基于贝叶斯估计的概念语义相似度算法
2010-07-18周献中王建宇赵佳宝
吴 奎,周献中,王建宇,赵佳宝
(1.南京理工大学 自动化学院,江苏 南京210094;2.南京大学 工程管理学院,江苏 南京210093)
1 引言
领域本体可以有效地组织、共享、重用领域中的知识,在软件工程、人工智能、信息检索、Web服务发现等领域扮演着越来越重要的角色。概念语义相似度计算是领域本体应用中的基础问题,用于表示本体中两个概念之间的语义接近程度,以便提高知识检索、服务匹配、本体映射等过程的性能[1]。已有的各种概念语义相似度计算模型,都是为了刻画两个概念之间的语义相近程度,其数值大小应尽可能地接近主观意识和客观因素。主观上,由于人们对事物认识的差异,并不能给出两个概念的相似度具体数值,但在父子概念层次结构中,某个概念与它的子概念之间的相似度必然大于其父概念与其子概念的相似度。如“哺乳动物”和“男人”之间的语义相似度应大于“动物”和“男人”之间的相似度,小于“哺乳动物”和“人”之间的相似度。客观上,任何一个概念都是对其祖先概念信息的细化。因此从信息论角度,两个概念之间的相似度与二者共享的信息有关,它们从相同祖先概念中共享的信息量越多,则二者越相似。
计算两个概念之间的语义相似度,目前有很多种方法,Budanitsky[1]对基于WordNet的几种方法进行了比较。李峰[2]认为这些方法可以分为两大类:一种是基于两个节点之间的路径长度,即语义距离;另一种是基于两个节点所含的共有信息大小。综合来看,基于语义距离算法简单,但它依赖于主观建立好的概念层次网络和各个边的权值,因而不能保证相似度的客观性;基于信息量的相似度计算在理论上更具有说服力,它根据信息论的方法,通过概念A、B之间的共享信息量和独立信息量计算获得,然而这种方法需要足够多的领域资料。针对这些方法的不足,江敏等[3]以加权和的方式综合不同方法的结果,然而这种方式的合理性值得怀疑;Anna Formica[4]提出了一种基于形式概念分析的相似度算法,基于概念的上下文计算二者的相似度。本文以Lin[5]的概念相似度算法为基础,提出一种基于贝叶斯估计的相似度计算方法(Bayesian Estimation Similarity,BES),通过综合考虑主观先验因素和客观统计样本,以求能更好地体现领域本体中两个概念之间的语义接近程度。
