间关联的重要枢纽.
2.1 系统任务需求分析
根据图1所示的系统架构可知,监控中心的通信服务端、Web服务端与后台数据库之间都存在数据流的交互,它们对数据库的任务需求(见图2)决定了数据库的结构模型设计.
通信服务端对后台数据库的任务需求包括以下2点:①车载终端通信号码、车载终端-车辆对应关系的查询,用于识别上传信息所属目标车辆;②车辆运行信息的更新接口,用于保存最新上传信息.
监控客户端对后台数据库的任务需求包括以下4点:①车辆管理,即维护车辆基本属性、车辆类型等信息;②车载终端管理,即维护终端配置属性、所属车辆等信息;③ 用户管理,即维护客户端的用户注册信息及所管辖车辆的信息;④车辆运行信息的查询,包括实时、历史信息的查询.
2.2 数据库的概念/逻辑设计
通过对任务进行需求分析,后台数据库主要对车辆、车载终端、用户3种实体对象及其联系进行存储管理.数据库的概念设计可利用实体-联系(E-R)图[1]来描述(见图3).车辆分别与车载终端、用户之间建立一对一、一对多的关系,它们是系统的业务基础数据,也被称为静态数据,一般具有数据量小、实体间关系简单、数据变化可能小等特点.车辆运行信息属于业务数据,描述车辆在各个历史时刻的运行状态(包括位置和工作参数等).随着时间的推移,车辆运行记录将不断增加,成为数据库中更新最频繁、数据量变化最大的一类实体数据.
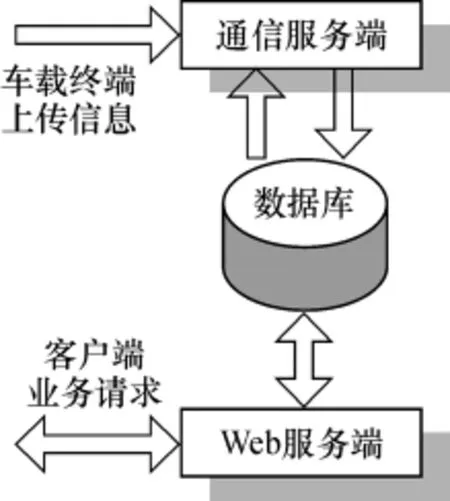
图2 对数据库的任务需求

图3 用E-R图描述的数据库概念结构
数据库的逻辑设计过程就是把E-R图中的实体、属性和联系转化为关系模式的过程[2],并据此创建数据库中的表格以及表格之间的关系.表1列出了本例数据库所包含的核心实体表和关系表.这些表作为系统业务应用的重要依据,其数据读写性能的好坏直接影响系统的整体性能.

表1 车辆监控系统数据库中的核心数据表
3 数据库优化方法
数据库优化方法很多,一般都是针对数据库文件和数据表的合理设计的,其中大数据量表是优化处理的重点.当系统的业务应用相对集中在单个数据表上时,这些表的行数往往达到千万甚至是数亿行.如何改进这些数据表的设计,尽量避免全表扫描和降低其查询的系统开销是数据库优化的关键.
本例数据库的车辆运行信息表是一张典型的大数据表,该表用于存储车辆历史时刻的运行状态,故表数据随着时间的推移不断增加.同时,车辆运行信息作为一类业务数据,是监控系统各种业务功能所依据的重要数据源,任何与车辆运行状态相关的数据交互行为都涉及到对这张表的I/O读写.因此,对该表优化的目标在于提高表的I/O读写效率,使系统整体性能得到显著提升.
对于数据库中其他以静态数据为主的实体表或关系表,一般其数据量较小,通过创建索引机制,就能达到较为理想的优化效果.
3.1 大数据表的分布存储策略
对用于存储业务数据的大数据表而言,其数据由系统在业务过程中自动产生,因此表数据的日益增长不可避免.因此,对这类表的优化主要从数据“分流”的角度出发,面向任务需求,对表数据进行分割处理,利用数据的分布存储来减少单张表格包含的总数据量.
3.1.1 添加冗余表分散访问
监控系统关于车辆运行信息表的应用需求有2种:①实时更新车辆的最新运行状态;②查询历史信息,如轨迹回放、状态参数统计图表等.第1种情况只需得知每台车辆最新一组运行信息即可,具有较高的数据读写频率,以保证车辆运行状态的实时性.显然,在数据量上它们只占全部车辆运行信息的极小部分.若每次对车辆最新状态的检索或更新都在全体运行信息中进行,这种做法显然是不合理的,对数据库资源的利用率太低.尤其当运行信息量增长到一定程度后,对表格的任何数据操作(包括查询、更新或删除)都会引起超时过期的错误,严重影响了系统业务功能的正常执行,并导致监控系统整体性能下降.
