突发公共事件下省级财政收入预测分析
2024-01-19王桐威李梦瑶赵姝瑶
□文/王桐威 李梦瑶 赵姝瑶
(1.东北林业大学理学院;2.东北林业大学文法学院 黑龙江·哈尔滨)
[提要] 本文以新冠肺炎疫情作为突发公共事件的代表,从经济角度的影响出发,通过收集2013~2021 年31 个省(区、市,除港、澳、台地区外)财政收入数据及相关经济指标,利用Lasso 回归筛选出有关经济指标作为特征后,采用多维K-Means 聚类算法对各省财政进行聚类分析,将全国各省划分成五类。接着基于各省数据再次利用Lasso 回归筛选出对当地财政收入影响较大的指标作为变量,建立SVR 回归模型,对2022 年与2023 年一般公共预算收入进行预测。与传统的变量选择方法相比,采用Lasso 回归分析选择变量避免变量的共线性问题,使得聚类分析更加接近实际。SVR 回归模型预测与灰色预测相比,精度较高,预测效果好,对国家以及相关地方政府制定未来财政计划以及实现经济社会长足发展都有一定的参考意义。
突发公共事件是指突然发生,造成了严重社会危害,需要采取应急处置措施予以应对的自然灾害、事故灾难、公共卫生事件和社会安全事件。本文以2020 年初爆发的新冠肺炎疫情作为突发公共事件的代表,以下称为“突发公共事件”。自2012年底开始,我国的经济增长速度显著,然而,2020 年初的突发新冠肺炎疫情对我国的经济总体运行产生了重大影响。由于及时实施了有效的策略,以及我国经济本身的强大抗风险能力,我国经济在受到打击后迅速恢复。然而,各地的财政收入还未能完全恢复到事件发生前的状态。
财政收入是地方政府为了执行其职责、实行公共政策以及提供公共产品和服务所筹集的资金总额。在国家层面,财政收入在国家经济中起着关键的作用,既为国家财政支出提供基础,又能调控和稳定国家经济发展。在省级层面,财政收入是评估省内政府财力的重要指标,省政府是否能在社会经济活动中提供充足的公共产品和完善的公共服务,很大程度上取决于省内财政收入的充足程度。
突发公共事件给经济稳定发展带来了巨大压力,各省财政收入下降,财政收支的问题愈加严重。但同时,许多地区也正在经历经济发展模式的重要转变阶段,政府是否能为企业和个人提供优质的公共服务,是否能支持省内经济转型的顺利进行,很大程度上取决于政府财政收入的多少。财政收入是政府运营和社会发展的重要支撑。因此,从全国角度来看,对地方财政收入的分类和预测是非常必要的,既可以为国家宏观调控提供参考,也为各地政府制定未来财政计划提供实用价值。
本文从2020 年初的突发公共事件为出发点,在各省(除港、澳、台地区外)发布的《统计年鉴》中收集2013~2021 年与财政收入相关的经济指标数据,考虑到原始数据存在着严重的共线性问题,本文选用了Lasso 回归作为筛取特征变量的主要方法。接着,再采用面对未知问题较为容易实现且对大数据集有较高的效率的K-Means 聚类算法,以地区生产总值、税收等利用Lasso 回归筛选出的变量作为特征,实现分类;之后,构建了SVR 回归模型,再次利用Lasso 回归通过各省的指标对其财政收入的影响大小,筛选出的特征变量,对2022 年各省财政收入进行预测。以上算法皆在Pycharm 编译环境下,利用python3.10实现。在进行聚类分析和预测分析后,得到了区域性经济特征,使得本文在国家区域化发展的背景下更有实际意义,也让所使用的分类和预测模型具有一定的社会价值。