贝叶斯统计推断[6]是当今统计学发展最快的分支之一,已成为当今统计学的重要组成部分。虽然这种方法曾经有很多争论,比如指定一种先验分布不免带有人为性,未必有助于问题的合理解决,但近年来这些争论已不是主流,大多数研究人员都承认贝叶斯方法可较好的应用于统计学的几乎所有分支。本文不考虑贝叶斯方法在哲学方面的问题,而是根据贝叶斯估计计算概念出现概率。该方法主要思路为:考虑到Beta分布可以通过选择合理参数适应多种分布形状,且容易获得计算结果,本文假设概念出现概率也服从Beta分布,随后基于语义距离的算法构造其先验参数,并利用贝叶斯估计计算该先验分布和统计样本下的后验概率,最后根据基于信息量的公式获得主观经验与客观事实相结合的概念语义相似度。
本文后续内容安排如下:第2节给出语义相似度计算的基本思想,第3节介绍本文提出的算法,第4节将本文提出的算法与现有的6种方法进行比较,最后在第5节总结全文。
2 基本思想
2.1 基本定义
本体的概念起源于哲学领域,是关于存在的学说。1993年美国斯坦福大学的G ruber给出了第一个在信息科学领域中的本体的正式定义[7]:本体是一个明确的概念化共享规范。目前关于本体的形式化定义很多,这里采用W 3C给出的定义[8]。
定义1:概念,也称为类,是指具有相似特性的实体集合的名称;某个概念所限定的具体事物对象,称为个体;个体之间的相互联系称为关系。如:“小张”是概念“学生”的个体,他与《本体论》这本“书”之间存在“借阅”关系。
定义2:本体是一种领域知识表示手段,可以被表示为O=(C,R,I,A),其中C表示概念集合,R表示关系集合,I表示个体集合,A表示相关公理集合。
定义3:如果概念 A具有概念B的特性,称概念A是概念B的子概念,记为A⊆B。如果A⊆B且A、B之间不存在满足继承关系的其他概念,则称概念A是概念B的直接子概念,记为A=B⊃;。概念B的子概念集合记为ch(B),概念B的直接子概念数称为该概念的出度deg⊃(B)。相应地,也有直接父概念B,父概念集合an(B)。
定义4:领域本体中的概念集在继承关系上构成了概念格。格的顶节点称为顶概念T,概念C与顶概念之间最短路径上的边数称为该概念的深度dep(C)。
定义5:在领域本体中,概念的出现概率记为P(C)=P(c∈C),它表示从所有个体中随机抽取某个个体是概念C个体的可能性。统计上,该数值可以用相对频率P(C)=f req(C)/N,其中 f req(C)=∑c∈C count(c)表示概念C的所有个体数,N为领域本体中全部个体数。
