基于篇章的中文地名识别研究
2010-07-18唐旭日陈小荷
唐旭日,陈小荷,许 超,李 斌
(南京师范大学 文学院,江苏 南京 210097)
1 引言
地理要素如地形要素(山脉,河流等)、行政区划、街道等的自动识别是基于文本的地理信息挖掘的前提。各类地理要素在自然语言中一般被标示为地名或机构名。因此,地理要素的识别可以看作是命名实体识别的一项子任务。而文本中地名信息往往多于机构名称,且许多机构地名都包含地名,因此地名识别是基于文本的地理信息挖掘首先要面临的任务,其识别质量的好坏也将影响机构名的识别。
在最近的几年里,地名识别的研究受到高度重视,且颇有成效[1-12]。总体看来,地名识别的研究存在以下趋势:复杂统计模型的使用;统计模型与语言知识的结合;内部结构特征与上下文特征的结合。基于统计模型的机器学习是当前自然语言处理的主要技术来源,地名识别方面当然也不例外。多个统计学习模型如隐马尔科夫模型[8]、支持向量机[9]、最大熵[7]、条件随机场(Conditional Random Fields,简写为CRFs)[11]等都被用于地名识别,且模型越来越复杂,存在多个模型集成使用,如文献[13]将隐马尔科夫模型与最大熵模型混合起来使用,或单个模型进行层叠使用(如文献[8]),或对原有基本模型进行修改,如文献[10]所采用的最大间隔隐马尔科夫模型(Max-margin H idden M arkov Model)等。从文献看,层叠隐马尔科夫模型、条件随机场以及基于最大间隔的隐马尔科夫模型在地名识别方面具有较大的优势,但是由于训练语料和测试语料并不一致,所以还不能明确判断各个模型之间的优劣。地名识别的第二个趋势是语言知识在统计模型中的充分应用。各种语言资源如地名列表、地名用字、地名特征尾字(或地名通名)列表等以各种形式与统计模型结合起来,如作为状态标注集合、特征判断等。语言资源的加入有利于地名识别精度的提高。文献[11]在CRFs模型的基础上加入了特征尾字,文献[8]采用角色标注对地名进行进一步分类,区分了中国地名、音译地名和其他地名,文献[5]对带特征词地名和不带特征词地名的区分,对比试验都表明了识别精度获得进一步提高。地名识别的第三个趋势是内部结构特征与上下文特征分析的结合。由于地名与其他类型字串存在千丝万缕的联系,仅依靠内部结构分析不足以判断其是否为一地名,因此,综合考虑内部结构特征和外部上下文特征是提高识别精度的有效方法。较早的地名识别研究(如文献[1])仅使用了地名内部结构的统计分析。而最近的研究中各种统计模型都使用了外部的上下文特征,其区别仅在于所考察的上下文的范围。现有的模型一般仅考察左右相邻3~4个字的区间,而对于语言中长距离依存关系的考察比较缺乏。
本文提出了篇章地名识别的概念和系统实现方法。该方法以篇章作为地名识别参照系,包含简单地名识别和复杂地名识别两个阶段,其中简单地名由基于条件随机场的简单地名识别模块和基于篇章地名关系的简单地名识别模块顺序构成。复杂地名识别由基于条件随机场的复杂地名识别模块构成。该方法在三个方面进行了有益探索:(1)在未分词语料上直接识别。现有地名识别大多建立在分词的基础上,依赖于分词预处理的精度。本文则尝试利用以字为单位的外部信息,采用无分词的地名识别策略;(2)区分简单地名和复杂地名,采用层叠条件随机场顺序处理简单地名和复杂地名;(3)将篇章地名关系这一长距离依赖信息纳入地名识别,突破了仅使用地名的左右邻字信息的局限,为提高系统性能提供新的动力。对比实验表明,采用上述策略的系统在整体上表现出良好性能,封闭测试和开放测试中F值分别达到92.87%和89.76%,说明综合利用短距离和长距离依存关系可以有效提高地名识别效果。研究同时还发现,在地名性判断中地名确信度低的字串对于地名识别干扰性较大,是导致地名识别精确度的降低的重要因素;应用篇章地名关系进行地名识别,能够在保持识别精确度不变的情况下有效提高召回率。
论文的第2节讨论了简单地名与复杂地名的区分和无分词地名识别策略,并给出了系统整体流程;第3、4、5节分别讨论基于CRFs的简单地名标注与文本分词、基于篇章的简单地名识别和复杂地名识别;第6节给出了系统的试验结果及相关分析;第7节为结语。