一、Lasso 回归变量选取
(一)Lasso 回归原理简述。Lasso 是一种以缩小特征集(降阶)为思想的收缩估计方法。Lasso 方法可以将特征的系数进行压缩并使某些回归系数变为0,进而达到特征选择的目的。
关于特征变量筛选的模型本质上是寻求模型稀疏表达的过程,而这种过程可以通过优化一个“损失”+“惩罚”的函数问题来完成。
Lasso 参数估计定义如下:
其中,λ 为非负正则参数,控制着模型的复杂程度。λ 越大,对特征较多的线性模型的惩罚力度就越大,最终获得一个特征较少的模型,称为惩罚项。接着采用交叉验证法,选取误差最小的λ 值。最后,按照得到的λ 值,用全部数据重新拟合模型。
(二)经济指标选择。为研究影响各省的财政收入因素,本文将一般公共预算收入作为因变量,结合《统计年鉴》中所给出的有关指标,选择了一般公共预算支出、地区生产总值、税收收入、人均可支配收入等20 个指标作为自变量,变量名称及含义对应见表1。(表1)

表1 变量名称及含义对应表
在接下来的聚类分析与预测中,皆会使用基于所给的变量中利用Lasso 回归的方法分别选取适用于聚类分析与预测分析的特征变量。
二、K-Means 多维聚类分析
(一)K-Means 模型原理简述及模型构造。K-Means 算法是一种典型的基于划分的聚类算法,也是一种无监督学习算法。K-Means 算法的思想是对给定的样本集,用欧氏距离作为衡量数据对象间相似度的指标,相似度与数据对象间的距离成反比,相似度越大,距离越小。首先从数据集中随机选取k 个初始聚类中心Ci(i≤1≤k),计算其余数据对象与聚类中心Ci的欧氏距离,找出离目标数据对象最近的聚类中心Ci,并将数据对象分配到聚类中心Ci所对应的簇中。然后计算每个簇中数据对象的平均值作为新的聚类中心,进行下一次迭代,直到聚类中心不再变化或达到最大的迭代次数时停止。
空间中数据对象与聚类中心间的欧氏距离计算公式为:
其中,X 为数据对象;Ci为第i 个聚类中心;m 为数据对象的维度:Xj、Cij为X 和Ci的第j 个属性值。
整个数据集的误差平方和SSE 计算公式为:
其中,SSE 的大小表示聚类结果的好坏;k 为簇的个数。
(二)K-Means 特征变量选取。本文用python 语言,结合全国省市综合财政数据,将数据进行预处理后,实现Lasso 回归,选出变量,得到的结果如表2 所示。(表2)
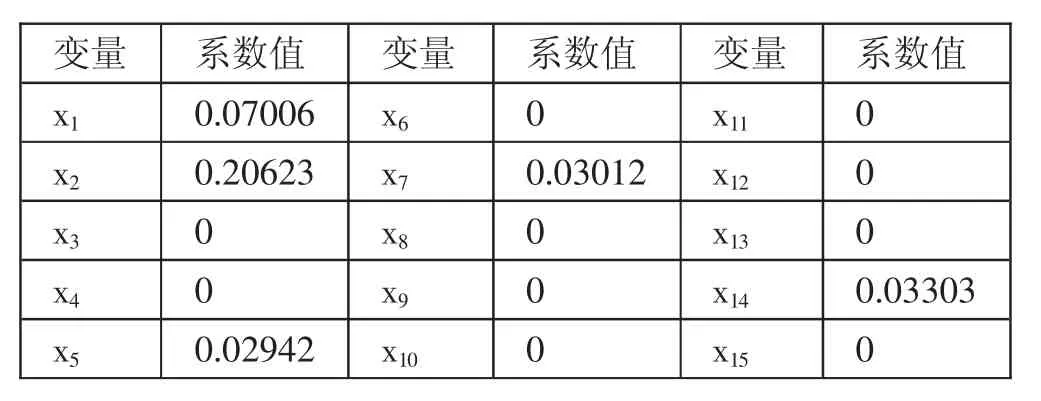
表2 变量及其系数一览表
由此可见,综合各省财政数据对一般公共预算收入影响较大的变量为:一般公共预算支出(x1)、地区生产总值(x2)、第三产业增加值(x5)、税收(x7)、农业总产值(x14)、城镇与农村人均可支配收入(x16、x17)。这些变量将作为聚类分析的特征。
(三)多维K-Means 聚类分析模型应用。利用python 中的pandas 功能将数据以矩阵形式带入模型中,根据Lasso 所筛选出的特征变量,K-Means 算法将我国各省份共分为五类,如表3 所示。(表3)

表3 全国各省与直辖市聚类情况一览表