定义6:在领域本体中,概念C1和C2之间的相似度定义为[5]
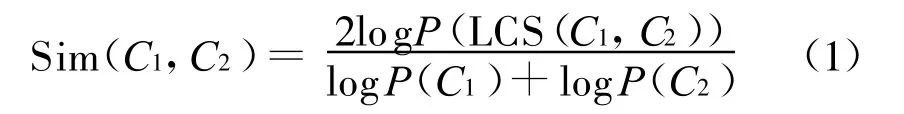
其中LCS(C1,C2)表示概念C1和C2的最小公共父概念。
2.2 相似度基本假定
从公式(1)我们可以看出概念出现概率是计算两个概念语义相似度的关键,而它需要在大样本空间中统计基础上获得,本文提出了一种基于贝叶斯估计的算法以减小这种依赖。在下文展开之前,首先给出如下两个基本假设:
1)领域知识库中,“个体a是概念C中的个体”这一命题的取值只有True和False两种可能,即随机变量 x:=a∈C服从0~1分布;
2)若个体a是概念C中的个体,则它必然是C的父概念的个体,因此某概念的出现概率必然大于其子概念的出现概率,小于其父概念的出现概率。
显然,这两个基本假定是可以接受的,概念语义相似度具有如下性质[5,9]:
1)当两个概念相同时,相似度最大,规定为1;当两个概念没有共性时相似度最小,规定为0,即0≤Sim(C1,C2)≤1,且Sim(C,C)=1。
2)概念间相似度与二者所处层次有关,概念层次越深,对事物刻画越细,父子概念之间的差异越小,语义越接近。即Sim(C,C)≤Sim(C,C)。
3)某个概念的直接子概念越多,则分类越细,某个子概念对父概念的修饰越少,父子概念之间相似度越大。
3 基于贝叶斯估计的概念相似度算法原理
3.1 概念出现概率先验分布构造
根据基本假设,从领域本体中任意选取某个体ai,事件 xi:=ai∈C是独立同分布的,且服从概率为P的0~1分布。我们利用基于语义距离的算法构造概率P的先验分布。概念之间的语义距离是指概念层次结构中节点之间最短路径的加权和,路径的权值可按公式(2)计算:

其中经验参数ρ>1反映了概念层次结构中语义距离随着深度变化的减小程度。两个概念之间的语义距离为:
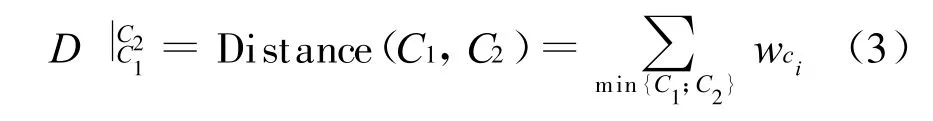
其中min{C1;C2}是概念C1和C2之间的最短路径,因此C1和C2的语义相似度为:
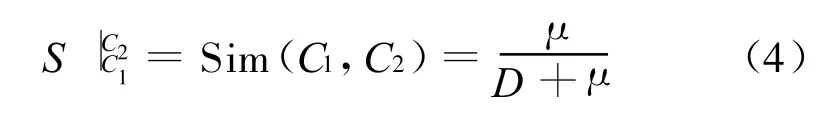
经验参数μ为调节参数。根据公式(4)容易验证对于任意概念C均有