通过添加冗余表单独存储车辆的实时运行信息,可以有效解决这一问题.在冗余表中,每台车辆只有唯一一条运行记录与之对应.有新的上传信息时,先更新冗余表中对应的实时信息,再添加到车辆历史信息表中以同步数据.
冗余表的建立,使应用系统根据不同需求有选择地访问目标表格,达到了分散访问的目的.虽然存在数据冗余,由于冗余的信息量相对较少,对提高系统对车辆的实时刷新性能有很大作用,因此这种用“空间换取时间”的代价是值得的[3].
3.1.2 创建子表分散存储
关于车辆历史运行信息,表数据量庞大、检索耗时的固有问题依然存在.不过,对历史信息的检索一般是针对某台车辆的条件查询问题.据此,本文提出了按车辆实体创建子表,不同车辆的历史运行信息分别存储到不同的子表中,即将原历史信息表用一组以车辆实体为区分标志的子表来代替.进行这样的优化处理后,执行某种历史查询时只需访问目标车辆对应的历史信息子表即可,即使今后系统扩大车辆监控规模,车辆总数增加,也不会对各车辆历史数据的查询性能有太大影响.
尤其在大规模的车辆监控系统中,历史信息往往是海量的,采用子表集取代原表的优化方法,使得数据的物理存储方式更具灵活性,对改善系统性能、提高系统可扩展性等方面有很大的贡献.
3.2 表的分区优化
表的分区优化是从表数据的物理存储位置着手,根据数据的某种特性对表进行横向或纵向分割,再将表数据按照一定的规则分散到不同的物理分区上存取,从而实现数据的并行处理,显著提高系统访问数据的效率[4].
分区优化适用于大数据表,对改善表的数据读写性能有很大贡献.针对本例已创建的车辆历史运行信息子表,均采用这种优化方法.下面以此为例,基于SQL语言说明对表进行分区的基本操作.
1)创建分区函数
根据车辆运行信息特征,选择信息上传时间为分区依据.初步设计单张子表最多容纳每台车1年的历史数据,故按照季度划分设定上传时间的分界值,即每个活动分区存储一个季度的历史信息.创建分区函数的SQL语句示例如下:
CREATE PARTITION FUNCTION table_partfunc(datetime)AS RANGE RIGHT
FOR VALUES(quarter1,quarter2,quarter3,quarter4)
2)创建分区架构
创建分区函数后,必须将其与分区架构相关联,以便将分区定向至特定的文件组,获得良好的I/O平衡.使用文件组分离数据有助于优化性能和维护,文件组的数目在一定程度上由硬件资源决定,一般情况下,文件组数最好与分区数相同.
定义分区架构时,即使多个分区位于同一个文件组中,也必须为每个分区指定一个文件组(如[PRIMARY]),并使用如下的SQL语句创建分区架构:
CREATE PARTITION SCHEME table_partscheme AS PARTITION table_partfunc ALL TO([PRIMARY])
3)创建分区表
分区函数与分区架构分别定义了表数据存储的逻辑结构和物理结构.分区表的创建使用架构,架构使用函数,通过将分区表的特定列设为分区函数的分区依据,实现这三者的有机结合.用于创建分区表的SQL语句如下:
CREATE TABLE table(...)ON table_partscheme(SampleTime)
3.3 索引的合理使用
在关系数据库中,索引主要用于提高数据操作的性能,利用索引可以不用检索整个数据库,便能从大量的数据记录中迅速找到目标值,从而增强了检索效率.事实上95%的数据库性能问题都可以通过索引技术来解决[5].
索引主要分为聚集索引和非聚集索引.其中,聚集索引会改变表中数据存放的物理位置,令表中的行按索引顺序进行排序.对一些经常顺序访问的表而言,在请求大量检索结果时,聚集索引的使用显示出很多优势.非聚集索引仅仅将记录指向数据页的表行指针,不会改变数据存放的物理位置,通过直接查找索引值并快速定位到表的特定位置来实现对数据的访问,适用于精确匹配查找或请求少量查询结果的场合[6].本例数据库中用于存储业务基础数据的实体表主要使用非聚集索引,一般在主关键字上创建,根据实际应用需求也允许在那些经常查询键上创建多个非聚集索引,实现提高精确查询效率的目的.