2 系统流程
系统流程构建以充分利用地名的内部结构信息及其外部语境信息为指导思想。在内部构造特征方面,汉语中地名存在两种结构类型:简单地名和复杂地名。简单地名内部由词素构成,成分结构相对稳定,构成方法具有规律性,如“天安门”、“黄河”、“枣岭乡”等。复杂地名事实上是一种短语结构,由二个或多个词组成,如“香港 特别 行政区”、“珠江三角洲”、“抗日战争纪念馆”等。复杂地名中一般都包含简单地名。对北京大学1998年1至6月份《人民日报》标注语料(后简称为北大语料)中复杂地名分析显示,语料库中复杂地名中嵌套有简单地名的有4 935例,占复杂地名总数的83%。
简单地名和复杂地名的结构方式不同,应采用不同的识别模式。本文借鉴了文献[14]在进行机构名识别研究时的层叠条件随机场方法,采用按层叠加条件随机场模型,简单地名识别与复杂地名识别在系统的不同阶段完成。分层结构具有三个优势。首先,内嵌在复杂地名中的简单地名获得了与非内嵌地名一致的处理方式,有助于缓解数据稀疏问题;其次,分层处理可利用“复杂地名一般都包含简单地名”这一结构性规律,在复杂地名识别时利用已识别的简单地名信息;此外,分层处理有利于分别针对简单地名和复杂地名的结构特征与上下文信息识别进行优化处理,而不会彼此干扰。
外部语境在地名识别中具有非常重要的作用。外部语境信息包括近距离依存关系和长距离依存关系。本文通过采用无分词地名识别策略和条件随机场的特征模板设置来应用近距离依存关系。现有命名实体识别研究[7-8,14]一般在进行识别之前先做分词处理。然而由于地名常为未登录词,分词的结果对地名识别效果影响较大。采用无分词识别策略,以汉字作为基本特征单位,颗粒度细,能够缓解以词为单位造成的知识颗粒度大和数据稀疏问题。试分析例1。
例1 (a)到达镇江 (b)抵达镇江 (c)送达镇江
如在训练语料中包含例1(a),与例1(b),而不包含例1(c)时,以“字”为基本特征单位的无分词策略可利用两次出现的“达”字作为上下文信息,而以词为基本特征时,例1(a)与例1(b)都不能为正确判断例1(c)提供有用信息。有关条件随机场的特征模板设置在第3节中详细说明。
外部语境的另一个重要信息是长距离依存关系。地名的长距离依存关系还没有被地名识别研究者所重视。在已有研究中,地名自动识别所考虑的上下文语境一般为地名字串的左右邻字。仅有个别研究涉及了如何利用篇章中地名重现的问题,如文献[7]提出“在同一篇文章内,同一个人名或地名往往反复出现,已经出现的专名应该对文中其他地方的相同出现起指导提示作用”,并使用“动态词表”来记录同一篇章中出现的地名或人名。文献[13]也采用Cache方法对同一篇章中出现的命名实体进行储存。但是语篇中地名关系及其在地名识别中的应用还缺乏系统性。
本文认为,地名长距离依存关系的一种表现是篇章中地名语义关系,文献[7]提及的篇章地名同现是篇章地名语义关系的一种类型。篇章分析理论指出,篇章要完成其作为语言交际基本单位的功能,“必须具备语篇特征,它所表达的是整体意义。语篇中各成分是连贯的,而不是彼此无关的”[15]8。地名之间的语义关联是篇章连贯性的一种表现。以篇章为单位进行地名识别,可以利用篇章中地名之间存在的动态地名关系与静态地名关系有利于提高地名识别的效果。
基于以上分析,图1给出了地名识别流程。输入文本首先进入简单地名标注与分词一体化处理,并作为基于篇章的简单地名识别模块的输入,然后再进行复杂地名识别。简单地名与文本分词一体化处理、复杂地名识别两个模块以条件随机场模型为依托,基于篇章的简单地名识别则利用了地名库,篇章地名关系库和地名判断模型。
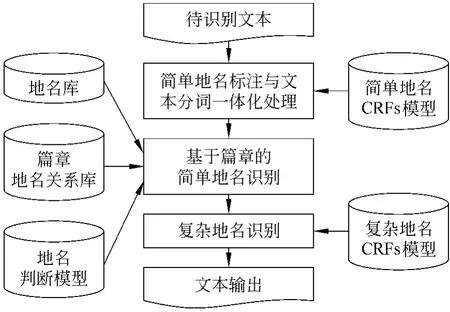
图1 地名识别流程图
3 简单地名标注与文本分词一体化处理
3.1 一体化标注集
地名标注与文本分词的不同之处在于文本分词仅对词边界进行标记,而地名标注增加了词语的句法范畴标记信息。然而两者都通过对字符串潜在状态标记完成,因此,可以对地名标记与文本分词进行一体化处理。例2给出了本文采用的一体化标注形式的示例。
例2.