(四)结果分析。根据Lasso 回归,一般公共预算支出、地区生产总值、第三产业增加值、税收、农业总产值、城镇与农村人均可支配收入作为特征,进行了聚类分析,将我国各省财政分为了五个类别。但这里要单独说明一下,在2020~2021 年间大多数省份的一般公共预算支出的增加主要是在医疗方面,并没有产生收入,故下文除重庆市外不作讨论。
第一类为广东省与江苏省,作为两个沿海的经济大省,其一般公共预算收入与GDP 在近几年一直稳居全国的前两位,即使受新冠肺炎疫情的冲击,但这两个省份也能够保持良好的经济态势,稳步发展。
第二类为上海市、北京市、山东省、浙江省。上海与北京作为中国最重要的经济中心与政治中心,内循环稳定,防疫工作更加先进,在一定程度上避免疫情冲击。而在疫情下,人们日益增加的消费需求,使得本就商品经济发达的浙江更具经济活力。山东省则作为传统的农业大省,地理位置优越,工业门类齐全,综合实力强,也是唯一一个常住人口与户籍人口都过亿的人口大省,这让山东的各项经济指标在全国名列前茅。疫情下的全球经济不稳定性,但浙江省与山东省的制造业为其经济提供了发展动力。
第三类则将重庆市单独分为一类。主要因素为国家的“西部大开发”战略以重庆市为核心引擎,因此重庆市的一般公共预算支出多为工业方面,可以将支出有效转化为收入,以此带动西部地区的经济发展。而且重庆的地理位置优越,交通运输业发达,其中江北机场在疫情时的空运运输量在国际上居于前位。
第四类为四川省、天津市、安徽省、河北省、河南省、湖北省、湖南省、福建省、辽宁省。这些省份本质上与第五类省份相同,经济欠发达,但各自存在其特殊性。比如,天津市与河北省处于“京津冀”工业基地,工业基础好;而安徽则背靠上海市和江苏省等经济发达地区,在这些地区经济转型升级时,可以承接二三产业的资源;湖南省位于“一带一路”的交通主干线上,税收与出口总量较大,建设了一批境外经贸合作园区;辽宁省由于地理位置、交通发达以及具有不依靠自然资源的重工业发达等原因,相较于东三省的其他区域经济发展较为良好。
第五类为云南省、内蒙古自治区、吉林省、宁夏回族自治区、山西省、广西壮族自治区、新疆维吾尔自治区、江西省、海南省、甘肃省、西藏自治区、贵州省、陕西省、青海省、黑龙江省。这些地区工业欠发达,产业结构不合理,未能实现转型升级,农产品商业化程度低,地理位置偏僻,地形大多以高山丘陵为主。其中,海南较为特殊,由于政策支持不足,产业结构以旅游业为主,在疫情期间受到较大冲击,加上海南的地理位置特殊,与内陆各省份贸易往来较少,资源匮乏。
三、SVR 预测分析
(一)SVR 原理简述及模型构建。SVR(支持向量回归)是在做拟合时采用了支持向量机的思想来对数据进行回归分析。SVR 的原理就是在线性函数两侧制造了一个“间隔带”,间距为∊(也称容忍偏差,根据经验人为设置的值),对所有落入到间隔带内的样本不计算损失,也就是只有支持向量才会对其函数模型产生影响,最后通过最小化总损失和最大化间隔来得出优化后的模型。
给定数据集T={(x1,y1),(x2,y2),…,(xn,yn)},其中,xi=(xi(1),xi(2),…,xi(n))T∈Rn,yi∈R,i=1,2,…,n。用数学语言描述问题如下:
其中,C≥0 为罚项系数,L∊为损失函数。