由于索引的使用需要额外的磁盘空间和维护开销,并且会降低添加、删除和更新数据行的速度,因此不是索引越多表的数据查询效率就越高,还需要结合表的应用场合、访问需求等方面判断是否创建索引,并选择最适合的索引类型.尤其对一些数据更新频繁的表,不适合创建索引.对于本例数据库中的车辆历史信息子表,一方面,这些表经过分区优化后数据查询速度已得到显著提高,而且表数据增长快,维护索引的代价太大;另一方面,这些表中的数据记录都是按照信息的上传时间先后次序插入的,故表数据本身具有按某列顺序存储特点,等效于对“上传时间”创建聚集索引.
4 应用实例的性能评价
利用本文方法创建一个数据库实例,并将其应用在某企业的工程机械定位监控系统中.该系统从正式投入使用至今已过半年,目前车辆监控规模约为500台,并且还在以20~30台/月的速度不断扩大.车载信息上传频率为1 min,故每台车的历史运行信息记录在数据库中约按1 500条/d的速率递增,则一台车一年的历史运行信息总量高达60万条记录.
根据上述统计信息,如果不对车辆运行信息总表进行优化,所有车辆的历史运行信息仍集中存储在一张表中,按固定500台的监控规模计算,不到一个月表数据就会超过1千万条记录.对数据库系统的性能测试结果表明,当单张表格的数据量达到上千万条记录时,系统对表的任何读写操作,无论过程繁简,都会产生明显的时延,少则40~50 s,多则几分钟.如此数据处理效率对于一个实时监控系统而言绝对是致命的,极易引发系统运行时错误,影响整个应用系统的运行性能,严重时甚至导致系统瘫痪.
经过优化设计的数据库则不会遭遇这样的数据灾难.首先,利用“分而治之”的思想对车辆运行信息总表进行分割,不同车辆的历史数据独立存储至各自的信息子表中,子表数据的增长率仅为5万条/月.同时,设子表记录总数不超过100万条以保证一定的数据读取速度,这时每张子表仍能够存储长达20个月的车辆历史数据,大大增强了数据库的存储能力.其次,对子表创建分区,进一步优化表数据的物理存储方式,提高了对子表的数据访问效率.最后,为表格创建索引,使得对该数据库中部分表的检索处理时间显著减少.
综上所述,本数据库实例能为车辆定位监控系统提供高性能的后台数据服务,其优化设计结构也能支持系统监控规模的进一步扩展,并保证系统的可持续健壮运行.
5 结语
本文基于车辆定位监控系统对数据库的任务需求展开数据库的概念/逻辑设计,并创建了数据库模型.为了进一步提高数据库的运行性能,根据各个数据表的特点和应用目的分别提出相应的优化方法,包括大数据表的分布存储、单表分区优化和聚集索引的合理使用.对某企业车辆定位监控系统数据库实例的性能评价结果表明,优化后的数据库对于监控系统数据的实时访问请求响应及时,大大增强了数据存储管理能力,保证了系统整体性能的稳定可靠.
References)
[1]James L J.数据库:模型、语言与设计[M].李天柱,译.北京:电子工业出版社,2004:38-44.
[2]张英锋,朱自强.城市交通监控系统数据库的设计[J].现代电子技术,2006,29(13):134-136.Zhang Yingfeng,Zhu Ziqiang.Design of database for monitoring system in urban traffic[J].Modern Electronic Technology,2006,29(13):134-136.(in Chinese)
[3]吴纲.SQL server大数据量数据库性能优化初探[J].武汉船舶职业技术学院学报,2010,9(1):27-30.Wu Gang.Performance optimization of SQL server database with mass data[J].Journal of Wuhan Institute of Shipbuilding Technology,2010,9(1):27-30.(in Chinese)
[4]李佳.工程机械服务平台的设计与实现[D].南京:东南大学自动化学院,2010.
[5]桂友武,桂友超.基于B/S模式数据库设计的优化[J].现代计算机,2009(7):121-123.Gui Youwu,Gui Youchao.Optimization of database design based on B/S pattern[J].Modern Computer,2009(7):121-123.(in Chinese)
[6]夏红霞,钱政.应用型工程数据库系统中性能优化技术研究[J].电脑知识与技术,2009,5(26):7340-7341,7355.Xia Hongxia,Qian Zheng.Research on technologies of improving the performance of engineering database[J].Computer Knowledge and Technology,2009,5(26):7340-7341,7355.(in Chinese)