3.3 Beta分布形状参数计算
考虑到标准Beta分布变量范围在[0,1]之间,做线性变换将上述Beta分布化为标准形式[10]:
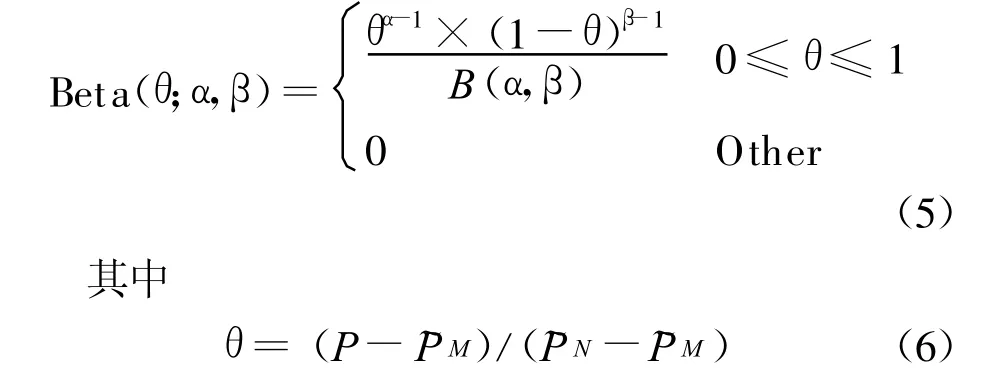
根据Beta分布形状参数计算公式[10]有:

其中,期望E=(˜PM+4˜P+˜PN)/6,方差D=(˜PN-˜PM)2/36。
3.4 后验出现概率
根据统计样本在n个个体中有k个个体属于概念C,下面根据最小贝叶斯风险估计计算θ的估计值。
设损失函数为 L(θ,δ),则统计判决 δ(X)的贝叶斯风险函数为
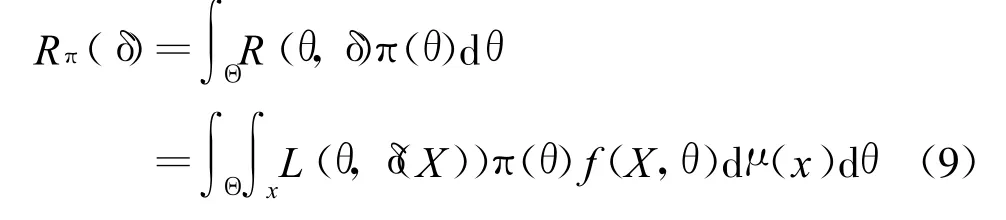
其中 f(X,θ)为 X在θ估计下的联合分布,根据贝叶斯定理,可得:

其中c(X)是归一化常数保证该分布是一个概率分布,将公式(10)代入公式(9)并交换积分次序后可得:
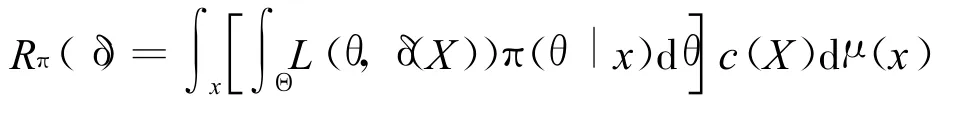
把损失函数 L(θ,δ(X))关于后验分布 π(θ|x)的加权平均称为后验风险,即
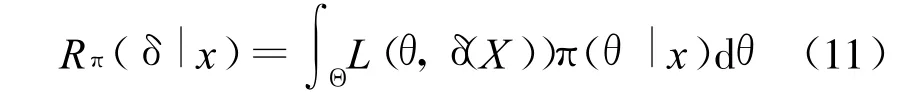
可以看出若某个 δ(X)使得后验风险 Rπ(δ|x)达到最小,则它也使贝叶斯风险 Rπ(δ)达到最小。取损失函数 L(θ,δ(X))=(δ(X)-θ)2代入公式(11)后得
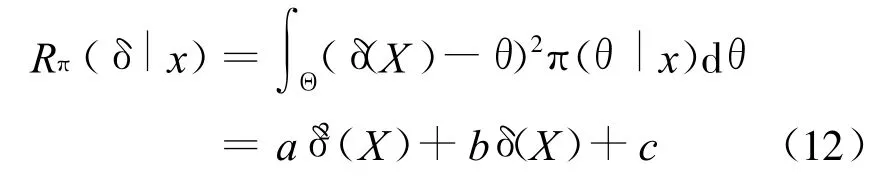
其中:
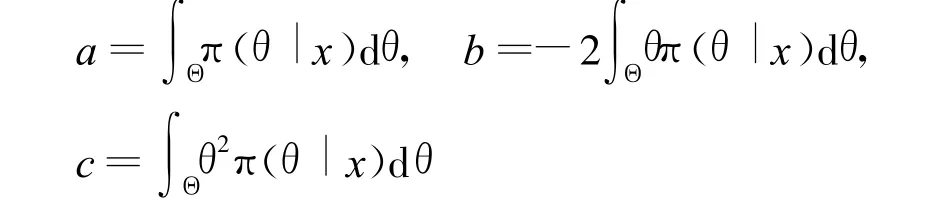
因此当δ=-b/2a时,Rπ(δ|x)取得最小值。根据公式(10),有:
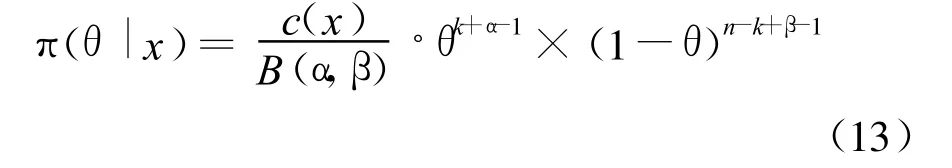
可以看出 π(θ|x)也服从 Beta分布,其超参数为k+α和n-k+β,即

因此使得Rπ(δ|x)取得最小值的δ为:
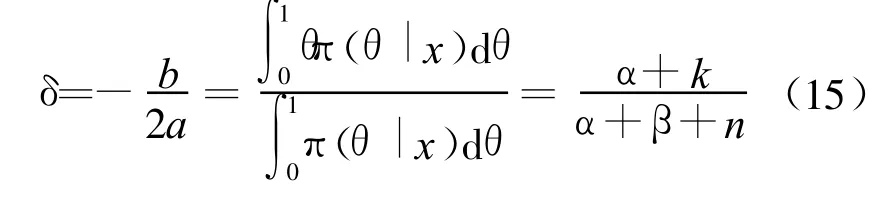
最后根据线性变换公式(6),有
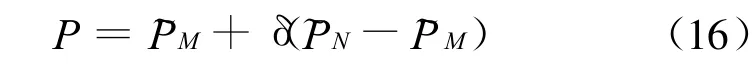
这样,我们便通过贝叶斯估计计算出概念出现概率P的后验估计值。从公式(16)看出P为概念出现概率的主观经验值根据统计特性的修正,当有大样本时δ趋向于k/n体现了统计特性。当样本很少,特别是k=0时并不能说某概念不可能出现,仍然具有一定的出现可能,可通过主观经验算法计算获得。