(a)引/S闽/B-ns江/E-ns水/S冲/B污/E线/B路/E西/S起/S闽/B-ns侯/C-ns县/E-ns文/B-ns山/C-ns里/E-ns 、/S东/B-ns至/C-ns湖/B-ns前/C-ns河/E-ns。/S
(b)党/B-nt中/C-nt央/E-nt国/B-nt务/C-nt院/E-nt对/S太/B-ns湖/E-ns流/B域/E的/S污/B染/E问/B题/E高/B度/E重/B视/E
考虑到机构名中也常常含有地名,表1中给出了本文采用的18位标注集,分为地名、机构名和其他三种类型,每种类型包含六个标记。

表1 简单地名标注集
3.2 模型获取
采用一体化标注集,通过训练可获取简单地名识别模型。本文采用了CRF++①CRF++是Taku Kudo采用C++语言编写的CRFs工具包,软件包下载地址为h ttp://crfpp.sou rceforge.net。作为模型训练平台。在标注集确定情况下,影响识别结果的因素主要包括以下几个方面:(1)训练语料大小及语料中地名分布情况;(2)势函数选择;(3)参数估算算法。训练语料的大小与模型的识别效果直接相关,太小会遭遇到数据稀疏问题,太大则可能包含噪音,训练时间也会大幅延长。为此,我们选择从语料中抽取仅包含地名的句子生成训练语料,从而在避免数据稀疏的情况下减少训练时间,同时也避免噪音的影响。
依据CRFs模型[16-17],给定一观察序列,其标注序列的概率由一组势函数确定:

影响概率值P的因素是λ(权重向量)、状态转移势函数 t和状态特征函数 s。本文采用了 LBFGS参数评估算法获取λ值。势函数选择在CRF++通过特征模板确定详见表2。
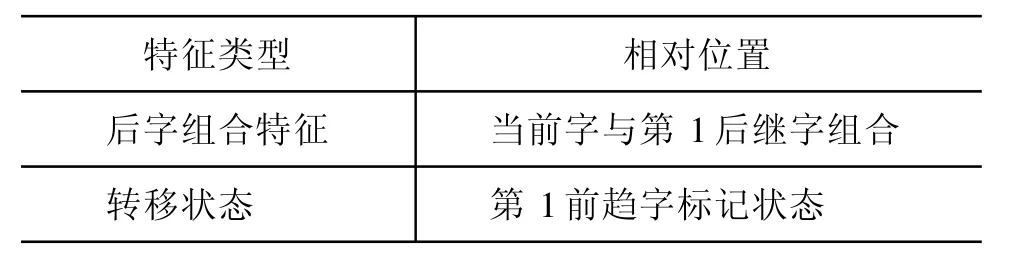
续表
运用获取的CRFs简单地名识别模型,对输入的文本进行识别,即可获得带有分词和地名、机构名标记的输出结果,如例3。
例3 历史给上海/ns提供了新一轮发展机遇。
4 基于篇章的简单地名识别
基于篇章的简单地名识别以一体化处理结果为基础,利用篇章中地名之间的各种固有或概率语义关系重新考察地名标注。考察包括对已标注地名字串的分析和未标注地名字串的分析两个方面。通过分析已标注地名字串的组成结构以及该字串是否与篇章中其他地名存在篇章语义关系,对标注进行修改,以提高标注准确率。对于未标注字串,如果该字串可以作为地名使用,且与篇章中其他地名存在篇章语义关系,则修改该字串为地名,从而提高标注召回率。分析未标注字串又有两种方案。一种方案是直接利用一体化处理所给出的地名标注和文本分词结果(如例3所示)。另一方案是不使用一体化处理中的分词结果,而采用逆向最大匹配对非地名字串进行重新切分,然后考察切分结果是否可能为地名,并将识别结果与原有识别结果合并。后面给出了基于篇章的简单地名识别流程。流程中步骤4分析已标注地名字串,步骤5分析未标注地名字串。两个步骤相对独立。