再引入拉格朗日乘子,这样就可以将问题转化为求极大值与极小值的问题,假设最终解为α*=(α*1+α*2+…+α*n)T。在解中,找出α*的某个分量C>α*j>0,则有式(7)和式(8)。
(二)变量选择。与聚类分析相比,各省财政收入的预测分析变量的选取也同样采用Lasso 回归,但是数据的选用范围由全国变为各省,表4 为进行Lasso 回归分析后各省采用变量的总结。(表4)

表4 进行Lasso 回归分析后各省采用变量一览表
(三)模型训练。为保证模型的精确度,挑选广东省、河南省以及黑龙江省这三个省,并对其2013~2021 年的一般公共预算收入进行预测,作为模型的训练集。分别基于表4 中所筛选出的变量对这三个省份2013~2021 年财政收入进行SVR 预测,之后,将所得到的预测值逐个整理与其真实值进行对比,可得到该模型很好地拟合了这三个省2013~2021 年的一般公共预算收入,具有较高的精确度,可以进行接下来对2022 年的财政收入进行预测。
(四)模型应用。基于表4 中所筛选出的变量对31 个省(区、市)2022 年的财政收入进行SVR 预测,之后将所得到的预测值逐个整理与其真实值进行对比,之后将所得到的预测值逐个整理与其真实值进行对比,如图1 所示。(图1)
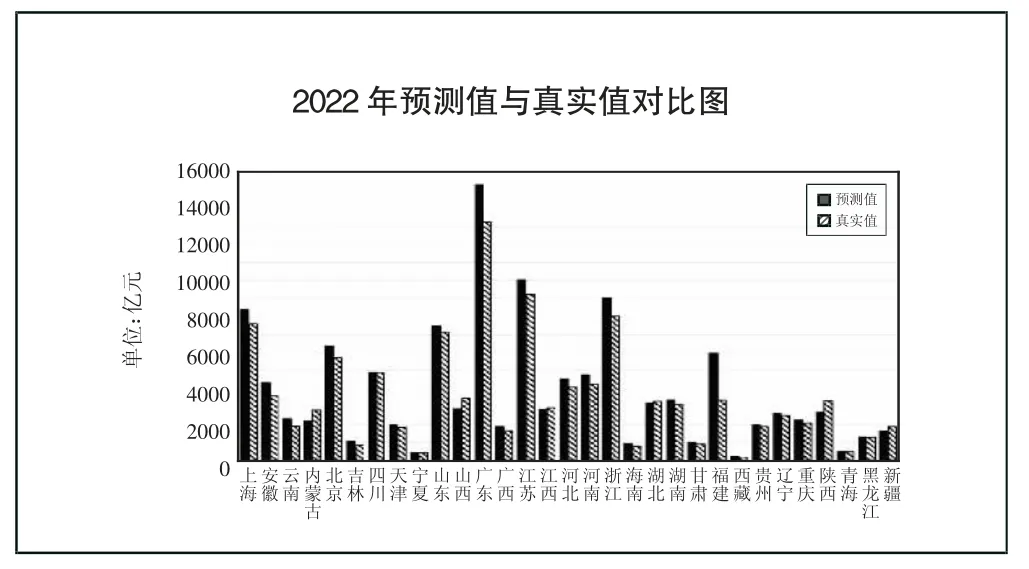
图1 2022 年预测值与真实值对比图
(五)结果分析。在不同数据中采用Lasso 回归筛选出适用于两种分析的特征变量后,利用python 语言通过两种算法,得到较为接近现实与精确度较高的聚类结果与预测结果。接下来,将聚类结果作为基础对预测结果展开分析。
第一类为广东省与江苏省。新冠肺炎疫情的爆发所带来的通货膨胀促进了广东与江苏两省就业率,有效提高了两省的税收收入,进而提高了一般公共预算收入。广东省人口自然增长率相比全国其他省份持续领先,也为社会消费和税收稳定助力。
对第二类中的上海市、北京市、山东省、浙江省与第三类的重庆市的分析与前文聚类结果的分析大体相似,不再赘述。
预测偏差较大的主要省份都出现在第四类与第五类中,因此下文将会对的预测偏差做出分析。
第四类,四川省、天津市、安徽省、河北省、河南省、湖北省、湖南省、福建省、辽宁省。这里福建省的预测值与真实值相差尤为显著,主要原因是其经济发展主要的两个支柱行业——外贸与旅游受疫情影响较大,同时福建省疫情高峰转段时间较晚,持续性的高运输成本导致省内企业运行成本提高,市场需求降低。
第五类为云南省、内蒙古自治区、吉林省、宁夏回族自治区、山西省、广西壮族自治区、新疆维吾尔自治区、江西省、海南省、甘肃省、西藏自治区、贵州省、陕西省、青海省、黑龙江省。预测值与真实值相差较大的两个省份为内蒙古自治区和陕西省,都为真实值比预测值高。其中,内蒙古自治区在2022 年财政收入剧增主要因为国际形势动荡,煤炭等能源出口大幅提高,拉动地区经济;而陕西省发展基础较好,如文化资源、能源、农业资源不断为经济发展助力。此外,陕西省的经济发展以内需为主,一方面进口贸易受限,国内需求增大;另一方面出口减少对其影响较小。
综上,在采用Lasso 回归分别筛选K-Means 聚类和SVR预测模型的有关变量得出的结果与现实贴近,说明本文所应用的两个模型精度较高,应用性较强,对国家宏观调控和各地政府制定未来财政计划具有一定的参考价值。