4 算法实现及结果分析
4.1 算法实现过程
基于上面介绍的概念相似度BES算法原理,我们实现了本算法,并与其他几种方法比较。在算法实验中以WordNet[11]作为数据源,首先利用JAWS开发包,以entity为根节点,通过函数getSynsets获得单词的义元,通过函数getTagCount获得该义元的出现次数,通过函数getHyponyms获得该义元的子概念。采用宽度优先的方式逐层访问各个概念节点信息,获得其出现次数统计值,并保存到自定义的数据库中。随后根据提取出的概念层次结构,遍历各个节点,依次计算各自的出现概率先验分布参数和后验估计值,由于这些数据的计算为实数运算,故算法复杂度取决于所采用的遍历策略,可以证明为O(n)[12]。概念出现概率的贝叶斯估计算法过程如下:

算法CalcValues(C)过程如下:

4.2 算法实验结果分析
由于不同的算法原理不同,计算结果也有较大差异,我们参考文献[1]的做法:以M iller和Charles统计的30对概念间的主观相似度数值作为参考标准,并与 Ted Pedersen 实现的 Wordnet::Similarity[13]中其他相似度算法结果对比。实验中取ρ=1.1,μ=0.5(x)=x,实验结果见表1,表中BES为本算法结果,HSO 、LCH、WUP、RES、JCN 、LIN分别表示 Hirst&St-Onge方法,Leacock&Chodorow方法,Wu&Palmer方法,Resnik方法,Jiang&Conrath方法和Lin方法。
为了比较不同相似度算法的差异,我们参考文献[1],计算各组数据与Human结果的相关系数,以此作为衡量各种算法优劣的指标,结果如表2所示,可以看出本文算法的相关系数稍高于其他算法。
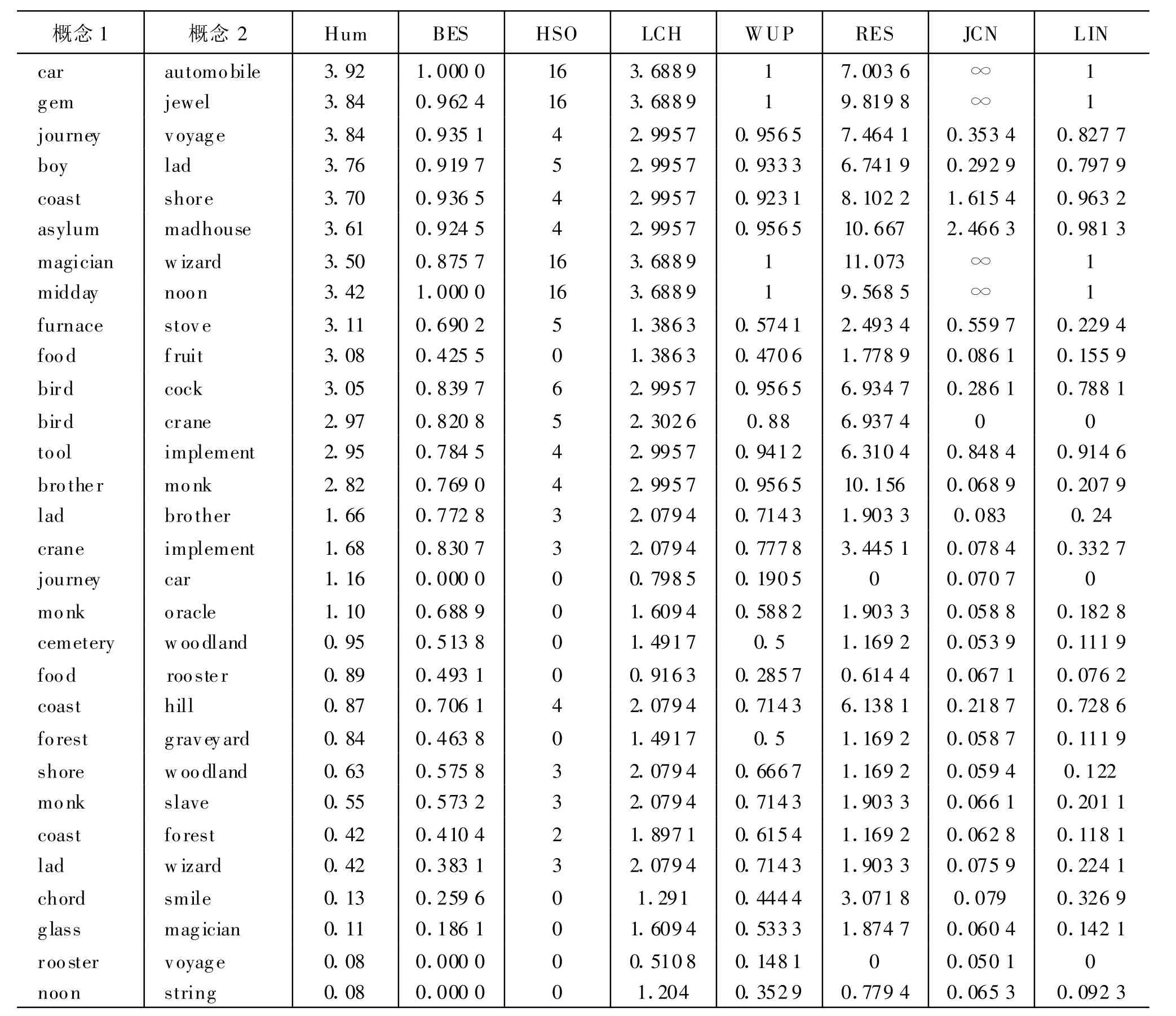
表1 相似度数值对比计算结果
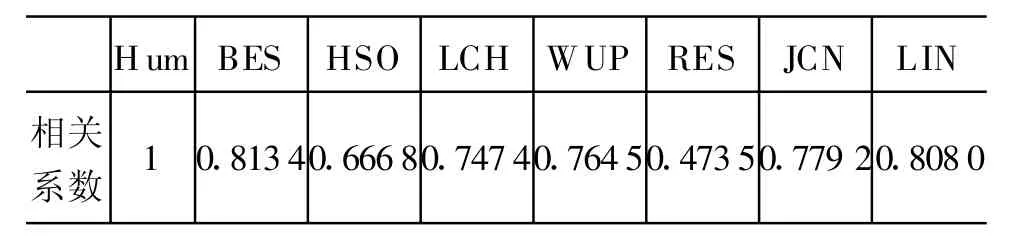
表2 相似度相关系数对比
4.3 参数对比实验
为了分析统计数据和算法参数对相似度计算结果的影响,采用同样的测试集做了对比实验,实验结果如表3所示。