由流程可知,基于篇章的简单地名识别,需要两个关键组块,其一是依据已识别地名集合 T获取篇章地名扩展集合T′。篇章地名扩展集合的实质是篇章地名同现集合,即在同一篇章中可能共同出现的地名集合。语篇的连贯性以及地名之间固有的语义关系,决定了同一篇章中一些地名会共同出现。第二个关键组块是地名性判断,即给定一个字串,在孤立语境中,通过对该字串的内部结果分析,判断该字串用作地名的概率。本文4.1节与4.2节详细介绍两个组块的获取方法。
基于篇章的简单地名识别流程如下:
步骤1:设定分词方案一为直接使用一体化处理结果,方案二为使用逆向最大匹配;
步骤2:给定一个篇章,通过简单地名标注与文本分词一体化处理得到分词与标注字串向量W;
步骤3:对W进行扫描,获取已识别地名集合 T,并依据T和篇章地名关系,获取篇章地名扩展集合T′=f(T);
步骤4:对W进行扫描,并重复以下操作:
4a.输入下一字串β,如β为空,退出本流程,否则转至4b;
4b.如果字串β被标注为地名,且β∉T′,且地名性判断中确信度小于预定阈值,则修改β标注为非地名;
步骤5:对W以句子S为单位重新扫描并执行以下操作:
5a.从S重复读入字串β,如β为空,退出步骤5;否则,如采用方案一,转至5b;如采用方案二,则对S使用逆向最大匹配分词,并获取对应位置且包含β的字串β′,并令β=β′,并转至5b;
5b.如β已被识别为地名,转至5a,否则,转至5c;
5c.对β进行地名性判定,如确信度大于预定阈值,转至 5d,否则,转至5a;
5d.如果β∈T′,则将β标识为地名;转至 5a;
步骤6:在W中合并原有标注地名与新标注地名并输出。
4.1 篇章地名扩展集合
在简单地名识别过程已识别的地名组成篇章地名集合T。在 T基础上,利用地名之间的同指关系、静态地理关系和动态地理关系,可以获得篇章地名扩展集合 T′,即
其中CR(T)、SR(T)、DR(T)分别为依据 T获得的同指关系集合、静态地理关系集合和动态地理关系集合。
地理实体的地名形式判断算法:
给定一地理实体的全称为C1C2…Cn-2Cn-1Cn,待定字串 C′=C′1C′2C′3…C′m-2C′m-1C′m,如果满足如 下三 个条件,则称字串C′为α的一种表征形式:
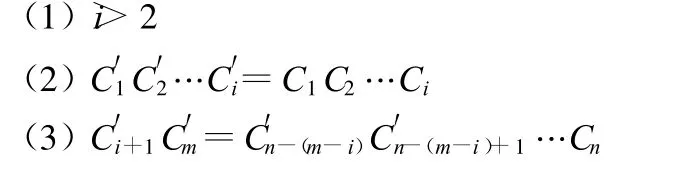
同指关系CR(T)基于如下事实:某一地理实体往往以不同地名形式在同一语篇中反复出现,从而形成不同地名形式之间的同指关系。例如,“西双版纳傣族自治州”、“西双版纳”、“西双版纳自治州”、“西双版纳州”都可以用来指向行政区划“西双版纳傣族自治州”,而在文本中四种地名形式都可能出现。通过地理实体的地名形式判断算法可以获得地理实体的不同语言使用形式。地名形式判断的基本思路是如果一个字符串长度大于或等于2,且其首尾能够与某一地理实体名称(参见表3name字段)模糊匹配,那么这一字符串被认为是该地理实体的一种表征形式。同一地理实体的不同地名形式具有同指关系。
静态地理关系SR(T)是指不同地理要素之间由于天然的或人为的原因而形成的稳定的地理关系。这种地理关系常被人们用来作为方位的参照体系。典型的静态地理关系为行政区划隶属关系,例如“西双版纳傣族自治州”与“云南省”之间的隶属关系。静态地理关系是世界知识的一部分,本文采用地名库作为静态地理关系数据库。该地名库包含162 344个中国地理实体,地名库结构如表3所示。给定两个地名,通过地名库查询可以判断两者是否存在行政区划隶属关系。

表3 地理要素库数据结构
动态地理关系SR(T)是由于人们的社会活动而形成的相互联系,表现为两个地名在同一篇章中出现。例如在同一语篇中,“中国”与“美国”、“英国”、“法国”之间的相互关联是由于外交关系而形成的;“新疆”与“广州”之间由于“广州中国进出口商品交易会”在同一语篇中形成的相互联系。本文以标注语料库为数据基本来源,以语篇为单位,通过获取语篇中地名的同现关系来获取动态地理关系,建立动态地理关系数据库。在实验中,我们从北大语料1至5月份语料中共抽取322 012个动态地理关系对。其中既包括了国家与国家之间的地理关系,如“中国—美国”,也包括了我国内部的地理关系,如“华北—石景山”。
4.2 地名性判断
“字串”地名性判断是在不考虑上下文的情况下,仅从字串内部信息来考察一个字串被标注为地名的概率。例如,“渌口”标注为地名的概率远高于“宋本”。本文将字串的地名性判断看作汉字潜在状态标注问题,使用CRF++作为训练平台建立基于条件随机场的地名性判断模型,表4给出了模型训练中地名的状态标记集合,非地名采用6位标注集①例如:如/B果/E没/B有/E工/B人/C阶/D级/E的/S支/B持/E(B,C,D,I,E,S)。训练词表采用从北大语料库1至5月份语料抽取的词表。运用该模型对字串进行地名性判断,可以获取两类重要信息:给定字串的最优标注和最优标注的确信度。最优标注确信度C f=P(标注序列/观察序列)为CRF中观察字串序列采用最优标注序列的条件概率(文献[17]给出了CRF中条件概率的定义)。例4给出了地名性判断示例。

表4 基于地名结构的简单地名标注集及示例
例4:
(a)民和县 → 民/B-LMC和/I-LMC县/ELCC确信度:94.80%
(b)民和委 → 民/B和/C委/E,确信度:99.58%
其中例4(a)在孤立语境中标注为地名的确信度为94.80%,而例4(b)为非地名的确信度为99.58%。判断为地名的字串所具有的确信度在基于篇章的简单地名识别流程中被用作阈值设置的依据。
5 复杂地名识别
复杂地名识别接受简单地名识别的输出,其中包含简单地名标注信息和分词信息。复杂地名识别也通过条件随机场模型识别。模型训练平台、数据来源、参数获取算法与简单地名相同。数据格式为“词+[O|ns]+标注”,其中O表示非地名,ns表示地名。状态标注集采用6位标注集(S,B,I,E1,E,O)②S为独立构成地名字,B、E1、E和 I分别表示地名首词,结尾倒数第2词,尾词和其他位置词。如:香港/B-ns特别/E1-ns行政区/E-ns。O为非地名。。特征选择见表5。