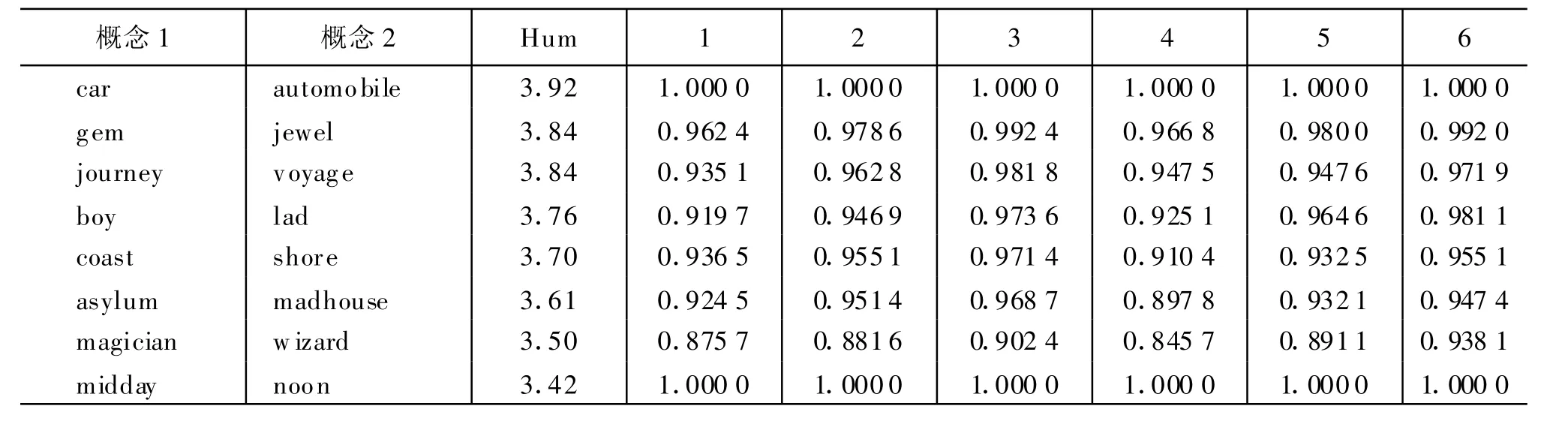
表3 参数调整对比计算结果

续表
实验中,前三组为带有统计数据的结果,其中第1组ρ=1.1,μ=0.5;第2 组 ρ=1.2,μ=0.3;第3组ρ=1.4,μ=0.2。后三组为概念出现次数均为0时的结果,其中第4组ρ=1.1,μ=0.5;第5组ρ=1.2,μ=0.3;第 6组ρ=1.4,μ=0.2。计算各组数据与H um an结果的相关系数,结果如表4所示。
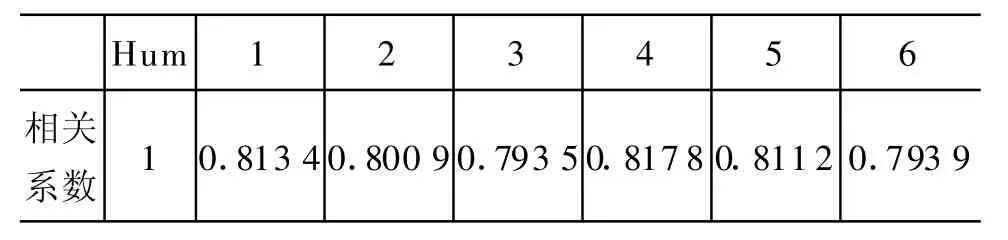
表4 参数调整对比实验相关系数
从实验结果看出,尽管随着统计数据和参数的变化,相似度结果也有所不同,但与主管经验的相关系数变化很小,因此本算法对数据和参数的变动不敏感。
5 结束语
概念相似度计算是本体映射、服务发现、语义检索等技术的关键基础。本文的主要贡献如下:提出了一种基于贝叶斯估计的概念出现概率算法;在此基础上概念相似度计算综合考虑了人为主观经验和客观统计样本,改进了传统方法的不足,具有较好的实用性。结合WordNet的算法实验表明,本算法与人为主观经验之间具有最大的相关系数。
由于本算法需要首先根据当前概念层次结构和出现次数计算各个概念的出现概率,当概念数较多,网络复杂时,如使用WordNet时,它必须构造新的数据库以便存放每个概念的出现概率,需要占用额外的资源。另外,由于概念相似度大小并没有客观标准,仅依赖少量测试数据并不能充分说明各种方法之间的性能差异,且主观经验值是否合理也有待商榷,因此如何评价各种算法的优劣性还值得进一步研究。
[1] A lexander Budanitsky,Graeme H irst.Evaluating Word-Net-based Measures of Lexical Semantic Relatedness[J].Computational Linguistics,2006,1(32):13-49.
[2] 李峰,李芳.中文词语语义相似度计算——基于《知网》2000[J].中文信息学报,2007,21(3):99-105.
[3] 江敏,肖诗斌,王弘蔚,等.一种改进的基于《知网》的词语语义相似度计算[J].中文信息学报,2008,22(5):84-89.