表5 复杂地名CRFs模型特征选择
6 实验与分析
6.1 层叠条件随机场无分词地名识别
为方便比较,我们参照文献[8],选择北大语料1至5月份语料为训练语料,1月份语料为封闭测试语料,6月份语料为开放测试语料。首先仅采用由条件随机场简单地名识别模块、复杂地名条件随机场模块组成的层叠条件随机场模型进行实验。表6给出了简单地名识别的实验结果,表7给出了复杂地名识别的实验结果,表8给出了层叠条件随机场地名识别结果。

表6 简单地名识别结果
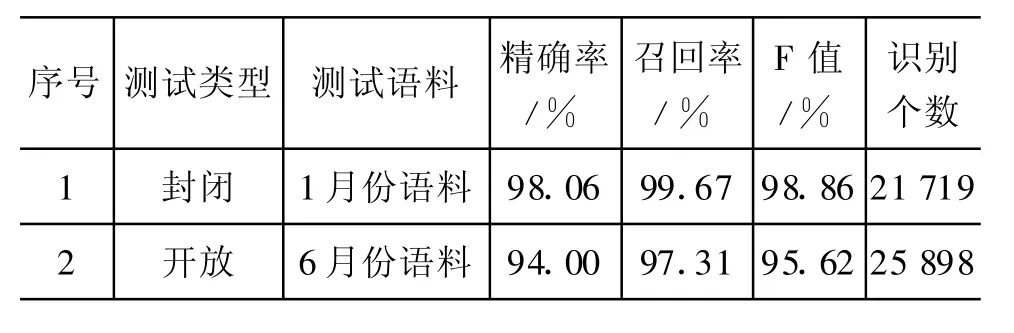
表7 复杂地名识别结果
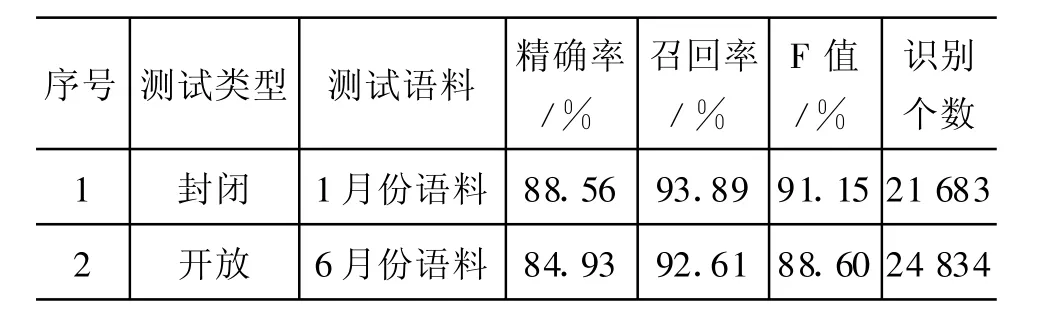
表8 综合地名识别结果
与已有研究相比,采用层叠条件随机场无分词策略在封闭测试和开放测试都取得了较好的性能,开放测试F值与已有类似研究相比高出大约3%。表6、表7和表8中封闭测试和开放测试F值变化不大,说明模型性能相对稳定。而表7显示,在假定分词和简单地名识别完全正确的情况下,复杂地名层级的识别精度可以达到98.86%和95.62%,说明进一步提高地名识别精度的突破口应放在简单地名的识别方面。
6.2 基于篇章的简单地名识别
由第4节可知,基于篇章的简单地名识别包含对已标注字串的考察和未标注字串的考察两个环节,且每一环节都存在地名性判断阈值设置问题。此外,在对未标注地名考察时还有两种方案:基于一体化处理和基于最大匹配。实验首先考察了在一体化处理的基础上不同阈值设置对简单地名识别结果的影响,在处理中省略基于篇章的简单地名识别流程中步骤4,而直接执行步骤5。图2、图3分别给出了不同阈值在封闭测试和开放测试中的识别结果。可以看出,随着确信度阈值趋向于0,封闭测试和开放测试中召回率和F值呈上升趋势,而精确率基本保持不变,说明在对未标注地名进行判断时,仅依靠篇章地名关系就可以正确判断未标注地名是否为地名。

图2 步骤5不同阈值封闭测试结果
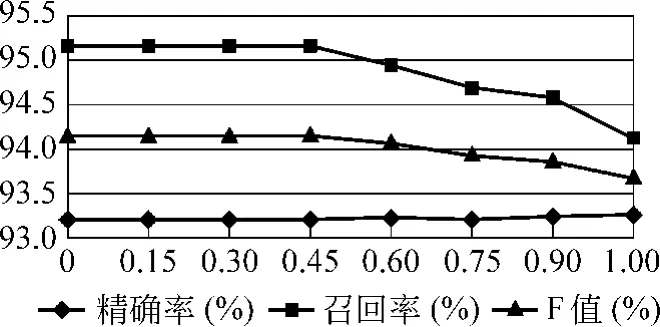
图3 步骤5不同阈值开放测试结果
为考察分词错误对于地名识别的影响,我们进一步分别采用基于CRFs的一体化处理(CRFs)和逆向最大匹配(BMM)两种方案进行了试验(图4、图5)。可以看出,BMM在阈值为0.60时封闭测试时F值方面有小幅提高,而在开放测试中与CRFs差距不明显。BMM在召回率方面的优势较为明显,这说明分词错误对地名识别具有具有较大影响。但是BMM需要对文本进行重新处理,处理时间会大幅延长。

图4 封闭测试两种方案测试结果

图5 开放测试两种方案测试结果