[4] Anna Form ica.Ontology-based concept similarity in Formal Concep t Analysis[J].Information Sciences,2006,176(18):2624-2641.
[5] Dekang Lin.An in formation-theoretic definition o f similarity[C]//Proceedings of the 15thInternational Conference on M achine Learning,San Francisco:M organ Kaufmann.1998:296-304.
[6] 陈希孺.数理统计引论[M].北京:科学出版社,1999:131-159.
[7] Thomas R.G ruber.A translation approach to portable ontology specification[J].Know ledge Acquisition,1993,5(2):1992-2201.
[8] W 3C.OW LW eb Ontology Language Reference[EB/OL][2009-7-8].http://www.w3.org/TR/ow l-ref.
[9] 刘群,李素建.基于《知网》的词汇语义相似度计算[C]//台北:第三届汉语词汇语义学研讨会论文集.2002:59-76.
[10] 方开泰,许建伦.统计分布[M].北京:科学出版社.,1987:246-258.
[11] Princeton University Cognitive Science Laboratory.W ordNet-a lexical database for the English language[EB/OL][2009-7-9].http://wordnet.p rinceton.edu.
[12] Thomas H.Cormen,Charles E.Leiserson,Ronald L.Rivest,Introduc tion to A lgorithms[M],M IT Press,2001:224-227.
[13] Ted Pedersen.W ordnet::Sim ilarity[EB/OL][2009-7-9],http://w nsim ilarity.sourceforge.net.