在此基础上,我们选择以一体化处理结果为基础,在对未标注地名考察时地名性判断阈值设置为0,在处理时执行基于篇章的简单地名识别流程中所有步骤,即包括步骤4和步骤5。表9和表10分别给出了在步骤4中地名性判断阈值设置为不同阈值的结果。可以看出,在阈值设置为0.10时,相对于阈值为0,即不对已识别地名进行处理时,系统召回率在封闭测试与开放测试分别降低了 1.34%和1.67%,而精确率分别提高了1.85%和2.38%,F值提高0.35%;在阈值为0.5的情况下,精确度会得到进一步的提高,召回率呈现下降趋势,F值也会下降。这说明地名性判断中确信度较低的地名会对地名识别精度产生较大影响,而将这一部分过滤后系统性能提高幅度较大。
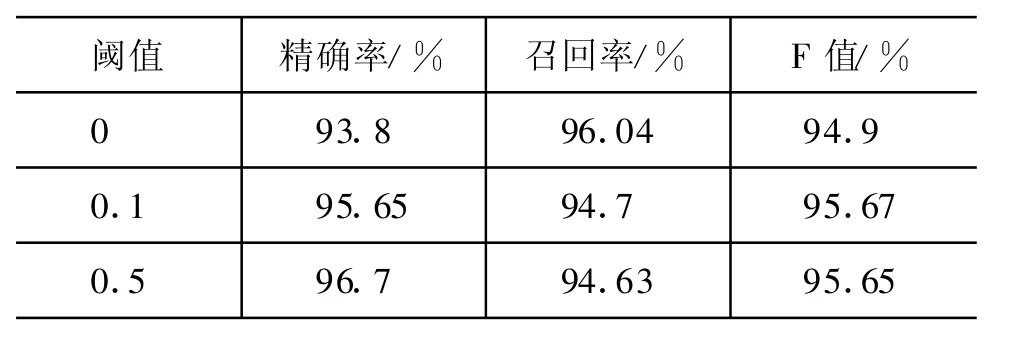
表9 已识别地名不同阈值封闭测试

表10 已识别地名不同阈值开放测试
上述实验也说明,使用一体化处理结果,在对已识别地名处理中地名判断确信度阈值设置为0.1,对未识别地名处理中地名判断确信度阈值设置为0时,基于篇章地名识别达到最好效果,封闭测试精确率和F值分别比一体化处理结果提高 1.87%和1.58%,开放测试精确率和F值分别提高2.33%和0.84%。
6.3 系统综合性能测试
采用6.2节基于篇章识别地名处理的最优设置,使用一体化处理结果,在对以识别地名处理中地名判断确信度阈值设置为0.1,对未识别地名处理中地名判断确信度阈值设置为0,对简单地名和复杂地名进行了综合实验,表11给出了测试结果。与表7相比较,在封闭测试中,精确度提高 2.85%,召回率提高0.49,F值提高1.72%,开放测试中,精确度提高2.45%,召回率下降0.33,F值提高1.16%。分析可以看出,过滤地名判断确信度较低的地名,采用篇章地名关系进行地名识别能够有效地提高地名识别精确率。
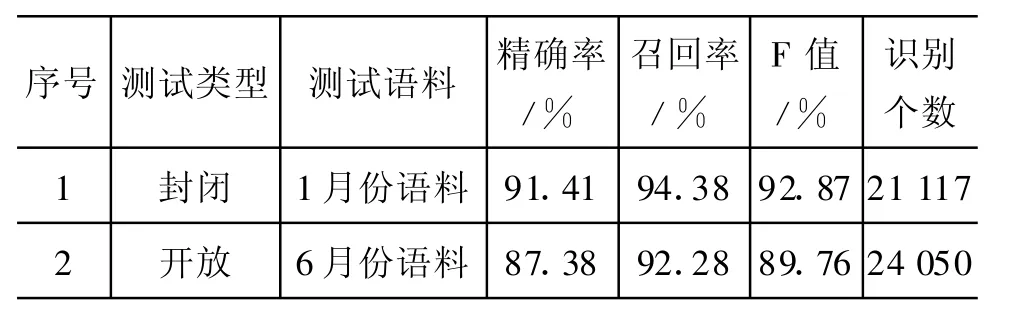
表11 加入地名关系后处理模块的整体识别结果
7 结语
本文探讨了以篇章为单位的地名识别策略和方法,以充分利用地名内部结构信息、左右近邻字等短距离依存关系以及篇章地名关系这一长距离依存关系为指导思想,构建了中文地名识别系统。该系统采用无分词策略,应用条件随机场作为基本模型,分别建立了基于条件随机场的简单地名识别模块、基于篇章的简单地名识别模块和基于条件随机场的复杂地名识别模块。在基于篇章的简单地名识别模块中,构建了篇章地名语义关系知识库和地名性判断模块。试验显示,基于上述策略的地名识别系统在封闭测试和开放测试中F值都达到了较高水平,说明以充分利用短距离依存关系和长距离依存关系的系统构建方法能够建立有效的地名识别模型。
长距离依存不仅表现在篇章地名关系方面,也表现在其他类型的命名实体中,因此这一方法有可能应用于其他类型命名实体识别之中。此外,如果能够建立基于条件随机场的综合考虑短距离和长距离依赖关系的模型,有可能会使系统性能得到进一步提升。这些是我们下一步的研究工作。
[1] 刘开瑛.中文文本自动分词与标注[M].北京:商务印书馆,2000.
[2] 乐小虬,杨崇俊,刘冬林.空间命名实体的识别.计算机工程,2005,31:49-53.
[3] 向晓雯,史晓东,曾华琳.一个统计与规则相结合的中文命名实体识别系统[J].计算机应用,2005,25:2404-2406.
[4] 庄明,老松杨,吴玲达.一种统计和词性相结合的命名实体发现方法[J].计算机应用,2005,24:22-24.
[5] 黄德根,孙迎红.中文地名的自动识别[J].计算机工程,2006,32:220-222.
[6] 李丽双,黄德根,陈春荣,杨元生.SVM 与规则相结合的中文地名自动识别[J].中文信息学报,2006,20(5):51-57.
[7] 钱晶,张杰,张涛.基于最大熵的汉语人名地名识别方法研究[J].小型微型计算机系统,2006,27:1761-1765.
[8] 俞鸿魁,张华平,刘群,吕学强,施水才.基于层叠隐马尔科夫模型的中文命名实体识别[J].通信学报,2006,27:87-94.
[9] 李丽双,黄德根,陈春荣,杨元生.基于支持向量机的中文文本中地名识别[J].大连理工大学学报,2007,47:433-438.
[10] L.Li,Z.Ding,and D.Huang.Recognizing Location Names from Chinese Texts Based on Max-M argin Network[C]//Proceedings of International Conference on Natural Language Processing and Know ledge Engineering 2008,Beijing,China,2008:325-331.
[11] 冯元勇,孙乐,张大鲲,李文波.基于小规模尾字特征的中文命名实体识别研究[J].电子学报,2008,36:1833-1838.
[12] 黄德根,岳广玲,杨元生.基于统计的中文地名识别[J].中文信息学报,2003,17(2):36-41.
[13] 张晓艳,王挺,陈火旺.基于混合统计模型的汉语命名实体识别方法[J].计算机工程与科学,2006,128:135-139.
[14] 周俊生,戴新宇,尹存燕,陈家俊.基于层叠条件随机场模型的中文机构名自动识别[J].电子学报,2006,34:804-809.
[15] 黄国文.语篇分析概要[M].长沙:湖南教育出版社,1983.
[16] H.M.W allach.Conditional Random Fields:An Introduction[R].University of Pennsy lvania,2004.
[17] J.Lafferty,A.M cCallum,and F.Pereira.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]//International Con ferenceon Machine Learning,2001.
